
机器学习避坑指南:训练集/测试集分布一致性检查
↑↑↑点击上方蓝字,回复资料,10个G的惊喜
工业界有一个大家公认的看法,“数据和特征决定了机器学习项目的上限,而算法只是尽可能地逼近这个上限”。在实战中,特征工程几乎需要一半以上的时间,是很重要的一个部分。
缺失值处理、异常值处理、数据标准化、不平衡等问题大家应该都已经手到擒来小菜一碟了,本文我们探讨一个很容易被忽视的坑:数据一致性。

众所周知,大部分机器学习算法都有一个前提假设:训练数据样本和位置的测试样本来自同一分布。如果测试数据的分布跟训练数据不一致,那么就会影响模型的效果。

在一些机器学习相关的竞赛中,给定的训练集和测试集中的部分特征本身很有可能就存在分布不一致的问题。实际应用中,随着业务的发展,训练样本分布也会发生变化,最终导致模型泛化能力不足。
下面就向大家介绍几个检查训练集和测试集特征分布一致性的方法:
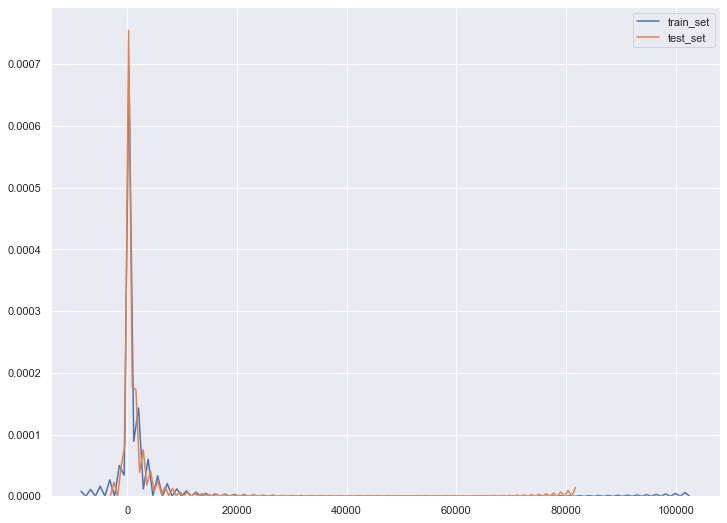
KDE(核密度估计)分布图
核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一,通过核密度估计图可以比较直观的看出数据样本本身的分布特征。
seaborn中的kdeplot可用于对单变量和双变量进行核密度估计并可视化。
看一个小例子:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
train_set=pd.read_csv(r'D:\...\train_set.csv')
test_set=pd.read_csv(r'D:\...\test_set.csv')
plt.figure(figsize=(12,9))
ax1 = sns.kdeplot(train_set.balance,label='train_set')
ax2 = sns.kdeplot(test_set.balance,label='test_set')
KS检验(Kolmogorov-Smirnov)
KS检验是基于累计分布函数,用于检验一个分布是否符合某种理论分布或比较两个经验分布是否有显著差异。两样本K-S检验由于对两样本的经验分布函数的位置和形状参数的差异都敏感,所以成为比较两样本的最有用且最常用的非参数方法之一。
我们可以使用 scipy.stats 库中的ks_2samp,进行KS检验:
from scipy.stats import ks_2samp
ks_2samp(train_set.balance,test_set.balance)
ks检验一般返回两个值:第一个值表示两个分布之间的最大距离,值越小即这两个分布的差距越小,分布也就越一致。第二个值是p值,用来判定假设检验结果的一个参数,p值越大,越不能拒绝原假设(待检验的两个分布式同分布),即两个分布越是同分布。
Ks_2sampResult(statistic=0.005976590587342234, pvalue=0.9489915858135447)
最终返回的结果可以看出,balance这个特征在训练集测试集中服从相同分布。
对抗验证(Adversarial validation)
除了 KDE 和 KS检验,目前比较流行的是对抗验证,它并不是一种评估模型效果的方法,而是一种用来确认训练集和测试集的分布是否变化的方法。
具体做法:
1、将训练集、测试集合并成一个数据集,新增一个标签列,训练集的样本标记为 0 ,测试集的样本标记为 1 。
2、重新划分一个新的train_set和test_set(区别于原本的训练集和测试集)。
3、用train_set训练一个二分类模型,可以使用 LR、RF、XGBoost、 LightGBM等等,以AUC作为模型指标。
4、如果AUC在0.5左右,说明模型无法区分原训练集和测试集,也即两者分布一致。如果AUC比较大,说明原训练集和测试集差异较大,分布不一致。
5、利用第 2 步中的分类器模型,对原始的训练集进行打分预测,并将样本按照模型分从大到小排序,模型分越大,说明与测试集越接近,那么取训练集中的 TOP N 的样本作为目标任务的验证集,这样即可将原始的样本进行拆分得到训练集,验证集,测试集。
除了确定训练集和测试集特征分布一致性,对抗验证还可以用来做特征选择。大家感兴趣的话可以给个点赞+在看,下一讲《特征选择》,我们用实例来看看对抗验证的具体用法和效果。
加老胡微信,围观朋友圈
推荐阅读
