
港科大&快手提出首个视频抠图框架!复杂背景下依然优异!CVPR2021
共 3055字,需浏览 7分钟
·
2021-07-10 05:49
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
https://github.com/nowsyn/DVM
https://arxiv.org/abs/2104.11208
视频demo链接:https://www.bilibili.com/video/BV1F44y1B7Nd
本文来源:https://mp.weixin.qq.com/s/XFnUeaXErTgGDGjjn-pQ4Q
摘要

本文提出了一种新的深度视频抠图框架,该框架利用了目标与参考帧以及相邻帧之间的时间信息。该框架采用了一种新的时空特征聚合模块的编解码结构。提出的模块有助于我们的模型在增强时间相干性,导致显着更好的alpha 预测对象快速运动或复杂的背景。本文还构建了一个大规模的视频抠图数据集,该数据集涵盖了大量独特的抠图案例,填补了当前和未来深度视频抠图研究中的数据空白。我们已经在我们提出的测试集和真实世界的高分辨率视频上进行了大量的实验,以验证我们的方法处理复杂场景的有效性
基本概念和遇到的问题
近年来,自媒体行业大火,有一大批人涌入,特别是视频领域,催生了更复杂的视频抠图的需求,如何提升视频抠图效果也成为了时下的重要课题之一。
首先要明白的一个问题是,什么是抠图?
抠图问题可以用下面的公式来定义:
公式中各个参数的具体含义:
图片
给定一张图片,由于前景和背景未知,因此对Alpha的估值是一个不适定问题,Trimap图通常作为额外输入来限定求解空间。Trimap是一个三类别的掩膜,用来指定确定的前景、背景以及未知的区域,而未知区域就是需要估值的区域。在实际应用场景中,Trimap可以来源于用户输入,特定场景下也可以由预训练的模型自动产生;比如人像抠图中,可以用人像分割模型预测的掩膜代替Trimap来提供先验知识。
视频抠图存在的问题:
1、缺乏大规模的深度学习视频抠图数据集,这是限制视频抠图发展的首要因素(数据集)
2、如果直接将图像抠图算法移植到视频数据上,需要对每一帧提供Trimap,然而逐帧标注Trimap显然不切实际,那么如何节省标注成、减少人力介入也是不可忽视的问题(Trimap获取)
3、视频抠图与图像抠图的最大区别就是前者需要考虑帧之间的连续性,如何利用时域信息减少抖动成为了新的挑战。(帧间信息和抖动问题)
解决思路:新的视频抠图框架
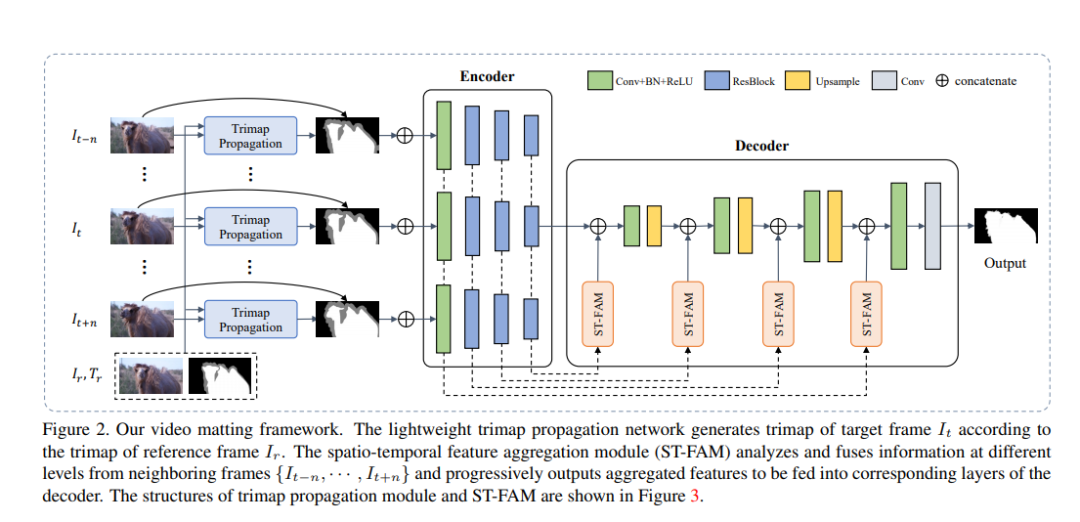
该算法是一个两阶段算法,可以在仅提供少量关键帧的Trimap下,将Trimap传播到其他帧,并融合相邻帧的时域信息产生具有连续性和一致性的预测结果。
特点:无需计算光流,为并行计算提供了便利;并提出一个基于合成的大规模视频抠图数据集
具体解决方案:
Trimap传播算法
传统的Trimap传播算法通常依赖于光流,然而现有的光流算法不擅长处理精细结构和带有大量透明度像素的场景。而这些场景又是视频抠图任务中常遇到的场景,为了避免依赖光流引入的误差,文中使用了跨越注意力(Cross-attention)机制来传播Trimap。对于一段视频,只需要人为标注极少量关键帧的Trimap,而其他帧则通过传播算法来自动生成Trimap,从而节约大量Trimap的标注成本。其中,人工标注Trimap的帧为参照帧,而未被标注的帧称为目标帧。网络框架如下图。
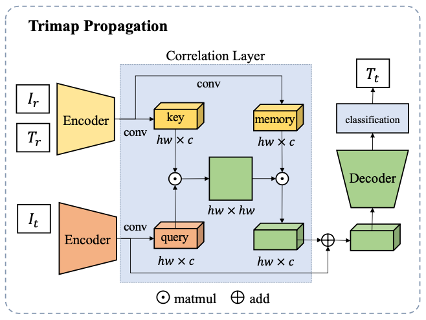
使用两个分享权重的编码器,来分别提取参照帧(F_r)和目标帧(F_t)的语义特征。
使用跨越注意力网络来计算目标帧与参照帧的像素间相似度关系。根据特征相似度的计算公式,如果一个目标帧像素属于前景的话,它也会被对应到参照帧里的前景像素,通过这种对应得到目标帧编码后的特征。
用解码器将编码特征重建后,对每个像素分类做三类别分类,产生最后的Trimap。
对于前景运动幅度较小的场景,此方案可以仅提供第一帧Trimap输入;即使在前景物体运动幅度较大的场景下,此方案在可以仅依靠少量关键帧Trimap为视频生成所有帧的Trimap,极大的减少了人工成本。与依赖光流的算法相比,该算法性能不受光流限制,预测更稳定,生成的Trimap质量也更高。同时这个模块可以接入到任意图像抠图算法上,具有普适性。下图是Trimap传播的例子。

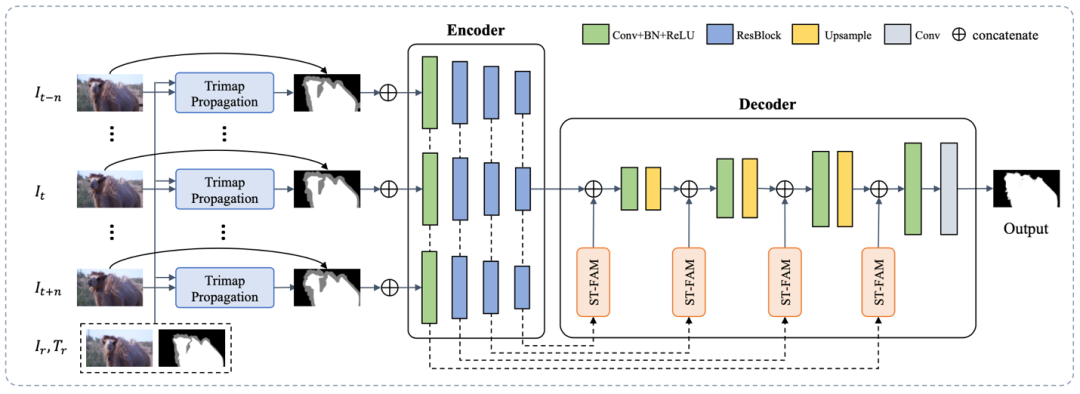
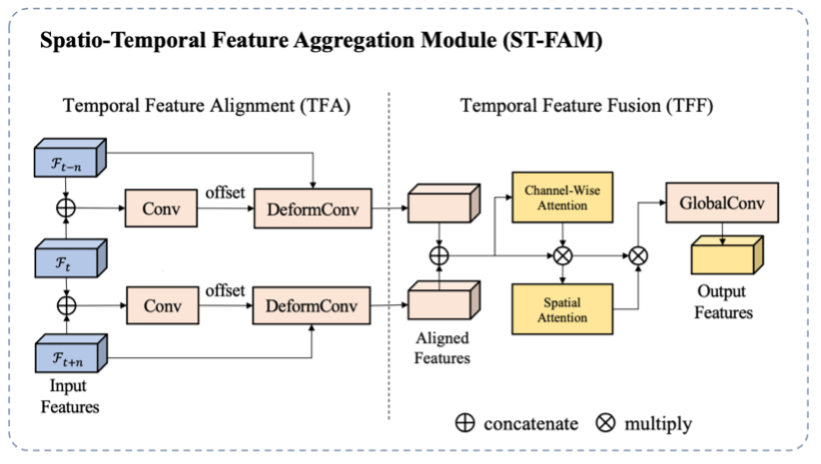
算法主体是一个自动编码器-解码器结构,在编码器与解码器之间有跳层连接,用来将不同层级的特征连接到解码器从而重建原始尺度的Alpha预测。为了利用视频里的时序信息,作者同时将目标帧以及其邻近帧送到编码器中得到对应的多帧多尺度空间特征,并通过时空特征融合模块(ST-FAM)将多帧特征融合,从而将时序信息编码到特征里。ST-FAM模块包括两个子模块: 时序特征对齐(TFA)模块和时许特征融合(TFF)模块,具体结构图如下图。
努力分享优质的计算机视觉相关内容,欢迎关注:
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看