
针对初学者的循环神经网络介绍

Python部落(python.freelycode.com)组织翻译,欢迎转发。
简单介绍什么是RNN,它们如何运行,以及如何用Python从头构建一个RNN。
循环神经网络(RNN)是一种专门处理序列的神经网络。它们通常用于自然语言处理(NLP)任务,因为它们在处理文本方面非常有效。在本文中,我们将探索什么是RNN,了解它们是如何工作的,并使用Python从头构建一个真正的RNN(仅使用numpy库)。
这篇文章假设你有神经网络的基本知识。我对神经网络的介绍涵盖了你需要知道的一切,所以我建议你先读一下(https://victorzhou.com/blog/intro-to-neural-networks/ )。
我们开始吧!
1. 为什么有用
标准神经网络(以及CNN)的一个问题是,它们只能处理预先确定的大小: 它们接受固定大小的输入并产生固定大小的输出。RNN是有用的,因为它允许我们使用可变长度的序列作为输入和输出。下面是一些RNN的例子:

输入为红色,RNN本身为绿色,输出为蓝色。来源:Andrej Karpathy
这种处理序列的能力使RNN非常有用。例如:
机器翻译(比如谷歌翻译)是通过“多对多”RNN完成的。原始文本序列被输入一个RNN,然后该RNN会生成翻译文本作为输出。
情感分析 (例如,这是一个积极的还是消极的评论?)通常是通过“多对一” 的RNN完成的。要分析的文本被输入一个RNN,然后该RNN会生成一个单独的输出分类(例如,这是一个积极的评论)。
在本文的后面,我们将从头构建一个“多对一”的RNN来执行基本的情感分析。
2. 工作原理
我们假设有一个带有输入x0,x1,...xn的“多对多”的RNN,我们希望它产生输出y0,y1,...yn。这些xi 和yi是向量,可以有任意的维数。
RNN利用以任意给定的步长t反复地更新一个隐藏状态h来运行,h是一个向量,也可以有任意的维数。
下一个隐藏状态ht是使用前一个隐藏状态ht -1和下一个输入xt进行计算的。
下一个输出yt是使用ht进行计算的。

一个多对多RNN
这就是使RNN循环的东西: 它对每个步骤使用相同的权重。具体来说,一个典型的标准RNN只使用3组权重来进行计算:
Wxh, 用于所有的 xt → ht 连接。
Whh, 用于所有的 ht-1 → ht 连接。
Why, 用于所有的 ht → yt 连接。
我们也对我们的RNN使用两个偏差:
bh,计算ht时加上。
by, 计算yt时加上。
我们用矩阵表示权重,用向量表示偏差。这3个权重和2个偏差就构成了整个RNN!
下面是把所有东西放在一起的方程式:
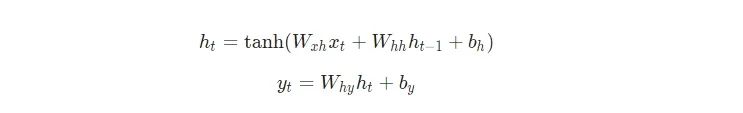
不要略过这些方程。停下来,盯着这个方程看一分钟。另外,记住权重是矩阵,其它变量是向量。
所有的权重都使用矩阵乘法进行应用,并将偏差加到结果乘积中。然后,我们使用tanh作为第一个方程的激活函数(其它激活函数像sigmoid也可以使用)。
不知道什么是激活函数?请认真阅读我之前提到的神经网络介绍。
3. 要解决的问题
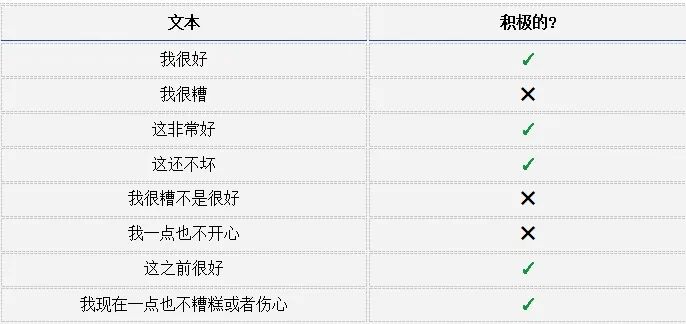
我们来动手干吧!我们将从头实现一个RNN来执行一个简单的情感分析任务: 确定给定的文本字符串是积极的还是消极的。
下面是我为本文收集的小数据集中的一些例子:
4. 计划
由于这是一个分类问题,我们将使用“多对一" RNN。这与我们前面讨论的“多对多”RNN类似,只不过它只使用最终的隐藏状态来产生一个输出y:
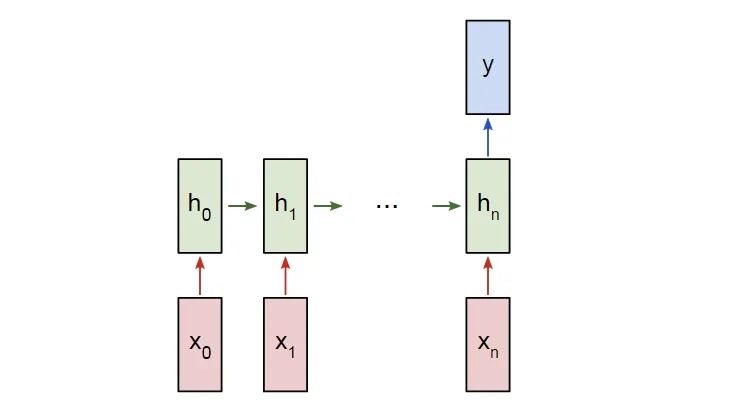
一个多对一RNN
每个xi都是一个向量,表示文本中的一个单词。输出y将是一个包含两个数字的向量,一个表示积极的,另一个表示消极的。我们将使用Softmax将这些值转换为概率,并最终在积极的/消极的之间进行决定。
我们来开始构建我们的RNN!
5. 预处理
我前面提到的数据集由两个Python字典组成:

True=积极的,False=消极的
我们必须做一些预处理才能把数据转换成可用的格式。首先,我们将构造一个包含我们数据中所有单词的词汇表:

vocab现在包含了至少在一个训练文本中出现的所有单词的列表。接下来,我们将分配一个整数索引来表示vocab中的每个单词。
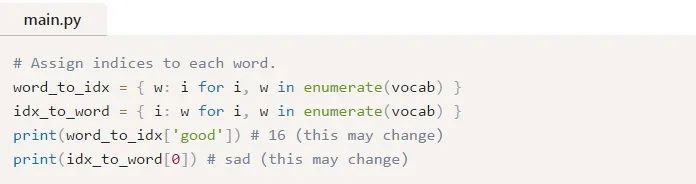
我们现在可以用对应的整数索引表示任意给定的单词!这是必要的,因为RNN不能理解单词——我们必须给它们提供数字。
最后,回想一下RNN的每个输入xi都是一个向量。我们将使用one-hot向量,它除了包含一个1之外,其余值都是0。每个one-hot向量中的“1”将位于这个单词对应的整数索引处。
由于我们的词汇表中有18个唯一的单词,每个xi将是一个18维的one-hot向量。

稍后,我们将使用createInputs()来创建向量输入,并将其传入我们的RNN。
6. 正向阶段
是时候开始实现我们的RNN了!我们将从初始化我们的RNN所需要的3个权重和2个偏差开始:
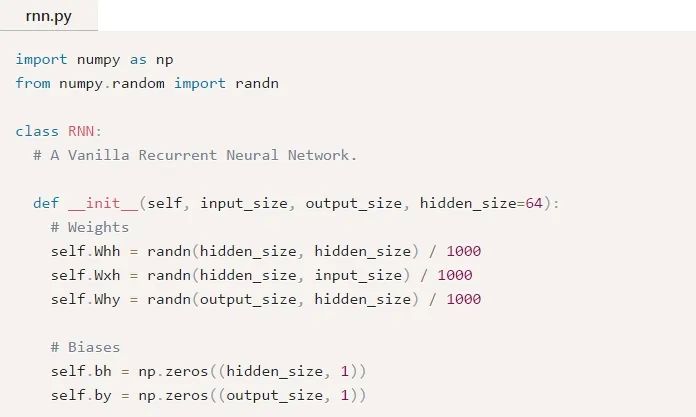
注意:我们除以1000是为了减小权重的初始方差。这并不是初始化权重的最佳方法,但它很简单,适合本文。
我们使用np.random.randn()从标准正态分布来初始化我们的权重。
接下来,我们来实现RNN的正向传递。还记得我们之前看到的这两个方程吗?
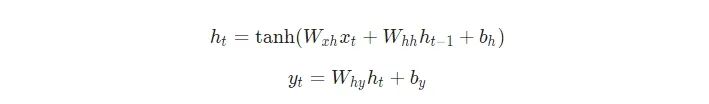
下面是这些同样的方程被写入代码中的形式:
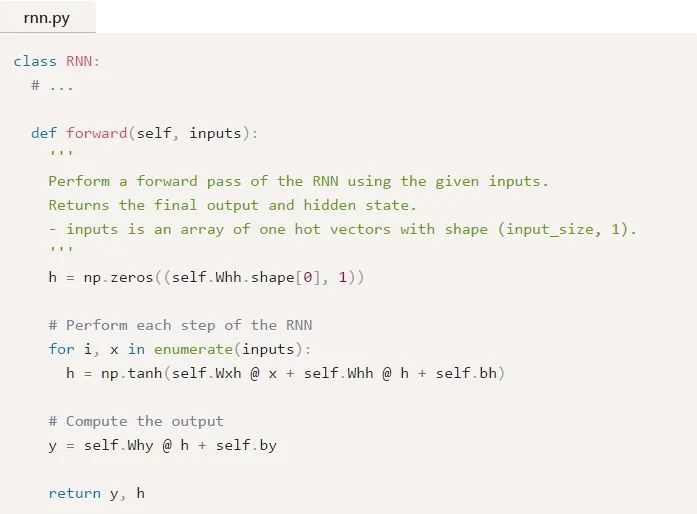
很简单,对吧?注意,我们在第一步中将h初始化为零向量,因为此时没有可以供我们使用的前一个h。
让我们来试试:
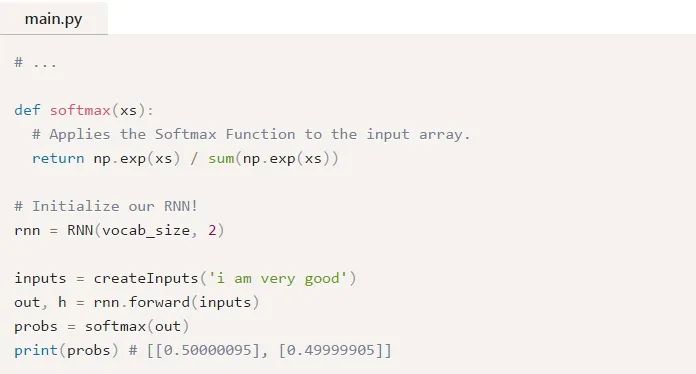
如果你需要复习一下Softmax,请阅读我对Softmax的简要说明。
我们的RNN可以运行,但还不是很有用。我们来改变这一点……
7. 逆向阶段
为了训练我们的RNN,我们首先需要一个损失函数。我们将使用交叉熵损失函数,它通常与Softmax配对使用。我们是这样计算它的:
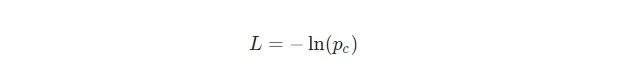
其中pc 是我们的RNN对正确类(积极的或消极的)的预测概率。例如,如果一个积极的文本被我们的RNN预测为90%的积极度,则损失为:
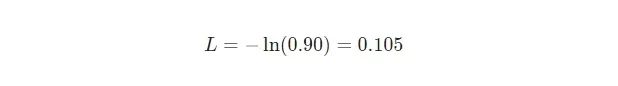
现在我们有了一个损失,我们将使用梯度下降训练我们的RNN来最小化损失。这意味着是时候推导一些梯度了!
⚠️以下部分假设你有多变量微积分的基本知识。如果你愿意,你可以跳过它,但我建议即使你不太明白也要略读一下。我们将在推导结果时逐步编写代码,即使表面的理解也会有所帮助。
如果你想了解这部分的额外背景知识,我建议你先阅读我的《神经网络介绍》中的《训练神经网络》部分。此外,这篇文章的所有代码都在Github上,所以如果你愿意,你可以follow它。
准备好了吗?我们开始吧。
7.1 定义
首先,我们来看一些定义:
让 y代表来自我们RNN的原始输出。
让p代表最终的概率:p=softmax(y).
让c 指代一个特定文本例子的真实标签,也可以说是“正确的”类。
让L代表交叉熵损失:L=-ln(pc)
让Wxh 、Whh 和Why代表我们的RNN中的3个权重矩阵。
让bh和by 代表我们的RNN中的两个偏差向量。
7.2设置
接下来,我们需要编辑正向阶段来缓存一些数据,以便在反向阶段中使用。在此过程中,我们还将为反向阶段设置骨架。它是这样的:

想知道我们为什么要进行缓存吗?请阅读我在我的CNN介绍的训练概述中的说明。我在其中做了同样的事情。
7.3梯度
是用到数学的时候了!我们从计算∂L/∂y开始。我们知道:
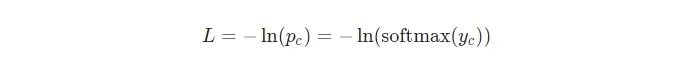
我将把使用链式法则推导∂L/∂y的过程留给你,但是推导出来的结果是漂亮的:
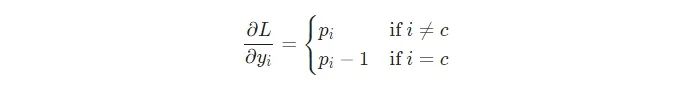
例如,如果我们有p = [0.2, 0.2, 0.6],并且其正确的类是c=0,那么我们就会得到 ∂L/∂y=[−0.8,0.2,0.6] 。这转换称代码也是很容易的:
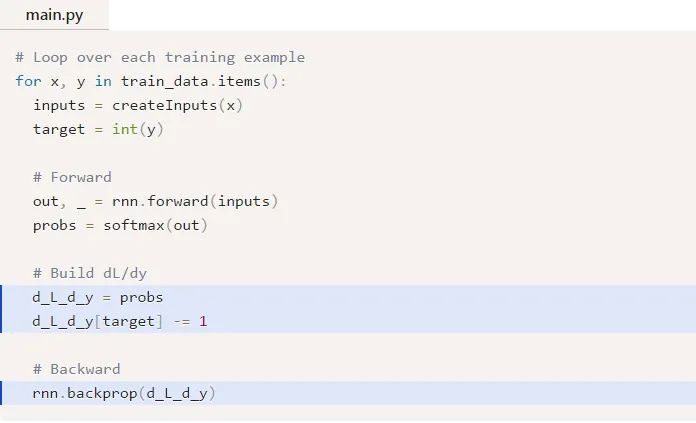
漂亮!下一步,我们来为Why和by尝试一下梯度,它们的梯度只用与将最终的隐藏状态转换为RNN的输出。我们有:

式中,hn是最终的隐藏状态,因此,
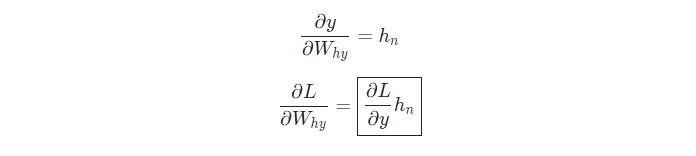
类似地,
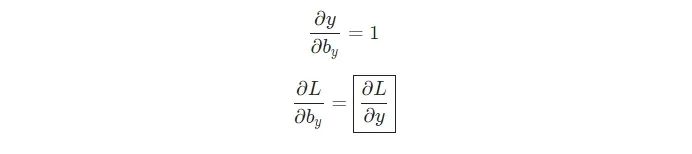
现在,我们可以开始实现 backprop()!

提醒: 我们之前在forward()中创建了self.last_hs。
最后,我们需要Whh 、Wxh 和bh的权重,它们将在RNN中的每一步使用。我们有:
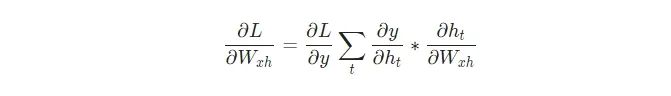
因为改变Wxh会影响每一个ht ,而每一个ht都会影响y,并最终影响L。为了完全计算Wxh的梯度,我们需要反向传播所有的步长,这也被称为随时间反向传播(BPTT):

随时间进行的反向传播
Wxh被用于所有的xt —> ht 正向连接,因此我们必须反向传播回这些连接的每一个。
一旦我们到达了一个给定的步长t,我们需要计算∂ht/∂Wxh
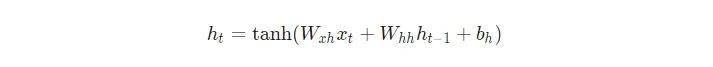
tanh的推导是众所周知的:
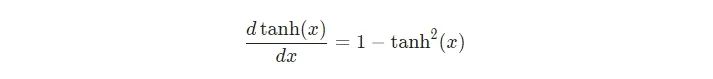
我们和平常一样使用链式法则:

类似地,
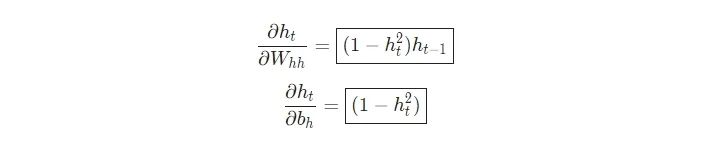
我们需要的最后一个东西是∂y/∂ht,我们可以递归地计算它:

我们将从最后的隐藏状态开始,并逆向运行来实现BPTT,这样当我们想要计算∂y/∂ht+1的时候我们就已经有了∂y/∂ht!最后的隐藏状态hn是一个例外:
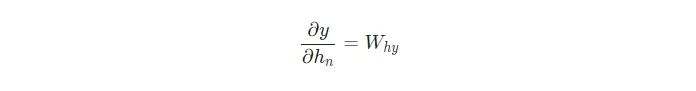
现在我们有了最终实现BPTT和完成backprop()所需要的所有东西:


一些需要注意的东西:
为了方便起见,我们已经将(∂L/∂y)*(∂y/∂h)合并到 ∂L/∂h中了。
我们需要不断地更新一个保存最近的∂L/∂ht+1值的变量d_h,我们计算∂L/∂ht需要用到这个值。
在完成BPTT之后,我们使用np.clip()截取小于-1或大于1的梯度值。这有助于缓解梯度爆炸问题,这是因为有很多相乘项时,梯度就会变的非常大。对于普通的RNN来说,梯度爆炸或梯度消失是很有问题的——像LSTM这样更复杂的RNN通常能够很好地处理它们。
一旦所有的梯度被计算出,我们就使用梯度下降来更新权重和偏差。
我们做到了!我们的RNN是完整的。
8. 高潮
终于到了我们一直等待的时刻——我们来测试我们的RNN!
首先,我们将编写一个辅助函数来使用我们的RNN处理数据:
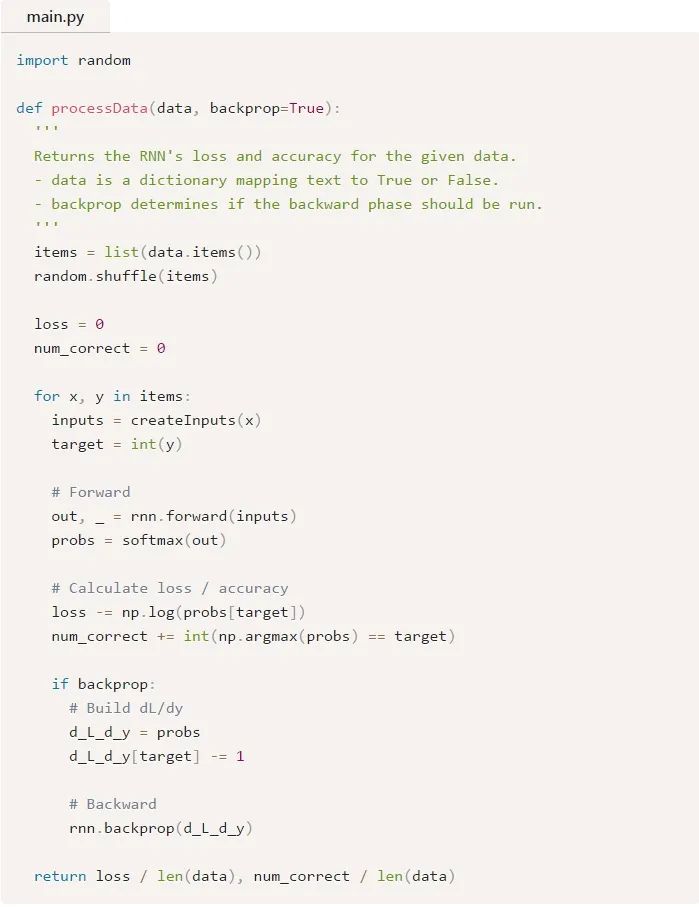
现在,我们可以编写训练循环:
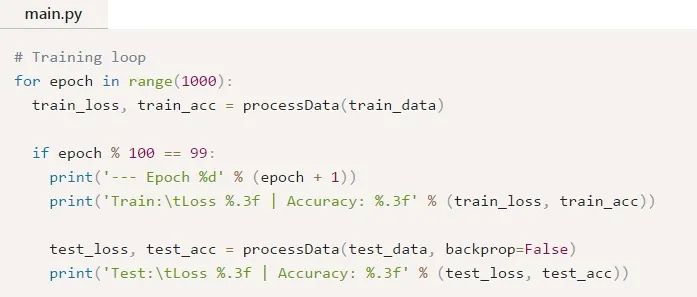
运行main.py应该会输出如下内容:
从结果来看我们自己建立的RNN还不错。
想自己尝试或修改这段代码吗?请在浏览器中运行这个RNN(https://repl.it/@vzhou842/A-RNN-from-scratch)。你也可以在Github上找到它。(https://github.com/vzhou842/rnn-from-scratch)
9. 结尾
就是这样!在这篇文章中,我们完成了一个循环神经网络的一个演示,包括它们是什么,它们是如何工作的,它们为什么有用,如何训练它们,以及如何实现一个。虽然如此,你还有很多事情可以做:
学习长短期记忆网络,一个更强大更流行的RNN架构,或者学习门控循环单元(GRU),一个著名的LSTM变体。
使用合适的ML库(比如Tensorflow、 Keras或 PyTorch)对更大/更好的RNN进行实验。
阅读关于双向RNN的内容。它会正向和反向处理序列,因此,有更多的信息对于输出层来说是可用的。
尝试词嵌入(比如 GloVe 或 Word2Vec),你可以使用它们将单词转换成更有用的向量表示形式。
尝试自然语言工具集(NLTK),一个流行的处理人类语言数据的Python库。
我写了很多关于机器学习的文章,所以如果你有兴趣从我这里获得前沿的ML内容,请订阅我的时事通讯。
英文原文:https://victorzhou.com/blog/intro-to-rnns/
↓扫描关注本号↓