说在前面
一些老师学习Python编程仅仅是为了教学,凡是教材上没有或者考试不考的东西就不想去接触,我认为这种态度并不可取。我学习编程的一大原因是为了提高工作效率,通过编写一些小程序减少枯燥的手工劳动。pandas数据分析在教材中占比不高,估计考试中出现的概率也不会太大。但是pandas的功能实在太强大了,不用它来做点什么东西实在说不过去。
刚好学校教务处让我做一个合并Excel文件的小工具,把老师们每个月的绩效工资、加班津贴和各种奖励津贴等进行汇总。以前这件事情都是用VLOOKUP函数来做,表格多了以后还是挺麻烦的。还有学生成绩汇总,以前手工阅卷的时候都是由各科老师登记本人任教的班级成绩,然后汇总给备课组长或者班主任,最后再汇总到教务处。中间要经过多人的手,容易出错,如果能够让各位老师把Excel文件放到指定文件夹,直接由教务处统一来汇总,相信效率一定会提高不少。(教务处老师抗议——你是不是想把我累死)没有遇到pandas的时候,根本不想去做这件事情,现在有了pandas,似乎可以动点脑筋了。
编程过程比想象的要困难的多,幸亏有万能的群——感谢“Python算法之旅”微信群和“Python技术交流教师群”的热心朋友们——特别感谢龙思宇老师、董付国老师、虞颖健老师、裘成老师和毛岩志老师的热心帮助和启发,让我在一次次“山穷水尽疑无路”时,看到了“柳暗花明又一村”。也许这就是编程的快乐吧,不仅解决了问题、学会了方法,还见识了一些有趣的灵魂,体会到思维碰撞的快感。今天我想和大家分享的不仅是这个实用的小程序,更多的是解决问题的过程。在这个过程中我走了很多弯路,也学到了很多知识。热心的老师们给了我很大的帮助和启发,我也希望今天的这篇文章能够对大家有所启发,期待您开发出更有趣、有用的程序。
一、问题描述
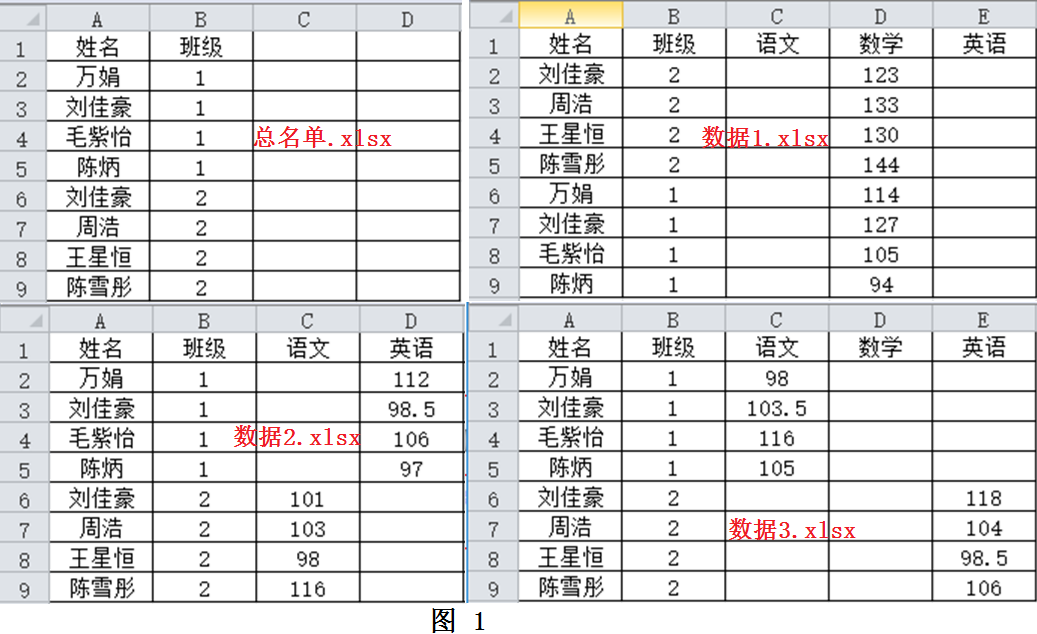
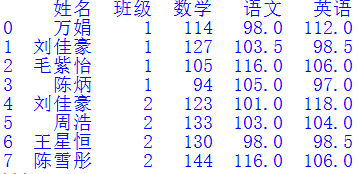
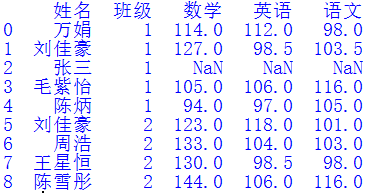
将多个Excel表格按照一定规则匹配、合成到一个文件中是常见的需求。当表格数量不多时,可以使用Excel软件的VLOOKUP函数来做。但是当表格很多,且匹配数据复杂时,该方法就不太实用了,需要寻找更好的方法。图1展示了4个Excel文件,第一份“总名单”记录了所有学生的姓名和班级信息,另外3份数据文件分别表示不同老师记录的学生成绩。其中“数据1”记录了2个班所有同学的数学成绩,“数据2”记录了1班的英语和2班的语文成绩,“数据3”记录了1班的语文和2班的英语成绩。我们希望依次将图1的3份数据文件与“总名单.xlsx”合并,获得如图2所示的“合并文件”。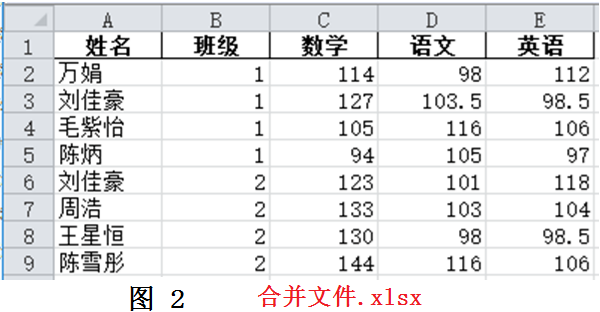
二、解题过程
pandas是基于numpy的数据分析模块,提供了大量标准数据模型和高效操作大型数据集所需的工具,能够快速便捷地进行数据分析和处理。我们今天就使用pandas模块来编程解决合并Excel文件的问题。我们首先使用函数read_excel()读取“总名单.xlsx”文件中的数据,并存储到DataFrame对象df中,代码如下:importpandas as pd #导入pandas模块file_name= "总名单.xlsx"df = pd.read_excel(file_name)
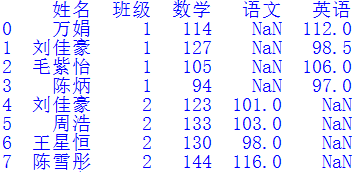
直接从Excel文件读取的数据中可能会存在一些无效列,我们需要将其清除,以便后续合并DataFrame对象。例如df中读入了两个无效列,其值都是NaN,需要清除掉,只保留姓名和班级列。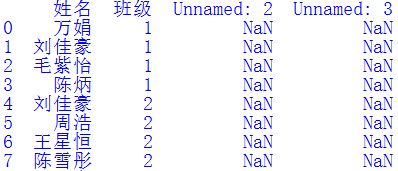
我们可以使用dropna()函数清除df中一整列都是缺失值的列。只需一行代码即可完成该功能:
df =df.dropna(axis=1,how='all') #清除df中一整列都是缺失值的列#也可以写作:df.dropna(axis=1,how='all',inplace=True)
其中inplace=True表示直接在df上修改,不返回新的DataFrame对象。清除无效数据后的df如下图所示:

第三步:合并“数据1.xlsx”文件
同样的,我们将“数据1.xlsx”中的数据存储到df2中,并清除无效数据,得到df2如下图所示:通常使用merge()函数来拼接左右两个DataFrame对象。因为1班和2班都有一个叫刘佳豪的同学,所以在使用merge()函数合并df和df2时,不能只考虑“姓名”列,必须同时以“姓名”和“班级”列作为连接键,才能确定该学生所在的行。相关代码如下:file_name = "数据1.xlsx" df2 = pd.read_excel(file_name)df2 = df2.dropna(axis=1, how='all')cols = ["姓名","班级"]df = pd.merge(df, df2, how='left', on=cols)
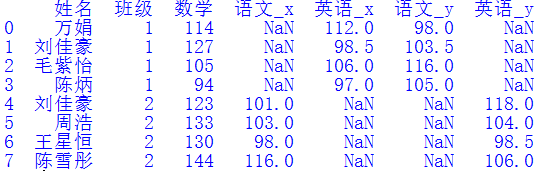
我们发现拼接结果和df2非常相似,但又略有区别。这是因为“数学”列是df2独有的,而df中除了连接键以外没有别的列,故拼接结果就是把多出的“数学”列加到了df中。然后调用merge()函数时为参数how赋值'left',即以df为基准对象,根据连接键,将df2的“数学”列拼接到df中,故各行排列的顺序与原df相同。第四步:合并“数据2.xlsx”文件
这一步的做法和第三步基本一样,除了Excel文件名不同,其他代码都是一样的。拼接结果如下图所示:
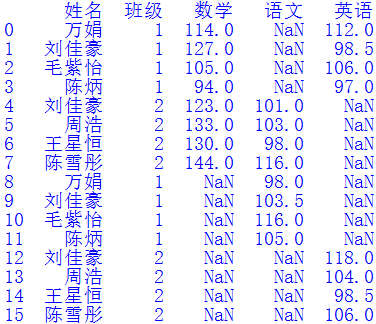
走到这一步时我遇到了困难。如果直接照搬前面的代码:df = pd.merge(df, df2, how='left', on=cols),则得到如下结果:可以看出,结果并没有合并“语文”和“英语”列,而是分成了“语文_x”、“英语_x”、“语文_y”和“英语_y”4列。我们把连接键改成cols =["姓名","班级","语文","英语"],并修改参数how='outer',则拼接结果如下图所示:结果确实是合并了“语文”和“英语”列,但它只是把df2中的数据作为新行拼接到了df中,并没有用有效数据去填充对应的NaN值。这不是我们想要的结果。那该怎么办呢?多番思索无果后,我到“Python算法之旅”微信群寻找帮助。老师们热心地答复了我,其中龙思宇老师给出的答案顺利解决了问题。他的答案非常简单,只有一行代码:
df.fillna(df2, inplace=True)
fillna()函数可以使用指定方法填充Dataframe对象的NaN值,在本例中df2中的语文和英语列恰好可以把原来df中的缺失值补上。问题完美解决。
但是——且慢,数据看上去太“完美”了——如果是有缺陷的数据呢?
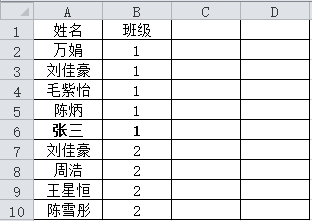
我在“总名单.xlsx”文件中间插入了一个学生,如下图所示:
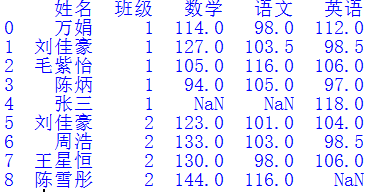
继续运行原来的代码,生成了如下结果:
果然出问题了!
在填充英语列的NaN值时,程序只知道从上向下依次填充,根本没有考虑其姓名和班级是否对得上号,结果导致乱了套。看来fillna()函数还是不够聪明。
有哪个函数能够根据关键字匹配来填充缺失值呢?
思来想去好像只有merge()函数比较适合,但是不能一步到位,需要先生成一些不必要的行或列,再想办法删除那些多余的行或列;或者把df2中的各列拆分出来,逐列处理后,再拼接到df中。
总之我想了很多办法,虽然最终能够实现想要的功能,但是算法过于简单粗暴,有违Python简明优雅的精神,实在不能令人满意!
饱受挫折的我再一次想到了万能的群。众位老师各抒己见,龙大神再次施展惊人绝技,3行代码令我茅塞顿开:
a.set_index(["班级","姓名"], inplace=True)b.set_index(["班级","姓名"], inplace=True)a.combine_first(b)
原来我被merge()函数蒙蔽了双眼,未能跳出思维定势。虽然之前也想到了其孪生兄弟join()函数,但简单试用以后发现行不通就放弃了。set_index()函数我是知道的,因为它经常和join()函数一起使用;但combine_first()函数我确实是第一次见到。学艺不精啊!宝刀在手,天下我有。有了set_index()和combine_first()函数的帮助,那一切都变得简单了。接下来就是机械地搬砖过程:cols = ["姓名","班级"]df.set_index(cols, inplace=True)df2.set_index(cols, inplace=True)df = df.combine_first(df2)
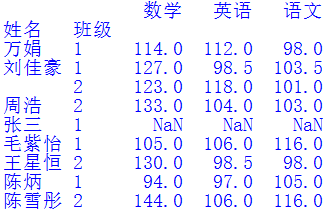
运行结果如下图所示:
为了获得我们想要的结果,还需要将上述结果按班级和姓名排序后,再把行索引还原回来,代码如下:
df.sort_values(by=["班级","姓名"], inplace=True)df.reset_index(inplace=True)
到这里,基本上就大功告成了。为了推广到一般的情形,我们可以把"数据1.xlsx"等3个Excel文件放到“合并文件夹”目录中,依次读取文件,与"总名单.xlsx"合并后,再存储到新文件"合并文件.xlsx"中。完整代码如下:#!/usr/bin/python3# 文件名: pandas应用之合并Excel文件# 作者:巧若拙# 时间:2021-12-25
import os, sysimport pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True)pd.set_option('display.unicode.east_asian_width', True) #中英文字符对齐
file_name = "总名单.xlsx"df = pd.read_excel(file_name)df = df.dropna(axis=1, how = 'all') #丢弃所有列中所有值均缺失的列basic_cols = list(df.columns) #获取基本列df.set_index(basic_cols, inplace=True)
path = "合并文件夹/"for file in os.listdir(path): try: iffile.index(".xls") or file.index(".xlsx"): new_df =pd.read_excel(path+file) new_df =new_df.dropna(axis=1, how='all') new_df.set_index(basic_cols, inplace=True) df =df.combine_first(new_df) except ValueError: print(f"{file}不是需要的文件")
df.reset_index(inplace=True)print(df)writer_file_name = "合并文件.xlsx"writer = pd.ExcelWriter(writer_file_name)df.to_excel(writer, sheet_name='汇总表', index=False)writer.save()
三、总结反思
台上三分钟,台下十年功。虽然最终呈现出来的代码没几行,但其中的过程跌沓起伏,曾经被使用和废弃的代码多达上百行,凝聚了众多朋友的智慧和本人的心血,希望能对你有所帮助。本段程序利用pandas模块提供的专业函数高效地完成了合并文件夹任务,几乎每条语句都能完成一个特定功能,体现了pandas的强悍作风,也尽量表现了Python简明优雅的编程风格。pandas在金融、统计、社会科学、工程等领域都有着广泛的应用,它提供的大量功能函数可以帮助我们快速方便地进行数据整理、分析和统计工作。但武器再好,不会用也是白搭。要想熟练使用这把“好剑”,就必须进一步深入学习,阅读相关教程和文档,提高自己的工作效率和编程水平。
除了本文提供的算法,还有很多方法也能实现合并Excel文件的功能。例如董付国老师就给我介绍了update()函数,它和combine_first()函数有一些微妙的区别,相信加以巧妙利用以后,一定也能完成任务。还有,我在文章中只提供了最基本的源代码,你可以结合tkinter,做出一个完整的作品,并打包成exe文件(就像我在视频中做的那样),提供给有需要的人。那么我就把这些作为课后作业交给你来完成吧,有什么好的想法和创意一定要记得和我交流哦!需要本文源代码和课后练习答案的,可以加入“Python算法之旅”知识星球参与讨论和下载文件,“Python算法之旅”知识星球汇集了数量众多的同好,更多有趣的话题在这里讨论,更多有用的资料在这里分享。
我们专注Python算法,感兴趣就一起来!
相关优秀文章:
阅读代码和写更好的代码
最有效的学习方式
课堂1:海龟绘图之正四边形及其拓展
课堂2:海龟绘图之多彩螺旋线
课堂3:海龟绘图之绘制虚线
课堂4:循环结构经典案例
课堂5:解析算法经典案例
课堂6:枚举算法经典案例
课堂7:算法程序实现的综合应用
利用pandas模块处理学生成绩
利用pandas模块处理百家姓数据