
特征蒸馏:为对比学习正名!效果堪比图像掩码方法!
共 3863字,需浏览 8分钟
·
2022-07-13 09:33
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
基于图像掩码(MIM,Masked image modeling)的自监督方法让ViT实现了更好的微调性能,比如基于MAE预训练的ViT-B可以在ImageNet-1K数据集达到83.6%准确度,这要超过之前基于对比学习的模型,如基于DINO的ViT-B只能达到82.8%。近日微软AI(SwinTransformer原团队)在论文Contrastive Learning Rivals Masked Image Modeling in Fine-tuning via Feature Distillation提出了一种简单的后处理方法来优化对比学习得到的预训练模型:通过简单的特征蒸馏(FD,feature distillation)来将原来的模型转换成和MIM有相似性质的新模型。对对比学习的模型进行特征蒸馏其在ImageNet-1K数据集上的微调性能可以和基于MIM的模型不相上下。这种特征蒸馏优化方法具有普适性,不仅可以优化对比学习模型,也可以用于有监督模型,MIM模型以及基于图像-文本对比学习的CLIP模型。对CLIP ViT-L模型进行特征蒸馏,其可以在ImageNet-1K数据集上达到89.0%,这是目前ViT-L所能实现的SOTA,而对30亿参数的SwinV2-G模型进行特征蒸馏,可以在ADE20K语义分割数据集上达到新的SOTA:61.4 mIoU。
特征蒸馏
论文提出的特征蒸馏方法非常简单,其整体架构如下所示,这里预训练的模型作为teacher模型,而要转换的新模型为student模型。这里的特征蒸馏主要有以下4个要点: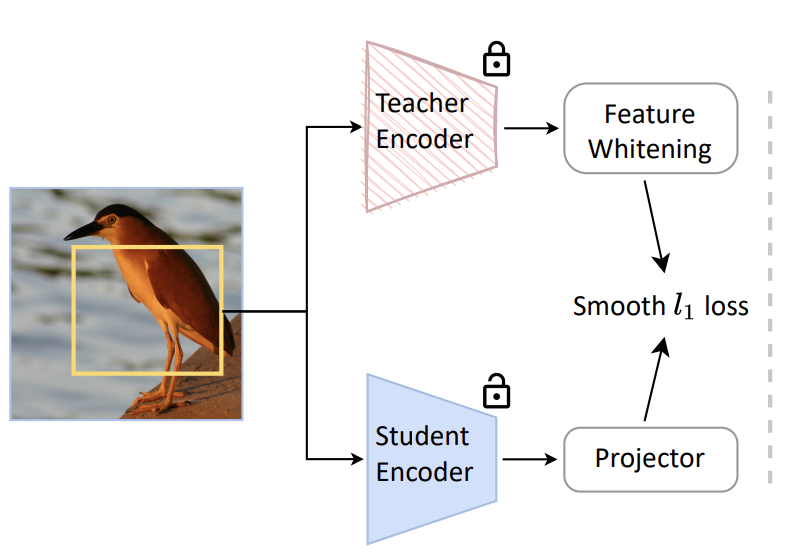 (1)蒸馏的目标采用特征图
(1)蒸馏的目标采用特征图
常规的知识蒸馏常常采用logits作为蒸馏目标,而这里的特征蒸馏采用模型输出的特征图作为目标,这也适用于那些没有logits输出的模型如CLIP。为了让teacher和student输出的特征图一致,teacher和student模型的输入是原始图像的同一数据增强视野(这里只采用RandomResizeAndCrop 0.08-1数据增强)。同时在student模型上加了一个projector,采用一个1x1卷积层,这其实也让特征蒸馏变得具有普适性,比如teacher模型和student模型的输出特征图的维度不一致。采用特征图作为蒸馏目标,比采用logits或者GAP特征(全局池化后特征)在效果上也更好,ViT-B的对比结果如下所示: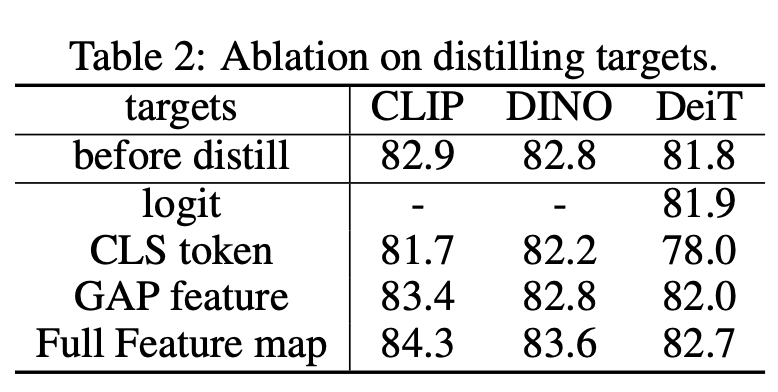 (2)对teacher的特征进行白化(whiten)
(2)对teacher的特征进行白化(whiten)
不同的预训练模型输出的特征的数量级不同,这样不同的模型其蒸馏训练的超参数都需要调整。这里对teacher输出的特征进行白化处理来将特征归一化同一量级,在实现上采用非训练的LayerNorm(去掉训练的weight和bias)。这里的损失函数采用smooth L1 loss,如下所示:
这里默认设置为2.0,和分别是student和teacher模型输出的特征图,代表的是projector,即1x1卷积。对特征进行白化处理,相比不处理或者L2 norm效果更好: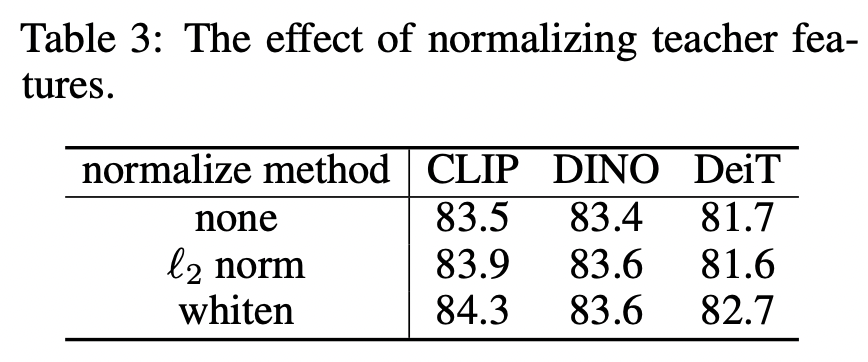 (3)采用共享的相对位置编码
(3)采用共享的相对位置编码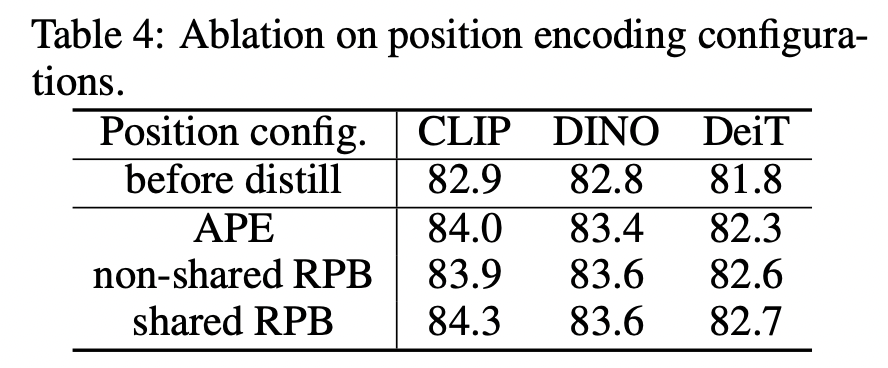 在做特征可视化后,发现共享RPB的蒸馏模型其不同heads的attention distances更发散,从而能得到更好的微调性能。(4)采用非对称的drop path rates这里teacher模型drop path rate设置为0,即不采用drop path,而student模型在{0.1, 0.2, 0.3, 0.4}中选择最优的drop path rate,此时效果是最好的。
在做特征可视化后,发现共享RPB的蒸馏模型其不同heads的attention distances更发散,从而能得到更好的微调性能。(4)采用非对称的drop path rates这里teacher模型drop path rate设置为0,即不采用drop path,而student模型在{0.1, 0.2, 0.3, 0.4}中选择最优的drop path rate,此时效果是最好的。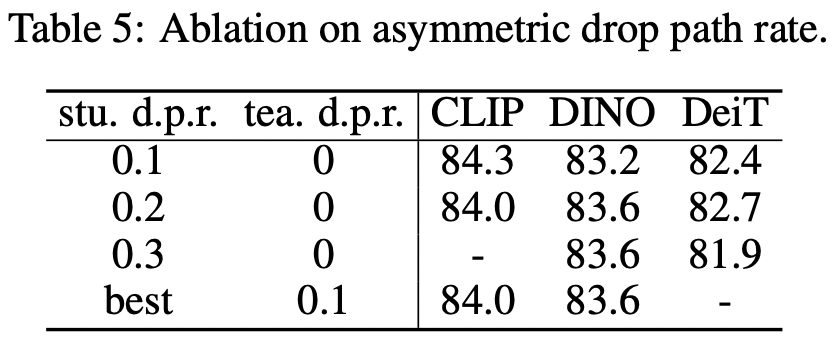
论文共选择了5种不同的预训练策略:DINO,EsViT,CLIP, DeiT和MAE,其中DINO,EsViT和DeiT采用ViT-B和Swin-B进行实验,而CLIP选择ViT-B和ViT-L进行实验。特征蒸馏在ImageNet-1K训练集上进行,训练epochs为300。下表对比了不同的预训练模型在特征蒸馏后在ImageNet-1K数据集上微调和linear probe,以及在ADE20K数据集上迁移的效果。可以看到DINO,EsViT,CLIP, DeiT方法预训练的模型经过特征蒸馏后均可以在ImageNet-1K数据集上微调效果上提升1~2%,也可以在ADE20K数据集上提升1~3.3 mIoU。这也使得对比学习的预训练模型效果和基于MIM的预训练模型(如MAE和BEiT)效果相当了。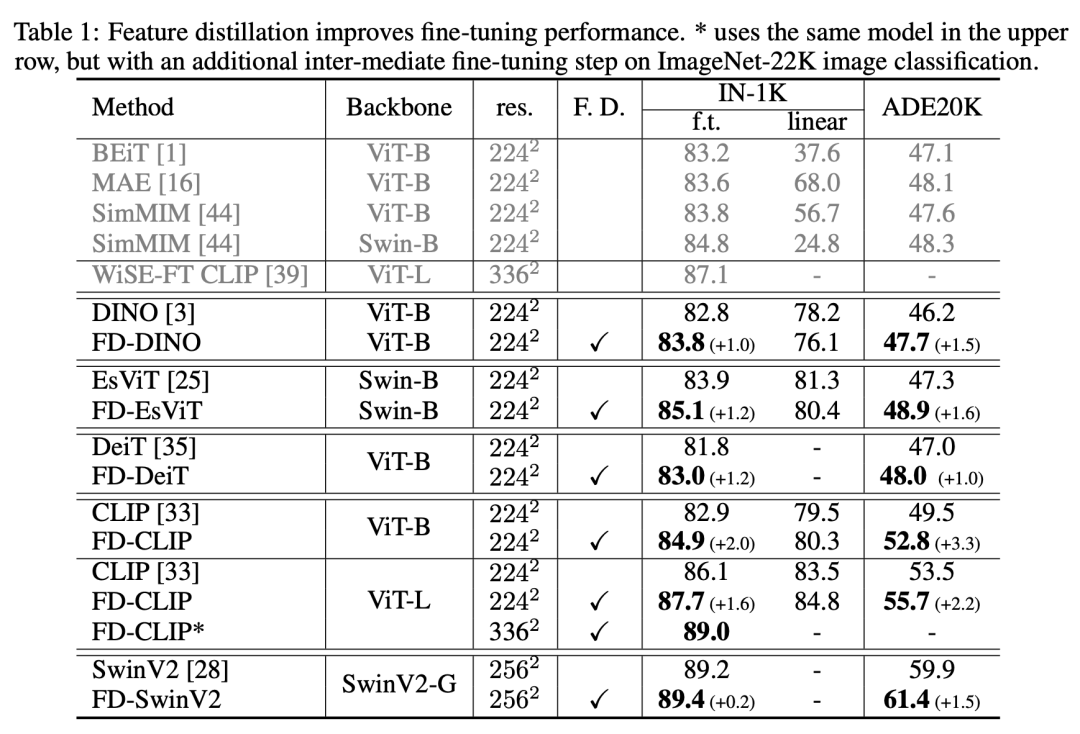
特征可视化
为了进一步研究为什么特征蒸馏会起作用,论文对特征蒸馏前后的模型做了特征可视化分析,主要包括以下几个部分:
(1)average attention distance per head
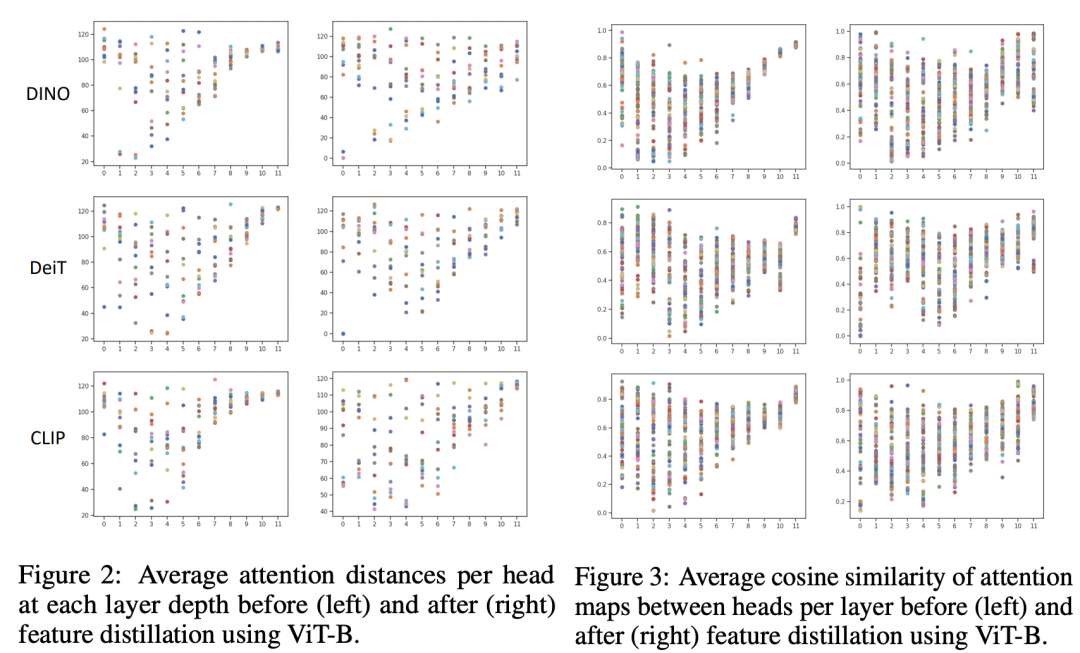
首先可视化了各个不同layer的各个head的average attention distance,average attention distance反应的是attention head的感受野大小。如下左图所示,可以看到对于特征蒸馏前的模型,其在深层的attention heads表现出了相似的感受野,这说明了不同的attention heads学习到了相似的模式,这是可能对模型容量的浪费;而经过特征蒸馏后,深层的attention heads的感受野相对发散一些,这也意味着模型的表达力可能更好。我们同样也可以从右图中的各个heads的average cosine similarity看出来差异(特征蒸馏后,深层的余弦相似度差异变得更大)。
 (2)attention 模式的改变
(2)attention 模式的改变
第二个分析是对attention map可视化,这里不同layer的average attention maps(不同heads平均)如下所示,这里attention map主要有两种模式:diagonal模式和column模式,其中diagonal模式说明模型学习到了不同patchs间的一些固定的相对位置,而column模式说明模型学习到的是patchs的固定位置。当然diagonal模式要比column模式更好,我们也可以看到特征蒸馏后,模型的diagonal模式要更加突出,其中共享的RPB也是其中的一部分原因。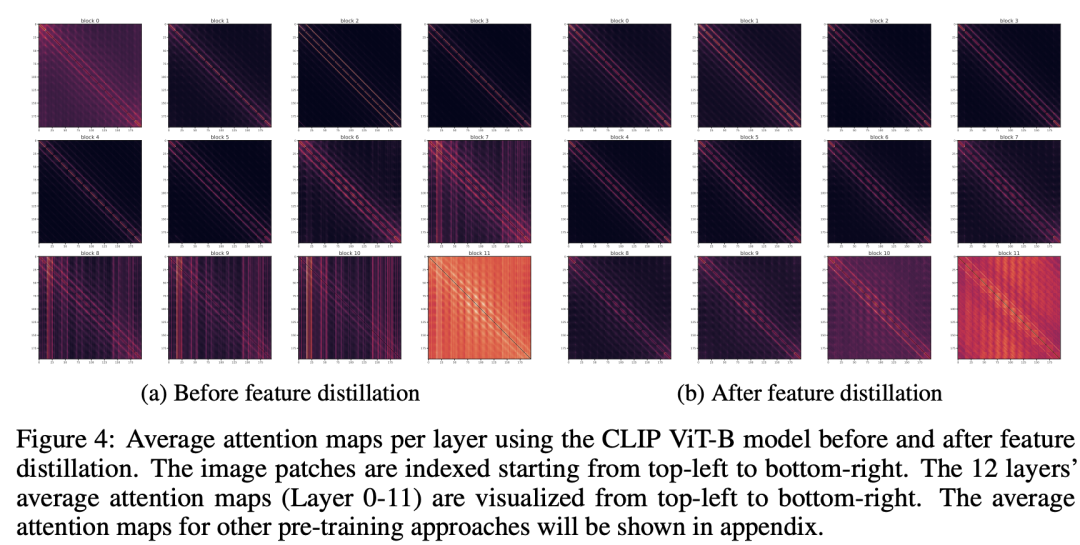 (3)loss / accuracy landscapes
(3)loss / accuracy landscapes
最后论文也分析了loss / accuracy landscapes,如下图所示,我们可以看到特征蒸馏后模型的loss / accuracy landscapes变得更平坦,网络更容易进行优化。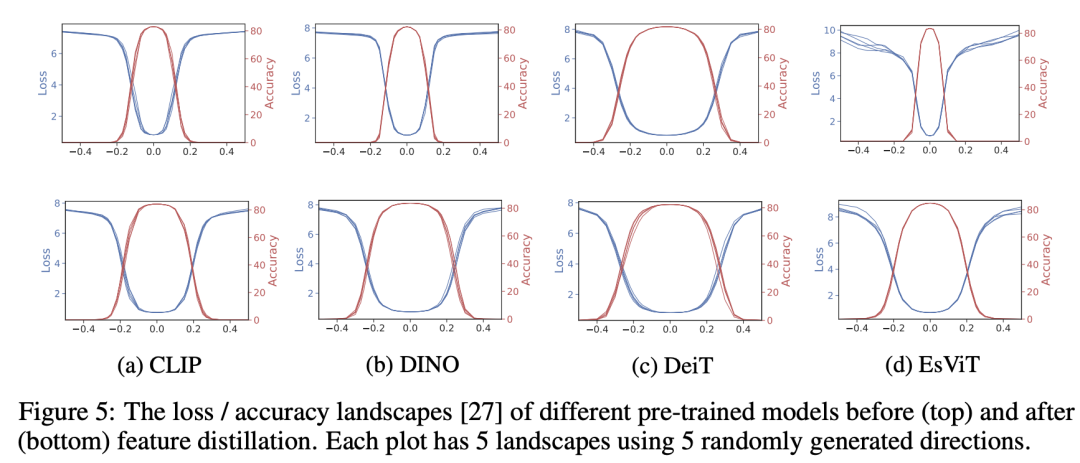
论文也对基于MAE的预训练模型进行了特征蒸馏,不过效果提升的不是特别明显(ViT-B从83.6% -> 83.8%)。如果同样进行特征可视化的话,可以看到MAE本身得到的模型其average attention distance就比较发散,同时loss / accuracy landscapes也比较平坦,特征蒸馏后变化不是特别大。这其实也侧面反映了通过对对比学习得到的模型进行特征蒸馏可以转换为和MIM预训练模型具有相似性质的新模型,从而提升其微调效果。 在论文的最后,作者认为一个好的预训练模型应该具有好的优化友好度(optimization friendliness),简单来说,就是一个好的预训练模型来进行初始化,它应该比较容易进行微调(比如有平坦的loss landscape)。而特征蒸馏则是增加了预训练模型的优化友好度。
在论文的最后,作者认为一个好的预训练模型应该具有好的优化友好度(optimization friendliness),简单来说,就是一个好的预训练模型来进行初始化,它应该比较容易进行微调(比如有平坦的loss landscape)。而特征蒸馏则是增加了预训练模型的优化友好度。
小结
同样架构的模型,其最终的性能也要取决于优化策略。无论是有监督,还是基于MIM的自监督,甚或是基于对比学习的自监督,我们如果能找到好的优化技巧,它们应该可以得到相似的性能:DeiT III证明了有监督,而这个工作证明了对比学习自监督。
参考
Contrastive Learning Rivals Masked Image Modeling in Fine-tuning via Feature Distillation https://github.com/SwinTransformer/Feature-Distillation
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
