
大模型指令微调-技巧篇(NEFT)
作者:uuuuu
文章地址:https://zhuanlan.zhihu.com/p/661962656
写在前面
今天给大家分享一个新的技巧(20231010),一行代码可以大幅提升指令微调的效果,相关pr已经合到抱抱脸的repo了,又是一个简单但是带来巨大效果提升的策略,作者分析是能降低下游微调过程中的模型过拟合现象。
paper:https://arxiv.org/pdf/2310.05914.pdfgithub:https://github.com/neelsjain/NEFTune/tree/maintrl: https://github.com/huggingface/trl/commit/c4ed3274be9cfd5fb8d9316b2fa0eff534bf6bcb
效果提升非常恐怖,基于llama2 7b,使用alpaca微调,在AlpacaEval上可以从29.79%提升至64.69%。其他的很多指令微调数据集也有很大的提升,Evol-Instruct训练的模型提升了10%,ShareGPT提升了8%,OpenPlatypus提升了8%。即使是经过RLHF进一步调优的强大模型,如LLaMA-2-Chat,也受益于使用NEFTune进行额外训练。
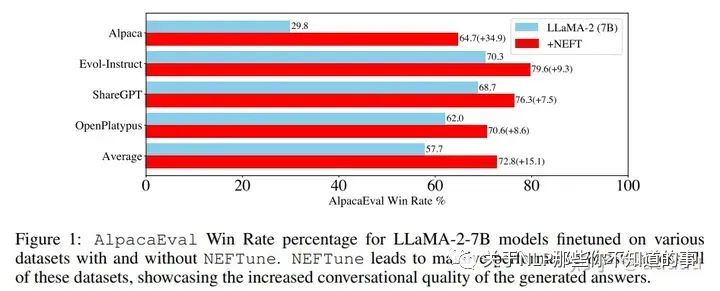
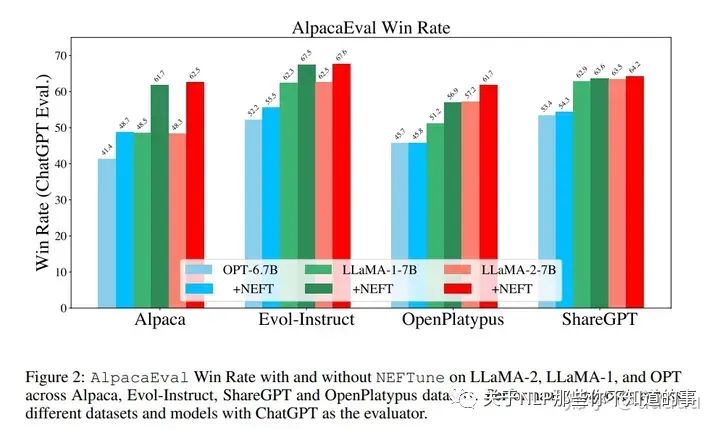
Noisy Embedding Instruction Finetuning (NEIF)

从原理的伪代码可以看出来与常规的微调相比,只是在embedding之后加了一个噪声。这个在bert之前,使用word2vec作为embedding的时候,印象中似乎也有这种做法。
噪声是从一个均匀分布中,采样独立同分布在[-1, 1]范围内的值,然后进行
的缩放。其中L为输入长度,d为embedding维度,α为可调节参数。
整个策略就这样,虽然很简单,但是有效不就完了,然后看看抱抱脸的实现,最后提供一些作者的分析
def neftune_forward(self, input: torch.Tensor):"""Implements the NEFTune forward pass for the model. Note this works only fortorch.nn.Embedding layers. This method is slightly adapted from the original source codethat can be found here: https://github.com/neelsjain/NEFTuneArgs:input (`torch.Tensor`):The input tensor to the model.noise_alpha (`float`):The noise alpha value to use for the NEFTune forward pass."""embeddings = torch.nn.functional.embedding(input, self.weight, self.padding_idx, self.max_norm, self.norm_type, self.scale_grad_by_freq, self.sparse)if self.training:dims = torch.tensor(embeddings.size(1) * embeddings.size(2))mag_norm = self.neftune_noise_alpha / torch.sqrt(dims)embeddings = embeddings + torch.zeros_like(embeddings).uniform_(-mag_norm, mag_norm)return embeddings
如果你有用trl来训练模型,那用起来很容易了,就是SFTTrainer加个neftune_noise_alpha的参数即可,否则你可以参照着修改一下,改动比较小。整个过程只在训练阶段生效,不影响推理阶段,所以也算是免费的午餐了?
一些分析
假设通过在训练时向嵌入中添加噪声,模型对指令微调数据集的特定细节(例如格式细节、确切措辞和文本长度)的过拟合程度会降低。模型不再完全收敛到精准的微调指令分布,而是更能够提供融入预训练基础模型知识和行为的答案。通过结果观察到的一个非常明显的副作用是,模型生成更连贯、更长的结果。在大多数数据集上,人工评测和机器评测都更喜欢更长、更冗长的答案(Dubois等人,2023年)。但我们发现,增加的冗长性仅仅是对指令分布过拟合减少的可见副作用之一;增加的冗长性本身无法解释性能上的提升。
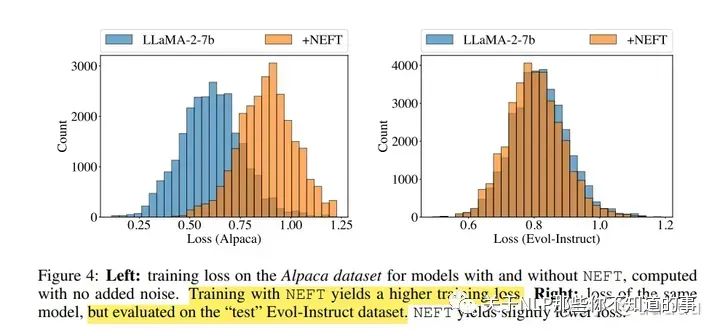
作者做了一个实验,在llama2 7b上使用/不适用neft,如上图,NEFTune模型的训练损失明显较高,但测试损失稍低,相比于没有使用NEFTune的基础模型。这表明使用NEFTune时过拟合较少,泛化能力更好。
作者发现在一些榜单评测上,跟答案的长度有强相关性。所以第二个实验想看下neft答案的长度变长,是否会牺牲文本的多样性。所以计算使用不同微调数据集进行训练的LLaMA-2模型在有和没有NEFT的情况下的n-gram重复率。在长的段落中,n-gram会更频繁地重复出现,所以控制段落的长度。在每个样本的开头计算重复率和多样性得分,使用固定长度的片段。对于使用Alpaca进行训练的模型,固定长度为50;对于使用Evol-Instruct进行训练的模型,固定长度为100;对于使用ShareGPT训练的模型和使用OpenPlatypus训练的模型,固定长度均为150。这些片段长度选取是,以确保至少一半的生成文本长度超过截断长度,并且长度不足的序列将被丢弃。
结果如下:
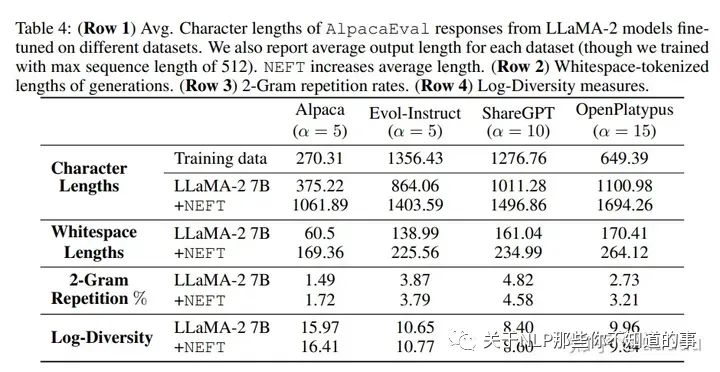
从上表前2行可以看到,neft的答案更长,但是后面2行用来评估多样性的指标基本差不多,然后作者得到新的结论,更长的回答并没有以多样性为代价,而是提供了额外的答案细节。
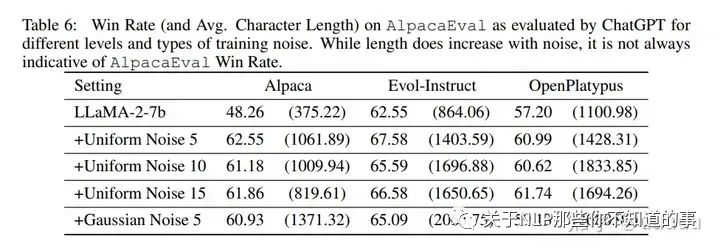
下面是对NEFT算法中使用均匀噪声和高斯噪声进行了剔除实验,并发现高斯噪声会导致更长的输出,但并不带来性能改善 ,以及超参数 alpha,变化不明显
除此之外,作者在附录还贴了很多额外的实验,感兴趣的可以看原文。