
CVPR 2022 | 腾讯AI Lab入选论文解读,关注图像理解、生成、建模及可信AI
来自腾讯AI Lab微信(tencent_ailab)
CVPR(Conference on Computer Vision and Pattern Recognition)是计算机视觉三大顶会之一,也是中国计算机学会推荐的人工智能领域的A类会议。今年会议于 6 月 19 - 24 日以线上线下结合形式举行,据此前披露数据,今年会议投稿量突破了一万,其中 2067 篇论文被接收。
本文将解读腾讯 AI Lab 18 篇入选论文,涵盖图像与视频理解、视觉内容生成、神经辐射场建模、可信AI、具身人工智能等方向。论文完整内容将于会议官方渠道发布,本文为部分论文解读。
图像与视频理解
视觉的理解与识别为计算机视觉任务中经久不衰的问题。面对海量数据的环境,如何设计性能优异的模型,与挖掘模型潜能的学习算法,成为了图像与视频理解的核心问题。针对数据特性本身,视频数据相比于图像数据,其时序连续性带来了更多研究空间,也使得视频的理解受到了广泛的关注。
1. 基于前景-背景融合的运动感知对比视频表征学习
Motion-aware Contrastive Video Representation Learning via Foreground-background Merging
本文由腾讯AI Lab主导,与上海交通大学、香港中文大学、密歇根大学合作完成。鉴于对比学习在图像领域已取得的成功,当前的自监督视频表征学习方法通常采用对比损失来学习视频表征。然而,当直接地将视频的两个增强视图拉近时,该模型倾向于将共同的静态背景作为捷径来学习,而不能捕捉更重要的运动信息,这种现象被称为背景偏差。这种偏差使得模型的泛化能力较弱,导致下游任务(如动作识别)的性能较差。
为了减轻这种偏见,本文提出前景-背景合并来有意识地将所选视频的运动前景区域合成到其他视频的静态背景上。具体来说,在没有任何现成的检测器的情况下,该项工作通过帧差和颜色统计从背景区域中提取运动前景,并在视频中融合其他的背景区域。通过要求原始片段和融合片段之间的语义一致性,使得该模型更加关注运动模式,并有效地消除背景偏见。
大量实验表明,该方法可以有效地抵抗背景偏置,从而在UCF101、HMDB51和Diving48数据集上取得最先进的下游任务性能。

2. 针对时序动作定位任务的无监督预训练
Unsupervised Pre-training for Temporal Action Localization Tasks
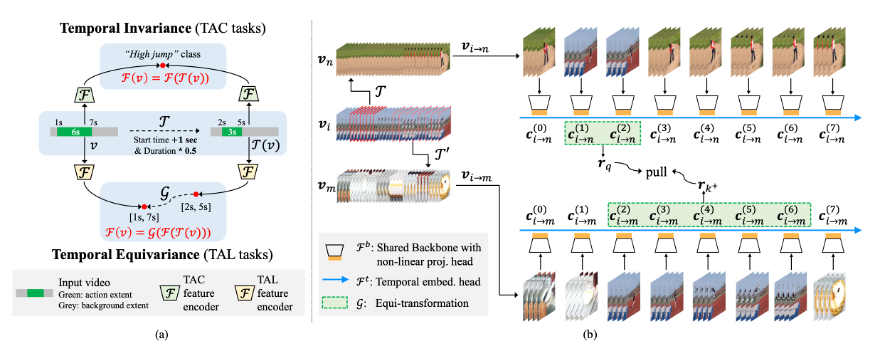
本文由腾讯AI Lab主导,与北京大学合作完成。虽然近年来无监督视频表征学习取得了显著的成就,但大多数现有的方法都是针对视频行为分类任务(TAC)进行设计和优化的。当应用于时序定位任务(TAL)时,由于视频级别分类和片段级别定位之间的固有差异,这些预先训练的模型的迁移性能会受限。
为了缓解这一问题,本文首次尝试对时序行为定位任务进行无监督预训练,提出一种新的自监督代理任务,称为“伪动作定位(Pseudo Action Localization,PAL)”。具体来说,该项工作首先从一个视频中随机选择两个不同时序区域(每个区域包含多个视频片段)作为伪动作区域,然后分别将它们粘贴到另外两个视频的不同时间位置。代理任务的目标是对齐两个新合成视频中粘贴的伪动作区域的特征,并最大化它们之间的一致性。
与现有的无监督视频表征学习方法相比,PAL 以时间密集采样和时间尺度敏感的方式引入时序等变对比学习范式,从而使上游预训练与下游 TAL 任务实现更好的对齐。大量实验表明,PAL 可以利用大规模无类别标签的视频数据来显著提高现有 TAL 方法的性能。
3. 针对弱监督时序动作定位探索去噪跨视频对比学习
Exploring Denoised Cross-video Contrast for Weakly-supervised Temporal Action Localization
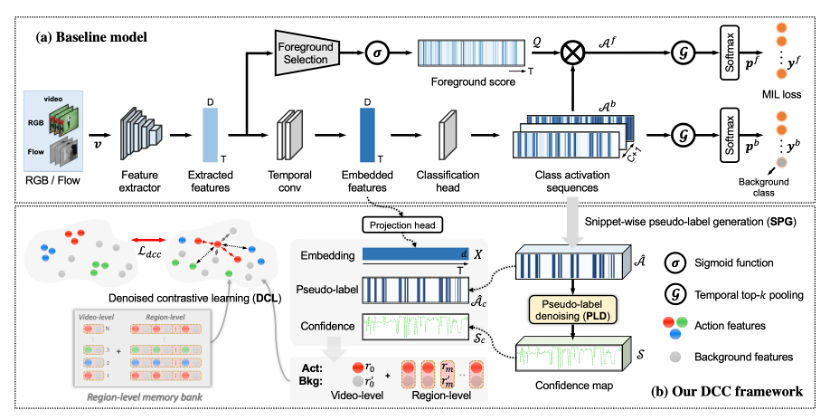
本文由腾讯AI Lab主导,与阿尔伯塔大学合作完成。弱监督时间动作定位旨在仅使用视频级弱标签来定位未修剪视频中的动作。大多数现有方法使用“先分类后定位”的框架解决这个问题,该框架基于片段分类序列来定位动作区域。然而,由于视频级标签的稀疏性,片段分类容易出错。
受到无监督对比表示学习的启发,本文提出了一种新颖的去噪跨视频对比算法,旨在增强视频片段的特征识别能力,以在弱监督环境中实现准确的时间动作定位。这是通过三个关键设计实现的:1) 一个有效的伪标签去噪模块,以减轻由嘈杂的对比特征引起的副作用,2) 一种有效的区域级特征对比策略,结合区域级特征记忆库,来捕获整个数据集的“全局”对比,以及 3)多样化的对比学习策略,以实现动作-背景分离以及类内紧凑性和类间可分离性。
在 THUMOS14 和 ActivityNet v1.2 上进行的大量实验证明了该方法的卓越性能。
4. 基于带权的序列EM的实时的视频物体分割算法
SWEM: Towards Real-Time Video Object Segmentation with Sequential Weighted Expectation-Maximization
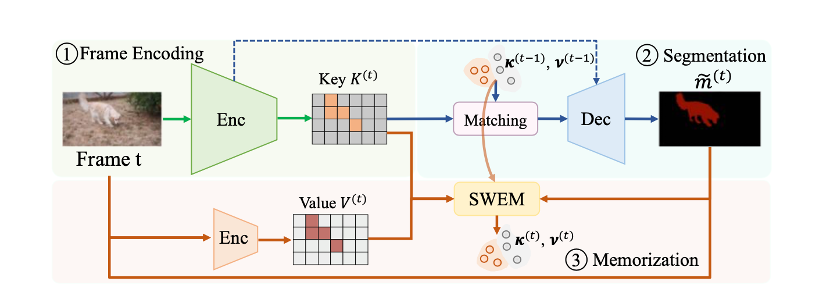
本文由腾讯AI Lab主导,与清华大学,腾讯TEG数据平台部合作完成。在半监督视频物体分割(VOS)任务中,基于时空记忆匹配的方法在准确性方面显著优于其他解决方案。然而不断增长的记忆规模会导致低下的推理效率。
为了解决这一问题,本文提出了一种带权的序列期望最大算法,简称为SWEM,该算法能够极大地减少记忆特征的冗余度。与之前只考虑视频帧间特征冗余的方法不同,该项工作提出的SWEM通过同时聚合帧间和帧内的相似特征,来得到表达力强且紧凑的基特征。此外,本文还提出了一种自适应加权方法来表明不同像素的重要程度,从而突出那些对物体分割贡献度较高的特征。
本文所提出的方法在推断过程中始终维持固定的记忆特征个数,从而保证了分割系统推理复杂度的稳定性。SWEM在DAVIS和YouTube-VOS数据集上都取得了极具竞争力的结果,并且能够保持实时的推理速度(36 FPS)。
5. 基于自监督transformer和Ncut的显著物体检测和分割
Self-Supervised Transformers for Unsupervised Object Discovery using Normalized Cut
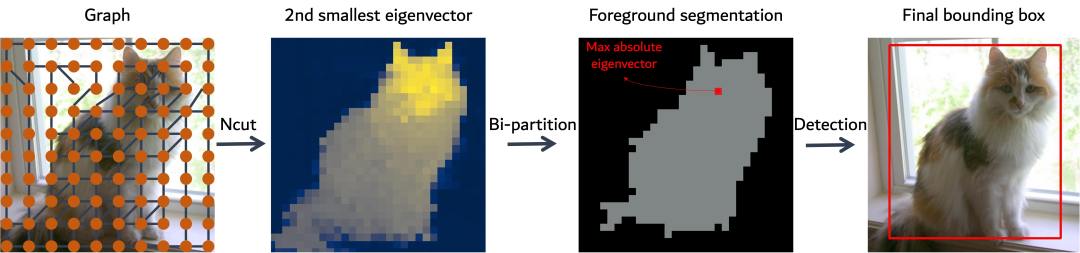
本文由腾讯AI Lab主导,与法国国立计算机及自动化研究院、三星、麻省理工大学合作完成。基于蒸馏的自监督学习的transformer (Dino)的Attention map会突出前景物体。本文展现了一个基于graph的方法,利用自监督学习的transformer的特征来检测图片中的物体。输入的图片方块是graph的节点,同时图片特征之间的相似度是graph的边。前景物体可以通过归一的图切割的方式得到。本文使用具有广义特征分解的谱聚类来解决图切割问题,并表明第二小的特征向量提供了切割解决方案,而且特征向量的绝对值大小表示此区域属于前景的可能性。
尽管方法很简单,但这种方法显著提高了无监督物体检测的性能:实验证明,该方法在 VOC07、VOC12 和 COCO20K 上分别比最近最先进的 LOST 提高了 6.9%、8.1% 和 8.1%。通过添加第二阶段与类别无关的检测器 (CAD),可以进一步提高性能。该方法可以很容易地扩展到无监督显著性检测和弱监督目标检测。对于无监督显著性检测,该项工作在 ECSSD、DUTS、DUT-OMRON 上的 IoU 与之前的技术水平相比分别提高了 4.9%、5.2%、12.9%。对于弱监督目标检测,该项工作在 CUB 和 ImageNet 上取得了具有竞争力的性能。
项目代码和Demo可见:https://www.m-psi.fr/Papers/TokenCut2022/
6. ADeLA:语义分割中视角变换下的自动稠密标注算法
ADeLA: Automatic Dense Labeling with Attention for Viewpoint Shift in Semantic Segmentation
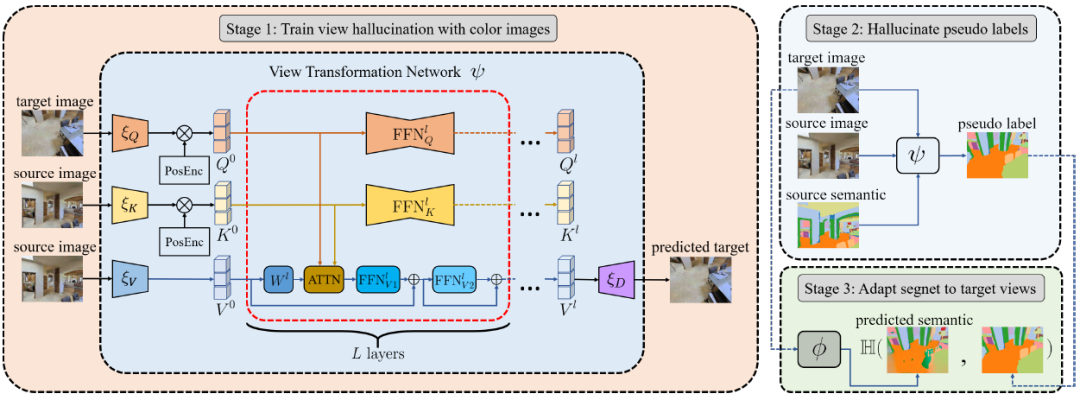
本文由腾讯AI Lab与斯坦福大学、北京大学和浙江大学合作完成,致力于解决多相机系统中由于视角变化导致语义分割性能下降的问题。这个问题提供了时序上关联但视角不一致的图片,并且仅有个别视角提供了对应的稠密语义标签。
过去的方法通过不同域之间的配准来解决这个问题,然而视角变化引起的障碍可能会破坏这样的配准效果。本文提出一个新颖的基于注意力机制的视角变换网络来预测目标图像的语义信息。即使在训练阶段缺少监督,视角变换网络依然能够泛化到语义图像。
本文提出的方法超越了最新的视角合成和关联预测方法,并且大幅优于基于无监督学习的域适应方法。
7. SVIP:视频中过程的序列验证
SVIP: Sequence VerIfication for Procedures in Videos
本文由腾讯AI Lab与上海科技大学合作完成,可以通过视频,自动判断操作流程,是否和标准流程一致,起到监督预警的作用。
本文提出了一种新颖的序列验证任务,旨在将执行相同动作序列的正视频对与具有步进级转换但仍执行相同任务的负视频对区分开来。这样一项具有挑战性的任务存在于一个开放集设置中,没有事先需要事件级甚至帧级注释的动作检测或分割。为此,该项工作仔细重组了两个公开可用的具有步骤-过程-任务结构的动作相关数据集。
为了充分研究任何方法的有效性,该项工作收集了一个脚本视频数据集,其中列举了化学实验中的各种步骤级转换。此外,引入了一种新的评估度量加权距离比,以确保评估过程中不同步级变换的等效性。最后,引入了一个简单但有效的基线,该基线基于具有新颖序列对齐损失的转换器,以更好地表征步骤之间的长期依赖性,优于其他动作识别方法。
代码和数据详见:https://github.com/svip-lab/SVIP-Sequence-VerIfication-for-Procedures-in-Videos
视觉内容生成
数字内容生成是视觉领域中备受关注的任务,内容智能创作有巨大应用价值。
保持几何结构的图像拼接方法
Geometric Structure Preserving Warp for Natural Image Stitching
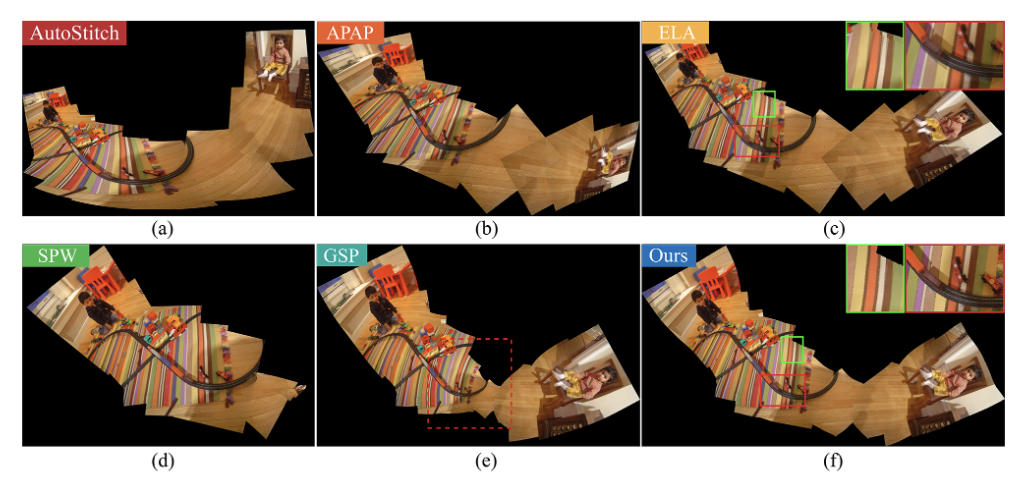
本文由腾讯AI Lab与新加坡国立大学、西北农林科技大学合作完成。保留场景中的几何结构在图像拼接中起着至关重要的作用。然而,现有的方法大多忽略了由直线或曲线反映的大规模布局,降低了整体拼接质量。
本文提出了一种结构保持拼接方法,可以产生具有自然视觉效果和较少失真的图像。该项工作首先采用基于深度学习的边缘检测来提取各种类型的大规模边缘。然后,对提取的边缘进行采样以构造多组三角形来表示它们的几何结构。作者引入了几何结构保持 (GES) 能量项来鼓励这些三角形进行相似变换。此外,本文提出了一种优化的GES能量项,以合理确定几何结构上采样点的权重,并将其添加到称为GES-GSP的全局相似性先验(GSP)拼接模型中,以实现局部对齐和几何结构保存之间的平滑过渡。
本文通过对拼接数据集的综合实验证明了所提出的 GES-GSP 的有效性。同时实验表明,所提出的方法在几何结构保存方面始终优于几种最先进的方法,并获得更自然的拼接结果。
神经辐射场建模
神经辐射场相关技术是近年来计算机视觉与图形学领域的热点研究问题。如何在不同数据条件下利用神经辐射场高效地进行场景与人物的高真实感建模,并灵活的对神经辐射场中的内容进行有效的编辑,是当下相关研究中核心问题。
1. 去模糊神经辐射场: 从模糊图片中恢复清晰神经辐射场
Deblur-NeRF: Neural Radiance Fields from Blurry Images
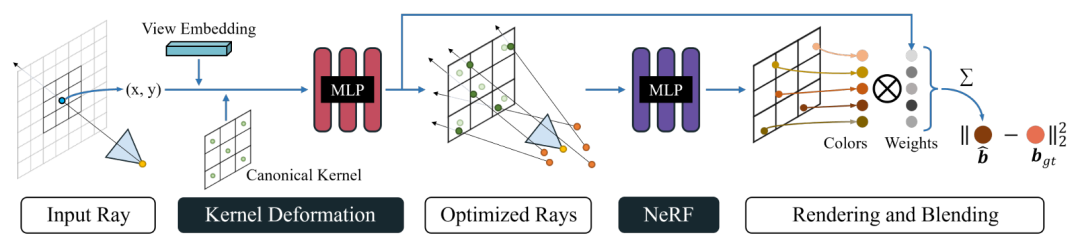
本文由腾讯AI Lab主导,与香港科技大学合作完成。由于出色的图像合成表现, 神经辐射场(NeRF)已经在3D场景重建和新视点合成领域获得了广泛的关注。然而在真正的重建过程中,拍摄时的镜头失焦或者相机抖动而带来的成像模糊常常会大大降低重建的精度。
为了解决这个问题,本文首创性地提出了从多个模糊的输入图像重建清晰的神经辐射场,可对模糊成像的过程进行建模,通过对模型合成的模糊结果进行分析从而进行去模糊。这个模糊模型的核心是一个新颖的可变性稀疏模糊核(DSK)模块。它通过对一个模板空间的稀疏模糊核进行变形,来模拟空间上处处不同的模糊核。同时模糊核中的每个点的光学中心也会同时被优化变形,因为模糊的物理过程也会有光学中心的变化。该方法将这个DSK模块参数化为一个多层感知器,因此它对不同的模糊类型都是通用的。同时优化神经辐射场和DSK模块,就可以得到一个清晰的神经辐射场。
该方法可以同时用于去除两种最常见的模糊:由于失焦和由于相机抖动造成的模糊。在合成数据集和真实数据集下的对比实验也证明了本方法超过了几个基线方法。
项目细节可见:https://github.com/limacv/Deblur-NeRF
2. NeRFReN: 支持反射的神经辐射场
NeRFReN: Neural Radiance Fields with Reflections
本文由腾讯AI Lab主导,与北京信息科学与技术国家研究中心、北京雁栖湖应用数学研究院合作完成。神经辐射场技术(Neural Radiance Fields,NeRF)通过利用基于坐标的场景表示,在新视点合成任务上取得了令人惊艳的效果。虽然神经辐射场建模了物体的视角相关特性,但实验表明其只能正确地处理高光等简单的反射现象。对于玻璃、镜子等物体带来的复杂反射,神经辐射场会估计错误的几何,并在某些不具有多视角一致性的场景下得到模糊的视点合成结果。
为此,本工作提出使用两个神经辐射场建模此类场景,其中一个建模真实几何的反射光,另一个建模反射像。针对这种欠约束表示,本工作提出采用几何先验和特殊设计的训练策略来进行解空间的约束。本工作提出的方法在有复杂反射的场景下可以实现高质量的视点合成效果,同时取得明显更优的深度估计结果。
本工作将所提出技术应用在了场景编辑上。在含有复杂反射的场景下取得更理想、可解释性更强的的新视点合成结果,并且可以实现多个场景编辑操作,如反射去除、反射替换等。
项目细节可见:https://bennyguo.github.io/nerfren/

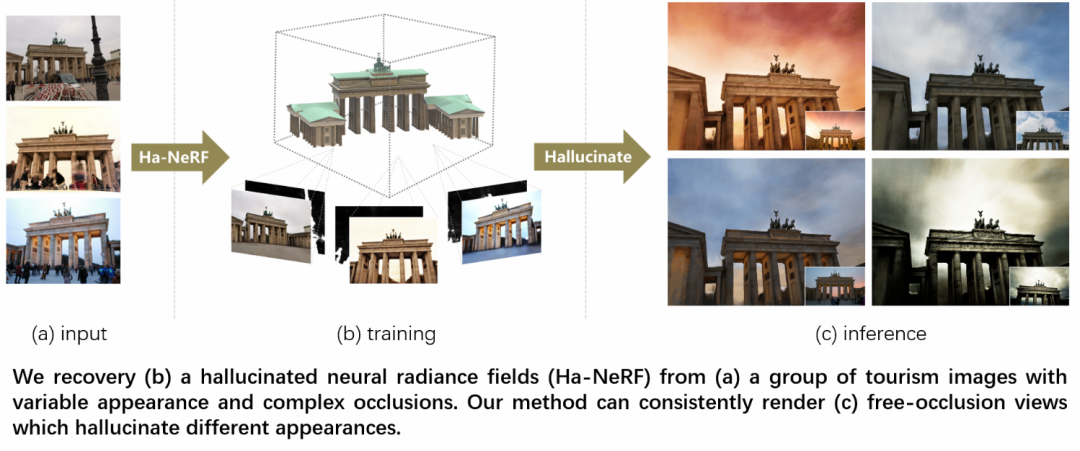
3. 光影幻象:神经辐射场中的时空流转
Hallucinated Neural Radiance Fields in the Wild
本文由腾讯AI Lab主导,与西安交通大学合作完成。神经辐射场(NeRF)因其令人印象深刻的新视点合成能力而备受关注。本文研究了幻象NeRF问题:即从一组旅游中拍摄的图片恢复高保真的不同时间的NeRF。现有的解决方案采用具有可控的外观嵌入的NeRF来在各种条件下渲染新的视点,但无法跨视角一致地渲染未曾见过外观的图像。
为了解决这个问题,本文提出了一个端到端框架来构建一种幻象NeRF,称为Ha-NeRF。具体来说,本文提出了一种外观幻象模块来处理时变的外观,并将这样的外观转换到新的视点当中。针对旅游图像的复杂遮挡问题,该方法引入抗遮挡模块对静态对象进行精确的能见度建模。
在合成数据和真实旅游照片采集上的实验结果表明,该方法不仅能产生理想的外观,而且能从不同视角渲染无遮挡的图像。
项目细节可见:https://rover-xingyu.github.io/Ha-NeRF/
可信AI
近年来,人工智能算法被广泛地应用到医疗、金融、工业生产等多个重要领域,这些算法在提升生产力的同时,也面临各种风险隐患。可信AI目标于使AI系统所做出的决策能够被理解、被信任,其研究范围包含鲁棒性、公平性、可解释性和隐私保护等。
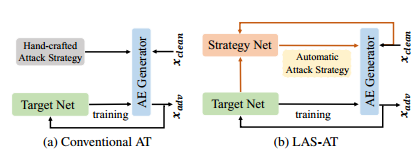
1. LAS-AT:具有可学习攻击策略的对抗训练
LAS-AT: Adversarial Training with Learnable Attack Strategy
本文由腾讯AI Lab主导,与中国科学院大学信息工程研究所国家重点实验室,香港中文大学(深圳)大数据研究院数据科学学院合作完成。
对抗训练通常被描述为一个min-max的优化问题,其性能取决于内部的max优化问题,即对抗样本的生成。以前的大多数方法都采用投影梯度下降,手动指定对抗样本的攻击生成参数。攻击参数的组合可以被称为攻击策略。一些研究表明,在整个训练阶段使用固定的攻击策略生成的对抗样本会限制模型的鲁棒性,并提出在不同的训练阶段使用不同的攻击策略来提高鲁棒性。但是,这些多阶段的手工设计的攻击策略需要大量的专业知识,而且鲁棒性改进有限。
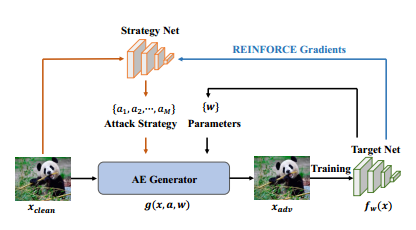
本文通过引入“可学习的攻击策略”的概念,提出了一种新的对抗训练框架,它学习自动生成攻击策略,以提高模型的鲁棒性。该框架由一个使用对抗样本进行训练以提高模型鲁棒性的目标网络和一个生成攻击策略以控制对抗样本生成的策略网络组成。在三个基准数据库上的实验评估表明了该方法的优越性,并且该方法优于现有的对抗训练方法。
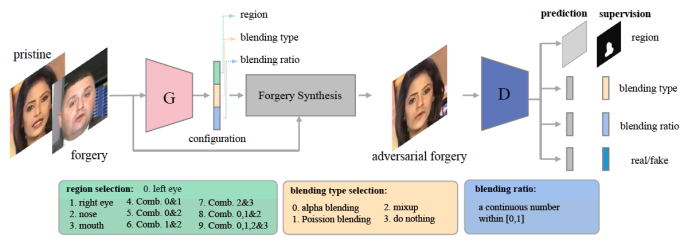
2. 基于自监督对抗样本的可泛化的假脸检测方法
Self-supervised Learning of Adversarial Example: Towards Good Generalizations for Deepfake Detection
本文由腾讯AI Lab主导,与阿德莱德大学合作完成。近年来,基于深度学习的人脸造假方法层出不穷,同时,针对这些假脸的检测方法也受到了广泛的关注。但是,现有的假脸检测方法一般只能被用来检测训练集中已知的几种造假方法产生的假图,当测试案例中给出的假脸图片由未知的造假方法生成,这些检测方法往往表现较差。
为了有效缓解泛化性的问题,本文提出了一个简单的原则:一个可以泛化的表征必定会对各种假图都敏感。基于此,本文首先提出在训练过程中用可学习的增广方式来决定多种造假参数,并由这些造假参数来丰富假图的种类;其次,为了增强敏感性,本文让模型在预测人脸图片真假的同时,也同步预测假图的造假参数;最后,为了构造困难的检测样本,该项工作用对抗学习的方式来交替更新增广模型和检测模型。
广泛的实验证明,本文的方法能有效提高基准模型的泛化性,并在多个基准数据集上优于现有的方法。
3. 基于对抗分布迁移的黑盒对抗攻击
Boosting Black-Box Attack with Partially Transferred Conditional Adversarial Distribution
本文由腾讯AI Lab与清华大学、香港中文大学(深圳)、深圳大数据研究院、腾讯数据平台部、美团和鹏程实验室人工智能中心合作完成,提出了一种高效的黑盒攻击方法,更贴近业务的运行环境,可以提供更好的对抗鲁棒性评测,进而推动系统的安全性和可靠性。
由于不需要被攻击模型的模型结构和网络参数等信息,黑盒攻击更贴近实际的运行环境,可以更好的衡量业务系统的潜在威胁。本文研究了一种基于对抗样本分布迁移的黑盒攻击方法。对抗样本的迁移性指在替代模型上生成的对抗样本对目标模型仍然具有一定的攻击性。然而,替代模型和目标模型之间潜在的网络结构、模型参数、训练数据集等方面的不一致性,极大的影响着对抗样本的迁移成功率。
本文提出了一种新的部分迁移机制来缓解这种不一致性,特别建模了基于条件流模型的对抗样本分布,并在替代模型上进行流模型学习。在对目标模型的黑盒攻击过程中,本文仅迁移条件流模型的部分参数,其余参数则基于目标模型优化得到。这种部分迁移策略可以兼顾攻击效率和性能,在多个基准数据集和真实的API系统上的实验验证了方法的有效性。
具身人工智能
具身人工智能 (Embodied AI) 指拥有实体、在环境中学习的人工智能,亦即人工智能的具身化。
具身人工智能关注以下几个重点问题:1)搭建供智能体学习的仿真/真实环境 2)具身智能体的学习任务 3)如何学习和解决这些任务。
视觉感知是具身智能的重要组成部分,具身化的智能体如何主动在复杂环境中发展可靠、鲁棒、可泛化的视觉系统,理解实体概念,如何感知能够更好服务于决策与执行的信息,也为视觉的发展带来了新的任务和挑战。
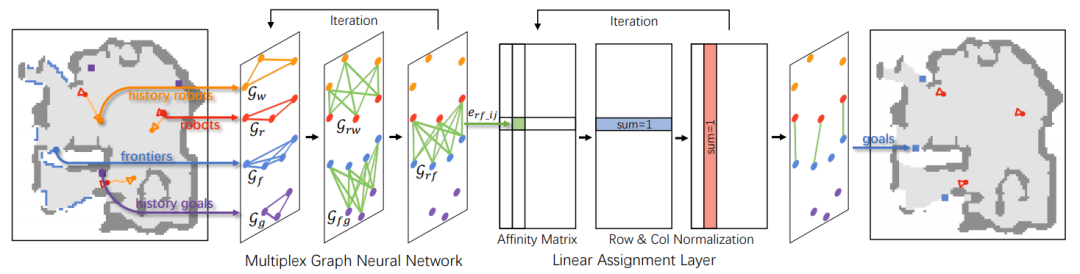
基于神经二值图匹配的多机器人自主场景重建
Multi-Robot Active Mapping via Neural Bipartite Graph Matching
本文由腾讯AI Lab与斯坦福大学、清华大学、北京大学和山东大学合作完成,主要研究多机器人自主场景重建的问题。该问题的目标是利用最少的时间步实现完整的场景重建,而解决这个问题的关键在于用于实现高效机器人移动的目标位置预测算法。过去的方法要么通过一种贪心策略选择边界点(frontier)作为目标位置,要么通过强化学习来直接回归目标位置,这两种方法在探索效率和场景的重建完整度上都表现欠佳。
本文通过融合上述两种方法提出了一种新颖的多机器人自主场景重建算法。具体而言,本文将该问题简化为二值图匹配,并通过建立机器人和边界点的点与点对应来解决该问题。为了实现更有效的图匹配,本文提出一个多元图神经网络来学习点与点之间的神经距离用于填充图匹配中的邻接矩阵。该项工作通过强化学习最大化长期的时间效率和场景完整度来优化多元图神经网络。该算法仅需要9个场景就可以训练成功,且在多种不同的室内场景和一些机器人上验证了其优越性。
猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!附下载 |《TensorFlow 2.0 深度学习算法实战》