
基于DnCNN的图像和视频去噪
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

随着数字图像数量的增加,对高质量的图像需求也在增加。然而,现代相机拍摄的图像会因噪声而退化。图像中的噪声是图像中颜色信息的失真,噪声是指数字失真。当在夜间拍摄时,图像变得更嘈杂。该案例研究试图建立一个预测模型,该模型将带噪图像作为输入并输出去噪后的图像。
这个问题是基于计算机视觉的,CNN等深度学习技术的进步已经能够在图像去噪方面提供最先进的性能,用于执行图像去噪的模型是DnCNN(去噪卷积神经网络)。
BSD300和BSD500数据集均用作训练数据,BSD68用于验证数据。由于数据有限,每个图像使用了4次,即缩放到[1.0,0.7,0.8,0.7]。
每个缩放图像被分割成50x50的块,步幅为20。每个贴片都添加了一个标准偏差在[1,55]之间的高斯噪声。数据生成代码如下所示:
#Fix Noisestddevs = np.random.uniform(1, 55.0, 125000)[:, np.newaxis, np.newaxis, np.newaxis]noise = np.random.normal(loc = 0, scale=stddevs, size=(125000, 50, 50, 3)).astype(np.float16)def get_dataset(img_path):def image_generator():patch_size = 50stride = 20index = 0for scale in [1, 0.9, 0.8, 0.7]:for path in img_path:true_img = cv2.imread(path)for i in range(0, true_img.shape[0] - patch_size + 1, stride):for j in range(0, true_img.shape[1] - patch_size + 1, stride):Y = true_img[i:i+patch_size, j:j+patch_size]gauss_noise = noise[index].astype(np.float32)X = np.clip(Y + gauss_noise, 0, 255.0)index = (index + 1)%125000yield (X/255.0,),Y/255.0return tf.data.Dataset.from_generator(image_generator, output_signature=((tf.TensorSpec(shape=(None, None, 3)),),(tf.TensorSpec(shape=(None, None, 3)))))
DnCNN中有三种类型的层:
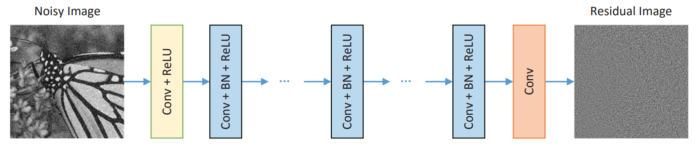
Conv+ReLU:过滤器大小为3,过滤器数量为64,跨步为1,使用零填充保持卷积后的输出形状,使用ReLU作为激活函数。输出为形状(批量大小,50、50、64)
Conv+批量归一化+ReLU:过滤器大小为3,过滤器数量为64,步长为1,使用零填充保持卷积后的输出形状,使用批量归一化层更好地收敛,ReLU作为激活函数。输出为形状(批次大小,50、50、64)。
Conv:滤镜大小为3,跨步为1,滤镜数量为c(彩色图像为3个,灰度图像为1个),使用零填充在卷积后保持输出形状。输出形状为(批次大小,50,50,c)。
DnCNN模型的输出为残差图像。因此,原始图像=噪声图像-残差图像。
在DnCNN中,在每层卷积之前填充零,以确保中间层的每个特征贴图与输入图像具有相同的大小。根据本文,简单的零填充策略不会导致任何边界伪影。
本文建议深度为17,但本案例研究适用于深度为12和深度为8。
评估指标是PSNR(峰值信噪比)分数。它只是一个数值,表示构造的去噪图像与原始图像相比有多好。
def get_model(depth, channels):noise_inp = tf.keras.layers.Input(shape = (50, 50, channels), dtype=tf.float32)init = 'Orthogonal'y = tf.keras.layers.Conv2D(filters = 64, kernel_size = 3, padding = 'same', kernel_initializer=init,use_bias=True)(noise_inp)y = tf.keras.layers.ReLU()(y)for i in range(1, depth-1):y = tf.keras.layers.Conv2D(filters = 64, kernel_size = 3, padding = 'same', kernel_initializer=init,use_bias=True)(y)bn = tf.keras.layers.BatchNormalization(axis=-1, epsilon=1e-5, momentum=0.9)y = bn(y)y = tf.keras.layers.ReLU()(y)residual = tf.keras.layers.Conv2D(filters = channels, kernel_size = 3, padding = 'same', kernel_initializer=init,use_bias=True)(y)true_img = tf.keras.layers.Subtract()([noise_inp, residual])model = tf.keras.Model(inputs = [noise_inp], outputs=[true_img])model.compile(optimizer=tf.keras.optimizers.Adam(), loss='mse')return modeldef lr_decay(epoch):lr = 1e-3if epoch+1 > 20:lr/=30elif epoch+1 > 10:lr /= 10return lrmodel = get_model(8, 3)lr_callback = tf.keras.callbacks.LearningRateScheduler(lr_decay)dataset = get_dataset(bsd500).shuffle(1000).batch(128).prefetch(tf.data.experimental.AUTOTUNE).repeat(None)model.compile(optimizer=tf.keras.optimizers.Adam(), loss='mse')history = model.fit(x = dataset, steps_per_epoch=2000, epochs=30, shuffle=True,verbose=1,callbacks=[lr_callback])
批量大小=128,每个历元的步数=2000,历元数=30。



BSD68数据集上的峰值信噪比对于标准差25为~28,对于标准差50为~25。
如果深度=12,则BSD68数据集上的峰值信噪比对于标准差25为28.30,对于标准差50为26.13。
我们可以将这个想法扩展到视频帧,每个帧作为输入传递给DnCNN模型,生成的帧传递给视频编写器。
import sysimport tensorflow as tfimport numpy as npimport cv2import timeimport matplotlib.pyplot as pltimport osimport globimport seaborn as snbimport refrom skvideo.io import FFmpegWriterclass Denoiser:def __init__(self, merge_outputs):self.model = tf.keras.models.load_model('./model')self.merge_outputs = merge_outputsdef get_patches(self, frame):patches = np.zeros(shape=(self.batch_size, 50, 50, 3))counter = 0for i in range(0, self.SCALE_H, 50):for j in range(0, self.SCALE_W, 50):patches[counter] = frame[i:i+50, j:j+50]counter+=1return patches.astype(np.float32)def reconstruct_from_patches(self, patches, h, w, true_h, true_w, patch_size):img = np.zeros((h,w, patches[0].shape[-1]))counter = 0for i in range(0,h-patch_size+1,patch_size):for j in range(0,w-patch_size+1,patch_size):img[i:i+patch_size, j:j+patch_size, :] = patches[counter]counter+=1return cv2.resize(img, (true_w, true_h), cv2.INTER_CUBIC)def denoise_video(self, PATH):self.cap = cv2.VideoCapture(PATH)self.H, self.W = int(self.cap.get(4)), int(self.cap.get(3))self.SCALE_H, self.SCALE_W = (self.H//50 * 50), (self.W//50 * 50)self.batch_size = ((self.SCALE_H * self.SCALE_W) // (50**2))outputFile = './denoise.mp4'writer = FFmpegWriter(outputFile,outputdict={'-vcodec':'libx264','-crf':'0','-preset':'veryslow'})while True:success, img = self.cap.read()if not success:breakresize_img = cv2.resize(img, (self.SCALE_W, self.SCALE_H), cv2.INTER_CUBIC).astype(np.float32)noise_img = resize_img/255.0patches = self.get_patches(noise_img).astype(np.float32)predictions = np.clip(self.model(patches), 0, 1)pred_img = (self.reconstruct_from_patches(predictions, self.SCALE_H,self.SCALE_W, self.H, self.W, 50)*255.0)if self.merge_outputs:merge = np.vstack([img[:self.H//2,:,:], pred_img[:self.H//2,:,:]])writer.writeFrame(merge[:,:,::-1])else:writer.writeFrame(pred_img[:,:,::-1])writer.close()PATH = sys.argv[1]print(f"Path is : {PATH}")denoise = Denoiser(merge_outputs = True)x = denoise.denoise_video(PATH)
参考
https://arxiv.org/pdf/1608.03981.pdf
https://www.appliedaicourse.com/
GITHUB代码链接:https://github.com/saproovarun/DnCNN-Keras
小白团队出品:零基础精通语义分割↓↓↓
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
