
SQL进阶,子查询与窗口函数
本节给大家讲解SQL在实际过程中用途比较多的子查询与窗口函数,下面一起学习。
示例工具:MySQL8.0、Navicat Premium 12 本文讲解内容:子查询与窗口函数 适用范围:SQL进阶应用
子查询
子查询用于为主查询返回其所需数据,或者对检索数据进行进一步的限制,通常将一个查询(子查询)的结果作为另一个查询(主查询)的数据来源或判断条件,常见的子查询有WHERE子查询,HAVING子查询,FROM子查询,SELECT子查询,EXISTS子查询。
子查询是一种嵌套在其他 SQL 查询的 WHERE 子句中的查询,可以在 SELECT、INSERT、UPDATE 和 DELETE 语句中,同逻辑运算符一起使用。
使用子查询必须遵循以下几个规则:
子查询必须括在圆括号中。
子查询的 SELECT 子句中只能有一个列。
子查询不能使用 ORDER BY,在子查询中,GROUP BY 可以起到同 ORDER BY 相同作用。
返回多行数据的子查询只能同多值操作符一起使用,比如 IN 操作符。
子查询不能直接用在聚合函数中。
BETWEEN 不能同子查询一起使用,但 BETWEEN 操作符可以用在子查询中。
创建数据表
通常情况下子查询都与 SELECT 语句一起使用,其基本语法如下所示:
SELECT column_name [, column_name ]FROM table1 [, table2 ]WHERE column_name OPERATOR (SELECT column_name [, column_name ]FROM table1 [, table2 ][WHERE])
对于子查询的数据演示创建两个表,一个是薪水表,另一个是职位表,并且插入数据。
#创建薪水表SALARYCREATE TABLE SALARY(ID VARCHAR ( 10 ),NAME VARCHAR ( 10 ),AGE VARCHAR ( 10 ),ADDRESS VARCHAR ( 10 ),SAL INT(10) );
给薪水表插入数据,数据内容如下所示:
# 给薪水表插入数据INSERT INTO SALARY(ID,NAME,AGE,ADDRESS,SAL) VALUES('C001','Rmesh',35,'Ahmedabad',2000),('C002','Khilan',25,'Delhi',1500),('C003','Kaushik',23,'Kota',2000),('C004','Chaitali',25,'Mumbai',6500),('C005','Hardik',27,'Bhopal',8500),('C006','Komal',22,'MP',4500),('C007','Tom',26,'MP',5500),('C008','Muffy',24,'Indore',10000);
查询所有的薪水数据如下所示:
SELECT * FROM SALARY;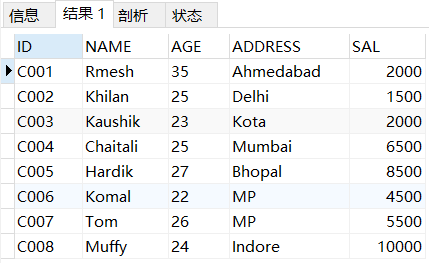
同理创建一个职位表。
#创建职位表JOBCREATE TABLE JOB(JID VARCHAR ( 10 ),JB VARCHAR ( 10 ));
给职位表插入数据,数据内容如下所示:
# 给职位表插入数据INSERT INTO JOB(JID,JB) VALUES('C001','Teacher'),('C002','Docter'),('C003','Teacher'),('C004','Worker'),('C005','Nurse'),('C006','Teacher'),('C007','Docter'),('C008','Teacher');
查询所有的职位数据如下所示:
SELECT * FROM JOB;
子查询过滤
子查询最常见的使用是在WHERE子句的IN操作符中,以及用来填充计算列。先看一个简单的例子,要查询所有医生的薪水情况,这里首先在职位表中查询所有医生的JID,查询结果如下:
SELECT JIDFROM JOBWHERE JB='Docter';
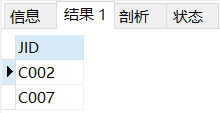
然后在薪水表中查询ID为'C002','C007'的薪水情况,查询结果如下:
SELECT SALFROM SALARYWHERE ID IN('C002','C007');
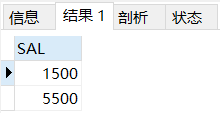
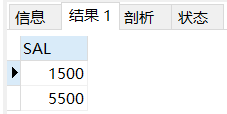
这里使用子查询更加简便,子查询从内向外依次处理,在下面的SELECT语句中,MySQL实际上执行了两个操作,首先查询返回两个ID号:C002和C007。
然后,这两个值以IN操作符要求的逗号分隔的格式传递给外部查询的WHERE子句,可以看到输出的结果是正确的,并且与前面WHERE子句所返回的值相同。
SELECT SALFROM SALARYWHERE ID IN(SELECT JIDFROM JOBWHERE JB='Docter');
使用子查询查询薪水大于8000的员工的所有信息,首先内部查询薪水大于8000的ID,然后外部使用一个WHERE查询即可得到结果。
SELECT *FROM SALARYWHERE ID IN (SELECT IDFROM SALARYWHERE SAL > 8000);
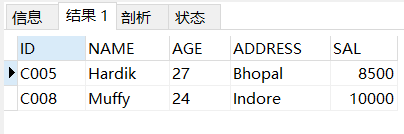
作为计算字段使用子查询
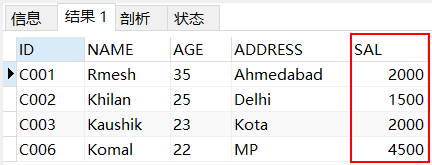
使用子查询的另一方法是创建计算字段,创建计算字段需要使用聚合函数,例如count,sum,avg,max,min等,这里首先计算平均薪水作为一个内查询,然后在外部使用WHERE子句进行查询,得出薪资比平均薪资低的员工的所有信息。
SELECT * FROM SALARYWHERE SAL < (SELECT AVG(SAL)FROM SALARY);
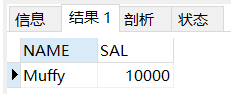
除使用WHERE过滤,还可以使用HAVING过滤,HAVING子句对分组统计函数进行过滤,也可以在HAVING子句中使用子查询,要查询薪资最高的人及其薪资情况,首先内部查询最高工资,然后外部以人名分组后使用HAVING子句过滤,查询结果如下。
SELECT NAME,SALFROM SALARYGROUP BY NAMEHAVING SAL = (SELECT MAX(SAL)FROM SALARY);
窗口函数
窗口函数与数据分组功能相似,可指定数据窗口进行统计分析,但窗口函数与数据分组又有所区别,窗口函数对每个组返回多行,而数据分组对每个组只返回一行;窗口函数指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化,而数据分组是针对所有数据进行统计,窗口函数的写法如下。
<窗口函数> over (partition by <用于分组的列名>order by <用于排序的列名>)窗口函数主要有两种,一种是专用窗口函数,包括rank、dense_rank、row_number等。另一种是聚合函数,包括sum、avg、count、max、min等,下面逐一介绍窗口函数的五个功能,分别是聚合、排序、极值、移动、切片,下面一起来学习。
创建表
首先创建一个金额表,年份、姓名、国家设置为字符串类型,交易金额设置为整型。
#创建金额表payCREATE TABLE pay(year VARCHAR ( 10 ),name VARCHAR ( 10 ),country VARCHAR ( 10 ),payment INT(10) );
给金额表插入数值。
# 给金额表插入数据INSERT INTO pay(year,name,country,payment) VALUES(2017,'Lining','China',1119),(2018,'Lining','China',1176),(2018,'Zhaoqi','China',1388),(2019,'Zhaoqi','China',1597),(2018,'Jackie','USA',1028),(2019,'Jackie','USA',1934),(2020,'Jackie','USA',1837),(2017,'Tom','India',1578),(2018,'Tom','India',1329),(2019,'Tom','India',1578),(2020,'Tom','India',1399);
将所有的数据查询出来结果如下所示。
SELECT * from pay;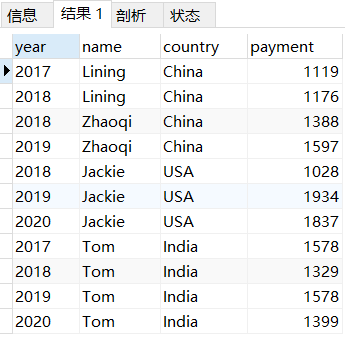
一、聚合
1、计算列表总金额
SELECT *, SUM(payment) OVER() as Total_payment from pay;计算当前列表的总金额可以使用窗口函数,sum是求和,over()中不添加参数,则对所有数据进行求和,输出的结果都是15963。
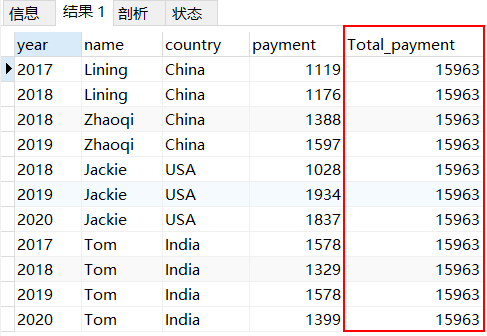
2、计算各国家总金额
SELECT *, SUM(payment) OVER() as Total_payment,SUM(payment) OVER(PARTITION by country) as country_paymentfrom pay;
计算各国家总金额就要对各个国家分组,这里分组使用的是PARTITION by,PARTITION by的功能与GROUP BY的功能类似,指定按照那一列进行分组,用country分组求和,则每个country的输出结果一致。
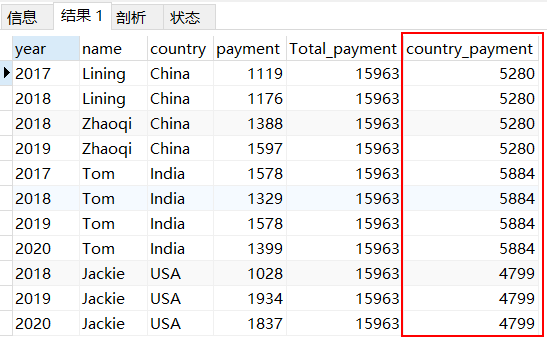
3、按国家降序累加求和金额
SELECT *, SUM(payment) OVER() as Total_payment,SUM(payment) OVER(PARTITION by country) as country_payment,SUM(payment) OVER(PARTITION by country ORDER BY payment DESC) as order_paymentfrom pay;
这里使用SQL中常用的向下累计求和的方法,当使用order by时,没有rows between则意味着窗口是从起始行到当前行,所以对不同国家进行累加求和操作。
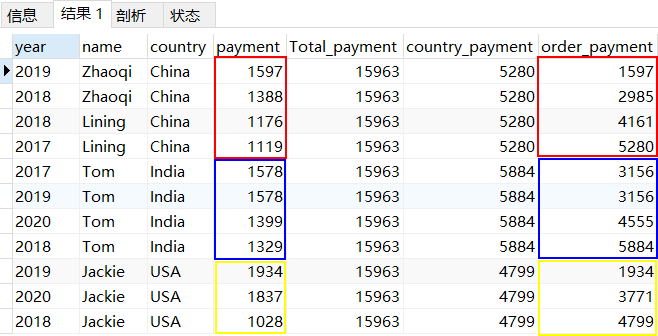
4、不同国家人数计数
count()用于计数,与前面sum的用法基本一致,可以用count(distinct country)进行去重,如果用partition by进行分组,则分组后再计数。
SELECT *, COUNT(name) OVER() as Total_people,COUNT(name) OVER(PARTITION by country) as country_peoplefrom pay;
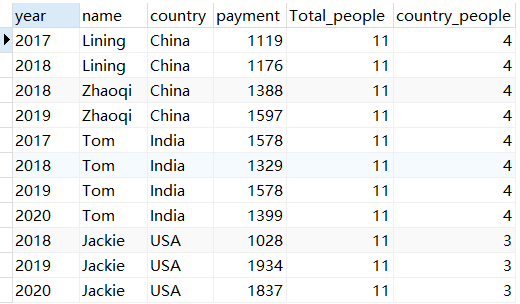
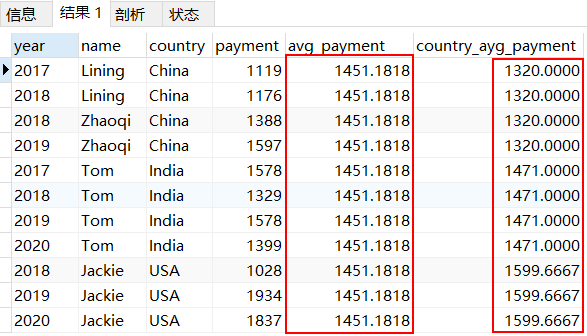
5、 不同国家平均金额
SELECT *, AVG(payment) OVER() as avg_payment,AVG(payment) OVER(PARTITION by country) as country_ayg_paymentfrom pay;
使用avg聚合函数的用法与前面的聚合运算用法一致,PARTITION by同样用来分组,这里分组后求均值。
6、各国家最低金额
SELECT *, MAX(payment) OVER() as Max_payment,MIN(payment) OVER(PARTITION by country) as country_min_paymentfrom pay;
这里MAX(payment)函数对整个数据计算最大值,使用PARTITION by对于不同的国家分组后然后计算最小值。

二、排序
1、各国家按金额排序
使用窗口函数排序,会使用到三个函数,row_number,rank,dense_rank,他们的使用区别如下:
row_number从1开始,按照顺序,生成分组内记录的序列;
rank生成数据项在分组中的排名,排名相等会在名次中留下空位;
dense_rank生成数据项在分组中的排名,排名相等会在名词中不会留下空位。
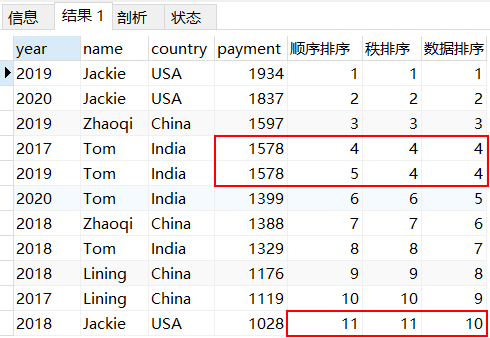
SELECT *,ROW_NUMBER()OVER(ORDER BY payment DESC) as '顺序排序',RANK()OVER(ORDER BY payment DESC) as '秩排序',DENSE_RANK()over(ORDER BY payment DESC) as '数据排序'from pay;
row_number函数,按照行记录的顺序来排序,此处从1到11按顺序排列;rank函数,在排名相等会在名次中留下空位,此处共同排名为第4名,同时忽略第5名,继续往下排列;dense_rank排名相等会在名词中不会留下空位此处共同排名为第4名,不忽略第5名,继续往下排列。
三、极值
1、当前行金额最高的人
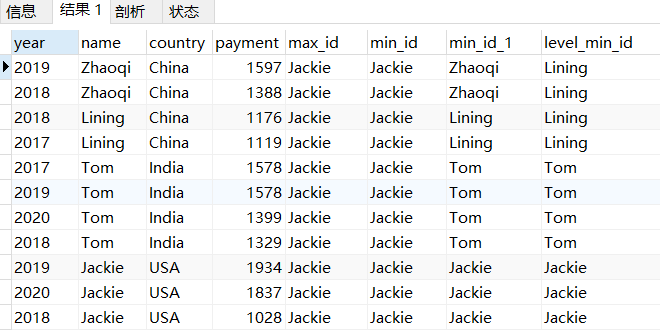
first_value截止当前行的第一个,last_value截止当前行的最后一个。
select *,first_value(name)over(order by payment desc) as max_id,first_value(name)over(order by payment asc) as min_id,last_value(name)over(order by payment desc) as min_id_1,last_value(name)over(partition by country order by payment desc rows between unbounded preceding and unbounded following) as level_min_idfrom pay;
first_value按分组排序后取范围内第1个值,last_value取最后1个值,因为默认窗口的关系,last_value会随着窗口的改变而改变,所以一般不用last_value,如果要用,则改变窗口为所有行,此处用来查询当前金额最大的人,以及截至当前金额最小的人。
四、移动
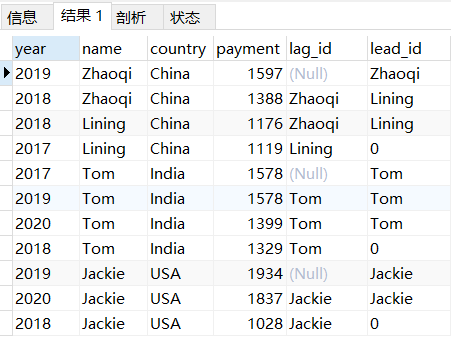
1、按国家分组金额排名前1位和后1位人名
select *,lag(name,1,null)over(partition by country order by payment desc) as lag_id,lead(name,1,'0')over(partition by country order by payment desc) as lead_idfrom pay;
五、切片
1、按金额切片
ntile(n)用于将分组数据按照顺序切分成N片,返回当前切片值,ntile把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,ntile返回此行所属的组的编号,ntile(3)表示将表切分为3组,ntile可以分组排序后切分,表示对当前的组内进行切分后排序。
select *,ntile(3) over(order by payment desc) as total_part,ntile(2)over(partition by country order by payment desc) as level_partfrom pay;

对比Excel系列图书累积销量达15w册,让你轻松掌握数据分析技能,可以在全网搜索书名进行了解:
