
Transformer+self-attention超详解(亦个人心得)
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


最近刚开始阅读transformer文献感觉有一些晦涩,尤其是关于其中Q、K、V的理解,故在这里记录自己的阅读心得,供于分享交流
01
1.1 计算顺序

1.2 计算公式详解
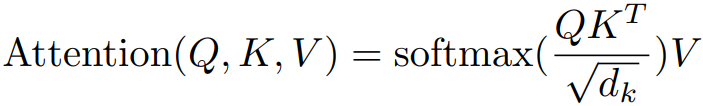
公式1

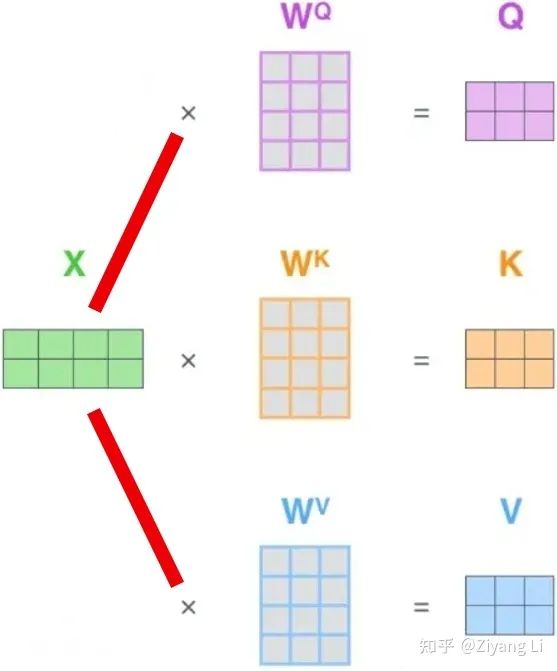
补充:最开始的W权值矩阵需要初始化,在后续BP的过程中,W的具体数值会不断更新学习,这样做的好处不仅仅是可以提高模型的非线性程度,还能提高模型拟合能力,通过不断学习让注意力权值正确分布
02
2.1 整体结构

Transformer模型结构
2.2 encoder
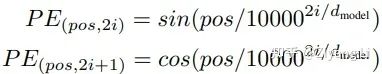
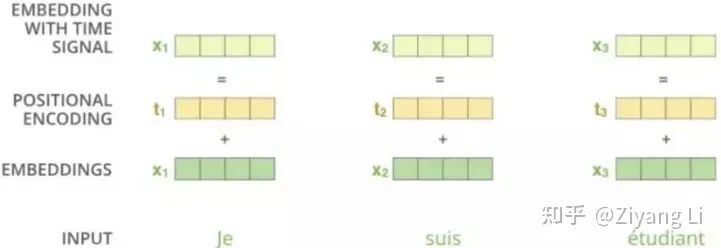
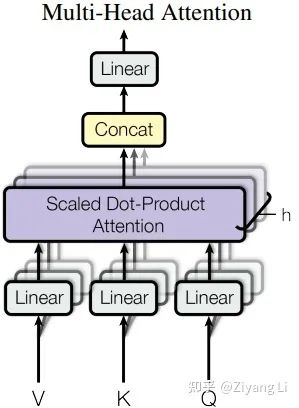
2.3 Multi-Head Attention层
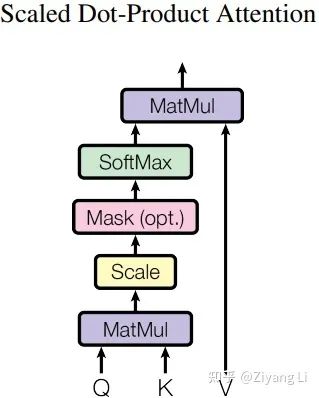
2.4 Scaled Dot-Product Attention层

2.5 decoder
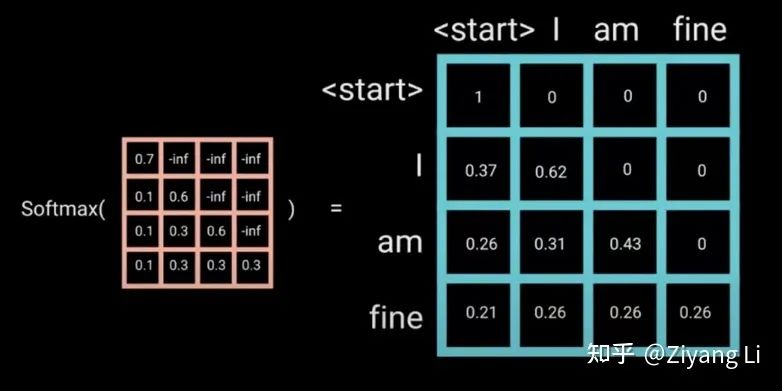
2.6 Mask
 为0,因此可以将未来信息抹去。
为0,因此可以将未来信息抹去。
2.7 关于decoder的输入(包括shifted right)讲解:


推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!
评论