
Delta Lake 实践 | Databricks 数据洞察 Delta Lake 在基智科技(STEPONE)的应用实践
作者
高爽,基智科技数据中心负责人
尚子钧,数据研发工程师
1
基智科技
北京基智科技有限公司是一家提供智能营销服务的科技公司。公司愿景是基于 AI 和大数据分析为 B2B 企业提供全流程的智能营销服务。公司秉承开放,挑战,专业,创新的价值观从线索挖掘到 AI 智达、CRM 客户管理覆盖客户全生命周期,实现全渠道的营销和数据分析决策,帮助企业高效引流,精准拓客,以更低的成本获取更多的商机。截至目前,基智科技已与包括房产、教育、汽车、企业服务等领域展开广泛合作。
2
背景
在基智科技目前的离线计算任务中,大部分数据源都是来自于业务 DB(MySQL) 。业务 DB 数据接入的准确性、稳定性和及时性,决定着下游整个离线计算 pipeline 的准确性和及时性。最初我们在 ECS 上搭建了自己的 Hadoop 集群,每天使用 Sqoop 同步 MySQL 数据,再经由 Spark ETL 任务,落表写入 Hive ,ES,MongoDB 、MySQL ,通过调用 Service API 做页签的展示。
我们的 ETL 任务一般在凌晨1点开始运行,数据处理阶段约1h, Load 阶段1h+,整体执行时间为2-3h,下图为我们的 ETL 过程:
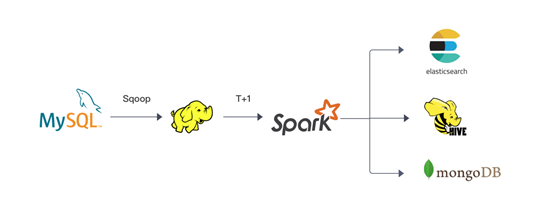
3
存在的问题
上面的架构在使用的过程中以下几个问题比较突出:
随着业务数据的增长,受 DB 性能瓶颈影响突出。
需要维护多套数据源,数据冗杂,容易形成数据孤岛使用不方便。
天级 ETL 任务耗时久,影响下游依赖的产出时间。
数据主要存储在 HDFS 上,随着数据的增加,需要增加集群,成本这一块也是不小的开销。
大数据平台运维成本高。
4
选择 Databricks 数据洞察 Delta Lake
为了解决天级 ETL 逐渐尖锐的问题,减少资源成本、提前数据产出,我们决定将T+1级 ETL 任务转换成T+0实时数据入库,在保证数据一致的前提下,做到数据落地即可用。
考虑过使用 Lambda 架构在离线、实时分别维护一份数据但在实际使用过程中无法保证事务性,随着数据量增大查询性能低,操作较复杂维护成本比较高等问题最终没能达到理想化使用。
后来我们决定选择数据湖架构,紧接着考察了市场上主流的数据湖架构:Delta Lake(开源和商业版)& Hudi。二者都支持了 ACID 语义、Upsert、Schema 动态变更、Time Travel 等功能,但也存在差异比如:
Delta Lake 优势:
支持 Java 、Scala 、Python 及 SQL。
支持作为 source 流式读写,批流操作简捷。
Delta Lake 不足:
引擎强绑定 spark 。
需要手动合并小文件。
Hudi 优势:
基于主键的快速 Upsert / Delete 。
支持小文件自动合并。
Hudi 不足:
不能支持 SQL 。
API 较为复杂。
综合以上指标,加上我们之前的平台就是基于阿里云平台搭建,选型时阿里云尚未支持 Hudi ,最终我们选择了阿里云 Databricks 数据洞察(商业版 Delta Lake 专业性更强)。同时 Databricks 数据洞察提供全托管服务,能够免去我们的运维成本。
5
整体架构图
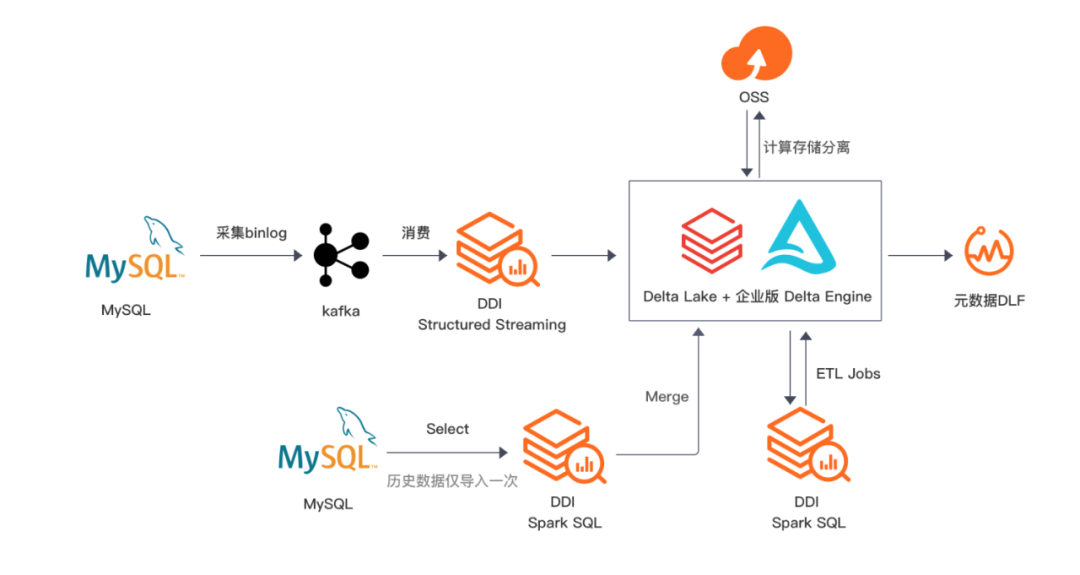
整体的架构如上图所示。我们接入的数据会分为两部分,存量历史数据和实时数据,存量数据使用 Spark 将 MySQL 全量数据导入 Delta Lake 的表中, 实时数据使用 Binlog 采集实时写入到 Delta Lake 表中,这样实时数据和历史数据都同步到同一份表里面真正实现批流一体操作。
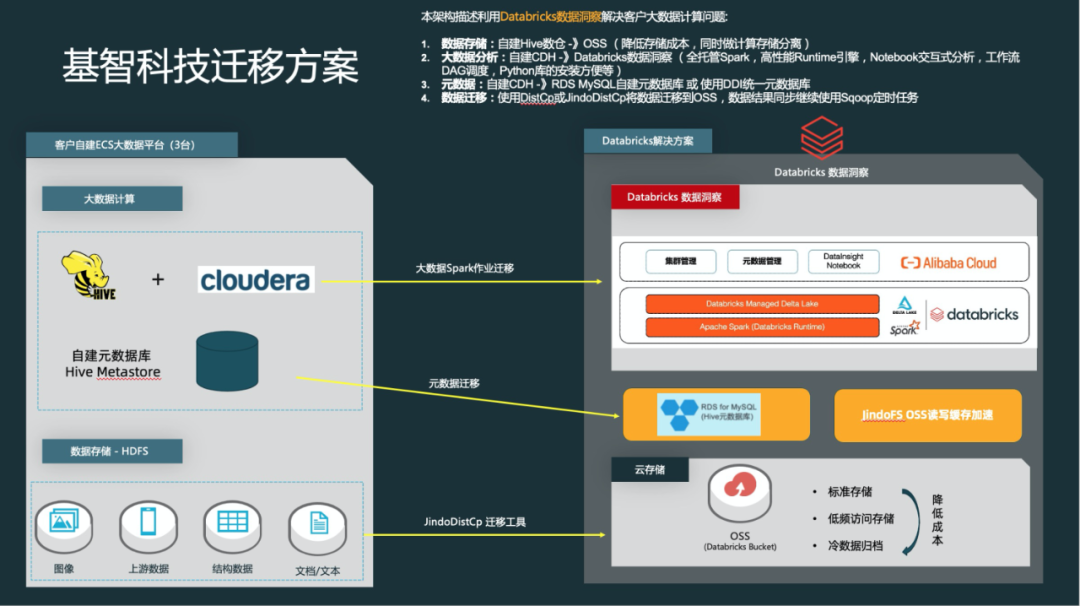
集群迁移
前期在阿里同事的协助下我们完成了数据迁移的工作,实现在Databricks数据洞察架构下数据开发工作,我们的前期做的准备如下:
数据存储将Hive数仓数据迁移到OSS,数据同步继续使用Sqoop定时执行。
元数据管理从自建Hadoop集群迁移到阿里云RDS MySQL,后面随着我们业务的扩展会转入DLF元数据湖管理。
大数据分析架构由自建CDH迁移到Databricks数据洞察。
Delta Lake 数据接入
每天做ETL数据清洗,做表的merge操作 ,delta表结构为:
%sql
CREATE TABLE IF NOT EXISTS delta.delta_{table_name}(
id bigint,
uname string,
dom string,
email string,
update timestamp,
created timestamp
)
USING delta
LOCATION '------/delta/'
%sql
MERGE INTO delta.delta_{table_name} AS A
USING (SELECT * FROM rds.table_{table_name} where day= date_format (date_sub (current_date,1), 'yyyy-mm-dd') AS B
ON A.id=B.id
WHEN MATCHED THEN
update set
A.uname=B.name,
A.dom=B.dom,
A.email=B.email,
A.updated=current_timestamp()
WHEN NOT MATCHED
THEN INSERT
(A.uname,A.dom,A.email,A.update,A.created) values (B.name,B.dom,B.email,current_timestamp(),current_timestamp())
6
Delta Lake 数据 Merge & Clones
由于 Delta Lake 的数据仅接入实时数据,对于存量历史数据我们是通过 SparkSQL 一次性 Sink Delta Lake 的表中,这样我们流和批处理时只维护一张 Delta 表,所以我们只在最初对这两部分数据做一次 merge 操作。
同时为了保证数据的高安全,我们使用 Databricks Deep Clone 每天会定时更新来维护一张从表以备用。对于每日新增的数据,使用 Deep Clone 同样只会对新数据 Insert 对需要更新的数据 Update 操作,这样可以大大提高执行效率。
CREATE OR REPLACE TABLE delta.delta_{table_name}_clone
DEEP CLONE delta.delta_{table_name};
7
产生的效益
节省了 DB 从库的成本,同时 Databricks 数据洞察全托管架构我们节省了人力成本(省1运维+2名大数据)因此我们采用商业版 Databricks 数据洞察 Delta Lake 流批一体架构之后,整体成本有很大节省。
得益于商业版 Databricks 数据洞察 Delta Lake 高效的执行引擎,执行效率上6-10的性能提升。
实现了计算和存储分离,同时基于 DLF 元数据湖管理,可扩展性明显提高。
商业版 Databricks 数据洞察提供了一整套批流处理的 Spark API 使我们研发工作高效便捷了很多。
8
后续计划
基于 Delta Lake ,进一步打造优化实时数仓结构,提升部分业务指标实时性,满足更多更实时的业务需求。
持续观察优化 Delta 表查询计算性能,尝试使用 Delta 的更多功能,比如 Z-Ordering ,提升在即席查询及数据分析场景下的性能。
END