
Ceph最新的EC-CLAY插件调研-下
EC改进方案选型
接上篇,介绍一下整个容灾方案在性能和可靠性方面如何做验证。
3个机柜,每个机柜15台机器,总共45台,需要在RBD场景下,找到成本、性能、数据可靠性的三者平衡点。
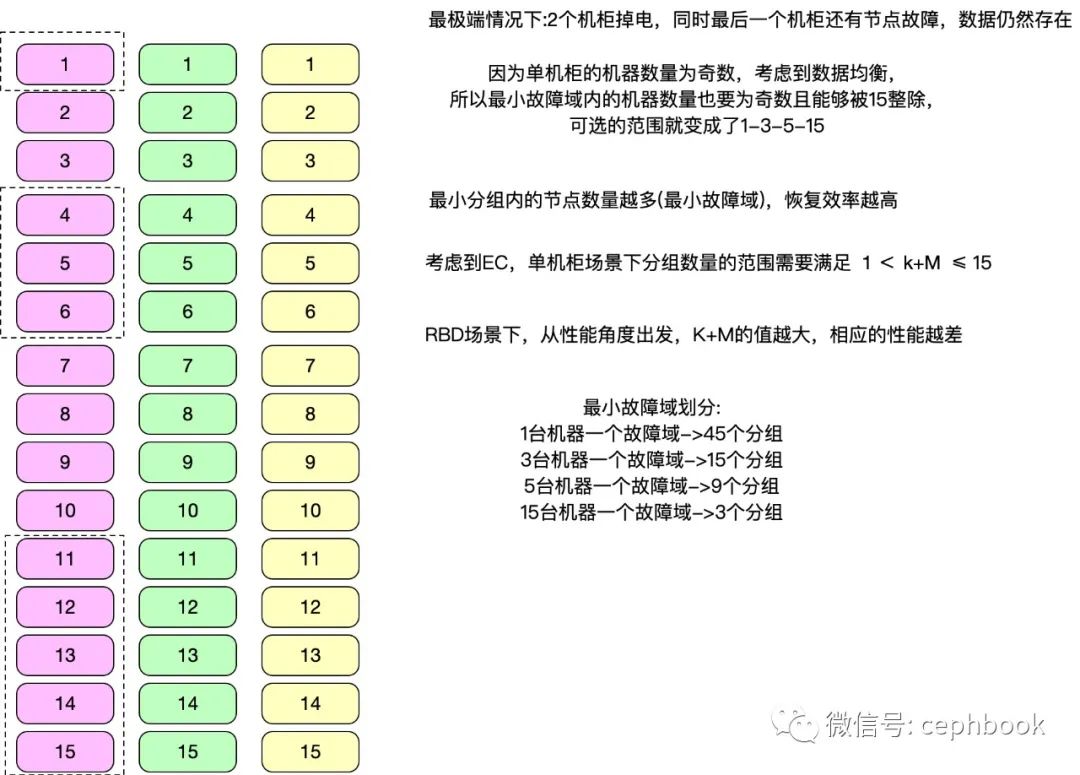
跨机柜容灾方案1
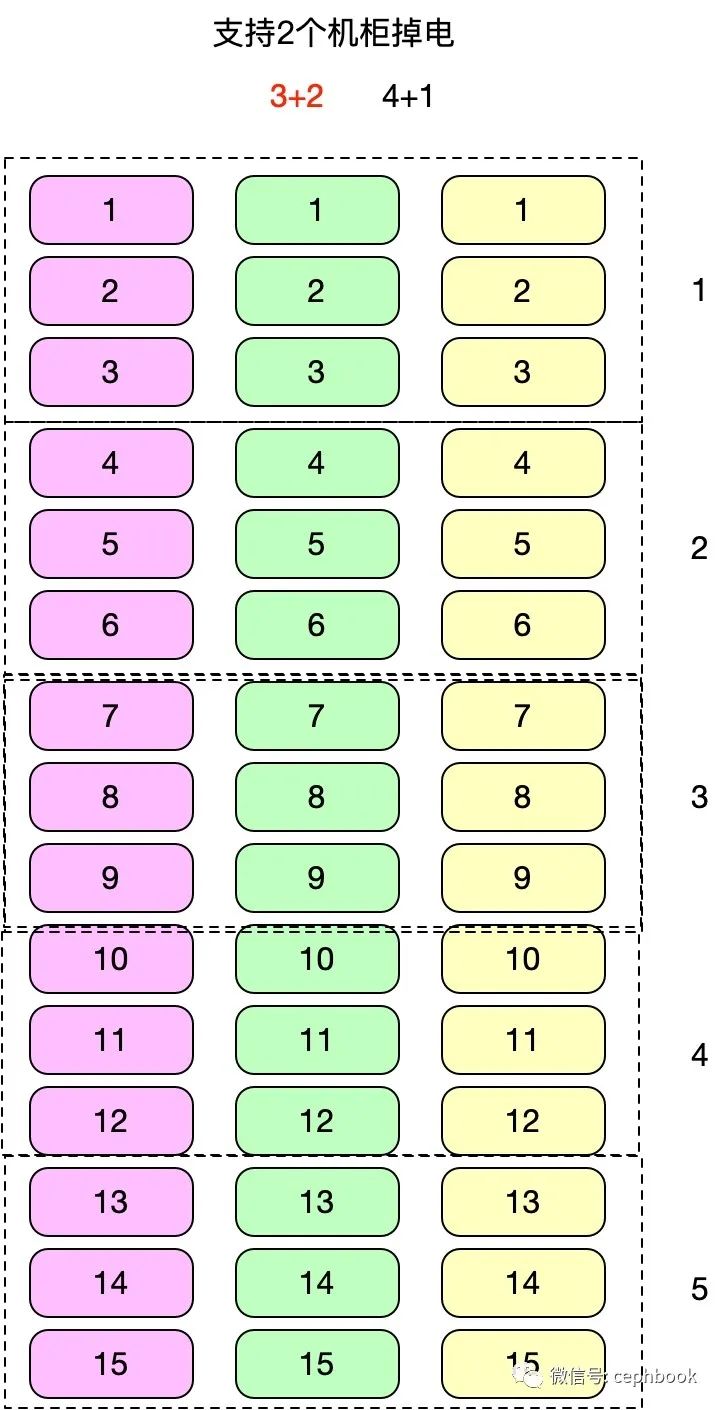
支持2个机柜级别的容灾,跨3个机柜单个分组共9个节点,共5个分组,对应的理论收益情况如下
| 名称 | K | M | D | 3副本得盘率 | EC得盘率 | 硬件成本节约比率 | 磁盘数据迁移量(ISA) | 磁盘数据迁移量(CLAY) | 数据恢复负载降低比率 |
|---|---|---|---|---|---|---|---|---|---|
| 3+2 | 3 | 2 | 4 | 33.33333333 | 60 | 180 | 3 | 2 | 33.33333333 |
ceph osd erasure-code-profile set CLAY-3-2-4 \
plugin=clay \
k=3 m=2 d=4 \
scalar_mds=isa \
technique=reed_sol_van \
crush-root=site1-ssd \
crush-failure-domain=ctnr
对应的crush rule如下
rule site1_sata_erasure_ruleset {
id 1
type erasure
min_size 3
max_size 5
step set_chooseleaf_tries 5
step set_choose_tries 100
step take site1-ssd
step choose indep 0 type media
step chooseleaf indep 1 type ctnr
step emit
}
单机柜容灾方案2
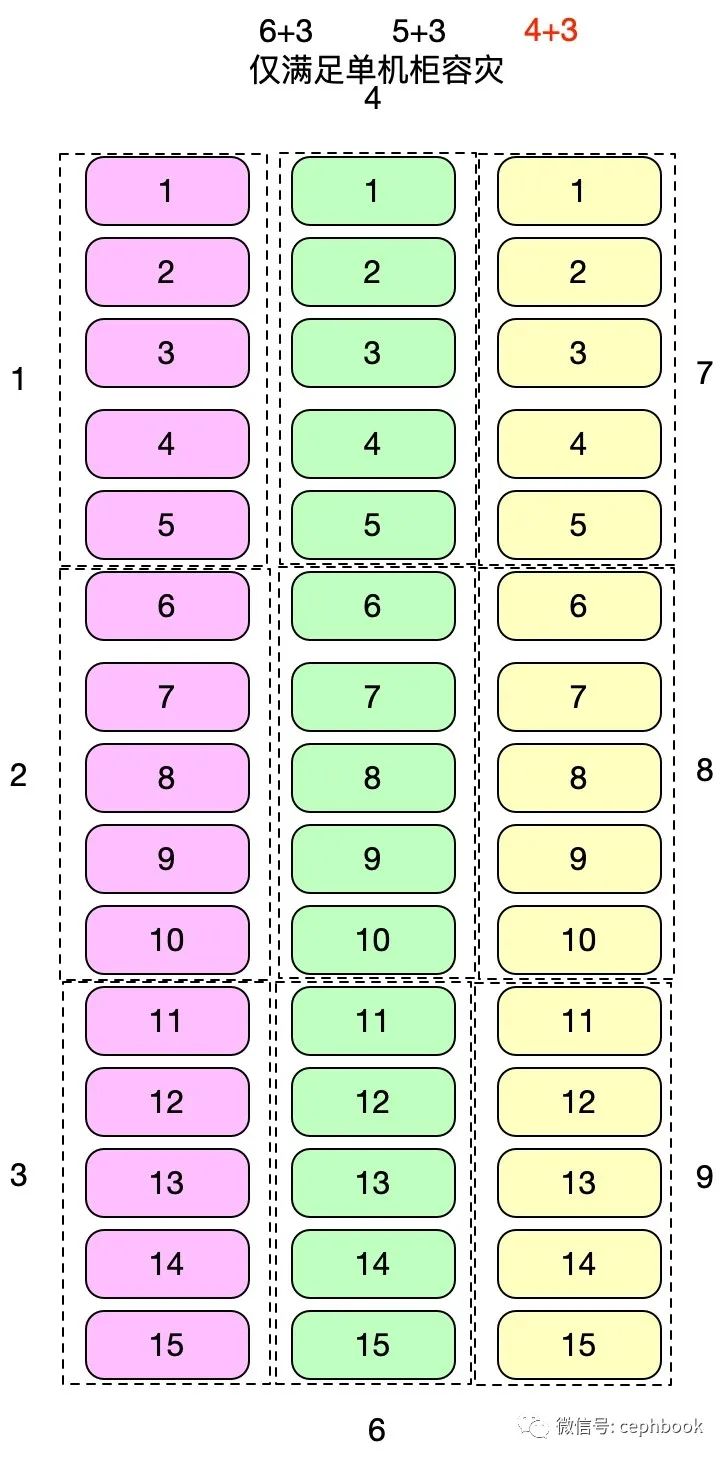
支持1个机柜级别的容灾,单个分组共5个节点,共9个分组,对应的理论收益情况如下
| 名称 | K | M | D | 3副本得盘率 | EC得盘率 | 硬件成本节约比率 | 磁盘数据迁移量(ISA) | 磁盘数据迁移量(CLAY) | 数据恢复负载降低比率 |
|---|---|---|---|---|---|---|---|---|---|
| 4+3 | 4 | 3 | 6 | 33.33333333 | 57.14285714 | 171.4285714 | 4 | 2 | 50 |
| 5+3 | 5 | 3 | 7 | 33.33333333 | 62.5 | 187.5 | 5 | 2.333333333 | 53.33333333 |
| 6+3 | 6 | 3 | 8 | 33.33333333 | 66.66666667 | 200 | 6 | 2.666666667 | 55.55555556 |
从性能最优原则,K+M总和最小则对应的理论性能最优,所以单机柜容灾模型下,4+3成为最优方案。
对应的ec配置如下
ceph osd erasure-code-profile set CLAY-4-3-6 \
plugin=clay \
k=4 m=3 d=6 \
scalar_mds=isa \
technique=reed_sol_van \
crush-root=site1-ssd \
crush-failure-domain=ctnr
对应的crush rule如下
rule site1_sata_erasure_ruleset {
id 1
type erasure
min_size 4
max_size 9
step set_chooseleaf_tries 5
step set_choose_tries 100
step take site1-ssd
step choose indep 0 type media
step chooseleaf indep 1 type ctnr
step emit
}
crush rule的生成与rule的验证模拟
crushtool --outfn crush5 --build --num_osds 450 ctnr straw2 10 media straw2 5 mediagroup straw2 0 unit straw2 0 root straw2 0
crushtool -d crush5 -o crush5.txt
crushtool -c crush5.txt -o crush5.txt #手工加上rule规则
crushtool -i crush5 --test --show-statistics --show-mappings --rule 1 --min-x 1 --max-x 20 --num-rep 6
容灾能力测试场景
性能测试
RBD场景,模拟大、小文件,顺序/随机读写,获取对应的fio性能基准数据,对比3副本与EC的性能差距。
3副本 vs CLAY_3+2 vs CLAY_4+3
| 场景名称 | iops | 带宽 | 90th延时 | 99th延时 | 备注 |
|---|---|---|---|---|---|
| 3副本-4M顺序读 | |||||
| 3+2-4M顺序读 | |||||
| 4+3-4M顺序读 | |||||
| 3副本-4M顺序写 | |||||
| 3+2-4M顺序写 | |||||
| 4+3-4M顺序写 | |||||
| 3副本-4k随机写 | |||||
| 3+2-4k随机写 | |||||
| 4+3-4k随机写 | |||||
| 3副本-4k随机读 | |||||
| 3+2-4k随机读 | |||||
| 4+3-4k随机读 |
故障恢复效率
前置条件:集群提前写入容量60%,模拟已有数据场景
目标:对比ISA和CLAY在K+M相同的情况下,RBD场景下持续读写数据,模拟单块OSD、单个OSD节点故障、多个OSD节点故障(可选),数据迁移所需的时长,同时记录对应的CPU、内存、网卡负载消耗情况,以及性能波动情况。
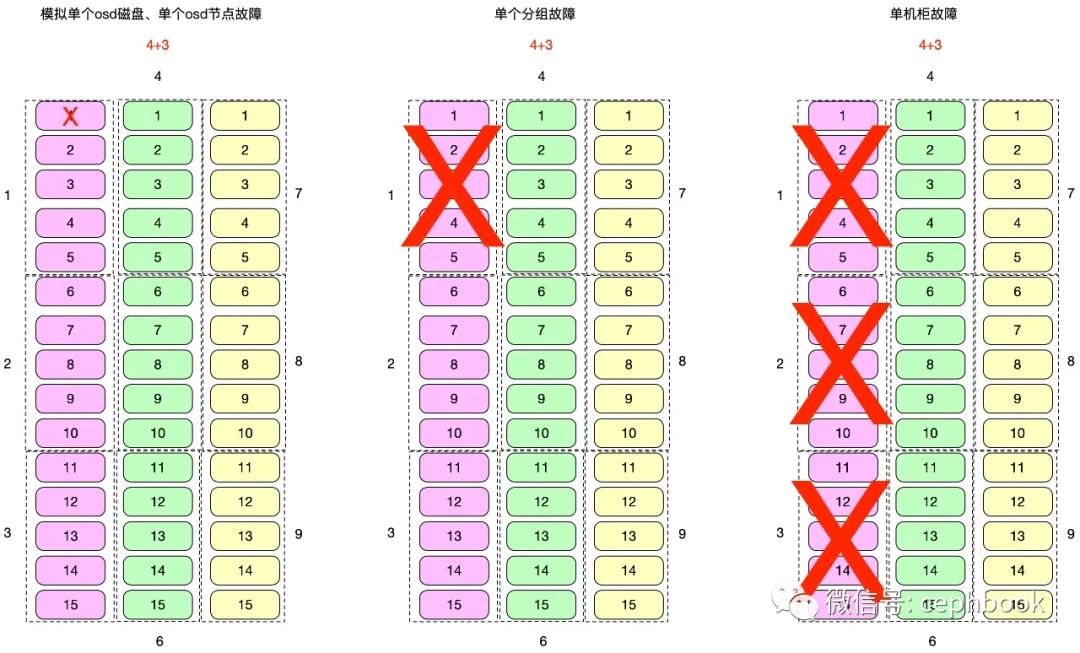
容灾能力
前置条件:集群提前写入容量60%,模拟已有数据场景
目标:RBD场景下持续读写数据,模拟最小故障域、单机柜、双机柜故障,记录对应的性能波动情况,考察在极端情况下整个集群的服务可用性和数据可靠性。
跨机柜容灾方案1
单机柜容灾方案2
欢迎订阅本公众号cephbook,干货满满,专业老司机教你搞"对象"存储!
评论