
解读困扰ML50年的问题!ICLR 2021接受论文:Google AI全新视角理解「泛化」
新智元
共 4177字,需浏览 9分钟
·
2021-03-16 13:05

新智元报道
新智元报道
来源:Google AI Blog
编辑:LQ、PY
【新智元导读】许多数学工具可以帮助研究人员理解某些模型中的泛化。但在现实环境中,现有的大多数理论在应用于现代深层网络时都失败了,这些理论既空洞又无法预测。在ICLR 2021接受的「深度启动框架:优秀的在线学习者是优秀的离线概括器」中,Google AI Blog提出了一个新的框架,用于通过将广义化与在线优化领域联系来解决此问题。
Deep Bootstrap框架
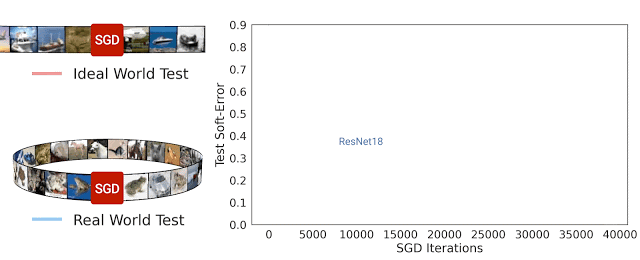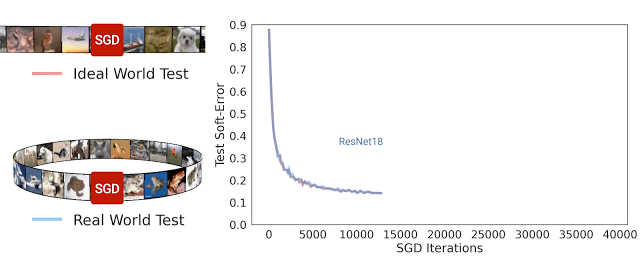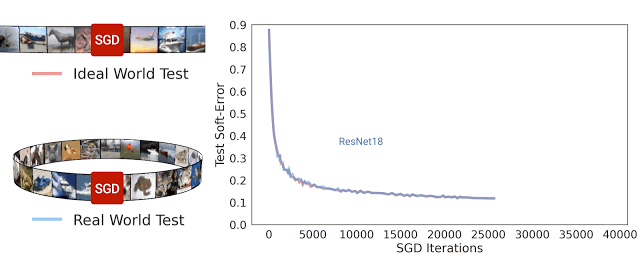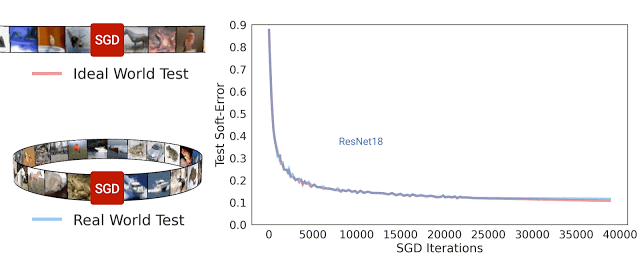

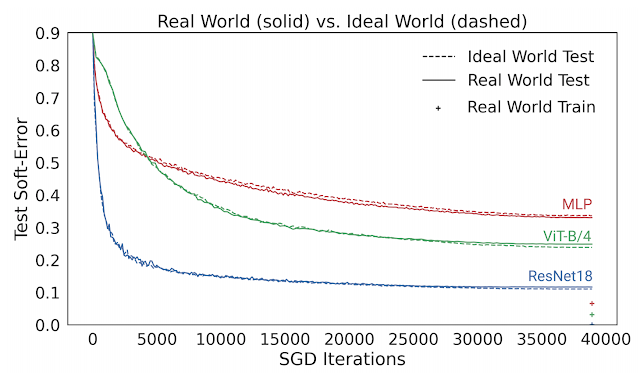
从优化行为理解泛化
应用Deep Bootstrap框架
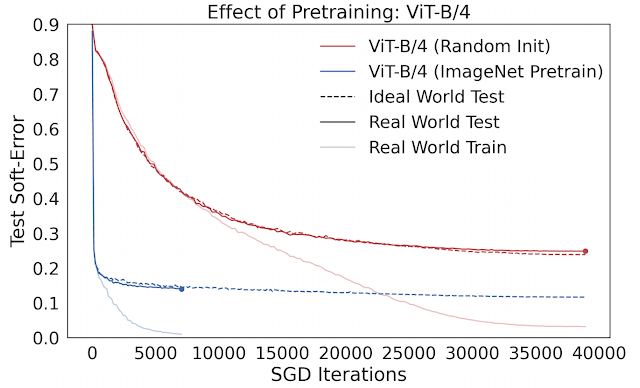 预训练的效果——在理想世界中,预训练的ViT优化得更快
预训练的效果——在理想世界中,预训练的ViT优化得更快结语
参考资料:https://ai.googleblog.com/

评论