
妹子给了我一个了乱码的Excel,我差点误会了...


为了解开粉丝的疑惑
让他面对现实
今天我就来给大家揭秘
乱码背后那些不为人知的事

首先
我们要意识到
『乱码』
本质上是编码与解码的方式不一致

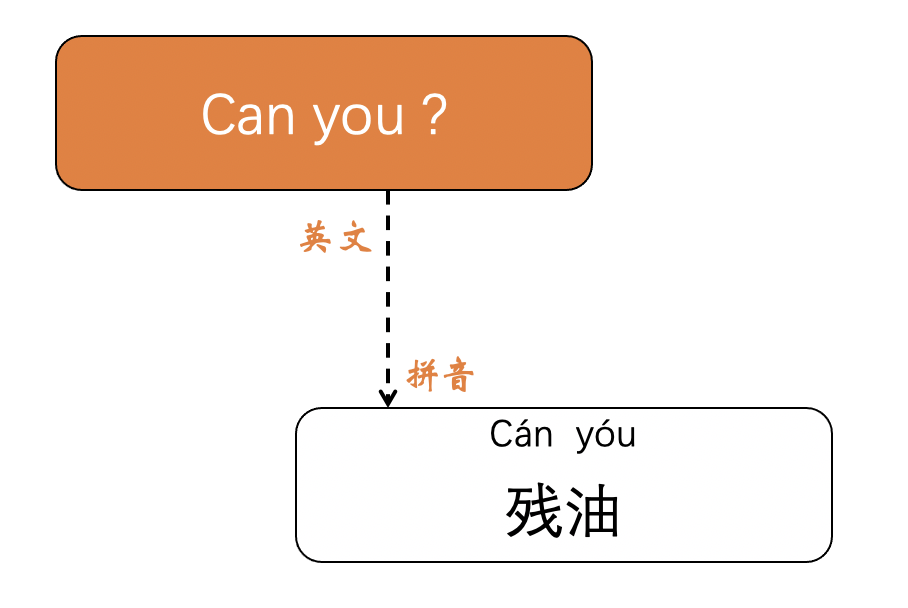
举个例子
当用拼音的方式来解读英文
事实上
Excel 对中文的解析编码
默认是 GBK

所以
当有人把 UTF-8 编码的 Excel 文件发给你
你打开后发现是一坨乱码
是很正常滴
才不是有什么隐含信息呢

那么遇到这种问题该怎么解决呢?

知道了乱码产生的原理是
读取的编码方式与写入时不一致
那么解决办法就很简单了

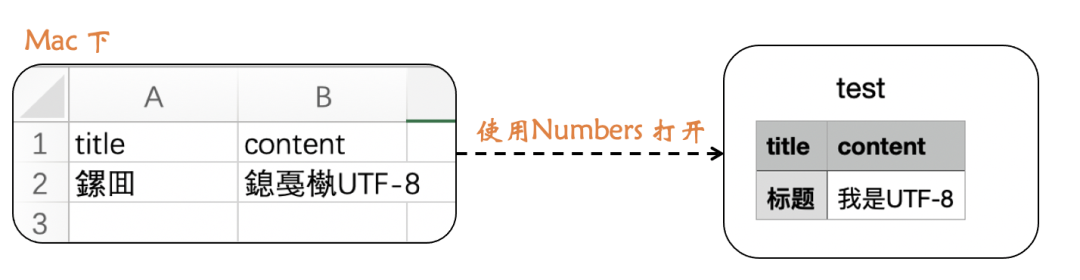
因为 Numbers 默认是 UTF-8
所以不会显示乱码

什么?你说就这?
iconv -f UTF-8 -t GB18030 test.csv > test2.csv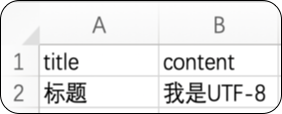
轻松搞定

既然讲到这了
那就再讲讲 UTF-8 到底是个什么东东
(非战斗人员可以撤离了)
首先,我们都知道
数据都是以二进制存储的(在电脑中)

因此
按照不同的编码方式
同一句话被编码后的 01 字符串不同
(正如我们前面所说的 UTF-8 和 GBK)

在了解 UTF-8 的具体编码方式之前
我们需要先来看看
字符集
上世纪60年代
美国制定了 ASCII 字符集
但随着各国计算机行业的发展
ASCII 不够用了
各国开始制定各自的字符集
直到 Unicode 的出现
Unicode 的制定就是为了
将世界上所有的符号都纳入其中
每一个符号都给予一个独一无二的编码
如此一来就可以解决乱码问题
(虽然到现在并没有解决)
回到 UTF-8
它其实是 Unicode 字符集的一种编码方式
UTF-8 由
肯·汤普逊
和
罗勃 · 派克
发明

其中
肯·汤普逊 是名副其实的大佬
听听
这是人话吗

知道了 UTF-8 的来历
那么 UTF-8 具体是怎么编码的呢?
UTF-8 作为一种可变长的编码方式
也就是说
不同的字符占用的字节数不同
2003年11月
UTF-8 被 RFC 3629 重新规范后
使用 1- 4个字节来进行编码
规则其实很简单

看不懂没关系
来看几个例子
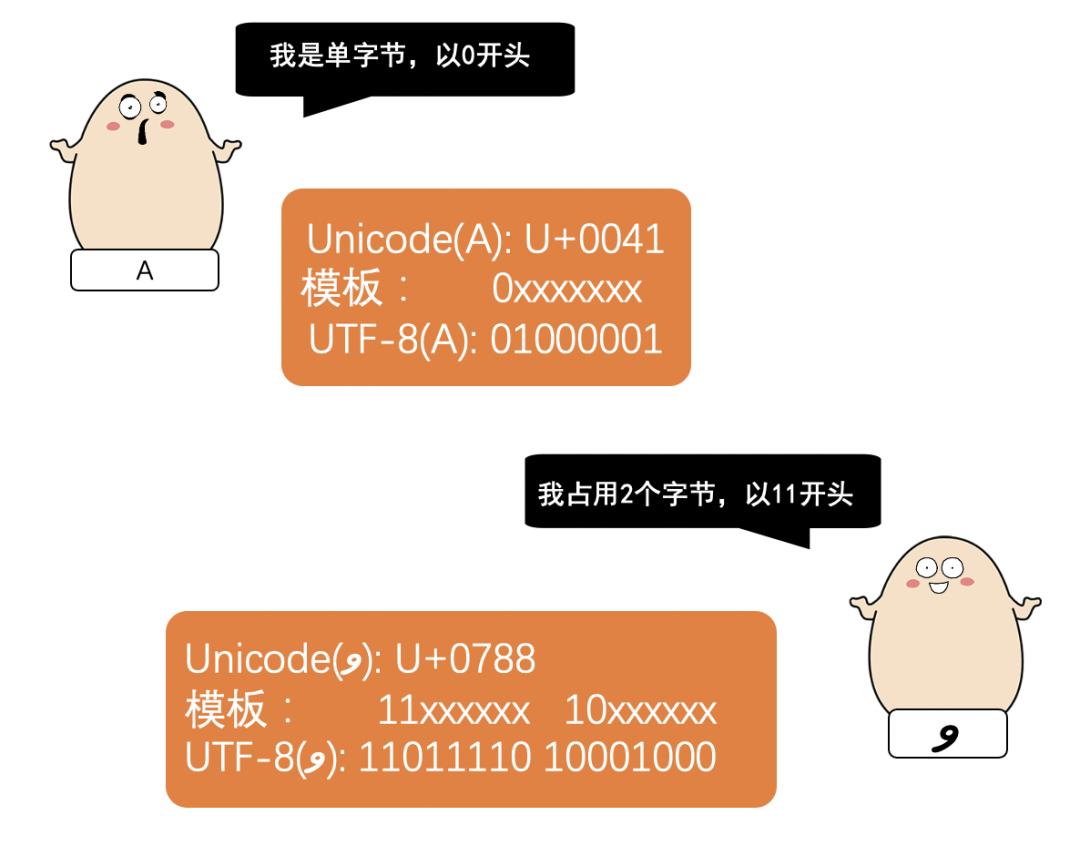
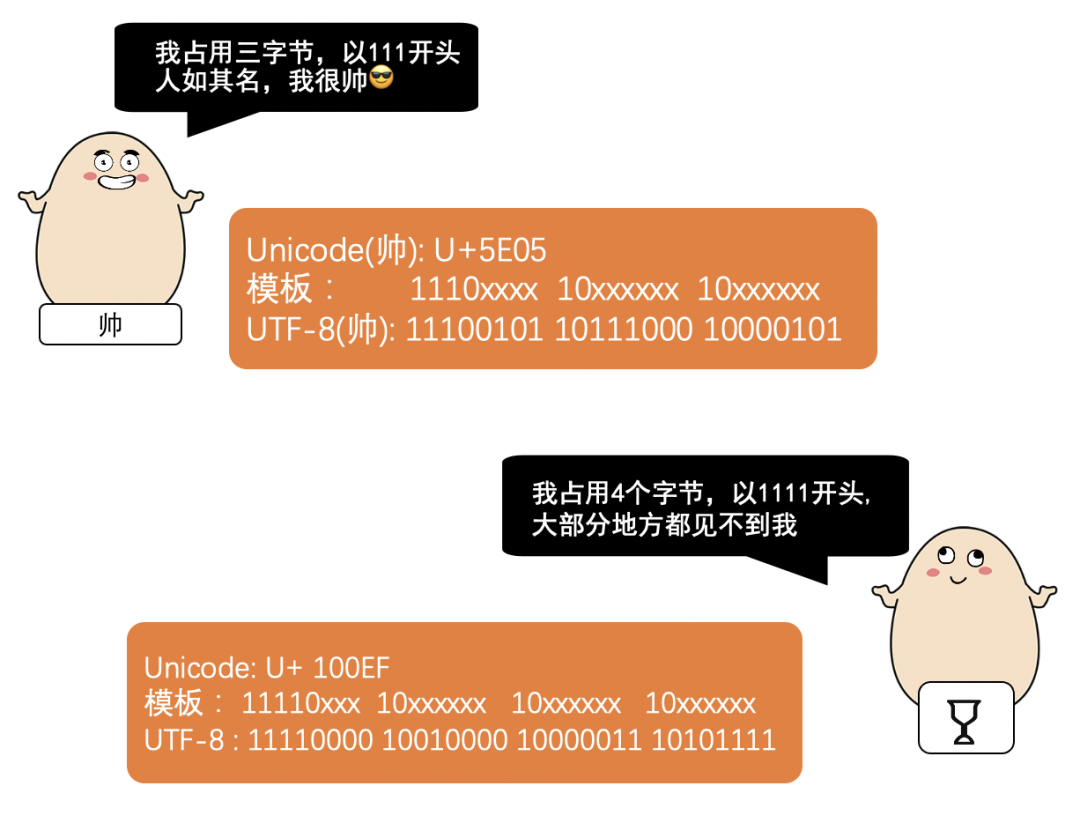
是不是很简单
什么?
你说还没看懂?

Unicode 字符查询地址:https://unicode-table.com/cn/