
Dive into Delta Lake | Delta Lake 尝鲜
点击上方蓝色字体,选择“设为星标”




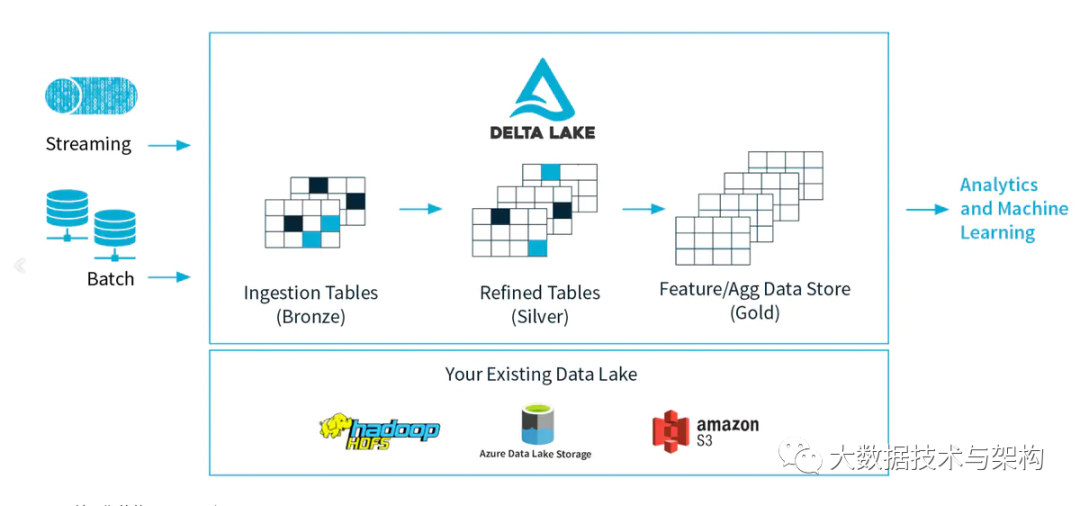
Delta Lake 是一个存储层,为 Apache Spark 和大数据 workloads 提供 ACID 事务能力,其通过写和快照隔离之间的乐观并发控制(optimistic concurrency control),在写入数据期间提供一致性的读取,从而为构建在 HDFS 和云存储上的数据湖(data lakes)带来可靠性。Delta Lake 还提供内置数据版本控制,以便轻松回滚。
为什么需要Delta Lake
现在很多公司内部数据架构中都存在数据湖,数据湖是一种大型数据存储库和处理引擎。它能够存储大量各种类型的数据,拥有强大的信息处理能力和处理几乎无限的并发任务或工作的能力,最早由 Pentaho 首席技术官詹姆斯迪克森在2011年的时候提出。虽然数据湖在数据范围方面迈出了一大步,但是也面临了很多问题,主要概括如下:
数据湖的读写是不可靠的。数据工程师经常遇到不安全写入数据湖的问题,导致读者在写入期间看到垃圾数据。他们必须构建方法以确保读者在写入期间始终看到一致的数据。
数据湖中的数据质量很低。将非结构化数据转储到数据湖中是非常容易的。但这是以数据质量为代价的。没有任何验证模式和数据的机制,导致数据湖的数据质量很差。因此,努力挖掘这些数据的分析项目也会失败。
随着数据的增加,处理性能很差。随着数据湖中存储的数据量增加,文件和目录的数量也会增加。处理数据的作业和查询引擎在处理元数据操作上花费大量时间。在有流作业的情况下,这个问题更加明显。
数据湖中数据的更新非常困难。工程师需要构建复杂的管道来读取整个分区或表,修改数据并将其写回。这种模式效率低,并且难以维护。
由于存在这些挑战,许多大数据项目无法实现其愿景,有时甚至完全失败。我们需要一种解决方案,使数据从业者能够利用他们现有的数据湖,同时确保数据质量。这就是 Delta Lake 产生的背景。
Delta Lake特性
Delta Lake 很好地解决了上述问题,以简化我们构建数据湖的方式。
支持ACID事务
Delta Lake 在多并发写入之间提供 ACID 事务保证。每次写入都是一个事务,并且在事务日志中记录了写入的序列顺序。
事务日志跟踪文件级别的写入并使用乐观并发控制,这非常适合数据湖,因为多次写入/修改相同的文件很少发生。在存在冲突的情况下,Delta Lake 会抛出并发修改异常以便用户能够处理它们并重试其作业。
Delta Lake 还提供强大的可序列化隔离级别,允许工程师持续写入目录或表,并允许消费者继续从同一目录或表中读取。读者将看到阅读开始时存在的最新快照。
Schema管理
Delta Lake 自动验证正在被写的 DataFrame 模式是否与表的模式兼容。
表中存在但 DataFrame 中不存在的列会被设置为 null 如果 DataFrame 中有额外的列在表中不存在,那么该操作将抛出异常 Delta Lake 具有可以显式添加新列的 DDL 和自动更新Schema 的能力 可伸缩的元数据处理
Delta Lake 将表或目录的元数据信息存储在事务日志中,而不是存储在元存储(metastore)中。这使得 Delta Lake 能够在固定的时间内列出大型目录中的文件,并且在读取数据时非常高效。
数据版本
Delta Lake 允许用户读取表或目录之前的快照。当文件被修改文件时,Delta Lake 会创建较新版本的文件并保留旧版本的文件。当用户想要读取旧版本的表或目录时,他们可以在 Apache Spark 的读取 API 中提供时间戳或版本号,Delta Lake 根据事务日志中的信息构建该时间戳或版本的完整快照。这允许用户重现之前的数据,并在需要时将表还原为旧版本的数据。
统一的批处理和流 sink
除了批处理写之外,Delta Lake 还可以使用作为 Apache Spark structured streaming 高效的流 sink。再结合 ACID 事务和可伸缩的元数据处理,高效的流 sink 现在支持许多接近实时的分析用例,而且无需维护复杂的流和批处理管道。
数据存储格式采用开源 Apache Parquet
Delta Lake 中的所有数据都是使用 Apache Parquet 格式存储,使 Delta Lake 能够利用 Parquet 原生的高效压缩和编码方案。
更新和删除
Delta Lake 支持 merge, update 和 delete 等 DML 命令。这使得数据工程师可以轻松地在数据湖中插入/更新和删除记录。由于 Delta Lake 以文件级粒度跟踪和修改数据,因此它比读取和覆盖整个分区或表更有效。
数据异常处理
Delta Lake 还将支持新的 API 来设置表或目录的数据异常。工程师能够设置一个布尔条件并调整报警阈值以处理数据异常。当 Apache Spark 作业写入表或目录时,Delta Lake 将自动验证记录,当数据存在异常时,它将根据提供的设置来处理记录。
兼容 Apache Spark API
开发人员可以将 Delta Lake 与他们现有的数据管道一起使用,仅需要做一些细微的修改。
基本使用
Create a table
val data = spark.range(0, 5)
data.write.format("delta").save("/tmp/delta-table")
// 分区表
df.write.format("delta").partitionBy("date").save("/delta/events")Read table
val df = spark.read.format("delta").load("/tmp/delta-table")
df.show()Update table
// overwrite
val data = spark.range(5, 10)
data.write.format("delta").mode("overwrite").save("/tmp/delta-table")// update
import io.delta.tables._
import org.apache.spark.sql.functions._
val deltaTable = DeltaTable.forPath("/tmp/delta-table")
// Update every even value by adding 100 to it
deltaTable.update(
condition = expr("id % 2 == 0"),
set = Map("id" -> expr("id + 100")))
// Delete every even value
deltaTable.delete(condition = expr("id % 2 == 0"))
// Upsert (merge) new data
val newData = spark.range(0, 20).as("newData").toDF
deltaTable.as("oldData")
.merge(
newData,
"oldData.id = newData.id")
.whenMatched
.update(Map("id" -> col("newData.id")))
.whenNotMatched
.insert(Map("id" -> col("newData.id")))
.execute()
deltaTable.toDF.show()// update by expressions
import io.delta.tables._
val deltaTable = DeltaTable.forPath(spark, pathToEventsTable)
// predicate and update expressions using SQL formatted string
deltaTable.updateExpr(
"eventType = 'clck'",
Map("eventType" -> "'click'")// merge
deltaTable
.as("logs")
.merge(
updates.as("updates"),
"logs.uniqueId = updates.uniqueId")
.whenNotMatched()
.insertAll()
.execute()Delete table
import io.delta.tables._
val deltaTable = DeltaTable.forPath(spark, pathToEventsTable)
deltaTable.delete("date < '2017-01-01'") // predicate using SQL formatted string
import org.apache.spark.sql.functions._
import spark.implicits._
deltaTable.delete($"date" < "2017-01-01") // predicate using Spark SQL functions and implicits流支持
查询表的旧快照
Delta Lake 时间旅行允许您查询 Delta Lake 表的旧快照。时间旅行有很多用例,包括:
重新创建分析,报告或输出(例如,机器学习模型的输出)。这对于调试或审计非常有用,尤其是在受监管的行业中
编写复杂的临时查询
修复数据中的错误
为快速更改的表的一组查询提供快照隔离 DataFrameReader options 允许从 Delta Lake 表创建一个DataFrame 关联到表的特定版本,可以使用如下两种方式:
df1 = spark.read.format("delta").option("timestampAsOf", timestamp_string).load("/delta/events")
df2 = spark.read.format("delta").option("versionAsOf", version).load("/delta/events")对于timestamp_string,仅接受日期或时间戳字符串。例如,2019-01-01 和 2019-01-01 00:00:00.000Z
增加列
当以下任意情况为 true 时,DataFrame 中存在但表中缺少的列将自动添加为写入事务的一部分:
write 或 writeStream 具有 .option("mergeSchema", "true") 添加的列将附加到它们所在的结构的末尾。附加新列时将保留大小写。
NullType 列
写入 Delta 时,会从 DataFrame 中删除 NullType 列(因为 Parquet 不支持 NullType)。当收到该列的不同数据类型时,Delta Lake 会将 schema 合并到新数据类型
默认情况下,覆盖表中的数据不会覆盖 schema。使用模式 overwrite 覆盖表而不使用 replaceWhere 时,可能仍希望覆盖正在写入的数据的 schema。可以通过设置以下内容来选择替换表的 schema :
df.write.option("overwriteSchema", "true")视图
Transactional meta 实现
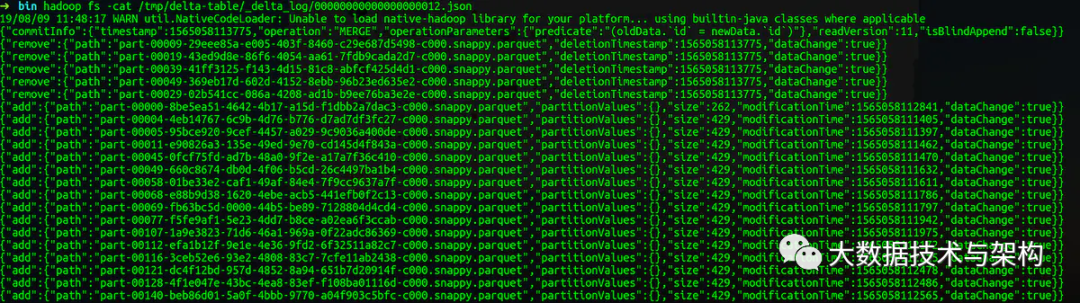
在文件上增加一个日志结构化存储(transaction log ),该日志有序(ordered)且保持原子性(atomic)。
增加或者删除数据时,都会产生一个描述文件,采用乐观并发控制 (optimistic concurrency control) 保证用户并发操作时数据的一致性。
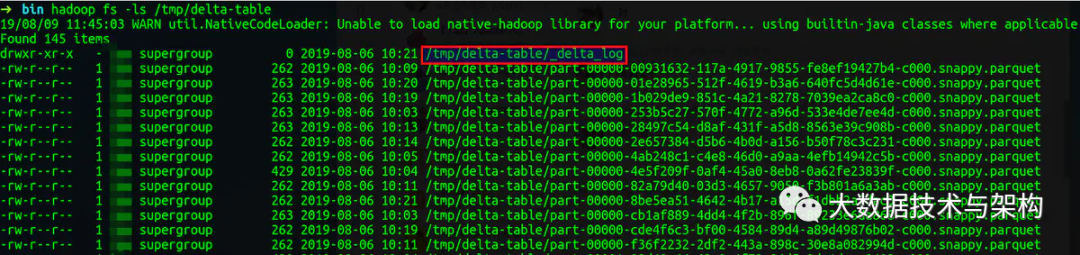
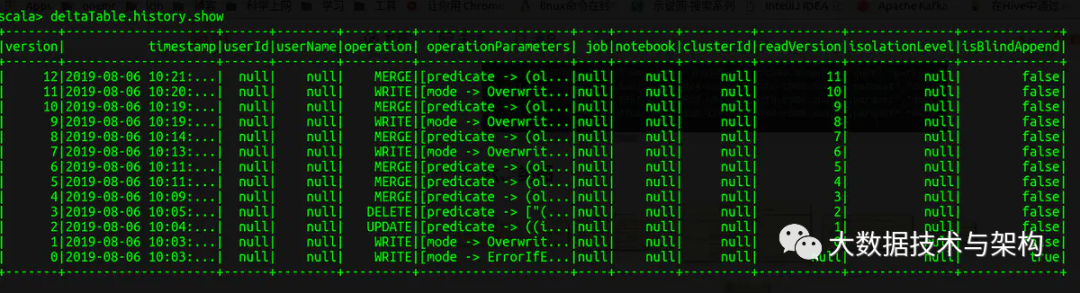
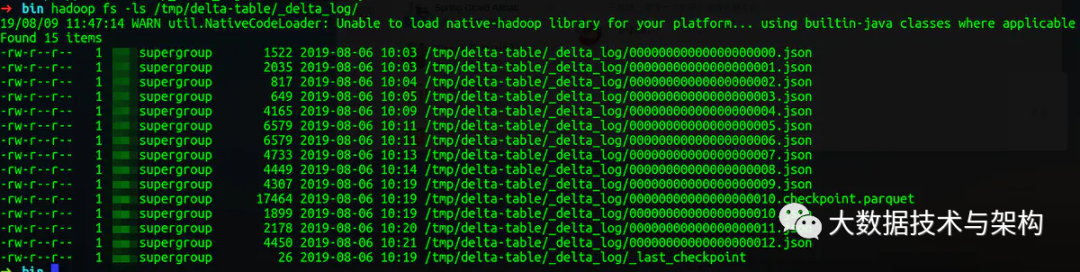
每次表更都生产一个描述文件,描述文件的记录数和历史版本数量一致。如图,delta-table表13个历史版本就有13个描述文件。
并发控制
Delta Lake 在读写中提供了 ACID 事务保证。这意味着:
跨多集群的并发写入,也可以同时修改数据集并查看表的一致性快照,这些写入操作将按照串行执行
在作业执行期间修改了数据,读取时也能看到一致性快照。
乐观并发控制
Delta Lake 使用 optimistic concurrency control 机制提供写数据时的事务保证,在这种机制下,写过程包含三个步骤:
Write: 通过编写新数据文件来进行所有更改
Validate and commit: 调用 commit 方法,生成 commit 信息,生成一个新的递增1的文件,如果相同的文件名已经存在,则报 ConcurrentModificationException。
名词解释
ACID ACID 就是指数据库事务的四个基本要素,对应的是原子性 Atomicity,一致性 Consistency,隔离性 Isolation 和持久性 Durability。
原子性: 一个事务要么全部成功,要不全部失败,事务出现错误会被回滚到事务开始时候的状态。
一致性: 系统始终处于一致的状态,所有操作都应该服务现实中的期望。
隔离性: 并发事务不会互相干扰,事务之间互相隔离。
持久性: 事务结束后就一直保存在数据库中,不会被回滚。
Snapshot
Snapshot 相当于当前数据的快照。这个快照包括的内容不仅仅只有一个版本号,还会包括当前快照下的数据文件,上一个 Snapshot 的操作,以及时间戳和 DeltaLog 的记录。
MetaData
这里是指 Delta Table 的元数据,包括 id,name,format,创建时间,schema 信息等等。
事务日志
事务日志的相关代码主要在 org.apache.spark.sql.delta.DeltaLog 中。这个是 Delta Lake 把对数据/表的操作的记录日志。
CheckSum
可以说 CheckSum 是一个对象,里面包含了,当前 SNAPSHOT 下的表的物理大小,文件数,MetaData 的数量,协议以及事务的数量。这些信息会转成 Json 格式,存放在 CheckSumFile 中。
校验文件是在 Snapshot 的基础上计算的,会和各自的事务生死存亡。


版权声明:
文章不错?点个【在看】吧! ?