
Python人工智能在贪吃蛇游戏中的运用与探索(中)
上篇我们说到用「DQN」来实现贪吃蛇训练,也就是用**Q(s,a)**和搭建神经网络来实现。
传送门:干货 | Python人工智能在贪吃蛇游戏中的应用探索(上)
那么我们如何合理的处理数据?
我们知道Q(s,a)中的state表示蛇的状态。这个状态包括苹果的位置,蛇的位置,边界的位置,蛇和边界的距离等等等等。如何表示这么多的内容,并准确的传入神经网络进行计算呢?
我们使用了一个很重要的数据结构-----「张量」。
这一次,我们的主题是:「张量(Tensor)是什么,是怎么流动的(Flow)?」
「什么叫张量(tensor)」
首先声明这里我们指的张量(tensor )是「Tensorflow」里最基本的数据结构.它是tensorflow最重要的概念,顾名思义,flow是流动的意思,tensorflow就是tensor的流动。「它和物理学中的tensor不是同一」个概念。
那张量到底是什么东西呢?简单点说,张量就是多维数组的泛概念。通常一维数组我们称之为向量,二维数组我们称之为矩阵,这些都是张量的一种。我们也会有三维张量、四维张量以及五维张量等等。零维张量就是一个具体的数字。
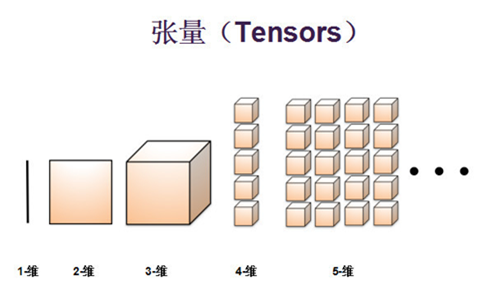
张量的基本概念
下图是全国某些城市的疫情图,它是一个三维的张量。
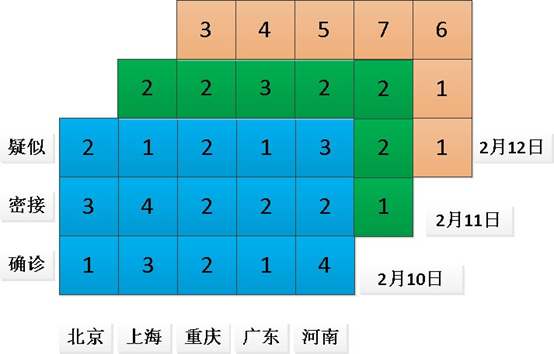
从上面图中,可以分析出张量的基本概念:
「维度」 也就是数据轴的个数。如前图数据有3个轴,分别指城市,分类,时间。借用生命科学中的知识,界门纲目科属种即可以表示生物分类的七个维度。
「形状」 表示张量沿每个轴的大小(元素个数),也就是shape。前面图矩阵示例的形状为(3, 5),3D 张量示例的形状为(3, 5, 3)。
「数据类型」 这是张量中所包含数据的类型,例如,张量的类型可以是float32、int32、float64 等。很少情况下,会遇到字符(char)张量
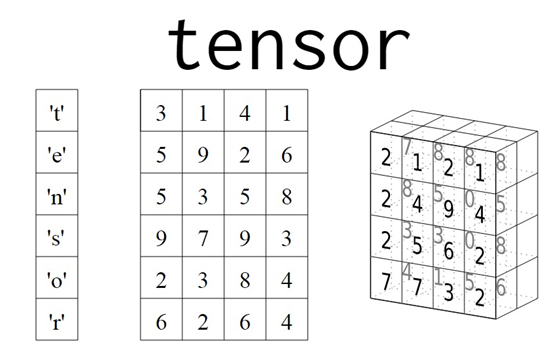
下图是张量的立体图形
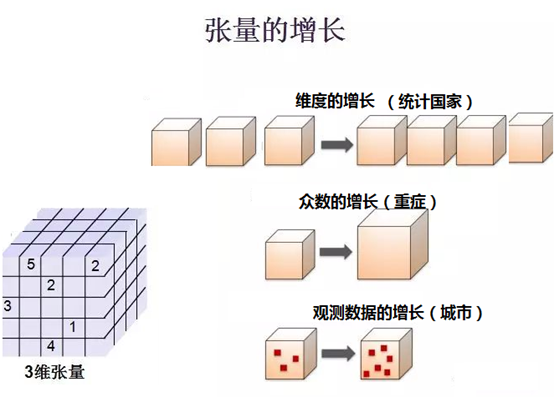
张量是可以根据实际情况增长或者缩小。比如我可以方便的增加一个统计的城市,可以增加统计的分类,可以增加统计的时间。随着疫情的发展,我们增加一个维度统计各个国家的疫情状况。
到这里,也许会有人将n维张量看作树状图,每个维度的元素都会有下面的分支,又有更下面的分支。硬要说,是一种特殊的树状图。由于shape的特性,n维的元素所包含的n-1维元素数量是相等的。例如shape为(2,2,3)的张量,二维有两个元素,那么他们一维具有的元素数是相等的。这与树状图每个分支可以无规则拓展是不同的。
张量或许存在一定的缺陷,但仍然是处理数据的最佳载体之一,尤其是在游戏制作中,多变量存在张量中可以更容易运用库函数进行各种操作。
「张量的表现形式」
在数学里面也有n维向量的说法,其实他们都是一维张量,数学中的N维向量指的是分量的个数,比如[1,2]这个向量的维数为2,它有1和2这两个分量;[1,2,3,······,1000]这个向量的维数为1000。在张量的概念中,他们都是一维张量。
那么,张量的维数和形状怎么看呢?
张量的shape本身是一个「元组」,元组元素的「个数」就代表了维度数,而从tuple[0]开始,表示每一维度(「从高维到低维」)的元素数量。比如(2,3)就表示为一维有3个元素,二维两个元素的二维张量。
「tensorflow中使用张量的优势」
用tensorflow 搭建的神经网络,输入层和输出层的值都是张量的形式。由于张量模型可以处理指标集(元素项)为多维的数据,所以在描述实际问题时,相比矩阵模型其更能接近于实际问题的属性,因此能更好地描述实际问题,** 从而保证神经网络算法是有效的
同时tensorflow库具有降维的作用,例如在DQN中,输入的是多维的描述环境的张量,内含许多复杂的小数,经处理输出的就是代表了上下左右四个可选择的动作的数字。
「张量通过numpy 实现数据的流动」
NumPy是Python中科学计算的基础包。它是一个提供多维数组对象,各种派生对象(如掩码数组和矩阵),以及用于数组快速操作的各种例程,包括数学,逻辑,形状操作,排序,选择,I / O离散傅立叶变换,基本线性代数,基本统计运算,随机模拟等等。
tensor最大的问题是不能游刃有余的进行数据的计算,比如:要对tensor进行操作,需要先启动一个Session, 否则,我们就无法对一个tensor进行简单的赋值或者判断的操作,这种限制对于程序来说是致命的。而数据在流动过程中需要大量的复杂的运算。所以,借助于numpy强大的计算能力,tensor与numpy方便的数据转换,它们完美的实现神经网络复杂的计算工作。
一般的操作过程是:tensorflow定义所有的计算过程,即计算流图,并建立神经网络,创建输入tensor,这时候,表示一个定义计算过程,并不真正进行计算;然后进入下一步,tensor通过显性或者隐性自动转换成numpy执行运算,这时候就是发挥numpy的计算能力的时候了。
「贪吃蛇程序中张量的使用」
上篇所谈到的搭建神经网络就是张量的运用之一。下面,我来简单介绍一些其他运用。
- 「创建与调用初始化张量」
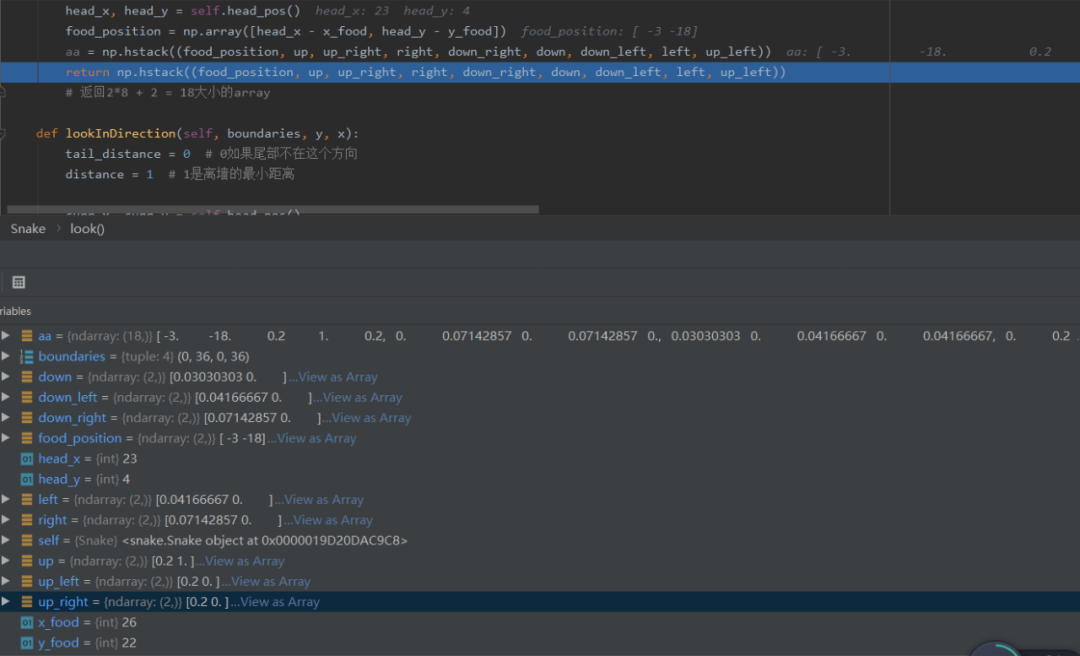
self.STATE = self.SNAKE.look(self.FOOD_X, self.FOOD_Y, boundaries))
将食物的位置坐标转化为numpy型储存
使用了np.hstack将各元素进行了水平堆叠,这些元素主要受蛇头方向和果实刷新位置影响,即果实在蛇头方向的上下左右、左上等等。
- 「经验的取出(memory)」
states, actions, rewards, next_states, dones = zip(*experiences)
\# 将信息转化成numpy格式
states = np.array(states).reshape(self.BATCH_SIZE, state_shape)
actions = np.array(actions, dtype='int').reshape(self.BATCH_SIZE)
rewards = np.array(rewards).reshape(self.BATCH_SIZE)
next_states = np.array(next_states).reshape(self.BATCH_SIZE, state_shape)
dones = np.array(dones).reshape(self.BATCH_SIZE)
return states, actions, rewards, next_states,
dones
我们先用zip*将张量拆开(此处的变量即为贪吃蛇原理的核心),再转化成numpy形式取出,方便后续用numpy进行数据处理。
- 「降维计算」
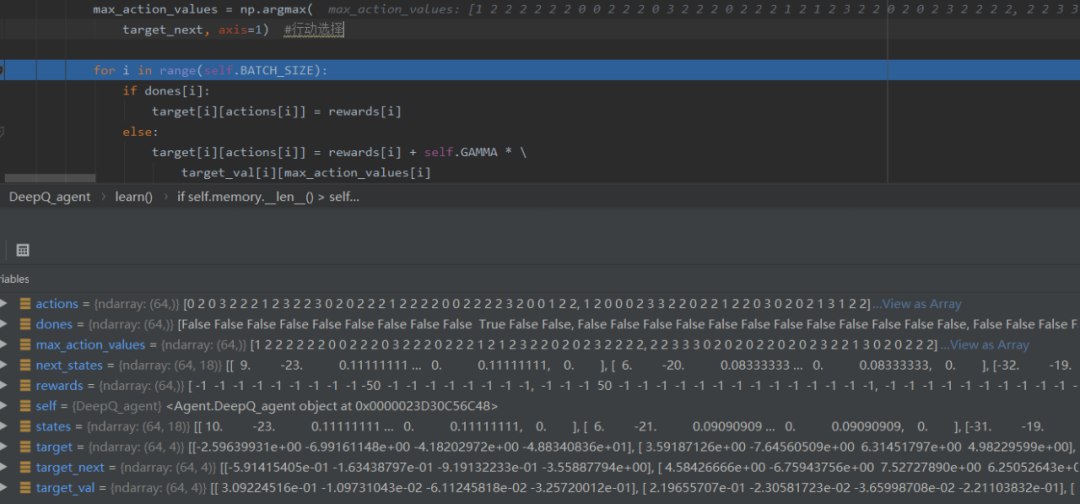
从上面图中可以看到,存储的数据往往有18项,最终我们通过tensorflow和numpy数据处理,将18个float8数据化成了action,即用0,1,2,3来表示方向。由上图,由于训练批次为64,所以action中有64个数,即为当时计算出的蛇的64次最佳行动。
下一篇中,我们将从贪吃蛇代码入手,分析并解释贪吃蛇代码的形成。
参考文献:
百度百科
百度图片
推荐阅读:
干货 | 学习算法,你需要掌握这些编程基础(包含JAVA和C++)
记得点个在看支持下哦~
