
SQL、Pandas、Spark:窗口函数的3种实现
导读
窗口函数是数据库查询中的一个经典场景,在解决某些特定问题时甚至是必须的。个人认为,在单纯的数据库查询语句层面【即不考虑DML、SQL调优、索引等进阶】,窗口函数可看作是考察求职者SQL功底的一个重要方面。
前期个人以求职者身份参加面试时被问及窗口函数的问题,近期在作为面试官也提问过这一问题,但回答较为理想者居少。所以本文首先窗口函数进行讲解,然后分别从SQL、Pandas和Spark三种工具平台展开实现。

模拟问题描述:
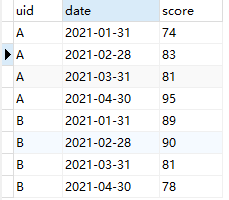
给定一组中学生的历次语文月考成绩表(每名学生含有4次成绩),需要实现以下3个需求:
对每名学生的4次成绩表分别进行排序,排序后每人的成绩排名1-2-3-4
求每名学生历次月考成绩的变化幅度,即本月较上个月的成绩差值
求每名学生历次月考成绩中近3次平均分
注:文末有送书活动!

MySQL8.0官方手册中关于窗口函数的介绍
当然,为了形象表达上述定义所言何物,这里还是进一步给出一些配套插图以便于理解。在给出具体配图之前,首先要介绍与窗口函数相关的3个关键词:
partition by:用于对全量数据表进行切分(与SQL中的groupby功能类似,但功能完全不同),直接体现的是前面窗口函数定义中的“有关”,即切分到同一组的即为有关,否则就是无关;
order by:用于指定对partition后各组内的数据进行排序;
rows between:用于对切分后的数据进一步限定“有关”行的数量,此种情景下即使partition后分到一组,也可能是跟当前行的计算无关。
相应的,这3个关键字在前面的数据样表中可作如下配套解释:
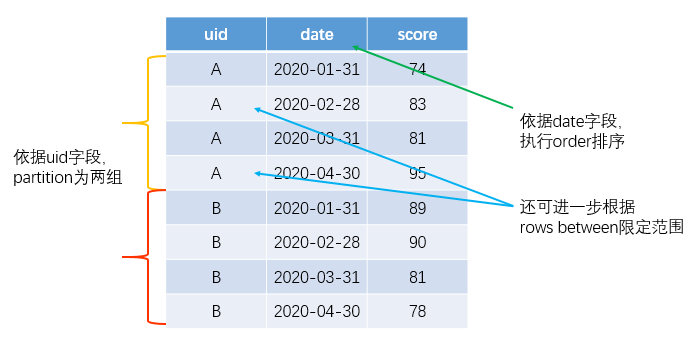
当然,到这里还不是很理解窗口函数以及相应的3个关键字也问题不大,后续结合前述的三个实际需求再返过来看此图多半会豁然开朗。
上面是窗口函数的逻辑解释,那么具体能用于实现什么功能呢?其实,窗口函数能实现什么功能则要取决于能搭配什么函数。仍然引用MySQL8.0官方文档中的一幅图例:
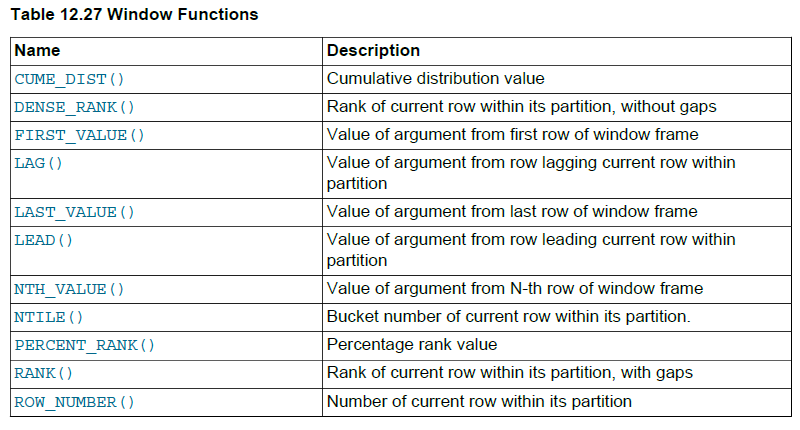
其中,上表所述的窗口函数主要分为两大类:
排序类,包括row_number、rank、dense_rank等,也包括percent_rank、cume_dist等分布排序类
相对引用类,如lag、lead、first_value、last_value、nth_value等
除了这两类专用窗口函数之外,还有广义的聚合函数也可配套窗口函数使用,例如sum、avg、max、min等。
所以,现在来看前面提到的三个需求,就刚好是分别应用这三类窗口函数的例子。【哪有什么刚好,不过是特意设计而已】
围绕这三个需求,下面分别应用SQL、Pandas和Spark三个工具予以实现。
既然窗口函数起源于数据库,那么下面就首先应用SQL予以实现。
注:以下所有SQL查询语句实现均基于MySQL8.0。
Q1:求解每名同学历次成绩的排名。
A1:由于是区分每名同学进行排序,所以需要依据uid字段进行partition;进一步地,按照成绩进行排序,所以order by字段即为score;最后,由于是要进行排名,所以配套函数选择row_number即可。注:row_number、rank和dense_rank的具体区别可参考历史文章:一文解决所有MySQL分类排名问题。
查询语句及查询结果如下:
SELECT *, row_number() over(partition by uid order by score desc) as `rank` from score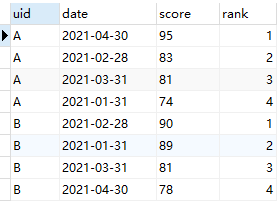
Q2:求解每名同学历次月考成绩的差值,即本月成绩-上月成绩。
A2:首先,仍然是依据uid字段进行partition;而后由于是要计算本月成绩与上月成绩的差值,所以此次的排序依据应该是date;进一步地,由于要计算差值,所以需要对每次月考成绩计算其前一行的成绩(在按照uid进行切分并按照date排序后,上月成绩即为当前行的前一条记录),所以配套函数即为lag。
给出具体实现SQL语句及查询结果如下:
SELECT *, score - lag(score) over(partition by uid order by date) as score_diff from score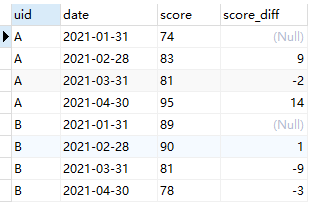
Q3:求解每名学生近3次月考成绩的平均分。
A3:在前两个需求的基础上,易见,仍然是依据uid进行partition、依据date进行排序,并选用avg聚合函数作为配套窗口函数。进一步地,由于此处限定计算近3次成绩的平均分,所以除了partition和order by 两个关键字外,还需增加rows between的限定。
具体SQL语句和查询结果如下:
SELECT *, avg(score) over(partition by uid order by date rows between 2 preceding and current row) as avg_score3 from score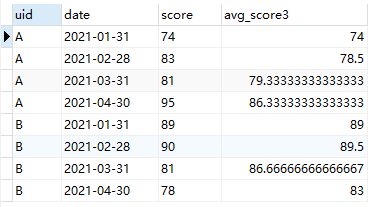
值得指出的是,对于每名学生,当切分窗口不足指定窗口大小(即目标行数)时会按实际的数据进行聚合,例如学生A,1月31日对应的近3次平均分即为本月成绩自身;2月28日对应近3次平均分即为本月成绩和上月成绩的平均分,而3月31日和4月30日计算的近3次平均分则为真正意义上的3次成绩均值。
Pandas作为Python数据分析与处理的主力工具,自然也是支持窗口函数的,而且花样只会比SQL更多。对于上述三个需求,Pandas分别实现如下:
Q1:求解每名同学历次成绩的排名。
A1:虽然Pandas接口非常丰富,但用其实现分组排名貌似却并不方便。不过也是可以的。基本思路如下:首先仍然分别用uid和score字段进行分组和排序,而后通过对取值=1的常数列num进行cumsum,即累加,即可获取分组排名结果。其中,还可进一步应用assign函数实现链式调用,最终整个需求实现下来也是一行代码即可!
具体Pandas实现代码即结果如下:
df.assign(rank=df.assign(num=1).sort_values("score", ascending=False).groupby("uid")['num'].cumsum())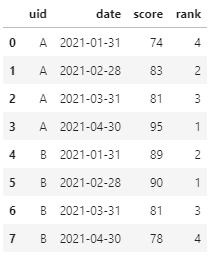
注:上述代码应用了assign实现链式调用,具体可参考文章Pandas用了一年,这3个函数是我的最爱……
Q2:求解每名同学历次月考成绩的差值,即本月成绩-上月成绩。
A2:对于这一特定需求,Pandas中实际上是内置了偏移函数shift,专门用于求解当前行的相对引用值。进一步地,对于求解差分结果,还可直接用diff实现,其中diff就相当于当前行-shift(1)。
两种API实现代码即执行结果分别如下:
# shift函数实现df.assign(score_diff=df["score"]-df.sort_values("date").groupby("uid")['score'].shift(1))# diff函数实现df.assign(score_diff=df.sort_values("date").groupby("uid")['score'].diff(1))
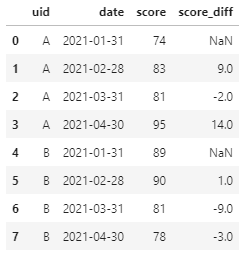
Q3:求解每名学生近3次月考成绩的平均分。
A3:如果说前两个需求用Pandas实现都没有很好体现窗口函数的话,那么这个需求可能才更贴近Pandas中窗口函数的标准用法——那就是用关键字rolling。rolling原义即有滚动的意思,用在这里即表达滑动窗口的意思,所以自然也就可以设置滑动窗口的大小。至于SQL中窗口函数的另外两个关键字partition和order则仍然需要借助Pandas的sort_values和gropupby来实现。另外,与SQL中类似,这里仍然是要用求均值函数来做为配套。
具体Pandas实现代码如下:
df.assign(avg_score3=df.sort_values("date").groupby("uid").rolling(window=3, min_periods=1)['score'].mean().reset_index().set_index("level_1")['score'])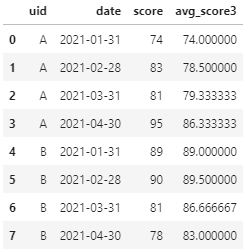
注:上述实现中用到了reset_index和set_index,其目的是为了保证滑窗聚合后保证顺序不变。为了追求单行代码实现,这里的写法不再优雅,并不提倡。
最后,选用Spark予以实现。应该讲,Spark.sql组件几乎是完全对标SQL语法的实现,这在窗口函数中也例外,包括over以及paritionBy、orderBy和rowsbetween等关键字的使用上。
注:在使用Spark窗口函数前,首先需要求引入窗口函数类Window。即
import org.apache.spark.sql.expressions.WindowQ1:求解每名同学历次成绩的排名。
A1:直接沿用SQL思路即可,需要注意Spark中的相应表达。
代码实现及相应执行结果如下:
df.select($"uid", $"date", $"score", row_number().over(Window.partitionBy("uid").orderBy($"score".desc)).as("rank"))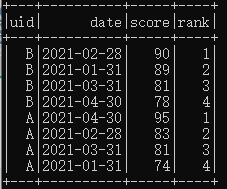
Q2:求解每名同学历次月考成绩的差值,即本月成绩-上月成绩。
A2:首先应用lag算子求出上月成绩,而后直接相减即可。
代码及执行结果如下:
df.select($"uid",$"date", $"score", ($"score"-lag($"score", 1).over(Window.partitionBy("uid").orderBy("date"))).as("score_diff"))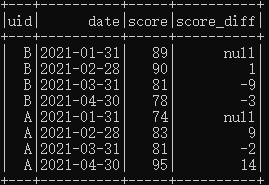
Q3:求解每名学生近3次月考成绩的平均分。
A3:仍然沿用SQL中思路即可,只需增加rowsBetween函数。
代码实现及执行结果如下:
df.select($"uid",$"date", $"score", avg("score").over(Window.partitionBy("uid").orderBy("date").rowsBetween(-2, 0)).as("avg_score3"))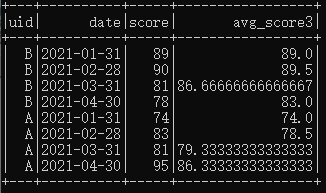
本文首先对窗口函数进行了介绍,通过模拟设定3个实际需求问题,分别基于SQL、Pandas和Spark三个工具平台予以分析和实现。总体来看,SQL和Spark实现窗口函数的方式和语法更为接近,而Pandas虽然拥有丰富的API,但对于具体窗口函数功能的实现上却不尽统一,而需灵活调用相应的函数。当然,窗口函数的功能还有很多,三个工具平台的使用也远不止这些,但其核心原理则是大体相通的。
最后,感谢清华大学出版社为本公众号读者赞助《数据科学实用算法》一本,截止本周五(4月16日)早9点,公众号后台查看分享最多的前3名读者随机指定一人,中奖读者将在【小数志】读者微信群中公布,若还未加群的可在公众号菜单-"关于"中添加小编微信联系入群。
相关阅读: