
为啥妹子给我发的 Excel 打开之后是乱码?


为了解开粉丝的疑惑
让他面对现实
今天我就来给大家揭秘
乱码背后那些不为人知的事

首先
我们要意识到
『乱码』
本质上是编码与解码的方式不一致

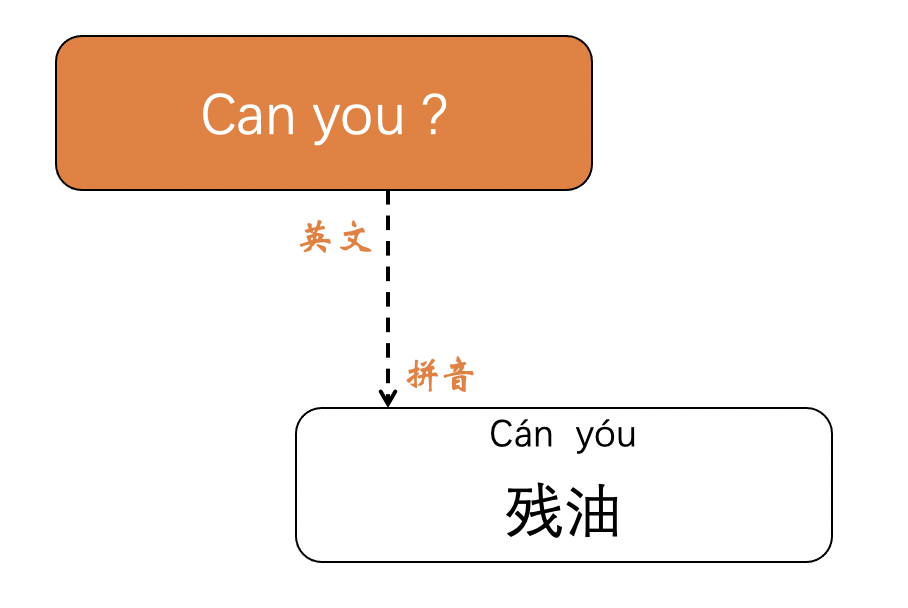
举个例子
当用拼音的方式来解读英文
事实上
Excel 对中文的解析编码
默认是 GBK

所以
当有人把 UTF-8 编码的 Excel 文件发给你
Excel 默认会用 GBK 去解析
双击打开
出现一大坨乱码
其实是很正常滴
才不是有什么隐含信息呢

那么遇到这种问题该怎么解决呢?

知道了乱码产生的原理是
读取的编码方式与写入时不一致
那么解决办法就很简单了
(把读取的编码方式改为 UTF-8)

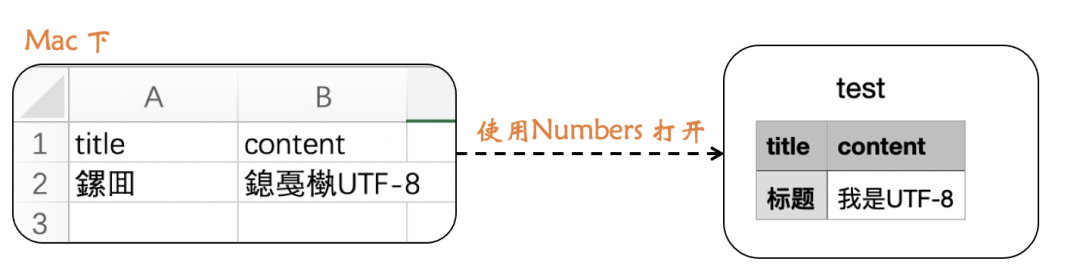
因为 Numbers 默认是 UTF-8
所以不会显示乱码

什么?你说就这?
iconv -f UTF-8 -t GB18030 test.csv > test2.csv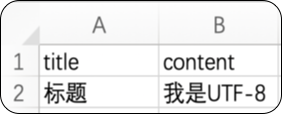
轻松搞定

既然讲到这了
那就再讲讲 UTF-8 到底是个什么东东
(非战斗人员可以撤离了)
首先,我们都知道
计算机起源于美国
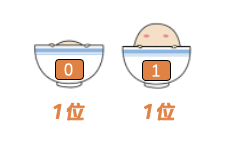
他们用二进制来存储数据

每一个 0 或 1 称为一位
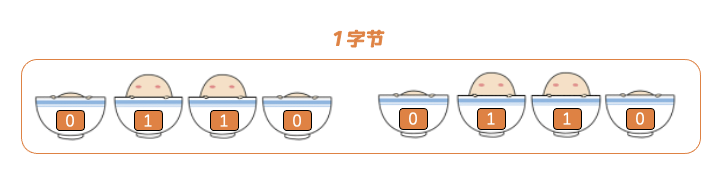
而八位就组成了一个字节
每一位能标识两种状态
每个字节则能标识 2^8 = 256 种状态
那么这些状态有啥用呢?

美国人把 0 - 127 这 128 个状态
都映射到各种字符上
包括大小写英文字母、标点符号、数字等
这就是常说的 ASCII 字符集

后来
随着其他国家开始使用计算机
ASCII 里没有他们的字母
他们便利用起剩下的 128 - 255 位
这被称为 ASCII 拓展字符集
然而
事情并没有这么简单
等到中国人开始使用计算机时
已经没有多余的位置了
咋办呢?

智慧的中国人民
毫不客气地去掉了127 位之后的编码
用 2 个字节来编码一个汉字
这样一来
7000 多常用汉字的编码问题就解决了
这就是 GB2312 编码
它是对 ASCII 的中文拓展
但汉字实在太多了
GB2312 不够用了咋办呢
这个问题充钱(拓展)就能解决

这回拓展出了GBK
不仅包含 GB2312 所有内容
还包含了 20000 多个
新的汉字(含繁体字)

再后来少数民族也要用电脑了
GBK 又拓展成了 GB18030
这一系列汉字编码标准被通称为
DBCS

中国人的编码问题解决了
但日本、韩国各自的编码问题咋办呢?
他们也各自搞了一套自己的编码标准
结果就是
谁也不支持谁
兼容性问题眼看着愈来愈严重
这可咋办呢?
这时
Unicode
闪亮登场
Unicode 的制定就是为了
将世界上所有的符号都纳入其中
每一个符号都给予一个独一无二的编码
如此一来就可以解决乱码问题
(虽然到现在并没有解决)
这就是字符集的发展过程
回到 UTF-8
它其实是 Unicode 字符集的一种编码方式
UTF-8 由
肯·汤普逊
和
罗勃 · 派克
发明

其中
肯·汤普逊 是名副其实的大佬
听听
这是人话吗

知道了 UTF-8 的来历
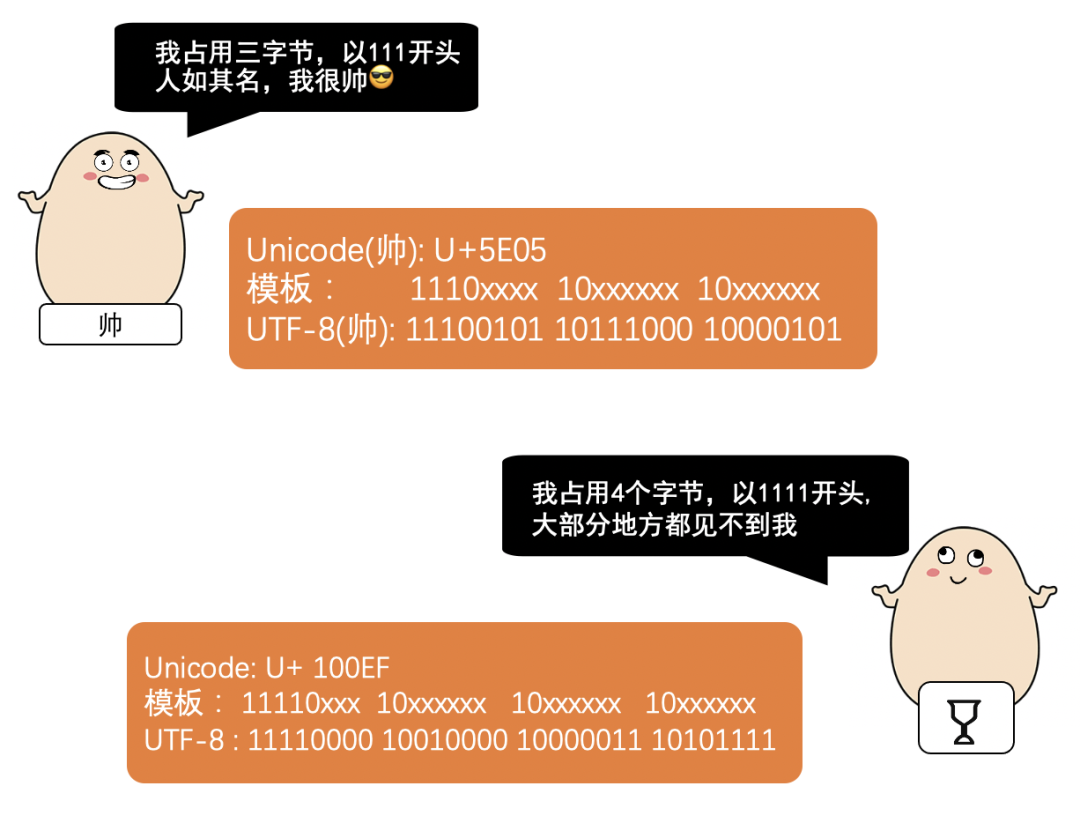
那么 UTF-8 具体是怎么编码的呢?
UTF-8 作为一种可变长的编码方式
也就是说
不同的字符占用的字节数不同
2003年11月
UTF-8 被 RFC 3629 重新规范后
使用 1- 4个字节来进行编码
规则其实很简单

看不懂没关系
来看几个例子
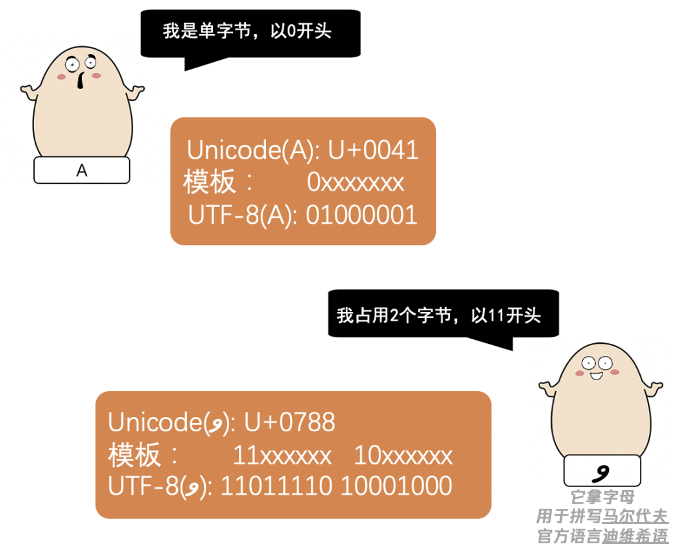
按照不同的编码方式
同一句话被编码后的 01 字符串不同
(正如我们前面所说的 UTF-8 和 GBK)

是不是很简单
什么?
你说还没看懂?


参考及拓展阅读
[1] Unicode 字符查询地址:https://unicode-table.com/cn/
[2] 码农翻身《编码的故事》: https://mp.weixin.qq.com/s/ejxh9wghrj6WepSSCL4-9A
往期推荐


