
(附论文) CVPR 2021轻量化目标检测模型MobileDets
点击左上方蓝字关注我们

论文:https://arxiv.org/pdf/2004.14525v1.pdf

1简介
构建在深度卷积上的Inverted bottleneck layers已经成为移动设备上最先进目标检测模型的主要构建模块。在这项工作中,作者通过回顾常规卷积的实用性,研究了这种设计模式在广泛的移动加速器上的最优性。
作者研究发现,正则卷积是一个强有力的组件,以提高延迟-准确性权衡目标检测的加速器,只要他们被放置在网络通过神经结构搜索。通过在搜索空间中合并Regular CNN并直接优化目标检测的网络架构,作者获得了一系列目标检测模型,MobileDets,并在移动加速器中实现了最先进的结果。
在COCO检测任务上,在移动CPU上MobileDets比MobileNetV3+SSDLite提升了1.7 mAP。MobileDets比MobileNetV2+SSDLite提升了1.9mAP,
在不增加延迟的情况下,在谷歌EdgeTPU上提升了3.7 mAP,在Qualcomm Hexagon DSP上提升了3.4 mAP,在Nvidia Jetson GPU上提升了2.7 mAP。此外,MobileDets即使不使用金字塔也可以在移动cpu上媲美最先进的MnasFPN,并在EdgeTPUs和dsp上实现更好的mAP分数以及高达2倍的加速。
本文主要贡献
不像许多现有的专门针对移动应用的IBN层的工作,本文提出了一种基于正则卷积构建块的增强搜索空间系列。证明了NAS方法可以从这种扩大的搜索空间中获得很大的收益,从而在各种移动设备上实现更好的延迟-准确性权衡。
提供了MobileDets,一组在多个硬件平台(包括手机)上具有最先进的Mobile目标检测模型。
2前人工作
2.1 Mobile Object Detection
物体检测是一个经典的计算机视觉任务,其目标是学习识别图像中感兴趣的物体。现有的目标检测器可分为2类:
Two-Stage检测器 One-Stage检测器
对于Two-Stage检测器,包括Faster RCNN, R-FCN和ThunderNet,在检测器做出任何后续预测之前,必须首先生成区域建议。由于这种多阶段的特性,Two-Stage检测器在推理时间方面并不高效。
另一方面,One-Stage检测器,如SSD、SSDLite、YOLO、SqueezeDet和Pelee,只需要通过一次网络就可以预测所有的边界框,使其成为边缘设备高效推断的理想候选。因此,在这项工作中将重点放在One-Stage检测器上。
SSDLite是SSD的一个有效变体,它已经成为最流行的轻量级检测器之一。它非常适合移动设备上的应用。高效的backbone,如MobileNetV2、MobileNetV3,与SSDLite配对,以实现最先进的移动检测结果。这两个模型将被用作baseline,以证明所提出的搜索空间在不同移动加速器上的有效性。
2.2 Mobile Neural Architecture Search (NAS)
NetAdapt和AMC是第一批尝试利用延迟感知搜索来微调预训练模型的通道数量的公司。MnasNet和MobileNetV3扩展了这一想法,以便在NAS框架中找到资源效率高的架构。通过技术的组合,MobileNetV3在移动CPU上提供了最先进的架构。作为一个互补的方向,最近有许多致力于提高NAS的搜索效率的工作。
2.3 NAS for Mobile Object Detection
大部分NAS文献主要集中于分类,只将学习到的特征提取器作为目标检测的backbone,而没有进一步的搜索。最近,多篇论文表明,通过直接搜索目标检测模型可以获得更好的延迟-精度权衡。
MnasFPN是移动检测模型的一个强大的检测NAS Baseline,它使用对移动友好的搜索空间搜索特征金字塔,极大地利用了深度可分离卷积。但是一九八存在几个因素限制了它在移动加速器上的推广:
到目前为止,深度卷积和特征金字塔在这些平台上都没有得到很好的优化,
MnasFPN不搜索backbone,这是延迟的瓶颈。
相比之下,本文的工作依赖于SSD Heads,并提出了基于全卷积Backbone的搜索空间,更易于接受移动加速。
3重新回顾全卷积移动搜索空间
Are IBNs all we need ?
Inverted Bottleneck(IBN)的布局如图2所示。IBN的设计目的是减少参数和FLOPS的数量,并利用depthwise和pointwise(1x1)卷积在移动cpu上实现高效率。
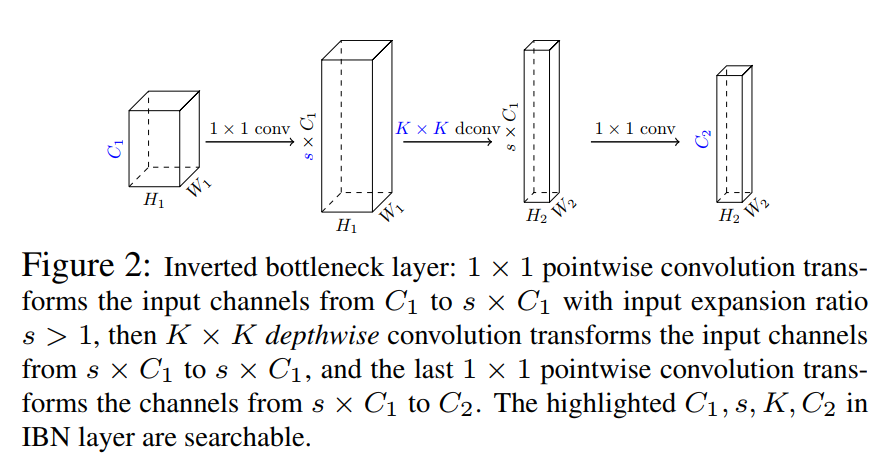
然而,并非所有的FLOPS都是一样的,特别是对于EdgeTPU和dsp这样的现代移动加速器来说。例如,一个常规的卷积在EdgeTPUs上的运行速度可能比它的深度变化快3倍,即使它有7倍的FLOPS。
观察结果表明,目前广泛使用的IBN-only搜索空间对于现代移动加速器来说可能是次优的。这促使本文通过重新访问规则(完全)卷积来提出新的构建块,以丰富移动加速器的IBN-only搜索空间。具体来说,提出了2个灵活的层分别进行通道扩展和压缩,具体如下。
3.1 融合IBN层(扩展)
深度可分离卷积是IBN的关键(图2)。深度可分离卷积背后的想法是将深度卷积(用于空间维度)和点卷积(用于通道维度)的组合代替复杂的全卷积。
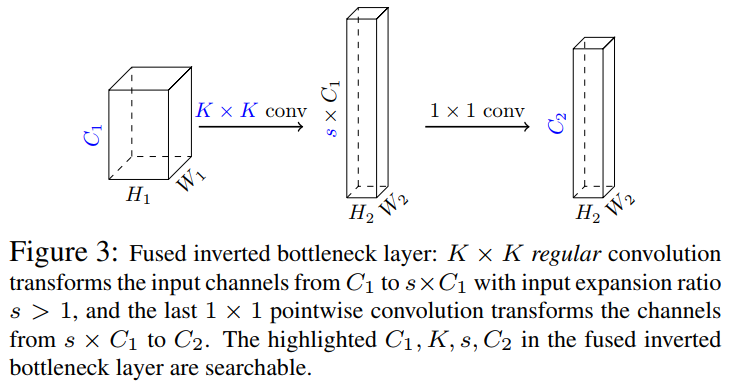
然而,复杂的概念在很大程度上是基于FLOPS或参数的数量来定义的,这与现代移动加速器的推理效率不一定相关。为了整合卷积,作者提出对IBN层进行修改,将其前卷积和随后的深度卷积融合为单个正则卷积(图3)。融合IBN的初始卷积使Kernel的数量增加了一个因子;这一层的扩展比例由NAS算法决定。
3.2 Tucker卷积层(压缩)
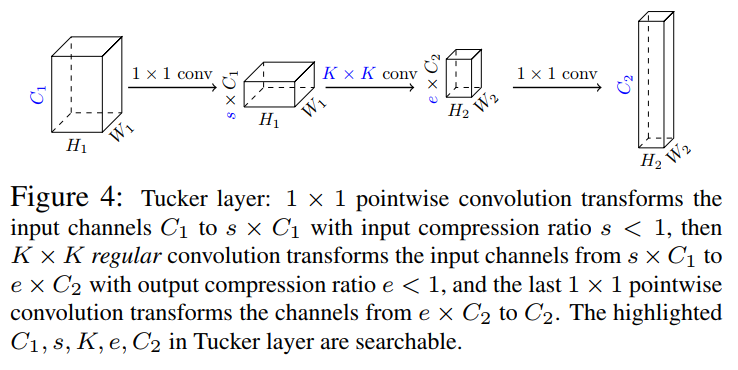
在ResNet中引入瓶颈层,降低了在高维特征图上进行大卷积的消耗。压缩比s<1的瓶颈层有:
输入通道为输出通道为的1×1卷积; 输入通道为输出通道为的K×K卷积; 输入通道为输出通道为的1×1卷积;
作者概括了这些瓶颈(图4)通过允许初始1×1卷积比K×K卷积有不同数量的输出卷积核,并让NAS算法决定最终的最佳配置。
作者将这些新的构建块称为Tucker卷积层,因为它们与Tucker分解有关。
4架构搜索方法
本文提出的搜索空间是互补的任何神经结构搜索算法。
在实验中使用了TuNAS,因为它的可伸缩性和相对于随机baseline的可靠改进。TuNAS构建了一个one-shot模型,该模型包含给定搜索空间中的所有架构选择,以及一个控制器,其目标是选择优化平台感知的奖励功能的架构。
在搜索过程中,one-shot模型和控制器一起训练。在每一步中,控制器从跨越选择的多项分布中抽样一个随机体系结构,然后更新与抽样体系结构相关的one-shot模型权值的部分,最后计算抽样体系结构的奖励,用于更新控制器。更新内容是通过对以下奖励功能应用强化算法来实现的:
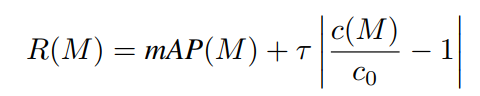
Cost Models
作者训练了一个Cost Model,——一个线性回归模型,它的特征是,对于每一层,输入/输出通道规模和层类型之间的交叉乘积的指标。该模型跨平台高保真度。线性代价模型与之前提出的基于查找表的方法有关,但只要求在搜索空间内对随机选取的模型的延迟进行基准测试,而不要求度量卷积等单个网络操作的cost。
因为R(M)是在每次更新步骤时计算的,所以效率是关键。在搜索过程中,本文基于一个小型的小批处理估计了mAP(M)的效率,并使用回归模型作为设备上延迟c(M)的替代。为了收集成本模型的训练数据,本文从搜索空间随机抽取数千个网络架构,并在设备上对每个架构进行基准测试。这在每个硬件和搜索之前只执行一次,消除了服务器类ML硬件和移动设备之间直接通信的需要。对于最终的评估,所找到的体系结构将基于实际硬件测试而不是成本模型进行基准测试。
5实验
5.1 不同硬件的实验
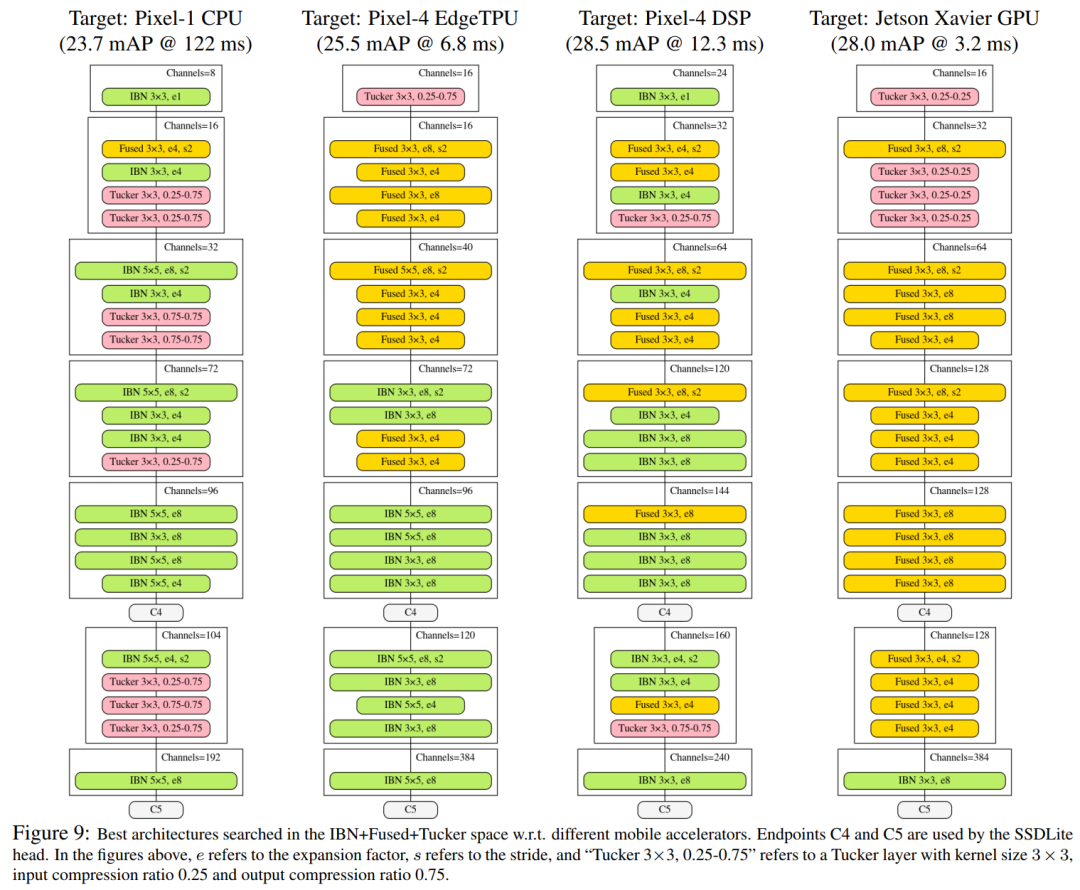
CPU
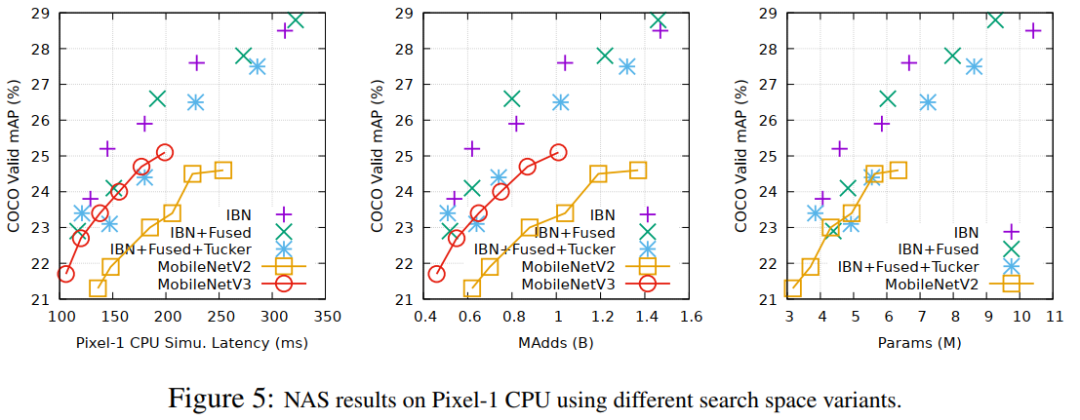
图5显示了pixel-1 cpu的NAS结果。正如预期的那样,MobileNetV3+SSDLite是一个强大的baseline,因为它的backbone的效率已经在相同的硬件平台上对ImageNet上的分类任务进行了大量优化。作者还注意到,在这种特殊情况下,常规卷积并没有提供明显的优势,因为IBN-only在FLOPS/CPU延迟下已经很强大了。然而,w.r.t.进行特定领域的体系结构搜索,目标检测任务在COCO上提供了不小的收益(150-200ms范围内的+1mAP)。
EdgeTPU
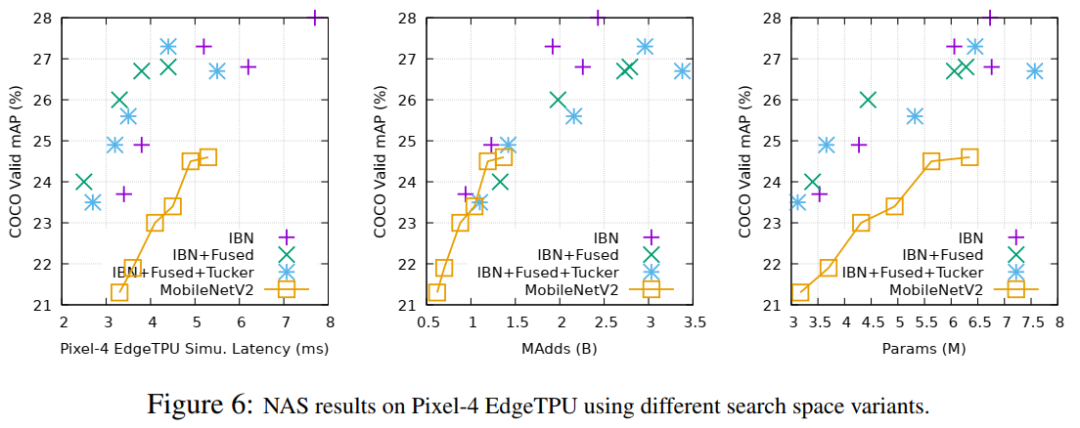
图6显示了以Pixel-4 EdgeTPUs为目标时的NAS结果。使用这3种搜索空间中的任何一种进行硬件感知的体系结构搜索,都能显著提高整体质量。这很大程度上是由于baseline架构(MobileNetV2)1对CPU延迟进行了大量优化,这与FLOPS/MAdds密切相关,但与EdgeTPU延迟没有很好地校准。值得注意的是,虽然IBN-only仍然提供了最好的准确性-madds权衡(中间图),但在搜索空间中使用常规卷积(IBN+Fused或IBN+Fused+Tucker)在准确性-延迟权衡方面提供了明显的进一步优势。实验结果证明了完全卷积在EdgeTPUs上的有效性。
DSP
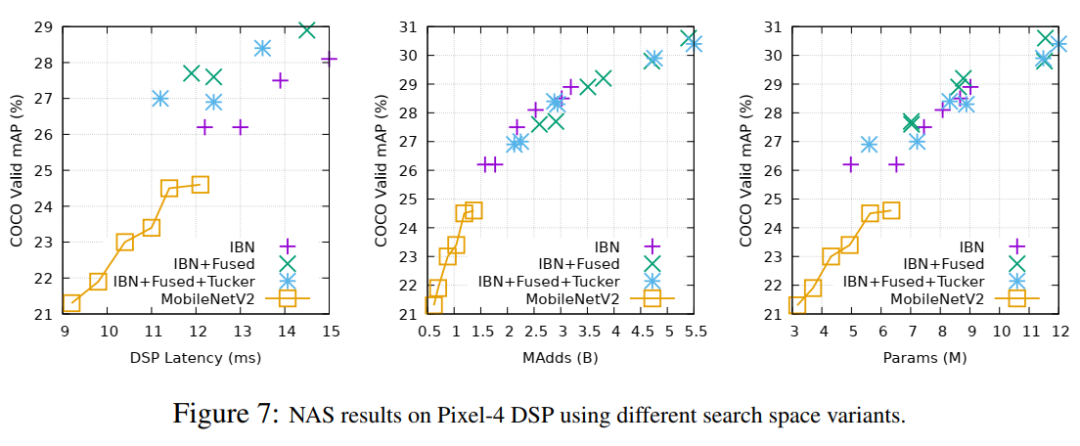
图7显示了Pixel-4 DSP的搜索结果。与EdgeTPUs类似,很明显,在搜索空间中包含规则卷积可以在相当的推断延迟下显著改善mAP。
5.2 SOTA对比结果

6参考
[1].MobileDets: Searching for Object Detection Architectures for Mobile Accelerators
END
整理不易,点赞三连↓