
FaceNet人脸识别(一)
与其他的深度学习方法在人脸上的应用不同,FaceNet并没有用传统的softmax的方式去进行分类学习,然后抽取其中某一层作为特征,而是直接进行端对端学习一个从图像到欧式空间的编码方法,然后基于这个编码再做人脸识别、人脸验证和人脸聚类等。
FaceNet算法有如下要点:
去掉了最后的softmax,而是用元组计算距离的方式来进行模型的训练。使用这种方式学到的图像表示非常紧致,使用128位足矣。
元组的选择非常重要,选的好可以很快的收敛。
对于整个FaceNet结构,这里的特征提取可以当作一个黑盒子,可以采用各式各样的网络。最早的FaceNet采用两种深度卷积网络:经典Zeiler&Fergus架构和Google的Inception v1。最新的FaceNet进行了改进,主体模型采用一个极深度网络Inception ResNet -v2,由3个带有残差连接的Inception模块和1个Inceptionv4模块组成。
FaceNet 结构
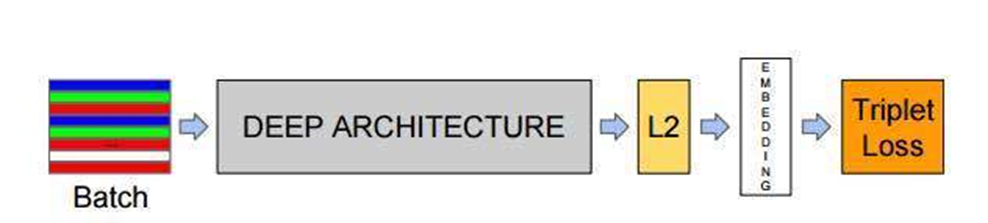
从上面的图中可以看到,整个FaceNet分为5个部分,具体表示如下:
batch :是指输入的人脸图像样本,这里的样本是已经经过人脸检测找到人脸并裁剪到固定尺寸(例如160x160)的图片样本。
Deep architecture:指的是采用一种深入学习架构例如imagenet历年冠军网络中的VGG,GoogleNet等,本文中我们将使用MoblieNetv2 作为主要的特征提取网络。
L2 :是指特征归一化(使其特征的||f(x)||2=1,这里是2次方的意思。这样所有图像的特征都会被映射到一个超球面上)
Embeddings:就是前面经过深度学习网络,L2归一化后生成的特征向量(这个特征向量就代表了输入的一张样本图片)
Triplet Loss:就是有三张图片输入的Loss(之前的都是Double Loss或者 是 SingleLoss)。直接学习特征间的可分性:相同身份之间的特征距离要尽可能的小,而不同身份之间的特征距离要尽可能的大
主体网络更改
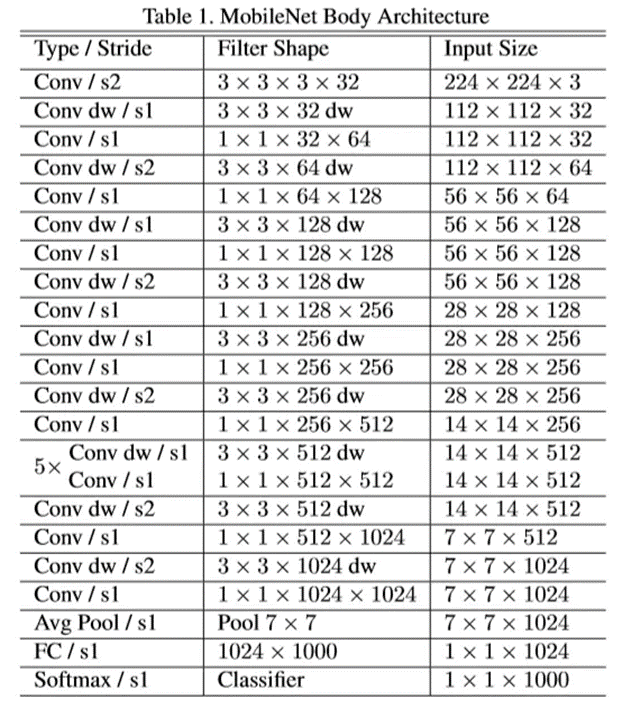
这里我们需要提及两个比较重要的点,我们将使用MoblieNet替换原本的网络,这是是谷歌在2017年提出,是一款专注在移动设备和嵌入式设备上的轻量级CNN神经网络,并迅速衍生了V1 V2以及V3版本,它相比于传统的CNN网络,在准确率小幅减低的前提下,大大减少模型参数的运算量。模型结构如下:
Triplet Loss
另一个是Triplet Loss,在深度学习中,很多度量学习的方法都是使用成对成对的样本进行loss计算的,这类方法被称为 pair-based deep metric learning。例如,在训练模型的过程,我们随意的选取两个样本,使用模型提取特征,并计算他们特征之间的距离。如果这两个样本属于同一个类别,那我们希望他们之间的距离应该尽量的小,甚至为0;如果这两个样本属于不同的类别,那我们希望他们之间的距离应该尽量的大,甚至是无穷大。正是根据这一原则,衍生出了许多不同类型的pair-based loss,使用这些loss对样本对之间的距离进行计算,并根据生成的loss使用各种优化方法对模型进行更新。
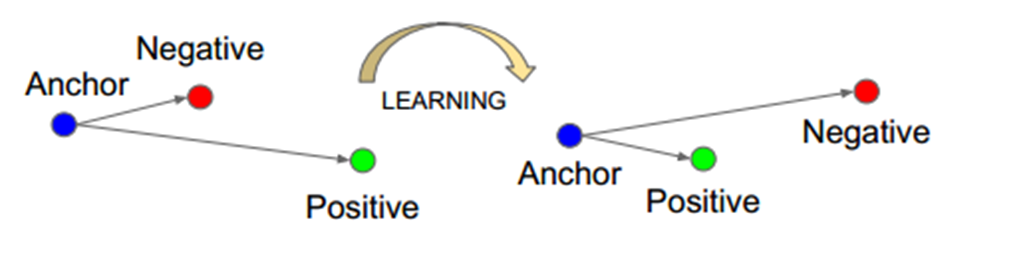
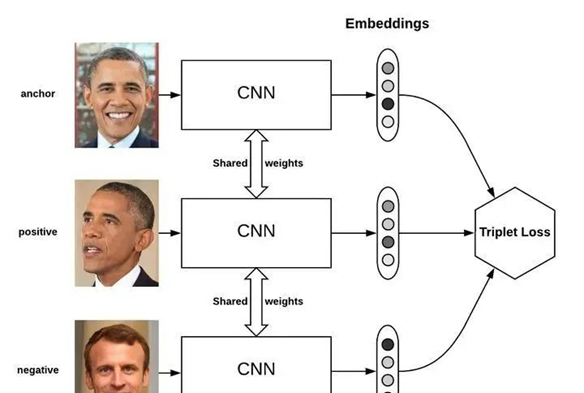
其中,使用最为广泛的就当属三元组损失了(Triplet loss),Triplet Loss的思想是让负样本对之间的距离大于正样本对之间的距离,在训练过的过程中同时选取一对正样本对和负样本对,且正负样本对中有一个样本是相同的。以狗、狼、猫数据为例,首先随机选取一个样本,此样本称之为anchor 样本,假设此样本类别为狗,然后选取一个与anchor样本同类别的样本(另一个狗狗),称之为positive,并让其与anchor样本组成一个正样本对(anchor-positive);再选取一个与anchor不同类别的样本(猫),称之为negative,让其与anchor样本组成一个负样本对(anchor-negative)。这样一共选取了三个样本,这也是为什么叫triplet的原因了。
Triplet Loss 的公式如下,通过公式可以看出,当负样本对之间的距离比正样本对之间的距离大m的时候,loss为0 ,认为当前模型已经学的不错了,所以不对模型进行更新。
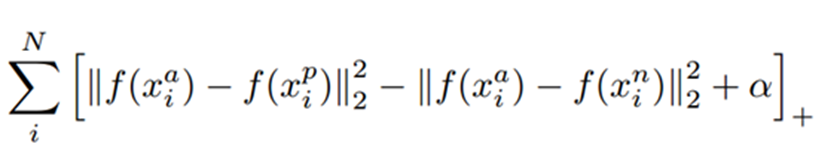
Triplet Loss最先被用于人脸识别中,如下图,输入一个triplet对(三张图像),使用同一个网络对这个三张图像进行特征提取,得到三个embedding向量,三个向量输入到Triplet Loss中得到loss,然后根据loss值使用反向传播算法对模型进行更新。
对于FaceNet的网络结构解析就到这里了,下个推文中我们将对数据进行解析,并进行处理,喜欢的可以继续关注哦!