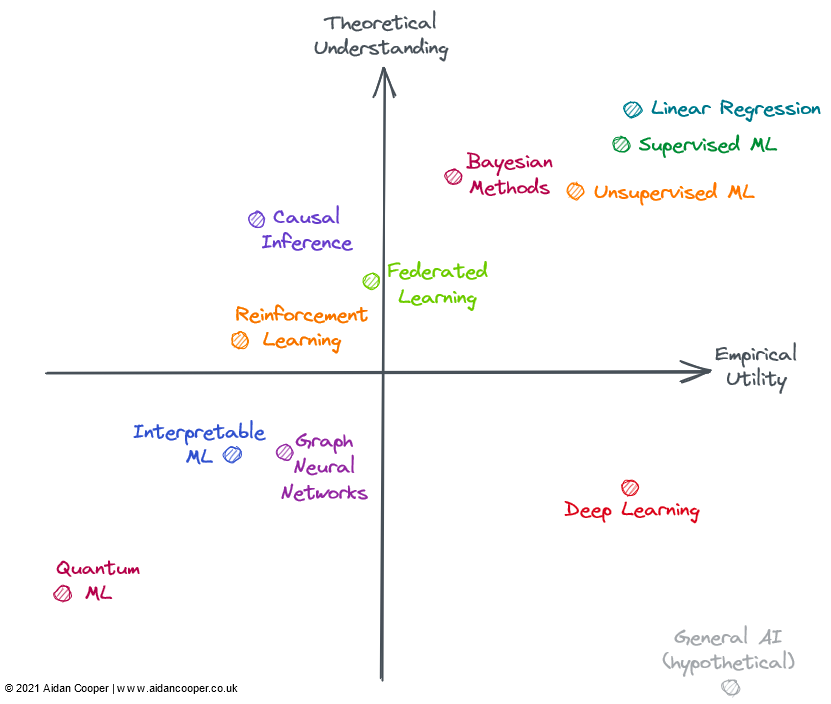
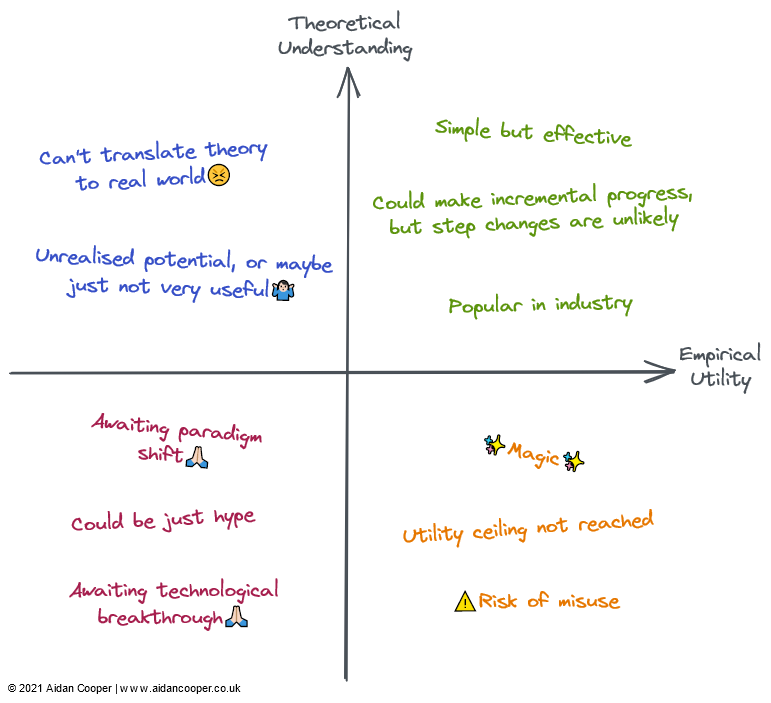
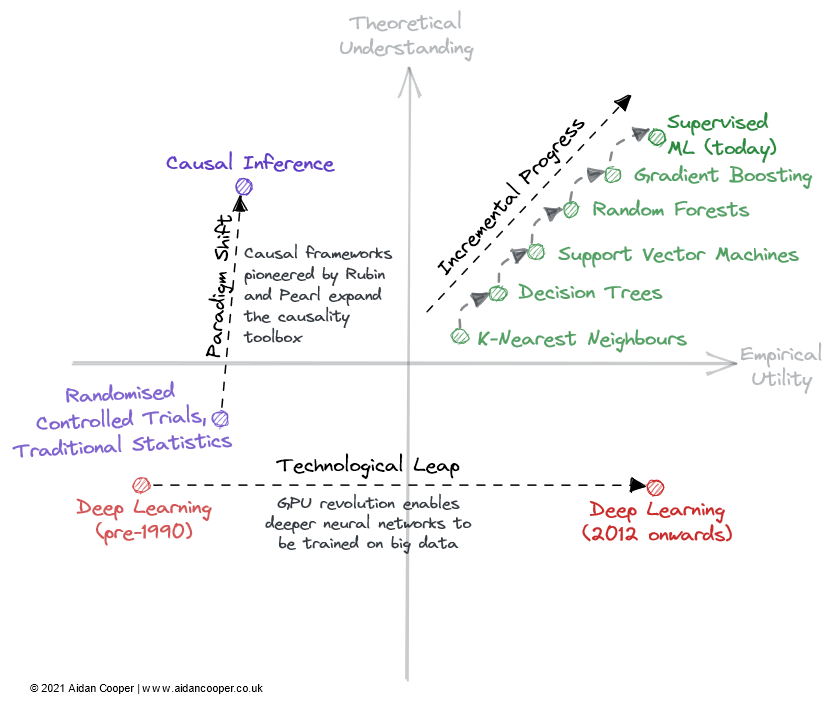
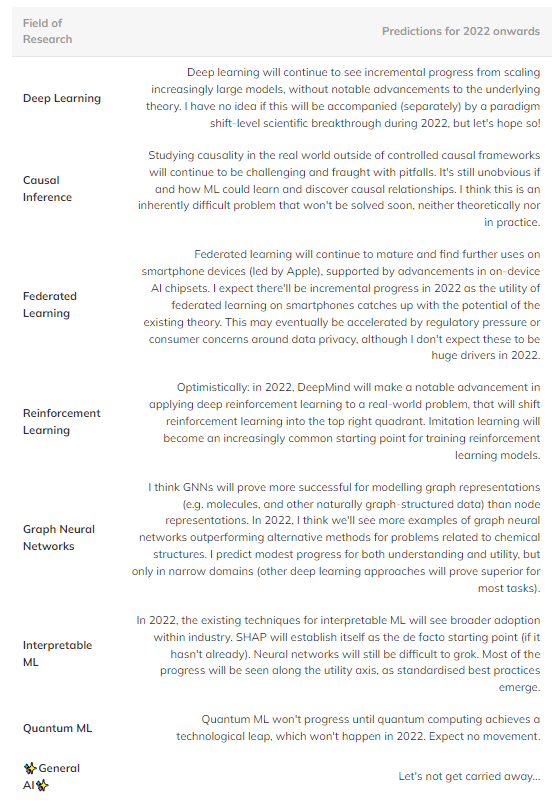
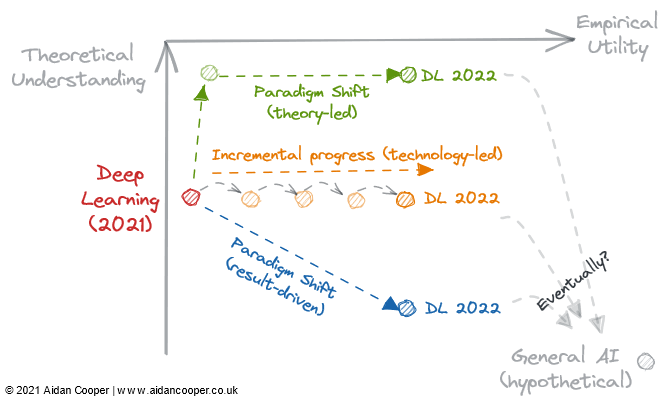
机器学习理论基础到底有多可靠?机器学习算法与Python实战关注共 5039字,需浏览 11分钟 ·2022-02-26 23:00 ↑↑↑点击上方蓝字,回复资料,10个G的惊喜选自aidancooper.co.uk 作者:Aidan Cooper 机器之心编译 知其然,知其所以然。机器学习领域近年的发展非常迅速,然而我们对机器学习理论的理解还很有限,有些模型的实验效果甚至超出了我们对基础理论的理解。目前,领域内越来越多的研究者开始重视和反思这个问题。近日,一位名为 Aidan Cooper 的数据科学家撰写了一篇博客,梳理了模型的实验结果和基础理论之间的关系。以下是博客原文:机器学习领域中,有些模型非常有效,但我们并不能完全确定其原因。相反,一些相对容易理解的研究领域则在实践中适用性有限。本文基于机器学习的效用和理论理解,探讨各个子领域的进展。这里的「实验效用」是一种综合考量,它考虑了一种方法的适用性广度、实施的难易程度,以及最重要的因素,即现实世界中的有用程度。有些方法不仅实用性高,适用范围也很广;而有些方法虽然很强大,但仅限于特定的领域。可靠、可预测且没有重大缺陷的方法则被认为具有更高的效用。所谓理论理解,就是要考虑模型方法的可解释性,即输入与输出之间是什么关系,怎样才能获得预期的结果,这种方法的内部机制是什么,并考量方法涉及文献的深度和完整性。理论理解程度低的方法在实现时通常会采用启发式方法或大量试错法;理论理解程度高的方法往往具有公式化的实现,具有强大的理论基础和可预测的结果。较简单的方法(例如线性回归)具有较低的理论上限,而更复杂的方法(例如深度学习)具有更高的理论上限。当谈到一个领域内文献的深度和完整性时,则根据该领域假设的理论上限来评估该领域,这在一定程度上依赖于直觉。我们可以将效用矩阵构造为四个象限,坐标轴的交点代表一个假设的参考领域,具有平均理解和平均效用。这种方法使得我们能够根据各领域所在的象限以定性的方式解释它们,如下图所示,给定象限中的领域可能具有部分或全部该象限对应的特征。一般来说,我们期望效用和理解是松散相关的,使得理论理解程度高的方法比理解程度低的更有用。这意味着大多数领域应位于左下象限或右上象限。远离左下 - 右上对角线的领域代表着例外情况。通常,实际效用应落后于理论,因为将新生的研究理论转化为实际应用需要时间。因此,该对角线应该位于原点上方,而不是直接穿过它。2022 年的机器学习领域并非上图所有领域都完全包含在机器学习 (ML) 中,但它们都可以应用于 ML 的语境中或与之密切相关。许多被评估的领域是重叠的,并且无法清晰地描述:强化学习、联邦学习和图 ML 的高级方法通常基于深度学习。因此,我考虑了它们理论与实际效用的非深度学习方面。右上象限:高理解、高效用线性回归是一种简单、易于理解且高效的方法。虽然经常被低估和忽视。,但它的使用广度和透彻的理论基础让其处于图中右上角的位置。传统的机器学习已经发展为一个高度理论理解和实用的领域。复杂的 ML 算法,例如梯度提升决策树(GBDT),已被证明在一些复杂的预测任务中通常优于线性回归。大数据问题无疑就是这种情况。可以说,对过参数化模型的理论理解仍然存在漏洞,但实现机器学习是一个精细的方法论过程,只要做得好,模型在行业内也能可靠地运行。然而,额外的复杂性和灵活性确实会导致出现一些错误,这就是为什么我将机器学习放在线性回归的左侧。一般来说,有监督的 机器学习比它的无监督 * 对应物更精细,更有影响力,但两种方法都有效地解决了不同的问题空间。贝叶斯方法拥有一群狂热的从业者,他们宣扬它优于更流行的经典统计方法。在某些情况下,贝叶斯模型特别有用:仅点估计是不够的,不确定性的估计很重要;当数据有限或高度缺失时;并且当您了解要在模型中明确包含的数据生成过程时。贝叶斯模型的实用性受到以下事实的限制:对于许多问题,点估计已经足够好,人们只是默认使用非贝叶斯方法。更重要的是,有一些方法可以量化传统 ML 的不确定性(它们只是很少使用)。通常,将 ML 算法简单地应用于数据会更容易,而不必考虑数据生成机制和先验。贝叶斯模型在计算上也很昂贵,并且如果理论进步产生更好的采样和近似方法,那么它会具有更高的实用性。右下象限:低理解,高效用与大多数领域的进展相反,深度学习取得了一些惊人的成功,尽管理论方面被证明从根本上难以取得进展。深度学习体现了一种鲜为人知的方法的许多特征:模型不稳定、难以可靠地构建、基于弱启发式进行配置以及产生不可预测的结果。诸如随机种子 “调整” 之类的可疑做法非常普遍,而且工作模型的机制也很难解释。然而,深度学习继续推进并在计算机视觉和自然语言处理等领域达到超人的性能水平,开辟了一个充满其他难以理解的任务的世界,如自动驾驶。假设,通用 AI 将占据右下角,因为根据定义,超级智能超出了人类的理解范围,可以用于解决任何问题。目前,它仅作为思想实验包含在内。每个象限的定性描述。字段可以通过其对应区域中的部分或全部描述来描述左上象限:高理解,低效用大多数形式的因果推理不是机器学习,但有时是,并且总是对预测模型感兴趣。因果关系可以分为随机对照试验 (RCT) 与更复杂的因果推理方法,后者试图从观察数据中测量因果关系。RCT 在理论上很简单并给出严格的结果,但在现实世界中进行通常既昂贵又不切实际——如果不是不可能的话——因此效用有限。因果推理方法本质上是模仿 RCT,而无需做任何事情,这使得它们的执行难度大大降低,但有许多限制和陷阱可能使结果无效。总体而言,因果关系仍然是一个令人沮丧的追求,其中当前的方法通常不能满足我们想要提出的问题,除非这些问题可以通过随机对照试验进行探索,或者它们恰好适合某些框架(例如,作为 “自然实验” 的偶然结果)。联邦学习(FL)是一个很酷的概念,却很少受到关注 - 可能是因为它最引人注目的应用程序需要分发到大量智能手机设备,因此 FL 只有两个参与者才能真正研究:Apple 和谷歌。FL 存在其他用例,例如汇集专有数据集,但协调这些举措存在政治和后勤挑战,限制了它们在实践中的效用。尽管如此,对于听起来像是一个奇特的概念(大致概括为:“将模型引入数据,而不是将数据引入模型”),FL 是有效的,并且在键盘文本预测和个性化新闻推荐等领域有切实的成功案例. FL 背后的基本理论和技术似乎足以让 FL 得到更广泛的应用。强化学习(RL)在国际象棋、围棋、扑克和 DotA 等游戏中达到了前所未有的能力水平。但在视频游戏和模拟环境之外,强化学习还没有令人信服地转化为现实世界的应用程序。机器人技术本应成为 RL 的下一个前沿领域,但这并没有实现——现实似乎比高度受限的玩具环境更具挑战性。也就是说,到目前为止,RL 的成就是鼓舞人心的,真正喜欢国际象棋的人可能会认为它的效用应该更高。我希望看到 RL 在将其置于矩阵右侧之前实现其一些潜在的实际应用。左下象限:低理解,低效用图神经网络(GNN)现在是机器学习中一个非常热门的领域,在多个领域都取得了可喜的成果。但是对于其中许多示例,尚不清楚 GNN 是否比使用更传统的结构化数据与深度学习架构配对的替代方法更好。数据自然是图结构的问题,例如化学信息学中的分子,似乎具有更引人注目的 GNN 结果(尽管这些通常不如非图相关的方法)。与大多数领域相比,用于大规模训练 GNN 的开源工具与工业中使用的内部工具之间似乎存在很大差异,这限制了大型 GNN 在这些围墙花园之外的可行性。该领域的复杂性和广度表明理论上限很高,因此 GNN 应该有成熟的空间并令人信服地展示某些任务的优势,这将导致更大的实用性。GNN 也可以从技术进步中受益,因为图目前不能自然地适用于现有的计算硬件。可解释的机器学习(IML)是一个重要且有前途的领域,并继续受到关注。SHAP 和 LIME 等技术已经成为真正有用的工具来询问 ML 模型。然而,由于采用有限,现有方法的效用尚未完全实现——尚未建立健全的最佳实践和实施指南。然而,IML 目前的主要弱点是它没有解决我们真正感兴趣的因果问题。IML 解释了模型如何进行预测,但没有解释基础数据如何与它们因果关系(尽管经常被错误地解释像这样)。在取得重大理论进展之前,IML 的合法用途大多仅限于模型调试 / 监控和假设生成。量子机器学习(QML)远远超出我的驾驶室,但目前似乎是一个假设性的练习,耐心等待可行的量子计算机可用。在那之前,QML 微不足道地坐在左下角。渐进式进步、技术飞跃和范式转变领域内主要通过三种主要机制来遍历理论理解与经验效用矩阵(图 2)。字段可以遍历矩阵的方式的说明性示例。渐进式进展是缓慢而稳定的进展,它在矩阵的右侧向上移动英寸场。过去几十年的监督机器学习就是一个很好的例子,在此期间,越来越有效的预测算法被改进和采用,为我们提供了我们今天喜欢的强大工具箱。渐进式进步是所有成熟领域的现状,除了由于技术飞跃和范式转变而经历更剧烈运动的时期之外。由于由于技术的飞跃,一些领域看到了科学进步的阶梯式变化。* 深度学习 * 领域并没有被它的理论基础所解开,这些基础是在 2010 年代深度学习热潮之前 20 多年发现的——它是由消费级 GPU 支持的并行处理推动了它的复兴。技术飞跃通常表现为沿经验效用轴向右跳跃。然而,并非所有以技术为主导的进步都是飞跃。今天的深度学习的特点是通过使用更多的计算能力和越来越专业的硬件训练越来越大的模型来实现渐进式进步。在这个框架内科学进步的最终机制是范式转变。正如托马斯 · 库恩(Thomas Kuhn)在他的著作《科学革命的结构》中所指出的,范式转变代表了科学学科的基本概念和实验实践的重要变化。Donald Rubin 和 Judea Pearl 开创的因果框架就是这样一个例子,它将因果关系领域从随机对照试验和传统统计分析提升为更强大的数学化学科,形式为因果推理。范式转变通常表现为理解的向上运动,这可能会跟随或伴随着效用的增加。然而,范式转换可以在任何方向上遍历矩阵。当神经网络(以及随后的深度神经网络)将自己确立为传统 ML 的独立范式时,这最初对应于实用性和理解力的下降。许多新兴领域以这种方式从更成熟的研究领域分支出来。预测和深度学习的科学革命总而言之,以下是我认为未来可能发生的一些推测性预测(表 1)。右上象限中的字段被省略,因为它们太成熟而看不到重大进展。表 1:机器学习几大领域未来进展预测。然而,比个别领域如何发展更重要的观察是经验主义的总体趋势,以及越来越愿意承认全面的理论理解。从历史经验上看,一般是理论(假设)先出现,然后再制定想法。但深度学习引领了一个新的科学过程,颠覆了这一点。也就是说,在人们关注理论之前,方法就有望展示最先进的性能。实证结果为王,理论是可选的。这导致了机器学习研究中系统的广泛博弈,通过简单地修改现有方法并依靠随机性来超越基线,而不是有意义地推进该领域的理论,从而获得了最新的最新成果。但也许这就是我们为新一波机器学习繁荣付出的代价。图 3:2022 年深度学习发展的 3 个潜在轨迹。深度学习是否不可逆转地以结果为导向的过程并将理论理解降级为可选的 2022 年可能是转折点。我们应该思考如下几个问题:理论突破是否会让我们的理解赶上实用性,并将深度学习转变为像传统机器学习一样更有条理的学科?现有的深度学习文献是否足以让效用无限地增加,仅仅通过扩展越来越大的模型?或者,一个经验性的突破会带领我们进一步深入兔子洞,进入一种增强效用的新范式,尽管我们对这种范式了解得更少?这些路线中的任何一条都通向通用人工智能吗?只有时间能给出答案。原文链接:https://www.aidancooper.co.uk/utility-vs-understanding/?continueFlag=b96fa8ed72dfc82b777e51b7e954c7dc准备写本书如何评判一个深度学习框架?Pytorch 常用损失函数拆解吴恩达最新采访:以数据为中心的AI【机器学习基础】优化背后的数学基础三连在看,月入百万👇 浏览 40点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 机器学习理论基础到底有多可靠?数据派THU0机器学习理论基础到底有多可靠?数据分析14800机器学习理论基础到底有多可靠?Datawhale0关于机器学习这门炼丹术,理论基础到底有多可靠?新机器视觉0统计学和机器学习到底有什么区别?i小码哥0统计学和机器学习到底有什么区别?Datawhale0统计学和机器学习到底有什么区别?小白学视觉0统计学和机器学习到底有什么区别?数据派THU0统计学和机器学习到底有什么区别?Python大数据分析0学习环境的理论基础《学习环境的理论基础》收集了当前有关学习和意义建构理论的描述,其中包括基于模型的推理、概念转变、论辩点赞 评论 收藏 分享 手机扫一扫分享分享 举报