点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
AI 研究人员在构建新的机器学习模型和训练范式时,通常会使用一组被称为归纳偏置(inductive biases)的特定假设,来帮助模型从更少的数据中学到更通用的解决方案。近十年来,深度学习的巨大成功在一定程度上归功于强大的归纳偏置,基于其卷积架构已被证实在视觉任务上非常成功,它们的 hard 归纳偏置使得样本高效学习成为可能,但代价是可能会降低性能上限。而视觉 Transformer(如 ViT)依赖于更加灵活的自注意力层,最近在一些图像分类任务上性能已经超过了 CNN,但 ViT 对样本的需求量更大。来自 Facebook 的研究者提出了一种名为 ConViT 的新计算机视觉模型,它结合了两种广泛使用的 AI 架构——卷积神经网络 (CNN) 和 Transformer,该模型取长补短,克服了 CNN 和 Transformer 本身的一些局限性。同时,借助这两种架构的优势,这种基于视觉 Transformer 的模型可以胜过现有架构,尤其是在小数据的情况下,同时在大数据的情况下也能实现类似的优秀性能。
论文地址:
https://arxiv.org/pdf/2103.10697.pdf
GitHub 地址:
https://github.com/facebookresearch/convit
在视觉任务上非常成功的 CNN 依赖于架构本身内置的两个归纳偏置:局部相关性:邻近的像素是相关的;权重共享:图像的不同部分应该以相同的方式处理,无论它们的绝对位置如何。相比之下,基于自注意力机制的视觉模型(如 DeiT 和 DETR)最小化了归纳偏置。当在大数据集上进行训练时,这些模型的性能已经可以媲美甚至超过 CNN 。但在小数据集上训练时,它们往往很难学习有意义的表征。这就存在一种取舍权衡:CNN 强大的归纳偏置使得即使使用非常少的数据也能实现高性能,但当存在大量数据时,这些归纳偏置就可能会限制模型。相比之下,Transformer 具有最小的归纳偏置,这说明在小数据设置下是存在限制的,但同时这种灵活性让 Transformer 在大数据上性能优于 CNN。为此,Facebook 提出的 ConViT 模型使用 soft 卷积归纳偏置进行初始化,模型可以在必要时学会忽略这些偏置。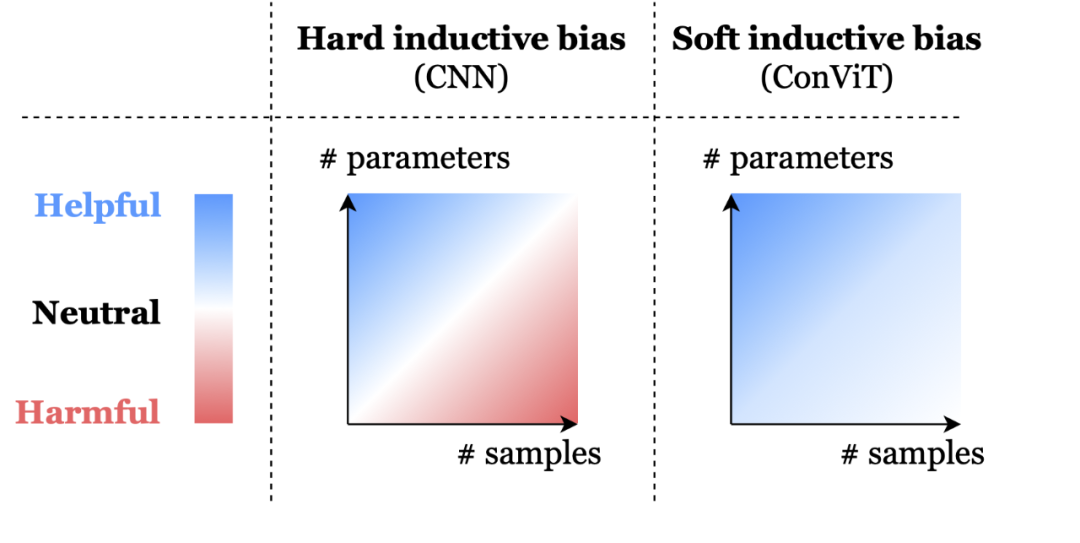
soft 归纳偏置可以帮助模型不受限制地学习。hard 归纳偏置,例如 CNN 的架构约束,可以极大地提高学习的样本效率,但当数据集大小不确定时可能就会成为约束。ConViT 中的 soft 归纳偏置能够在不需要时被忽略,以避免模型受到约束限制。ConViT 在 vision Transformer 的基础上进行了调整,以利用 soft 卷积归纳偏置,从而激励网络进行卷积操作。同时最重要的是,ConViT 允许模型自行决定是否要保持卷积。为了利用这种 soft 归纳偏置,研究者引入了一种称为「门控位置自注意力(gated positional self-attention,GPSA)」的位置自注意力形式,其模型学习门控参数 lambda,该参数用于平衡基于内容的自注意力和卷积初始化位置自注意力。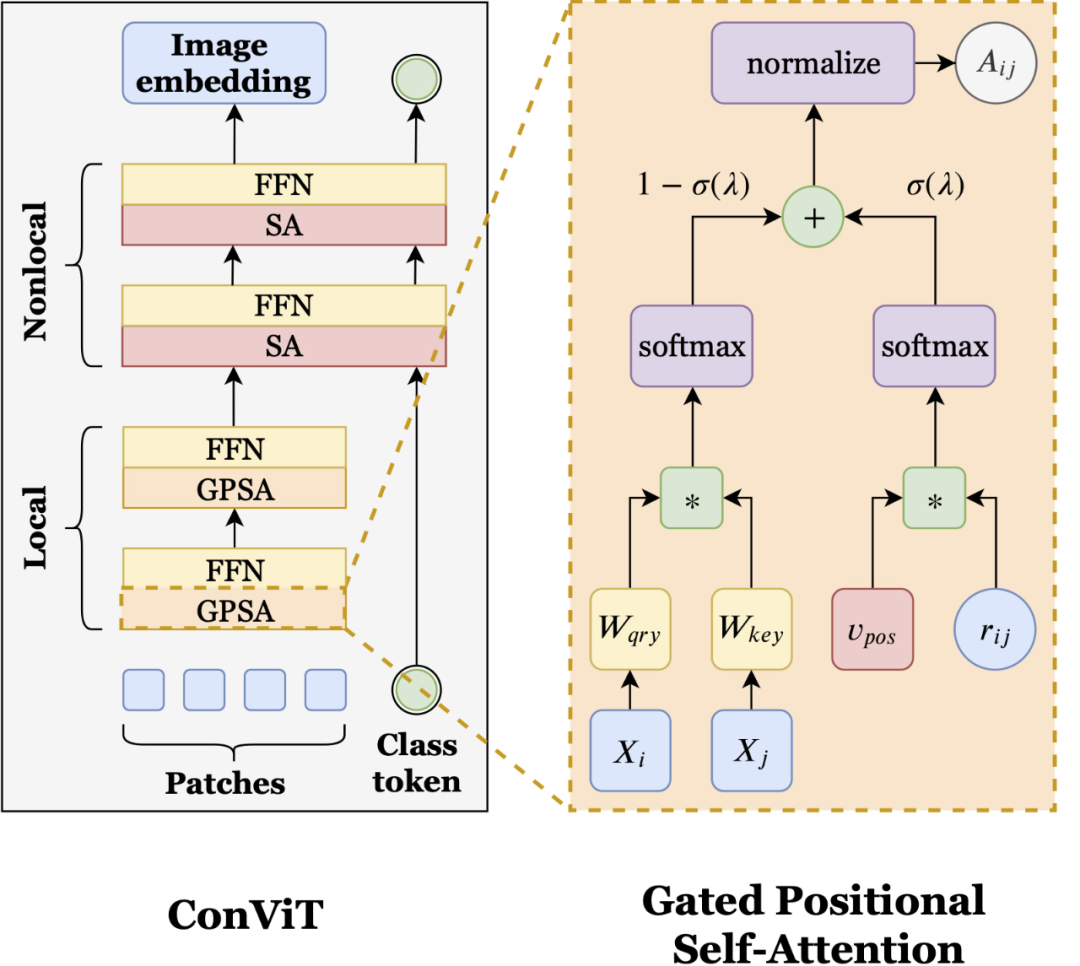
如上图所示,ConViT(左)在 ViT 的基础上,将一些自注意力(SA)层用门控位置自注意力层(GPSA,右)替代。因为 GPSA 层涉及位置信息,因此在最后一个 GPSA 层之后,类 token 会与隐藏表征联系到一起。有了 GPSA 层加持,ConViT 的性能优于 Facebook 去年提出的 DeiT 模型。例如,ConViT-S+ 性能略优于 DeiT-B(对比结果为 82.2% vs. 81.8%),而 ConViT-S + 使用的参数量只有 DeiT-B 的一半左右 (48M vs 86M)。而 ConViT 最大的改进是在有限的数据范围内,soft 卷积归纳偏置发挥了重要作用。例如,仅使用 5% 的训练数据时,ConViT 的性能明显优于 DeiT(对比结果为 47.8% vs. 34.8%)。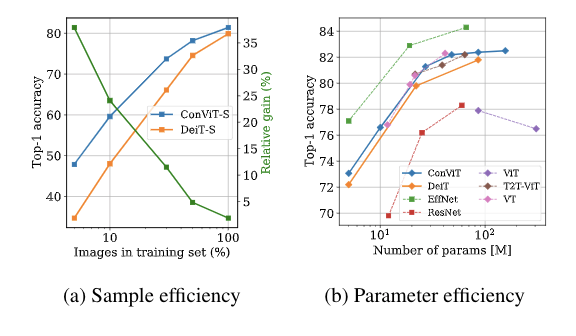
此外,ConViT 在样本效率和参数效率方面也都优于 DeiT。如上图所示,左图为 ConViT-S 与 DeiT-S 的样本效率对比结果,这两个模型是在相同的超参数,且都是在 ImageNet-1k 的子集上训练完成的。图中绿色折线是 ConViT 相对于 DeiT 的提升。研究者还在 ImageNet-1k 上比较了 ConViT 模型与其他 ViT 以及 CNN 的 top-1 准确率,如上右图所示。除了 ConViT 的性能优势外,门控参数提供了一种简单的方法来理解模型训练后每一层的卷积程度。查看所有层,研究者发现 ConViT 在训练过程中对卷积位置注意力的关注逐渐减少。对于靠后的层,门控参数最终会收敛到接近 0,这表明卷积归纳偏置实际上被忽略了。然而,对于起始层来说,许多注意力头保持较高的门控值,这表明该网络利用早期层的卷积归纳偏置来辅助训练。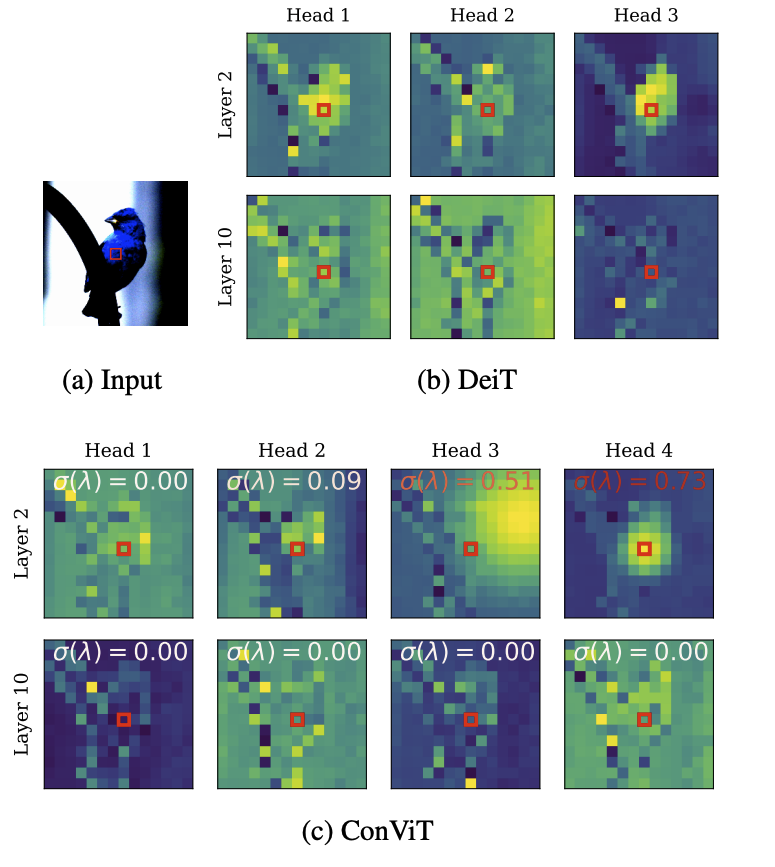
上图展示了 DeiT (b) 及 ConViT (c) 注意力图的几个例子。σ(λ) 表示可学习的门控参数。接近 1 的值表示使用了卷积初始化,而接近 0 的值表示只使用了基于内容的注意力。注意,早期的 ConViT 层部分地维护了卷积初始化,而后面的层则完全基于内容。测试是在 ImageNet-1K 上进行的,没有进行知识蒸馏,结果如下: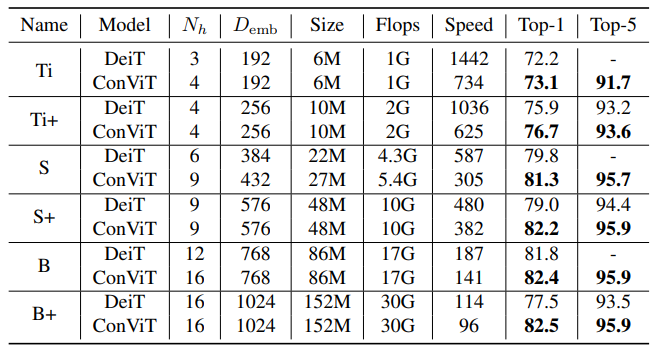
AI 模型的性能在很大程度上取决于训练这些模型所用的数据类型和数据规模。在学术研究和现实应用中,模型经常受到可用数据的限制。ConViT 提出的这种 soft 归纳偏置,在适当的时候能够被忽略,这种创造性的想法让构建更灵活的人工智能系统前进了一步。 感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。

