
基于OpenCV的行人目标检测
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
推荐阅读

转自|深度学习与计算机视觉

介绍
什么是目标检测

目标检测方法
-
级联检测器:该模型有两种网络类型,一种是RPN网络,另一种是检测网络。一些典型的例子是RCNN系列。 -
带锚框的单级检测器:这类的检测器没有单独的RPN网络,而是依赖于预定义的锚框。YOLO系列就是这种检测器。 -
无锚框的单级检测器:这是一种解决目标检测问题的新方法,这种网络是端到端可微的,不依赖于感兴趣区域(ROI),塑造了新研究的思路。要了解更多,可以阅读CornerNet或CenterNet论文。
什么是COCO数据集
如何评估性能
-
PASCAL VOC挑战(Everingham等人。2010年) -
COCO目标检测挑战(Lin等人。2014年) -
开放图像挑战赛(Kuznetsova 2018)。
平均精度
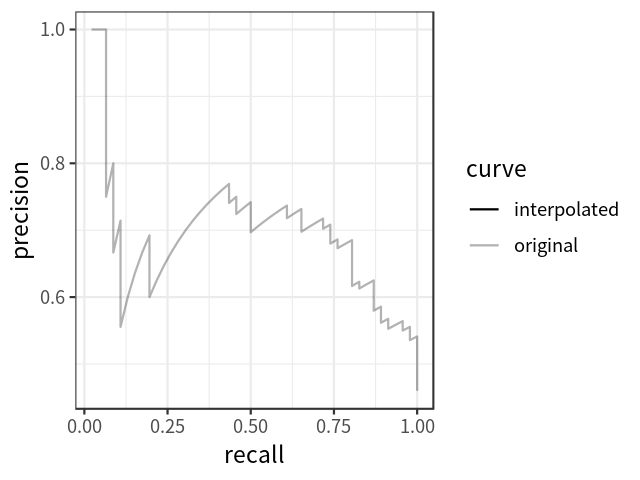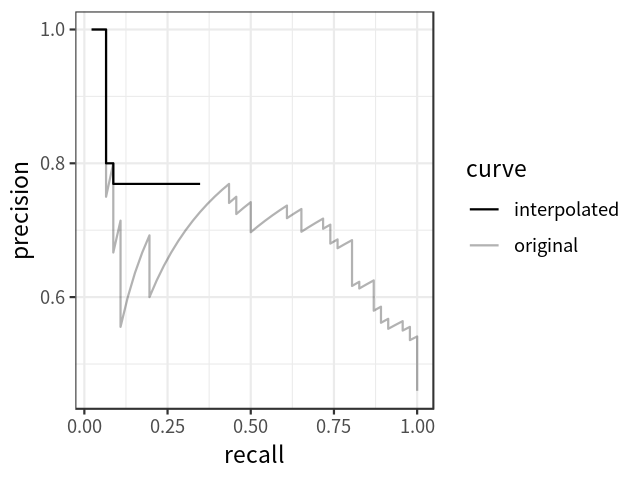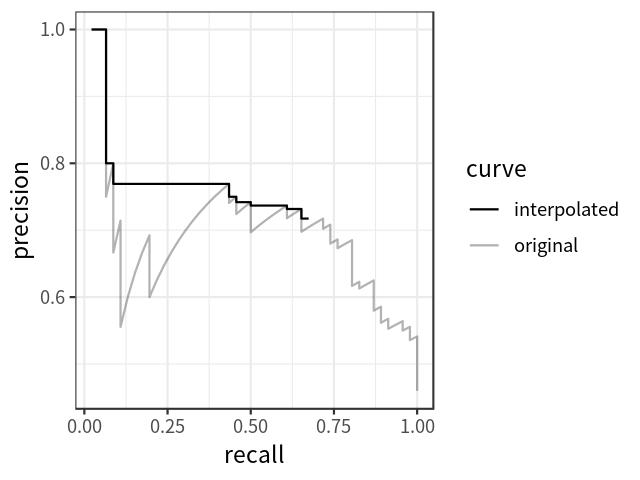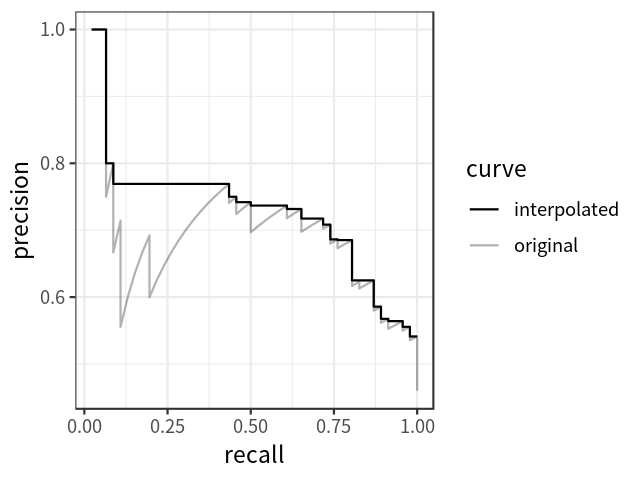

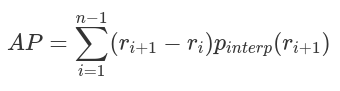
mAP
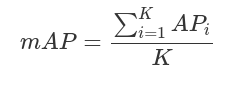
TIDE
实际问题陈述
挑战
-
视角:CCTV是顶装式的,与普通照片的前视图不同,它有一个角度 -
人群:商店/商店有时会有非常拥挤的场景 -
背景杂乱:零售店有更多的分散注意力或杂乱的东西(对于我们的模特来说),比如衣服、架子、人体模型等等,这些都会导致误报。 -
照明条件:店内照明条件与室外摄影不同 -
图像质量:来自CCTVs的视频帧有时会非常差,并且可能会出现运动模糊
测试集创建
第一个人体检测模型
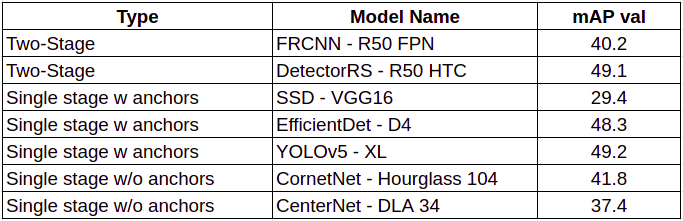
YOLOv5
性能
分析
结论
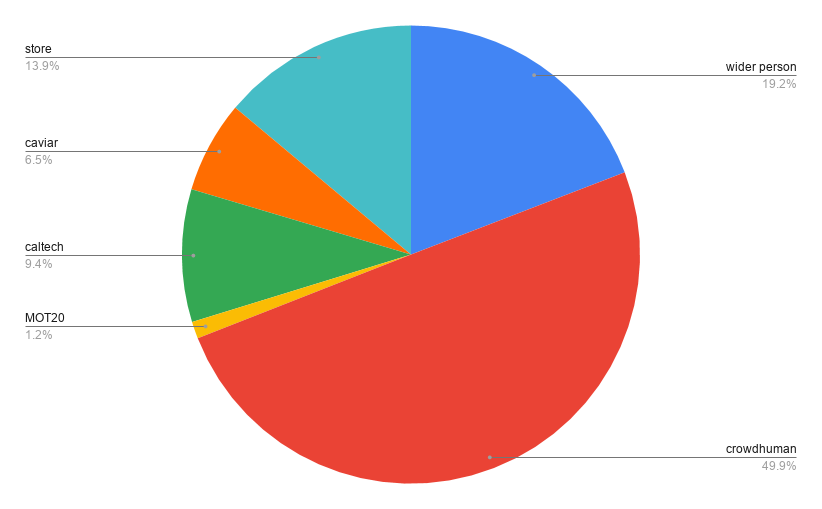
收集公共数据
第二个人体检测模型
训练迭代2:
-
主干网络:YOLOv5x -
模型初始化:COCO预训练的权重 -
epoch:10个epoch
性能
分析
结论
清理数据
-
错误标记的边界框 -
包含非常小的边界框或太多人群的图像 -
重复帧的附近
第三个人体检测模型
-
主干网络:YOLOv5x -
模型初始化:COCO预训练的权重 -
epoch:~100个epoch
性能
分析
结论
数据增强
-
视角 -
视角改变


-
照明条件 -
亮度 -
对比度

-
图像质量 -
噪音 -
图像压缩 -
运动模糊



第四个人体检测模型
性能
分析
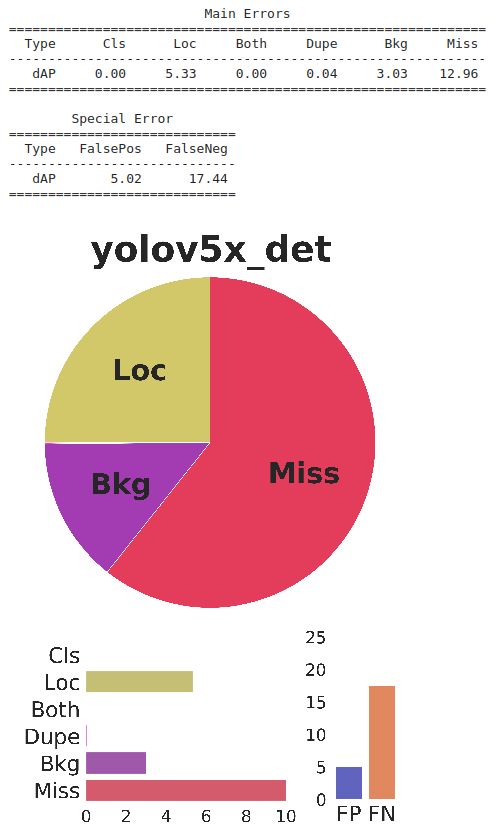
结论
创建自定义批注
最终人体检测模型
性能
分析
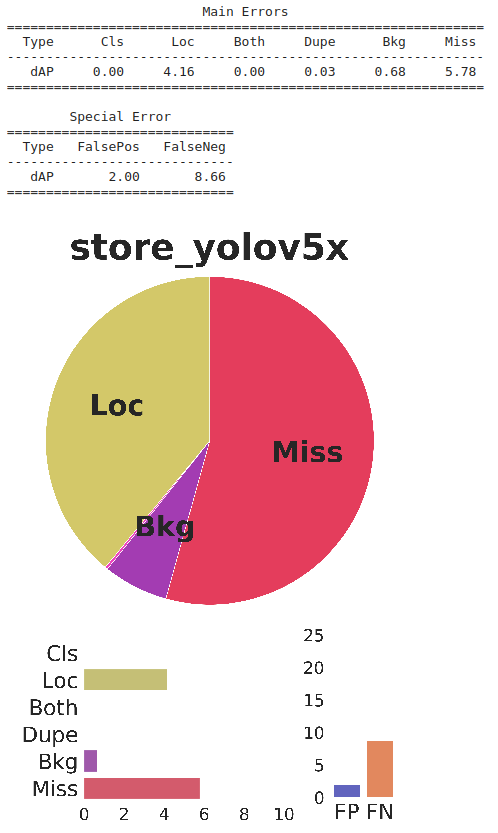
结论
总结
结论
参考文献
-
YOLO v5 by ultralytics, https://github.com/ultralytics/yolov5 -
Cross Stage Partial Network (CSPNet), https://arxiv.org/abs/1911.11929 -
A General Toolbox for Identifying Object Detection Errors, https://github.com/dbolya/tide -
https://blog.zenggyu.com/en/post/2018-12-16/an-introduction-to-evaluation-metrics-for-object-detection/ -
Python library for fast and flexible image augmentations(https://albumentations.ai/#).
数据集
-
WiderPerson, https://wider-challenge.org/2019.html -
CAVIAR, http://groups.inf.ed.ac.uk/vision/CAVIAR/CAVIARDATA1/ -
CALTECH Pedestrian dataset, http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论