
一文详解LLM评估:大模型评测什么、在哪评测、如何评测?
自谷歌2017年发布的Transformer网络结构以来,仅用五年多时间全球已迅速成长出庞大的大模型技术群,衍生出涵盖各种技术架构、各种模态、各种场景的大模型家族。
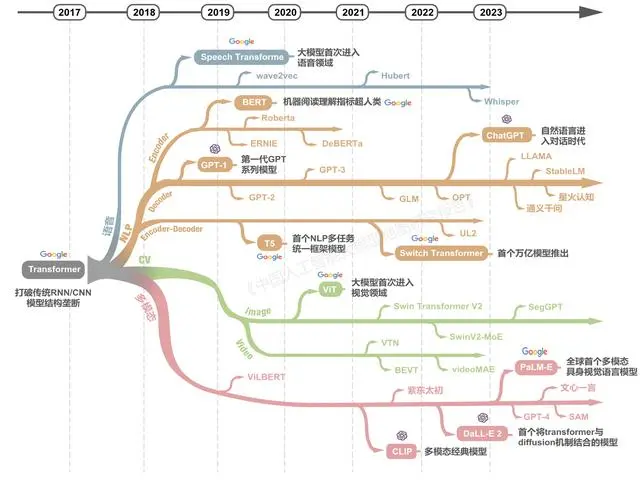
图注:中美引领全球大模型发展
从全球已发布的大模型分布来看,中国和美国大幅领先,超过全球总数的80%,美国在大模型数量方面始终居全球最高。美国谷歌、OpenAI等机构不断引领大模型技术前沿。欧洲、俄罗斯、以色列、韩国等地越来越多的研发团队也在投入大模型的研发。
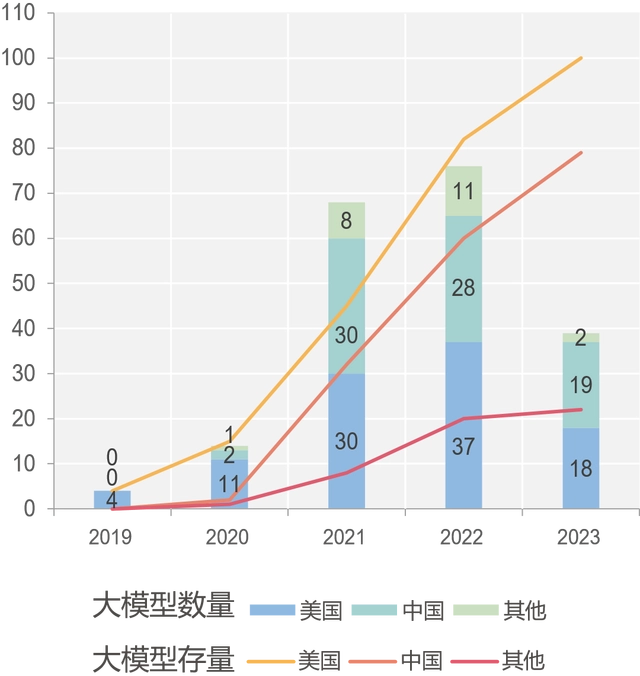
图注:中国大模型呈现蓬勃发展态势
5月,国家科技部下属的中国科学技术信息研究所,发布了《中国人工智能大模型地图研究报告》。内容显示,截至5月28日,国内10亿级参数规模以上基础大模型至少已发布79个。

图注:中国大模型分布地图
7月,国际咨询公司IDC发布《AI大模型技术能力评估报告2023》,调研了14家中国市场主流大模型技术厂商。IDC评估报告围绕产品技术、服务生态以及行业应用三大维度,考察大模型的10余项指标,其中“算法模型”和“行业覆盖”成为衡量大模型能力极其重要的两个指标。其中,「百度文心大模型3.5」拿下12项指标的7个满分,综合评分第一,算法模型第一,行业覆盖第一。阿里云在11项指标中获得通用能力、服务能力、创新能力、生态合作等6项满分,是唯一一家“服务能力”满分厂商。
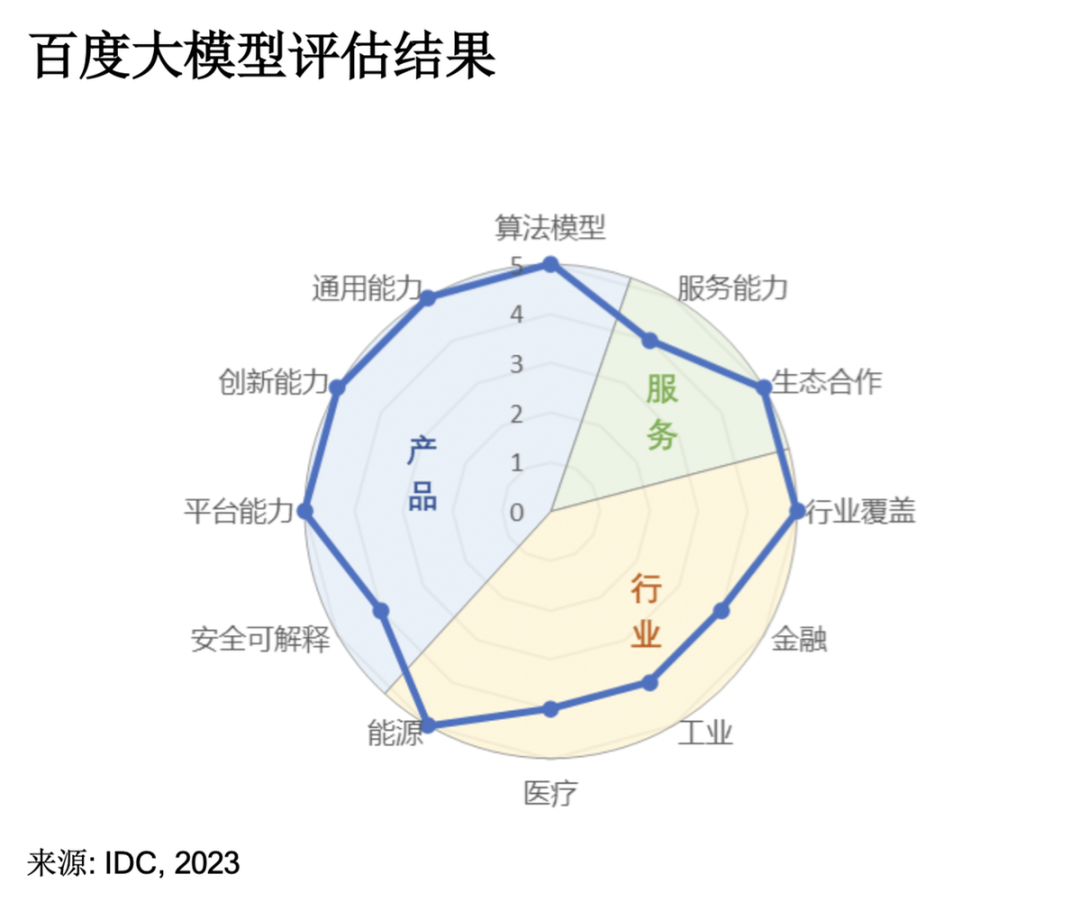

图注:阿里巴巴大模型评估结果
ChatGPT 带火了大模型应用的相关研究,评测基准也受到极大关注。在每个大模型贴上“技术领先”、“性能第一”等标签时,我们不免质疑:如何直观地评判哪一款大模型在技术和性能上更为卓越?那些宣称“第一”的评估标准与数据来源又是怎样的?
前不久,微软亚洲研究院公开了介绍大模型评测领域的综述文章《A Survey on Evaluation of Large Language Models》。该论文一共调研了219篇文献,以评测对象 (what to evaluate)、评测领域 (where to evaluate)、评测方法 (How to evaluate)和目前的评测挑战等几大方面对大模型的评测进行了详细的梳理和总结。

论文:A Survey on Evaluation of Large Language Models
机构:微软亚洲研究院
论文地址:https://arxiv.org/pdf/2307.03109.pdf
开源链接:https://github.com/MLGroupJLU/LLM-eval-survey
大模型评测相关研究:https://llm-eval.github.io/


根据不完全统计(见下图),大模型的评测方面发表的文章呈上升趋势,越来越多的研究着眼于设计更科学、更好度量、更准确的评测方式来对大模型的能力进行更深入的了解。
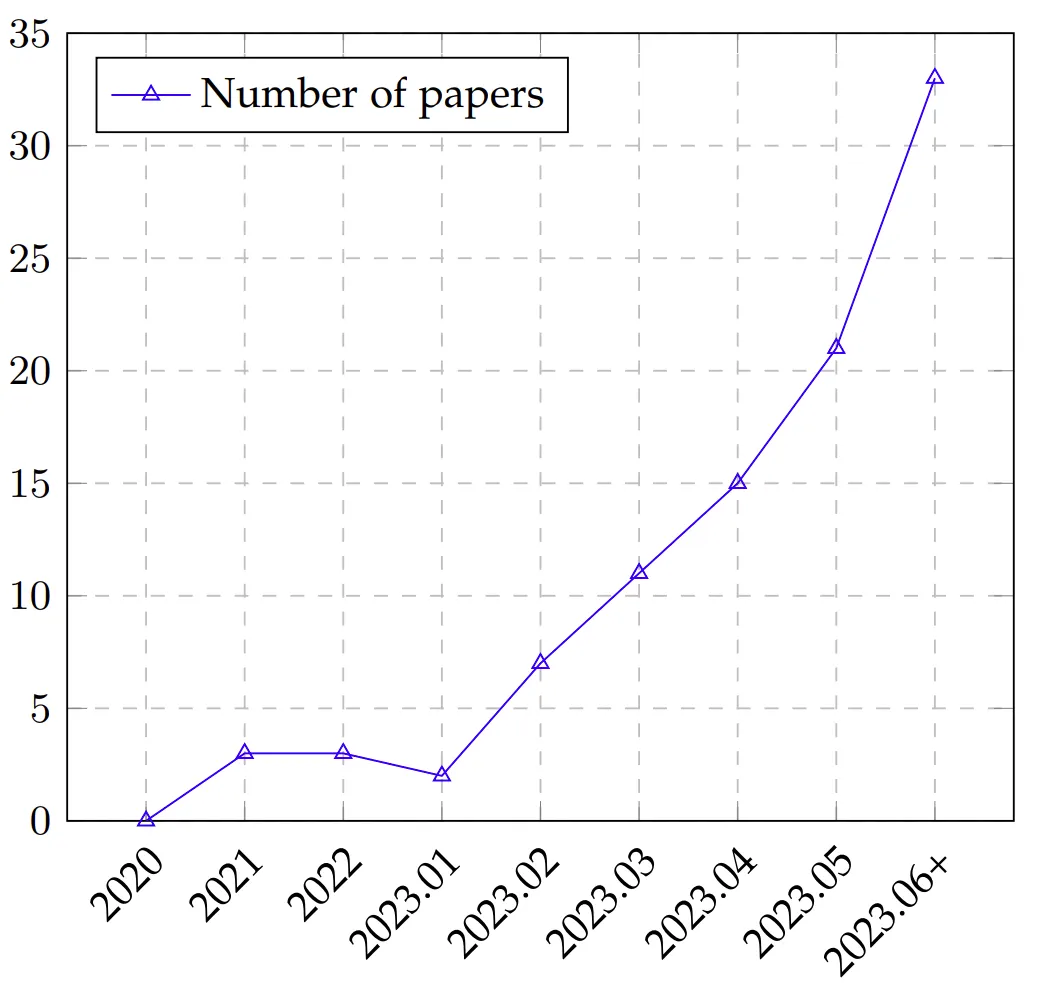
图注:LLM 评估论文随时间的趋势,从 2020 年到 2023 年 6 月(6 月数据包含 7 月的部分论文)
这篇论文作为大型语言模型(Large language models, LLMs)评测的首次全面综述,主要从三个方面对现有工作进行了探索:

图注:AI 模型的评估过程
评测内容 (What to evaluate),对海量的 LLMs 评测任务进行分类并总结评测结果;
评测领域 (Where to evaluate),对 LLMs 评测常用的数据集和基准进行了总结;
评测方法 (How to evaluate),总结了目前流行的两种 LLMs 评测方法。
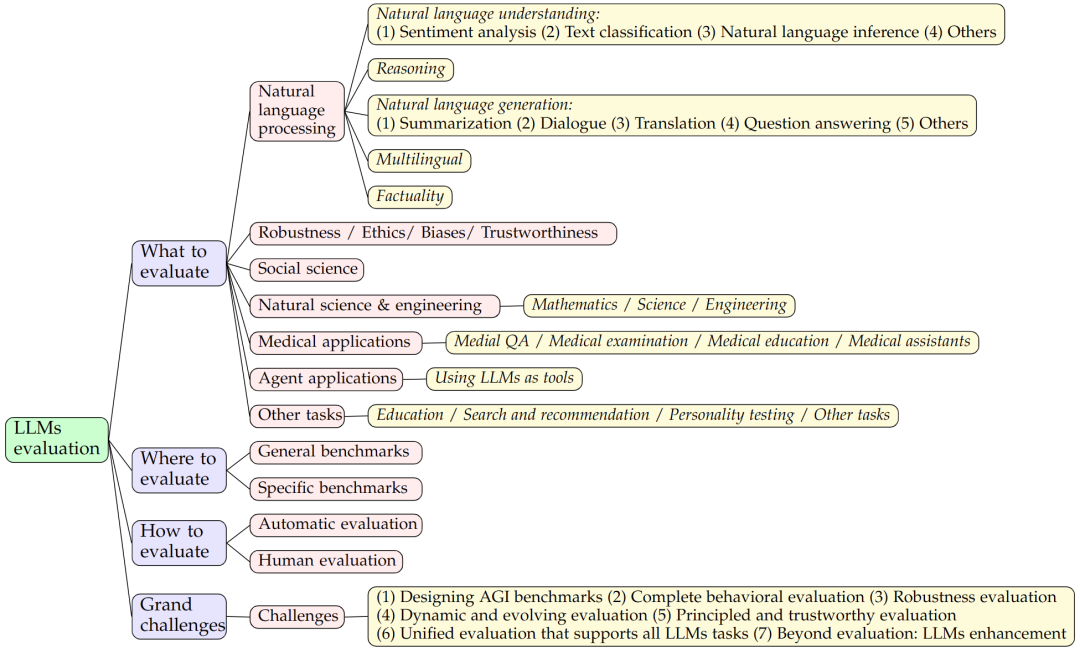
图 1:论文研究框架
通俗来讲,大模型是一个能力很强的函数 f,与之前的机器学习模型并无本质不同。那么,为什么要研究大模型的评测?大模型评测跟以前的机器学习模型评测有何不同?
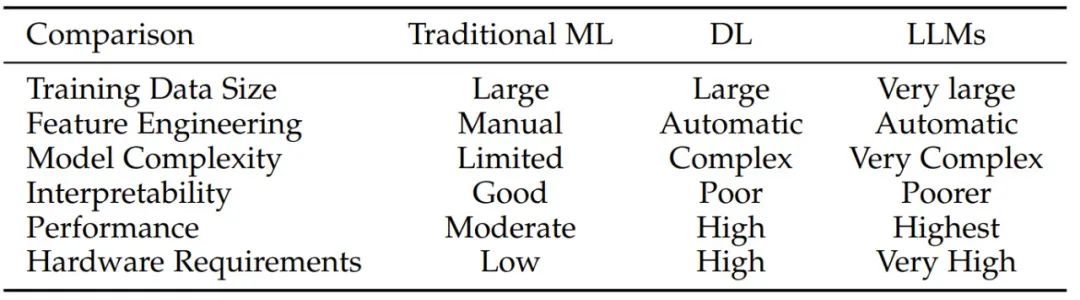
图注:对比传统机器学习、深度学习和 LLM
大型语言模型(Large language models, LLMs)背后的核心模块是 Transformer 中的自注意力模块,一大关键特性是上下文学习,最初开发也是为了提升 AI 在自然语言处理任务上的性能。正因为此,大多数评估研究关注的也主要是自然语言任务。
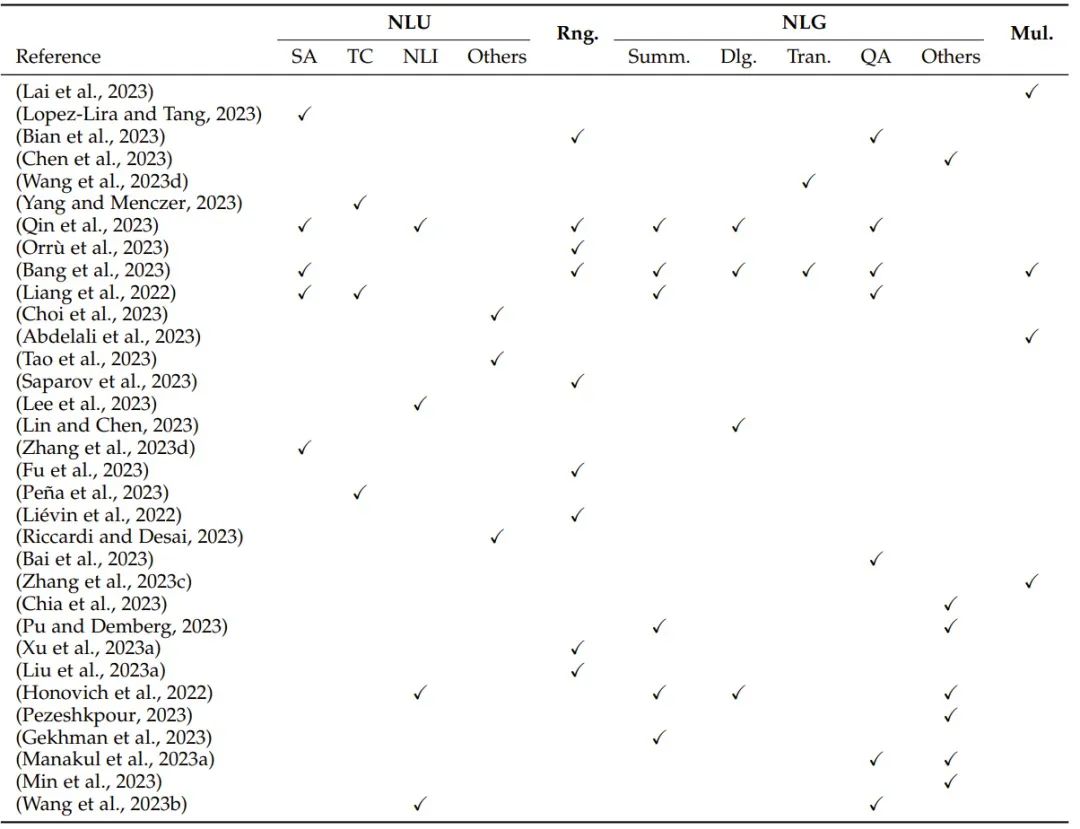
图注:表 2:基于自然语言处理任务的评估概况:NLU(自然语言理解,包括 SA(情感分析)、TC(文本分类)、NLI(自然语言推理)和其它 NLU 任务)、Rng.(推理)、NLG(自然语言生成,包括 Summ.(摘要)、Dlg.(对话)、Tran.(翻译)、QA(问答)和其它 NLG 任务)和 Mul.(多语言任务)
为了更清晰地展示 LLMs 的能力水平,文章将现有的任务划分为以下7个不同的类别:
自然语言处理:包括自然语言理解、推理、自然语言生成和多语言任务;
鲁棒性、伦理、偏见和真实性;
医学应用:包括医学问答、医学考试、医学教育和医学助手;
社会科学
自然科学与工程:包括数学、通用科学和工程;
代理应用:将 LLMs 作为代理使用;
其他应用
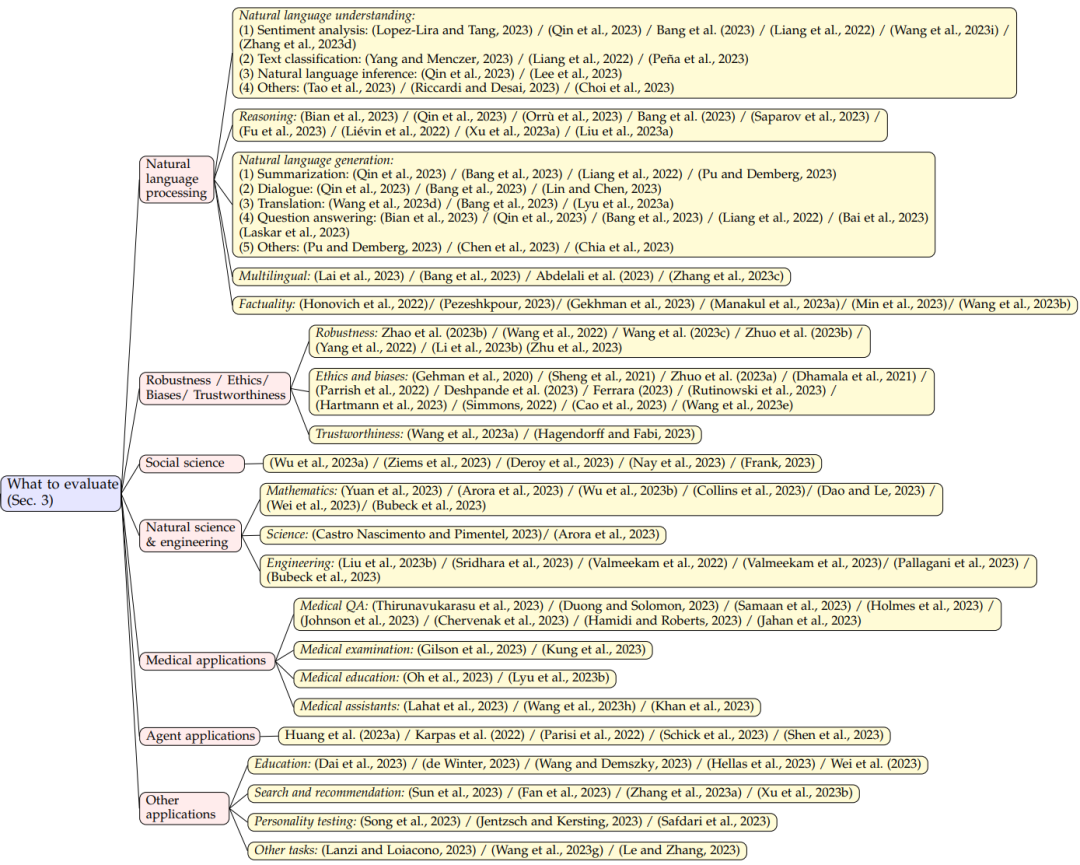
图注:评测内容
LLM 评估数据集的作用是测试和比较不同语言模型在各种任务上的性能。GLUE 和 SuperGLUE 等数据集的目标是模拟真实世界的语言处理场景,其中涵盖多种不同任务,如文本分类、机器翻译、阅读理解和对话生成。
随着 LLMs 基准测试的不断发展,目前已有许多受欢迎的评测基准。论文一共列出了19个流行的基准测试,每个都侧重于不同的方面和评估标准,为其各自的领域做出了贡献。
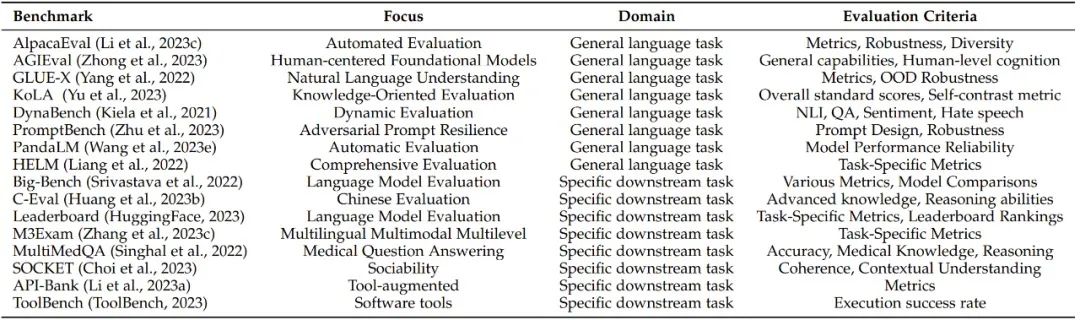
图注:LLM 评估基准概况
为了更好地总结,研究员将这些基准测试分为两类:通用基准(General benchmarks)和具体基准(Specific benchmarks),其中不乏一些深具盛名的大模型基准,比如来自LMSYS Org的Chatbot Arena。
Chatbot Arena,被行业人士普遍认为是最具公平性与广泛接受度的平台。LMSYS Org,是一个开放的研究组织,由加州大学伯克利分校、加州大学圣地亚哥分校和卡内基梅隆大学合作创立。该评测方式的设计灵感来源于国际象棋等竞技游戏中盛行的ElO评分系统。通过积累大量的用户投票,它能够更为贴近实际场景地评估各模型的综合表现。
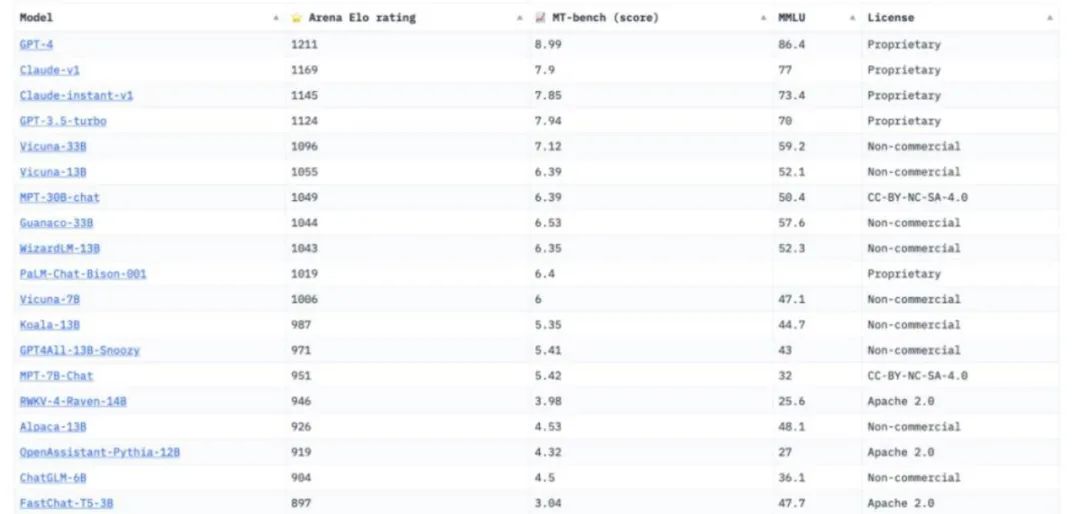
图注:Chatbot Arena
论文中提到了通用基准C-Eval,这是一个全面的中文基础模型评估套件。它包含了13948个多项选择题,涵盖了52个不同的学科和四个难度级别,该项目由上海交通大学、清华大学、爱丁堡大学共同完成。
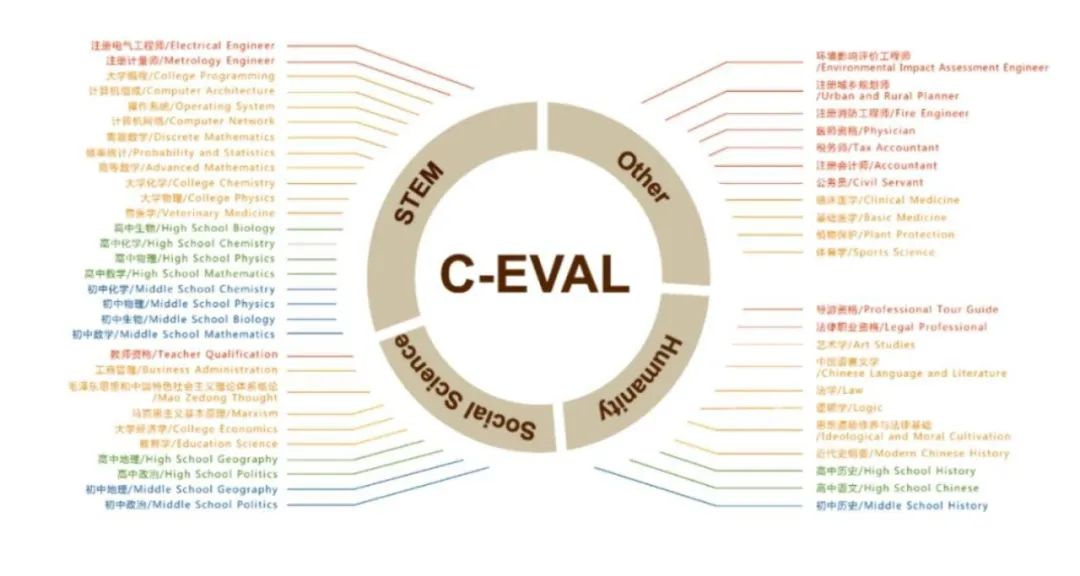
图注:通用基准C-Eval
除了通用任务的基准测试外,还存在一些专为某些下游任务设计的具体基准测试。譬如,MultiMedQA是一个医学问答基准测试,重点关注医学检查、医学研究和消费者健康问题。
文章介绍了两种常用的评测方法:自动评测和人工评测。
自动评测:基于计算机算法和自动生成的指标,能够快速且高效地评测模型的性能。
人工评测:侧重于人类专家的主观判断和质量评测,能够提供更深入、细致的分析和意见。
现有的协议不足以透彻地评估 LLM,还有许多挑战有待攻克,论文对大模型评测介绍了以下7个重大挑战。
设计 AGI 基准测试。什么是可靠、可信任、可计算的能正确衡量 AGI 任务的评测指标?
对完整行为进行评估。除去标准任务之外,如何衡量 AGI 在其他任务,如机器人交互中的表现?
稳健性评测。目前的大模型对输入的 prompt 非常不鲁棒,如何构建更好的鲁棒性评测准则?
动态演化评测。大模型的能力在不断进化、也存在记忆训练数据的问题。如何设计更动态更进化式的评测方法?
有原则且值得信任的评测。如何保证所设计的评测准则是可信任的?
支持所有 LLM 任务的统一评测。大模型的评测并不是终点、如何将评测方案与大模型有关的下游任务进行融合?
超越评估:LLM 强化。评测出大模型的优缺点之后,如何开发新的算法来增强其在某方面的表现?
论文总结了 LLMs 在不同任务中的成功和失败案例。
LLM 在生成文本方面展现出熟练度,能生成流畅和精确的语言表达。
LLM 能出色地应对涉及语言理解的任务,比如情感分析和文本分类。
LLM 具备强大的语境理解能力,能够生成与输入一致的连贯回答。
LLM 在多种自然语言处理任务上的表现都值得称赞,包括机器翻译、文本生成和问答。
LLM 可能会在生成过程中展现出偏见和不准确的问题,从而得到带偏见的输出。
LLM 在理解复杂逻辑和推理任务方面的能力有限,经常在复杂的上下文中发生混淆或犯错。
LLM 处理大范围数据集和长时记忆的能力有限,这可能使其难以应对很长的文本和涉及长期依赖的任务。
LLM 整合实时和动态信息的能力有限,这让它们不太适合用于需要最新知识或快速适应变化环境的任务。
LLM 对 prompt 很敏感,尤其是对抗性 prompt,这会激励研究者开发新的评估方法和算法,以提升 LLM 的稳健性。
在文本摘要领域,可以观察到 LLMs 可能在特定的评测指标上表现出低于标准的性能,这可能归因于那些特定指标的内在限制或不足。
LLMs 在反事实任务中 的表现不令人满意。
参考:
https://www.zhihu.com/question/601328258/answer/3128340188