
Vision Transformer | 超详解+个人心得
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!地址:https://zhuanlan.zhihu.com/p/435636952
论文名称:《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》
论文地址:https://arxiv.org/pdf/2010.11929.pdf
pytorch版本代码:https://github.com/lucidrains/vit-pytorch
01
这周开始阅读VIT,读完后颇有感触,在这里写下一些对论文的理解以及个人思考。
We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks
本文是基于transformer的encoder部分提出的针对图像分类任务的方法,关于传统transformer讲解可见本人另一拙作:《attention is all your need》
02
首先放图:
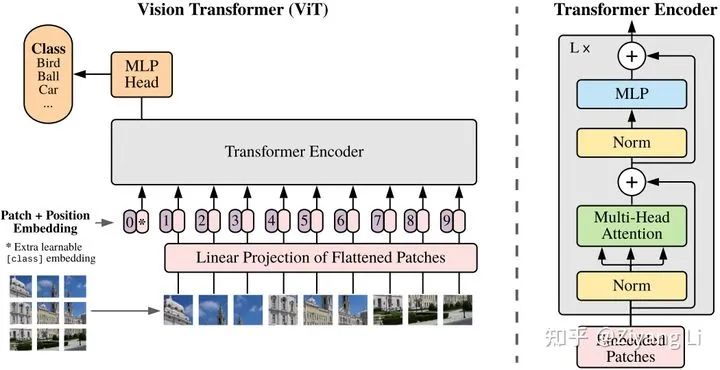
1.1 数据预处理
从图片的左下角开始看起,我们看到的是一个个被切分好的图片块,这里需要对输入作出解释:
假设原始输入的图片数据是 H x W x C,我们需要对图片进行块切割,假设图片块大小为P1 x P2,则最终的块数量N为:N = (H/P1)x(W/P2)。
这里需要注意H和W必须是能够被P整除的
接下来到了图一正中间的最下面,我们看到图片块被拉成一个线性排列的序列,也就是“一维”的存在(以此来模拟transformer中输入的词序列,即我们可以把一个图片块看做一个词),即将切分好的图片块进行一个展平操作,那么每一个向量的长度为:Patch_dim = P1 x P2 x C。
经过上述两步操作后,我们得到了一个N x Patch_dim的输入序列。
1.2 Patch + Position Embedding
仅仅拉平成P1 x P2 x C的向量是不够的,我们需要经过一个全连接层,对维度进行缩放,即文中的Patch Embedding,缩放后的维度为dim(使用nn.Linear即可,此处不再赘述),用公式表示即:
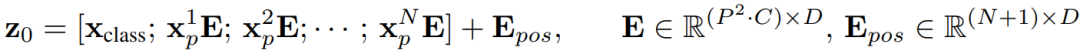
从公式中可以看出多了一个
这里用一张图来帮助理解:
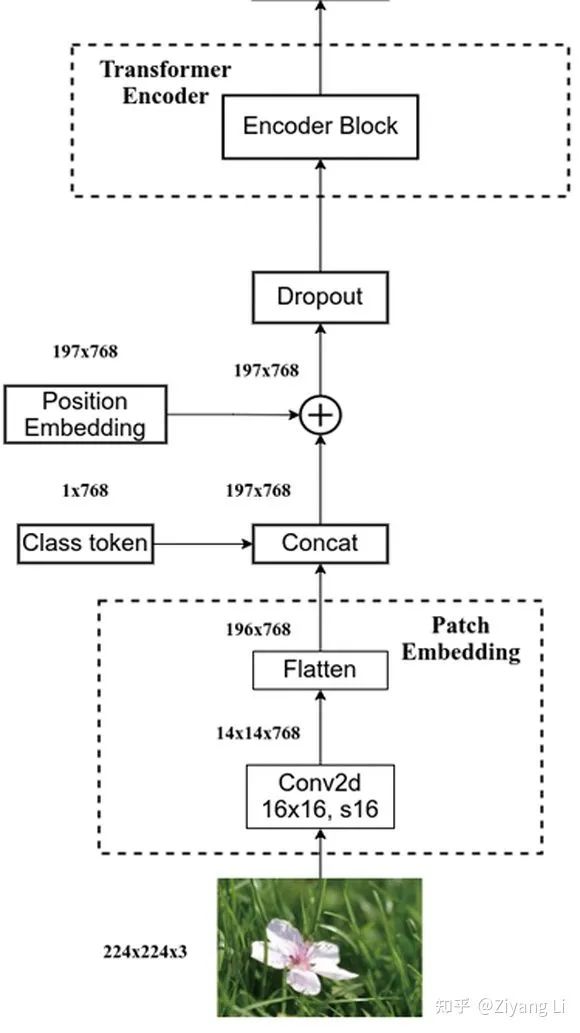
经过上述操作后,我们得到了想要的数据
1.3 Transformer Encoder
在图一的中间部分,我们可以看到之前经过处理的 被输入到了Transformer Encoder层,而该层的具体结构正如图一右侧所示,即下图:
被输入到了Transformer Encoder层,而该层的具体结构正如图一右侧所示,即下图:
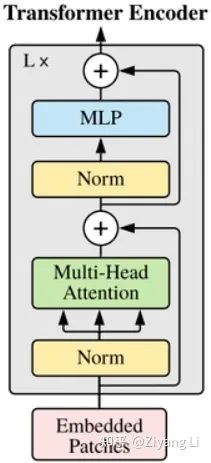
我们的
与Transformer类似,我们这里的多头是什么意思呢?
同样的,我们想让模型学习全方位、多层次、多角度的信息,学习更丰富的信息特征,对于同一张图片来说,每个人看到的、注意到的部分都会存在一定差异,而在图像中的多头恰恰是把这些差异综合起来进行学习。
1.4 MLP Head
结束了Transformer Encoder,就到了我们最终的分类处理部分,在之前我们进行Encoder的时候通过concat的方式多加了一个用于分类的可学习向量,这时我们把这个向量取出来输入到MLP Head中,即经过Layer Normal --> 全连接 --> GELU --> 全连接,我们得到了最终的输出。
这里作者经过实验选取了GELU作为激活函数
03
2.1 库导入
import torchfrom torch import nnfrom einops import rearrange, repeatfrom einops.layers.torch import Rearrange
这里的einops在我们后续对图像进行块切割时候会用到。
2.2 模型主体
def pair(t):return t if isinstance(t, tuple) else (t, t)class ViT(nn.Module):def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool='cls', channels=3, dim_head=64, dropout=0., emb_dropout=0.):super().__init__()image_height, image_width = pair(image_size)patch_height, patch_width = pair(patch_size)assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'num_patches = (image_height // patch_height) * (image_width // patch_width)patch_dim = channels * patch_height * patch_widthassert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'self.to_patch_embedding = nn.Sequential(Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=patch_height, p2=patch_width),nn.Linear(patch_dim, dim),)self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))self.cls_token = nn.Parameter(torch.randn(1, 1, dim))self.dropout = nn.Dropout(emb_dropout)self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)self.pool = poolself.to_latent = nn.Identity()self.mlp_head = nn.Sequential(nn.LayerNorm(dim),nn.Linear(dim, num_classes))def forward(self, img):x = self.to_patch_embedding(img)b, n, _ = x.shapecls_tokens = repeat(self.cls_token, '() n d -> b n d', b=b)x = torch.cat((cls_tokens, x), dim=1)x += self.pos_embedding[:, :(n + 1)]x = self.dropout(x)x = self.transformer(x)x = x.mean(dim=1) if self.pool == 'mean' else x[:, 0]x = self.to_latent(x)return self.mlp_head(x)
从forward部分开始,我们可以看到输入的img依次经过了patch_embedding --> concat_cls_tokens --> add_pos_embedding --> transformer --> mlp_head,下面我们对这几个部分进行逐一介绍:
2.2.1 patch_embedding
self.to_patch_embedding = nn.Sequential(Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=patch_height, p2=patch_width),nn.Linear(patch_dim, dim),)
这一步通过Rearrange将输入为[b, c, h, w]的图片切分为大小为p1*p2的图片块,同时通过Linear将维度从patch_dim缩放到dim。
2.2.2 concat_cls_tokens
经过上一步后我们通过:
b, n, _ = x.shape得到了输入图片的数量b,以及经过切分后的图片块总数n。
接下来我们通过Parameter来生成一个可学习的变量:
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))一个肯定是不够的,我们通过repeat方法进行重复:
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b=b) # shape为[batch_size, 1, dim]这样就生成了一个shape为[b,1,dim]的向量,我们只需将其与原矩阵concat即可
x = torch.cat((cls_tokens, x), dim=1)这里需要注意,经过concat后我们的n变为n+1,会在下面的添加位置信息时用到。
2.2.3 add_pos_embedding
与生成可学习的
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))接下来我们只需通过逐元素加和的方式添加到原矩阵中去即可
x += self.pos_embedding[:, :(n + 1)]至此数据处理部分结束,接下来我们就要把X输入到Transformer中去了。
2.3 Transformer部分
这一部分我单独拎出来讲解,首先上代码:
class Transformer(nn.Module):def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout=0.):super().__init__()self.layers = nn.ModuleList([])for _ in range(depth):self.layers.append(nn.ModuleList([PreNorm(dim, Attention(dim, heads=heads, dim_head=dim_head, dropout=dropout)),PreNorm(dim, FeedForward(dim, mlp_dim, dropout=dropout))]))def forward(self, x):for attn, ff in self.layers:x = attn(x) + xx = ff(x) + xreturn x
这里的depth为Transformer Encoder的堆叠次数,也即该部分深度,我们使用ModuleList既保持代码整洁又实现了模块堆叠。
继续往下看可以发现每一层其实都是一个同样的结构,即Attention部分 --> PreNorm --> Feed Forward部分 --> PreNorm。那么我们就分别来看一下这几步的具体代码。
首先来看Attention部分:
class Attention(nn.Module):def __init__(self, dim, heads=8, dim_head=64, dropout=0.):super().__init__()inner_dim = dim_head * headsproject_out = not (heads == 1 and dim_head == dim)self.heads = headsself.scale = dim_head ** -0.5self.attend = nn.Softmax(dim=-1)self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False)self.to_out = nn.Sequential(nn.Linear(inner_dim, dim),nn.Dropout(dropout)) if project_out else nn.Identity()def forward(self, x):qkv = self.to_qkv(x).chunk(3, dim = -1)q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=self.heads), qkv)dots = torch.matmul(q, k.transpose(-1, -2)) * self.scaleattn = self.attend(dots)out = torch.matmul(attn, v)out = rearrange(out, 'b h n d -> b n (h d)')return self.to_out(out)
从代码中不难看出,我们输入的X经过变换生成Q、K、V
Q×K计算关联性后进行一个 dim_head ** -0.5的维度缩放(此部分在Transformer中有介绍到),紧接着通过softmax计算权值再与原矩阵V相乘得到out,最后out经过一个全连接层进行最终的输出。
接下来是PreNorm部分:
class PreNorm(nn.Module):def __init__(self, dim, fn):super().__init__()self.norm = nn.LayerNorm(dim)self.fn = fndef forward(self, x, **kwargs):return self.fn(self.norm(x), **kwargs)
这一部分非常简单,所要实现的就是一个层归一化处理,这里不做过多介绍。
最后来到Feed Forward部分:
class FeedForward(nn.Module):def __init__(self, dim, hidden_dim, dropout=0.):super().__init__()self.net = nn.Sequential(nn.Linear(dim, hidden_dim),nn.GELU(),nn.Dropout(dropout),nn.Linear(hidden_dim, dim),nn.Dropout(dropout))def forward(self, x):return self.net(x)
从代码中可以看出,我们输入的X进入到容器中,进行了一次全连接 --> GELU --> 全连接的变换
接下来对于Feed Forward的输入,我们还要做一次层归一化处理。
在Transformer Encoder部分,这样的模块堆叠depth次后,我们来到了最终的分类层。
2.4 MLP Head
在进入分类头之前,我们需要把之前额外添加的分类专属向量单独提取出来:
x = x.mean(dim=1) if self.pool == 'mean' else x[:, 0]在我们concat后,这个向量就是处于下标为0的位置,故提取时只需输入x[:, 0]即可。这里的mean是我们在输入时的可选择项(在2.2 模型主体部分的代码中)
分类头其实就是一个全连接层:
self.mlp_head = nn.Sequential(nn.LayerNorm(dim),nn.Linear(dim, num_classes))
最终的num_classes即我们所需的图像类别数,至此整个VIT的代码讲解完毕。
04
本文对于Transformer部分的代码讲解不是足够细致,只因其不是本文讲解重点(后续会对本文Transformer部分代码讲解做出更新与改进),现有VIT模型的性能还需大量数据来训练(在论文中也有提出,小规模数据集的表现并不是很好),但作为继DERT后的又一项CV与NLP结合的工作,引爆热度是毋庸置疑的。
笔者才疏学浅,望广大读者批评指正,不吝赐教!
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》