
ICLR 2021 | 腾讯 AI Lab 入选论文解读
感谢阅读腾讯AI Lab微信号第120篇文章。本文将介绍解读7篇 ICLR 2021 腾讯 AI Lab 入选论文。
ICLR(International Conference on Learning Representations),即国际学习表征会议,由深度学习三巨头之二的 Yoshua Bengio 和 Yann LeCun 于2013年创立。尽管起步晚,但其影响力已不容小觑:它被誉为“深度学习的顶级会议”,受到学术研究者们的广泛认可,谷歌学术 h5 指数已经排到了全榜第 17 名,超过了 NeurIPS、ICCV、ICML。
日前它放出了今年的论文接收结果。ICLR 2021 共收到 2997 篇有效投稿,最终接收 860 篇,其中 53 篇为 Oral 论文,114 篇 Spotlight 论文,其余为 Poster 论文。接收率为 29%,相比去年的 26.5% 有所提升。
腾讯 AI Lab 共 7 篇论文被 ICLR 2021 收录,其中包括一篇 Spotlight 展示论文,涵盖腾讯 AI Lab 在机器学习和自然语言处理两大重点方向的研究成果。以下为详细解读。
Spotlight
1.针对医疗图像的一种稳定性对抗攻击方法
Stabilized Medical Image Attacks
本文由腾讯 AI Lab 和腾讯天衍实验室合作完成。深度神经网络使得医疗图像的自动诊疗的性能得到大幅提升。然而深度神经网络会带来对抗攻击的脆弱性等困难。因此针对普适医疗图像的对抗攻击具有明确的意义,可以有效进行分析并避免自动诊疗中带来的误判问题。
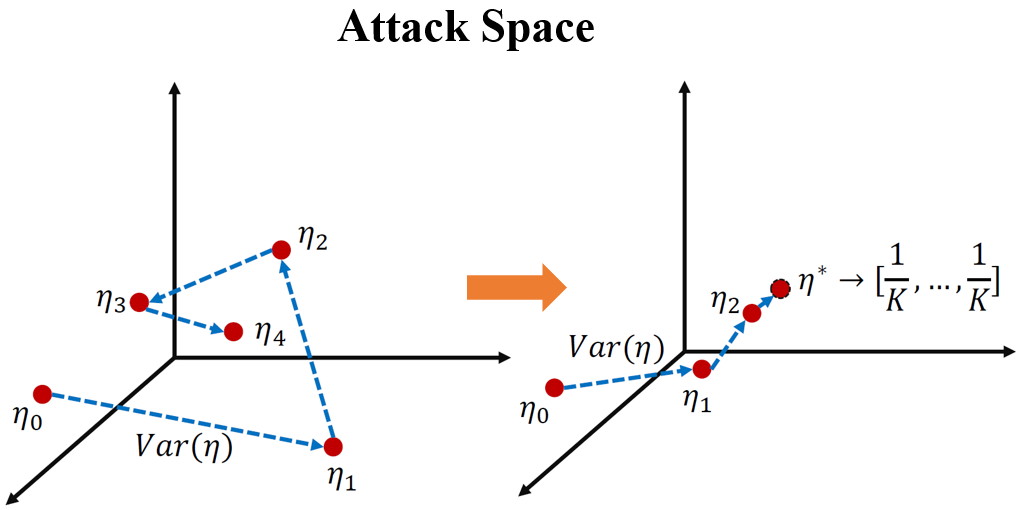
本文在现有针对自然图像的对抗攻击基础上,提出一个稳定性约束项。在对抗扰动迭代计算的过程中,该约束项衡量当前扰动和之前扰动的相似性。从KL散度的角度来看,该约束项使得对抗攻击将网络的输出引入一个错误而固定的结果。该结果不受网络结构和数据类型的影响。
在若干医疗图像分析的数据库中(包括最近的新冠数据库COVID-19),我们的方法能够稳定而有效的攻击现有的自动诊疗神经网络系统。本研究可用于分析自动医疗图像诊疗的潜在风险。例如由于医疗设备受污染带来的诊疗误判情况,以及人为的医疗保险欺诈等问题。
机器学习
本方向3篇论文,分别探索对抗攻击、图深度学习、离线强化学习等主题。
1.基于图信息瓶颈的子图识别
Graph Information Bottleneck for Subgraph Recognition
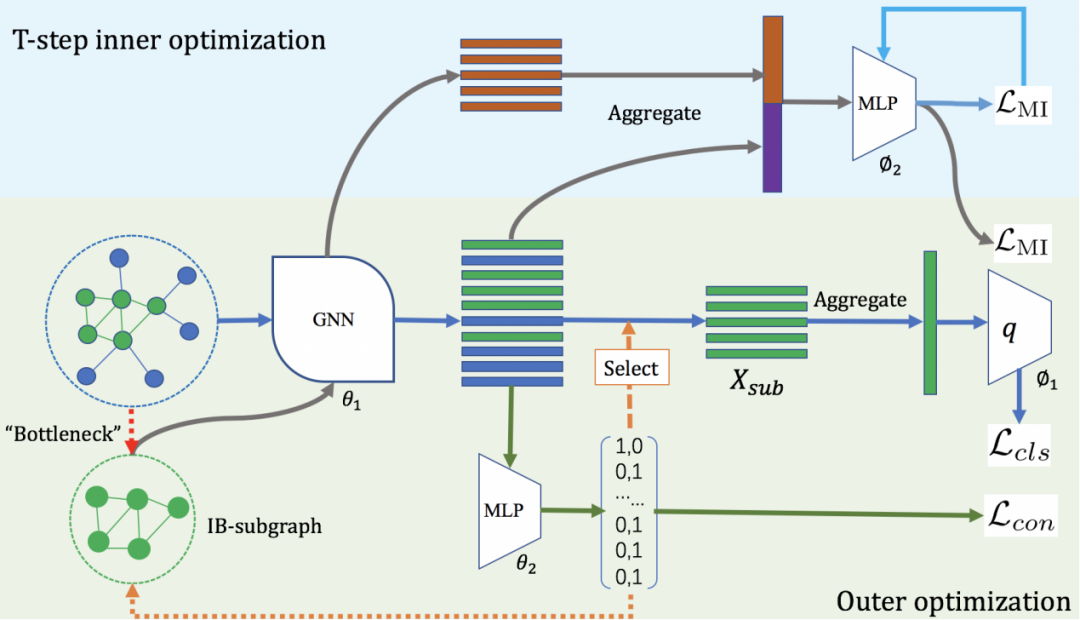
本文由腾讯 AI Lab 和中国科学院自动化研究所合作完成。图分类、药物分子官能团发掘、图数据去噪等任务都可以归结为寻找一个与原图标签最为相关且滤除噪声结构的子图。然而监督学习需要利用子图层面的标签,且图的不规则离散结构对算法优化带来了挑战。
本文基于信息瓶颈理论提出了信息瓶颈子图的概念和图信息瓶颈算法,并针对图的不规则离散结构提出了二层互信息优化算法与连续化松弛方法。基于该算法,不需要显式的子图标签即可有效识别这种子图。
实验表明,该算法能有效提高多种图分类算法的精度;在分子数据集上,该算法能够准确识别最能影响药物分子属性的子结构;此外,该算法对于有噪声的图分类任务有较好的鲁棒性。
本文在图深度学习中开拓出了一个子图识别的新的研究领域,并在药物发现中起到了一定的辅助分析的作用。其中结合信息瓶颈理论来解决图问题的思路也对今后的相关研究有借鉴意义。
想了解更多关于图深度学习的信息,可阅读文章:腾讯AI Lab联合清华、港中文,万字解读图深度学习历史、最新进展与应用
2.通过反转有限权重比特实现深度神经网络的有目标攻击
Targeted Attack Against Deep Neural Networks via Flipping Limited Weight Bits
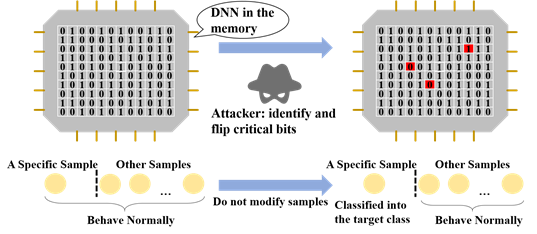
为了探索深度学习的脆弱性进而获取更加安全的深度模型,研究者们提出了许多的攻击范式,例如在训练阶段使用基于数据投毒的后门攻击、在推断阶段使用的对抗攻击。
本文研究了一种新的攻击范式,即通过修改部署的模型参数来达到恶意目的。我们的攻击目标为:将一个指定样本分类到目标类别(不对此样本进行修改),同时不显著降低模型在其他样本上的性能。由于网络参数在内存中是以二进制比特存储的,因此我们将识别重要比特问题形式化定义为二元整数规划问题,给出了带有约束的目标函数。
利用最新的整数规划算法,我们进一步给出了一种高效的优化方法。实验表明,该方法在多个数据集上表现显著优于启发式的方法。本研究可用于评估当前深度模型参数的鲁棒性,识别应用中的潜在安全隐患,进而促进更加安全的模型开发与部署。
3.一种基于距离度量学习及行为正则化的完全离线的元强化学习方法
Efficient Fully-Offiline Meta-Reinforcement Learning via Distance Metric Learning and Behavior Regularization
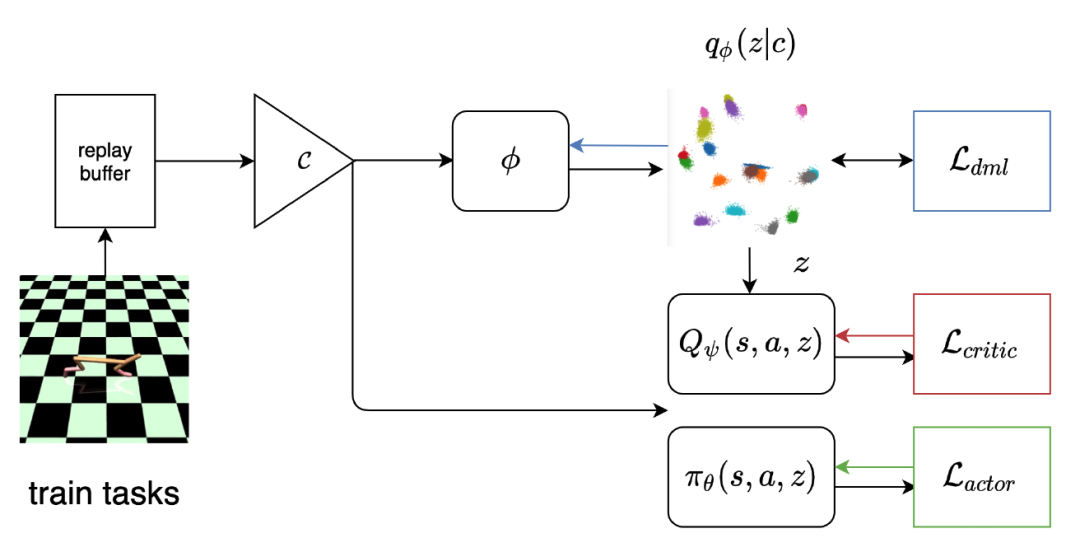
本文由腾讯 AI Lab 主导,与清华大学合作完成,主要研究离线元强化学习(OMRL)问题。离线元强化学习作为一种新颖的范式,可以让智能体以完全不与环境交互的方式快速适应新的未知任务,极大地提升了强化学习算法在真实世界中的应用范围和价值。围绕这一问题目前的相关研究还较少,并且有两个主要的技术难点。其一,离线强化学习中通常会因为训练数据与所学习策略的状态-动作对的分布偏移而产生较大误差,甚至导致价值函数的发散。其二,元强化学习要求在学习控制策略的同时能高效且鲁棒地进行任务推断(task inference)。
在本文中,我们将针对离线策略学习的行为正则化(behavior regularization)方法,与一个用于任务推断的确定性的任务信息编码器进行结合来解决上述的两大难点。我们在有界的任务信息嵌入空间中引入了一个全新的负指数距离度量,并且将其与控制策略的贝尔曼方程的梯度解耦进行学习。我们分析验证了在该设定下,采用一些简单的算法设计即可带来相比经典元强化学习及度量学习的效果的明显提升。据我们所知,本方法是第一个端到端、无模型的离线元强化学习算法,计算效率高并且在多个元强化学习实验环境上表现出优于以往方法的性能。
本方法赋予强化学习算法进行离线学习及高效迁移的能力,离线意味着不需要在真实环境中进行探索、交互,高效迁移意味着算法的鲁棒性及数据利用效率更高。我们的方法实现了同时具备上述两种能力的端到端的算法训练框架,可以极大扩展强化学习算法的实际应用范围:例如推动其在诸如医疗、农业、自动驾驶等数据稀缺或极度重视安全性的相关领域的实际应用,包括构建定制化的患者治疗方案、针对特定气候/作物品种的温室种植策略等。
自然语言处理
本方向3篇论文,分别关注命名实体识别、非自回归翻译(NAT)、编码器特征融合(EncoderFusion)等子领域。
1.命名实体识别中漏标实体问题的分析与解决
Empirical Analysis of Unlabeled Entity Problem in Named Entity Recognition
本文由腾讯 AI Lab 独立完成。在许多场景(如弱监督)中,命名实体识别(NER)模型严重地受到漏标实体问题的影响。漏标实体是指在训练数据中真实存在但在标注过程中遗漏的实体。通过在合成数据集上的大量实验,我们发现了模型效果变差的两个原因。一个是标注实体的减少,另一个是错误地将漏标实体当成负例。前一个原因影响较小而且可以通过使用预训练语言模型改善。第二个原因则在训练时严重地误导了模型并因此极大的影响了效果。
基于这些发现,我们提出了一种通用且可以消除漏标实体误导的方法。我们的核心思想就是基于负采样使得训练时遇到漏标实体的概率非常低。在合成数据和真实数据(如NEWS)上的实验表明我们的模型对漏标实体问题非常鲁棒并且远远好于之前的方法。我们在正常数据(如CoNLL-2003)的表现也非常接近目前最好的效果,可分析并解决命名实体识别中的漏标实体问题。
2.从理解到改进:非自回归翻译中的词汇选择
Understanding and Improving Lexical Choice in Non-Autoregressive Translation
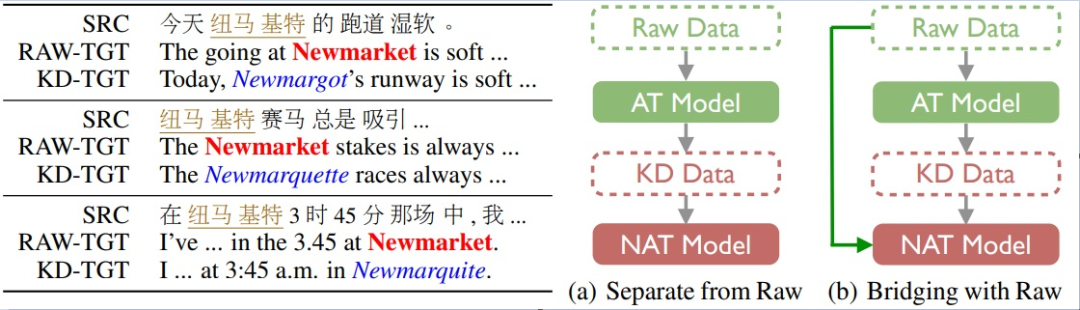
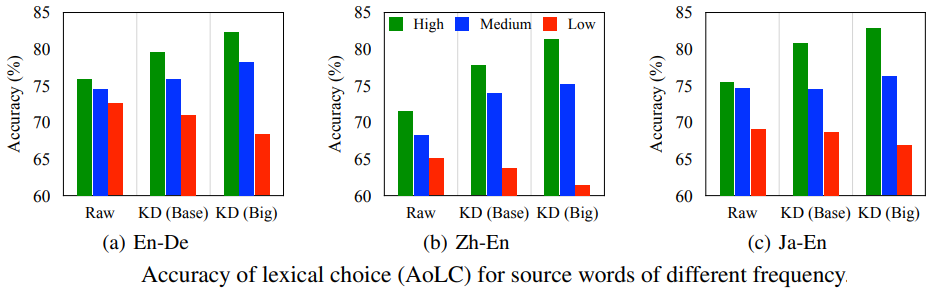
本文由腾讯 AI Lab 主导,与悉尼大学、澳门大学合作完成。非自回归翻译(NAT)是目前最受关注的机器翻译子领域之一。由于NAT模型摆脱了自回归分解的条件,一方面解码速度得到了很大提升,但另一方面翻译性能弱于传统的自回归翻译(AT)模型。目前NAT训练需要借助知识蒸馏(KD)技术来降低原始数据的复杂性,从而得到与AT可比的翻译质量。通过定性和定量的分析,我们揭示了KD的副作用:使原始数据的分布更加不平衡,从而带来了严重的词汇选择错误(特别是低频词)。
为了缓解该问题,我们提出将原始数据暴露给NAT模型,以恢复蒸馏数据中被遗漏的低频信息。为此,我们引入了一个额外的KL散度项来约束NAT模型和原始数据中的词汇选择。实验结果表明,该方法在多种语言对和模型结构上能够有效地、通用地提升翻译质量。大量分析证实该方法通过减少低频词的词汇选择错误来提高整体性能。令人鼓舞的是,我们在WMT14英德和WMT16罗英数据集上将SOTA NAT效果分别提高到27.8和33.8 BLEU值。
非自回归翻译(NAT)是目前最受关注的机器翻译子领域之一。NAT模型有快速解码优势但其性能却弱于传统的自回归翻译方法。围绕提升NAT的翻译质量,前人主要从模型结构、训练目标等方面进行探索。而本工作另辟新径,从数据角度发现了知识蒸馏的副作用,并定义了词汇选择问题。这将改变传统的KD训练,并引导后续工作提出更合理的训练策略。
3.从理解到改进:序列到序列建模中的编码器特征融合
Understanding and Improving Encoder Layer Fusion in Sequence-to-Sequence Learning
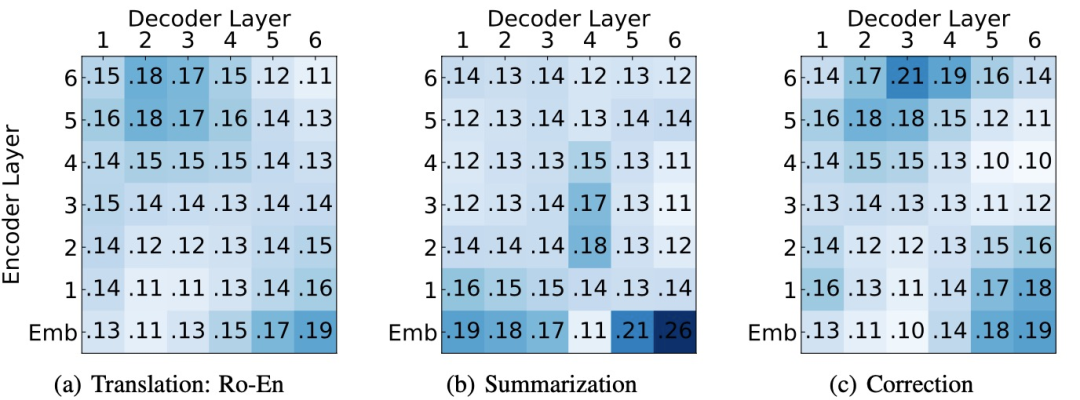
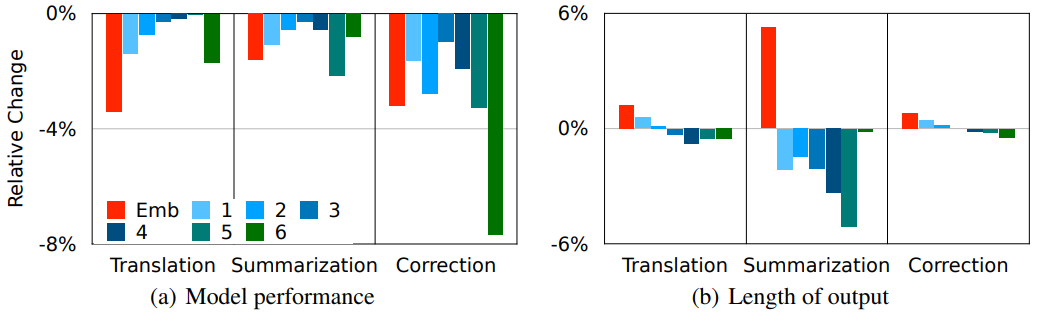
本文由腾讯AI Lab主导,与澳门大学、悉尼大学合作完成。编码器特征融合(EncoderFusion)是提升序列到序列建模中的经典技术之一。尽管其有效性已在各种自然语言处理(NLP)任务上得到的验证,但其原理及规律并没有被深入探究。
本文首先提出了细粒度层注意力模型来量化编码器每一层特征的贡献度,并在多个NLP任务(机器翻译、语法纠错、文本摘要)上进行分析,从而进一步理解EncoderFusion的本质。前人工作认为EncoderFusion主要利用嵌在编码器底层的词法和语法信息,而我们发现编码器词嵌入层比其他中间层更重要,并且始终受到解码器最上层的关注。基于该发现,我们提出了一种简单直接的融合方法,即只融合编码器词嵌入层到解码器输出层。
实验结果表明,该方法在多种序列建模任务上都优于已有融合方法,并使翻译任务在WMT16罗英和WMT14英法数据集上取得SOTA性能。分析进一步表明,SurfaceFusion能帮助模型学到更具表现力的双语词嵌入。该工作对编码器特征融合的改进和使用有较强启发和指导意义。
来源:腾讯AI Lab微信(tencent_ailab)

