
温故知新 | VAE 模型推导与总结
https://zhuanlan.zhihu.com/p/434394556
此总结首次完成于2021年4月25日,今日再次遇到vae模型推导问题,翻出一看,豁然开朗,故想分享于知乎社区,与大家共同分享,如有错误或不同见解请多多批评指正与交流。
摘要
VAE 模型 loss 的详细推导过程,变分自编码器的理解。
01
1.1 VAE模型基本网络结构
变分自编码器 (VAE) 由编码器和解码器两个部分组成。特征 x 输入编码器
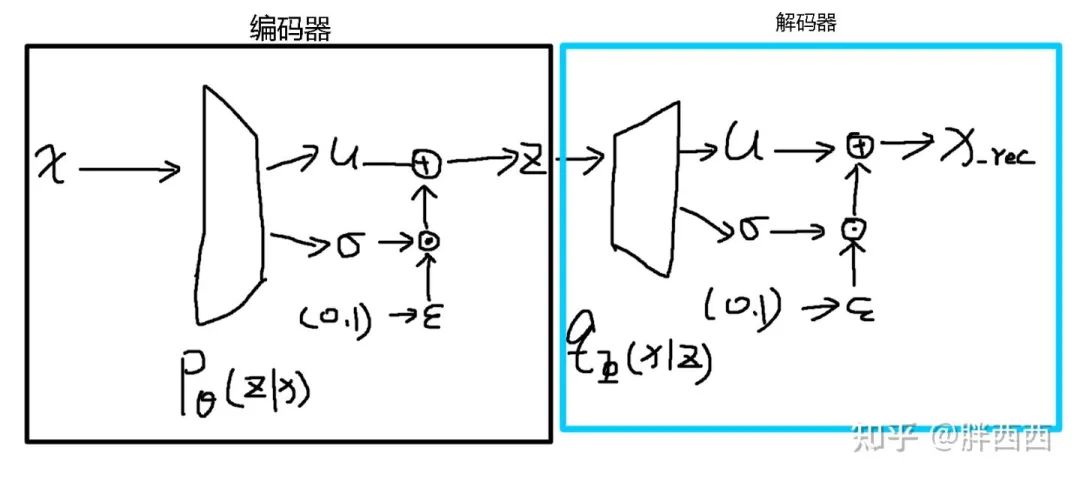
1.2
1.3 说明
变分自编码器所谓变分,指的是该模型存在泛函
02
首先需要明确VAE模型的目的就是为了使得似然函数
2.1 使得似然函数
由贝叶斯定理:
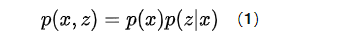
公式1变形有:
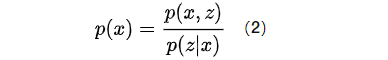
公式2左右对
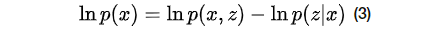
变形有,其中
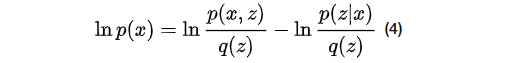
公式3两端对
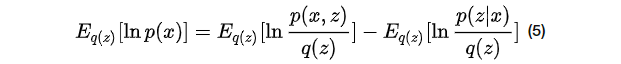
将公式4期望展开有:
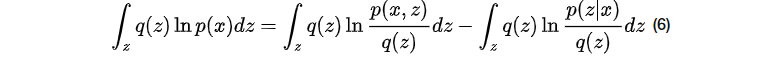
由kl散度定义,
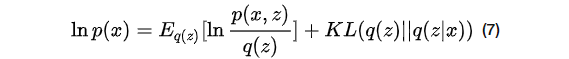
令
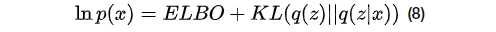
当且仅当
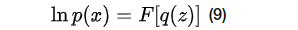
改变
所以可以来最大化
2.2 对
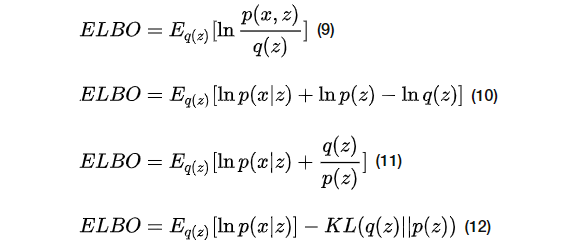
因为对于
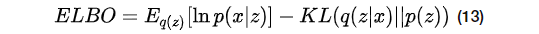
设重构的x服从于高斯分布(
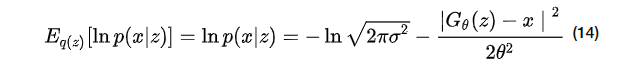
设
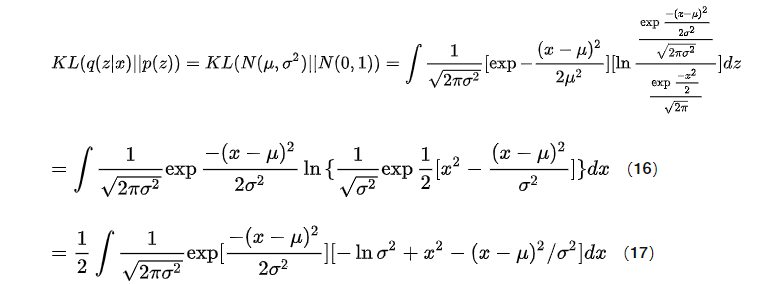
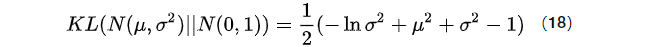
根据重构项和KL散度项的约束,我们可以得出(19)式
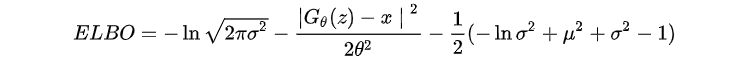
!!!!注意,
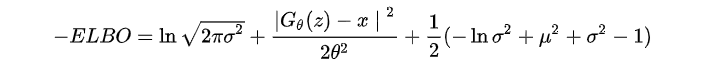
03
根据以往经验,容易犯错误的地方有,使用神经网络时候,一定要对ELBO先取负再优化!
很久之前发布的文件与代码
https://gitee.com/sulei_ustb/vae-model
猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!附下载 |《TensorFlow 2.0 深度学习算法实战》