
基于分割的包围盒生成用于全方位行人检测


摘要
由于行人在全向图像中的出现可能会旋转到任意角度,普通行人检测器的性能可能会大幅下降。现有的方法通过在推理过程中转换图像或用全方位图像训练检测器来缓解这个问题。但是,第一种方法大大降低了推理速度,第二种方法需要费力的注释。为了克服这些缺点,作者利用现有的大型数据集(可以利用其分段注释)来生成紧密匹配的边框注释。作者还提出了一种伪鱼眼失真增强方法,进一步提高了性能。大量的分析表明,作者的检测器成功地将边界框适合于行人,并显示出显著的性能改进。

作者将本文的贡献总结如下:
作者提出从现有的分割注释中生成紧密匹配的边界框,用于全方位的行人检测。
作者提出了一种新的数据增强方法,使透视图像能够模仿全向图像。
作者在公开可用的基准数据集上进行了大量的实验,并证明了所提出的方法的显著性能改进。

框架结构

提出的方法的总体架构
训练时将视角图像输入到检测器网络,评估时输入全向图像。

实验结果
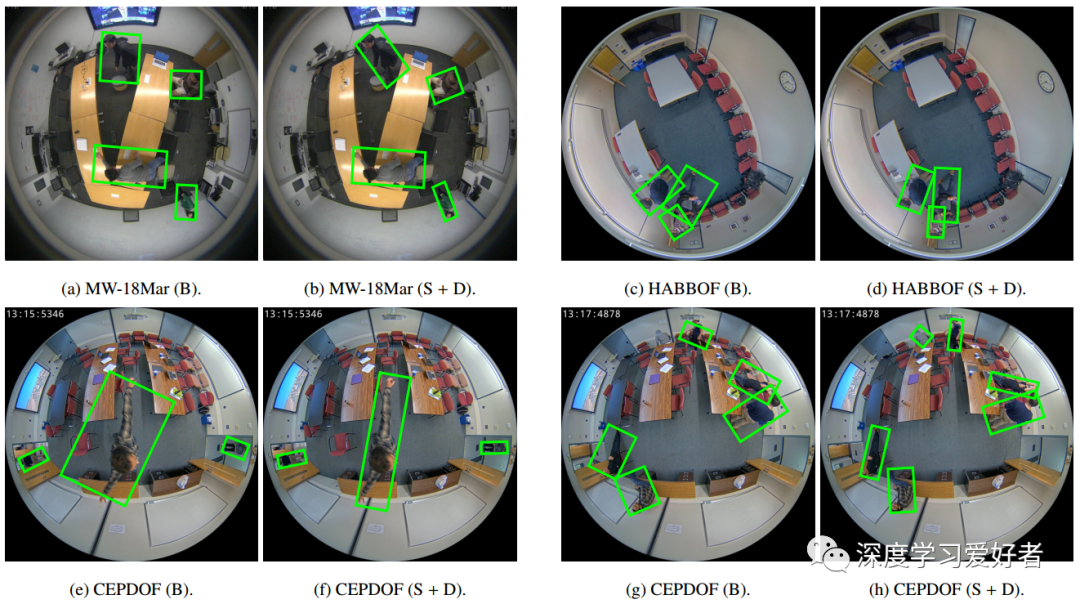
基线方法和提出的方法对每个数据集的检测结果示例
每个区块的左右图像分别显示了基线法和提出的基于伪鱼眼失真分割方法的结果。
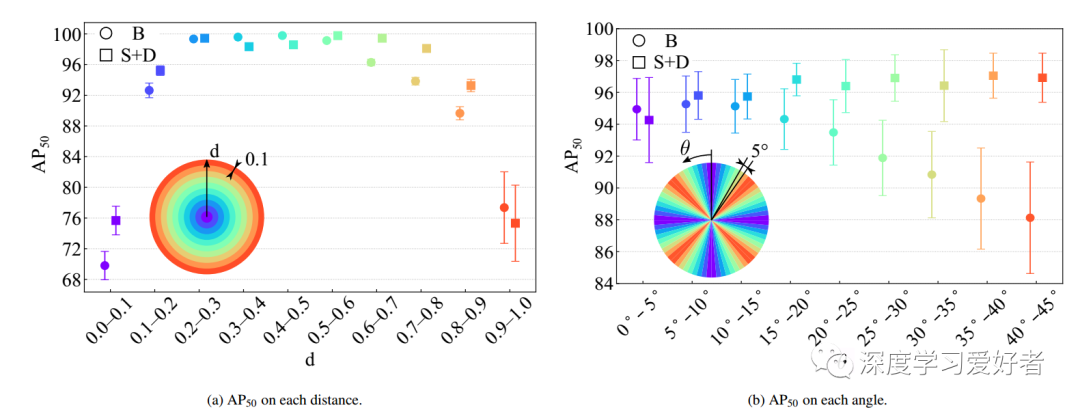
MW-18Mar数据集每个位置的AP50
每个图表中的柱形表示标准误差。标记的颜色表示每个圆圈中的位置。(B:用COCO的原始包围盒训练,s + D:用分割注释生成的包围盒训练,添加伪鱼眼失真。)
 结论
结论
本文提出了一种基于分割的包围盒生成方法,在不使用全向图像进行训练的情况下提高全向行人检测器的性能。这种方法使检测器能够紧密地将盒子放入行人中,因此优于传统方法,特别是对于高欠条阈值的AP。作者还提出了一种伪鱼眼失真增强算法来进一步提高性能。该方法使透视图像能够模仿全向图像,从而提高了对全向图像失真的鲁棒性。实验结果表明,该检测器成功地将盒子匹配到行人身上,并取得了显著的性能改善。
论文链接:https://arxiv.org/pdf/2104.13764.pdf
双一流高校研究生团队创建 ↓
专注于计算机视觉原创并分享相关知识 ☞
整理不易,点赞三连!