
实战 | 手把手教你如何使用抓包神器 MitmProxy
大家好,我是安果!
今天教大家如何使用 MitmProxy 这款抓包工具
玩爬虫的小伙伴都知道,抓包工具除了MitmProxy 外,还有 Fiddler、Charles以及浏览器 netwrok 等
既然都有这么多抓包工具了,为什么还要会用 MitmProxy 呢??今天教大家使用 MitmProxy 抓包工具的原因,主要有以下几点:
不需要安装软件,直接在线(浏览器)进行抓包(包括手机端和 PC 端)
配合 Python 脚本抓包改包
抓包过程的所有数据包都可以自动保留到txt里面,方便过滤分析
使用相对简单,易上手
1
配置 MitmProxy
MitmProxy可以说是客户端,也可以说是一个 python 库
方式一:客户端
https://mitmproxy.org/downloads/在这个地址下可以下载对应的客户端安装即可
方式二:Python库
pip install mitmproxy通过这个 pip 命令可以下载好 MitmProxy,下面将会以 Python 库的使用方式给大家讲解如何使用(推荐方式二)
2
启动 MitmProxy
MitmProxy 启动有三个命令(三种模式)
mitmproxy,提供命令行界面
mitmdump,提供一个简单的终端输出(还可以配合Python抓包改包)
mitmweb,提供在线浏览器抓包界面
mitmdump启动
mitmdump -w d://lyc.txt
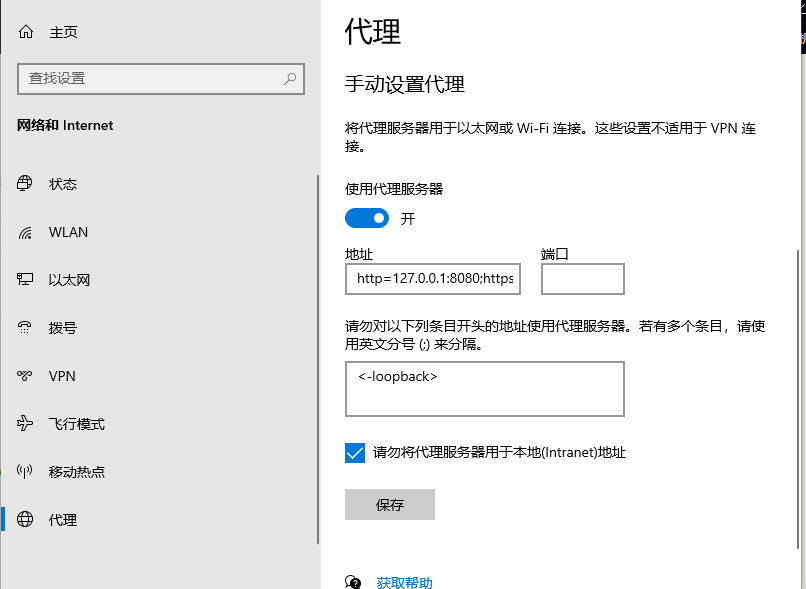
这样就启动mitmdump,接着在本地设置代理Ip是本机IP,端口8080
安装证书
访问下面这个链接
http://mitm.it/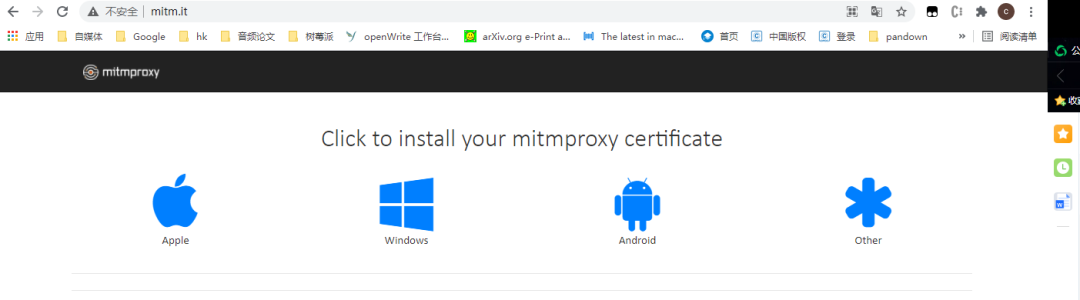
可以选择自己的设备(window,或者Android、Apple设备去)安装证书。
然后随便打开一个网页,比如百度
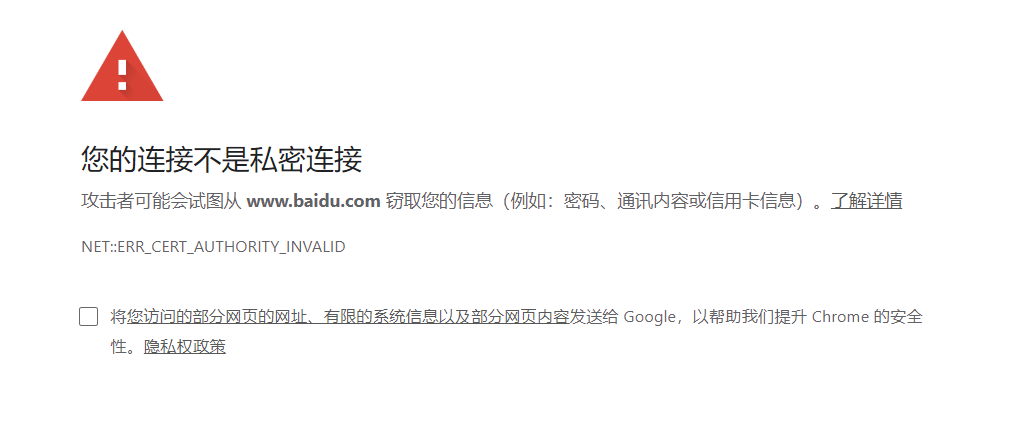
这里是因为证书问题,提示访问百度提示https证书不安全,那么下面开始解决这个问题,因此就引出了下面的这种启动方式
浏览器代理式启动
哪一个浏览器都可以,下面以Chrome浏览器为例(其他浏览器操作一样)
先找到chrome浏览器位置,我的chrome浏览器位置如下图
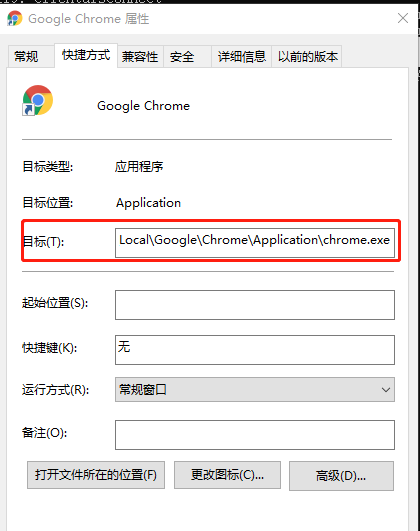
通过下面命令启动
"C:\Users\Administrator\AppData\Local\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors--proxy-server是设置代理和端口
--ignore-certificate-errors是忽略证书
然后会弹出来Chrome浏览器,接着我们搜索知乎
在cmd中就可以看到数据包
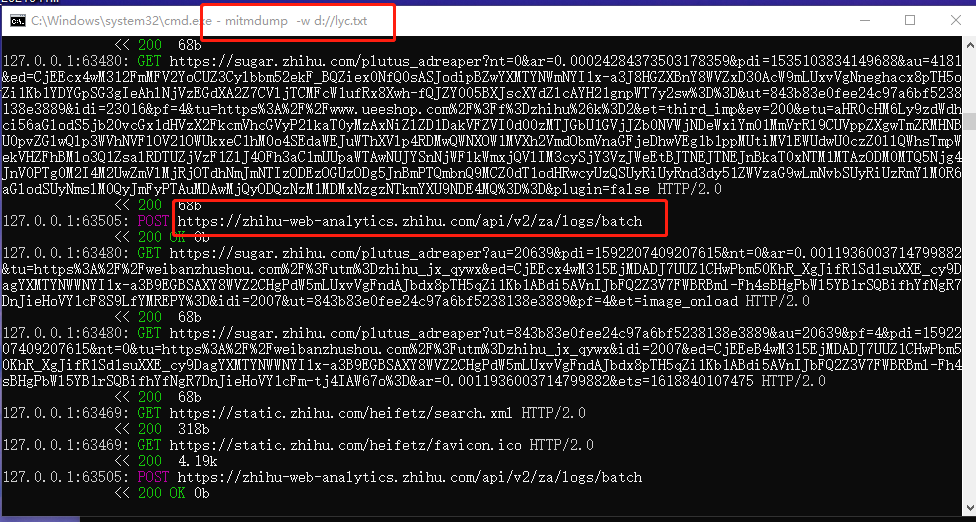
这些文本数据可以在编程中进行相应的操作,比如可以放到python中进行过来监听处理。
3
启动 Mitmweb
新开一个cmd(终端)窗口,输入下来命令启动mitmweb
mitmweb
之后会在浏览器自动打开一个网页(其实手动打开也可以,地址就是:http://127.0.0.1:8081)
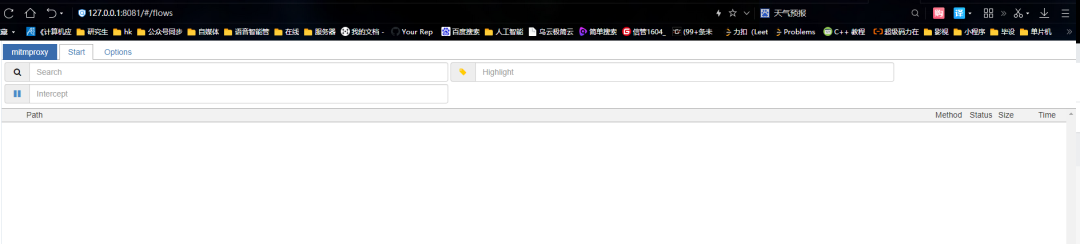
现在页面中什么也没有,那下面我们在刷新一个知乎页面
重点:关闭mitmproxy终端!关闭mitmproxy终端!关闭mitmproxy终端!
如果不改变在mitmweb中获取不到数据,数据只在mitmproxy中,因此需要关闭mitmproxy这个命令终端
刷新知乎页面之后如下:
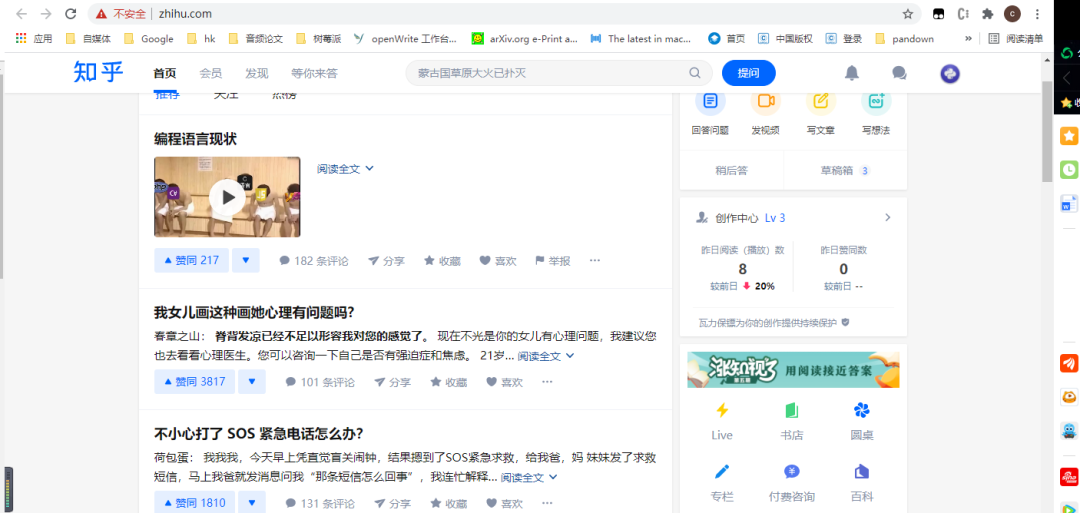
在刚刚的网页版抓包页面就可以看到数据包了
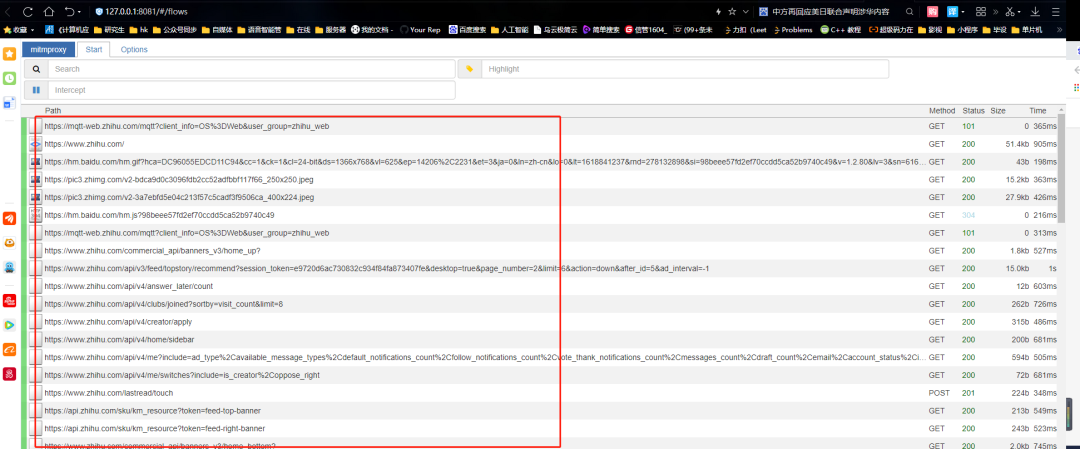
并且还包括https类型,比如查看其中一个数据包,找到数据是对应的,说明抓包成功。
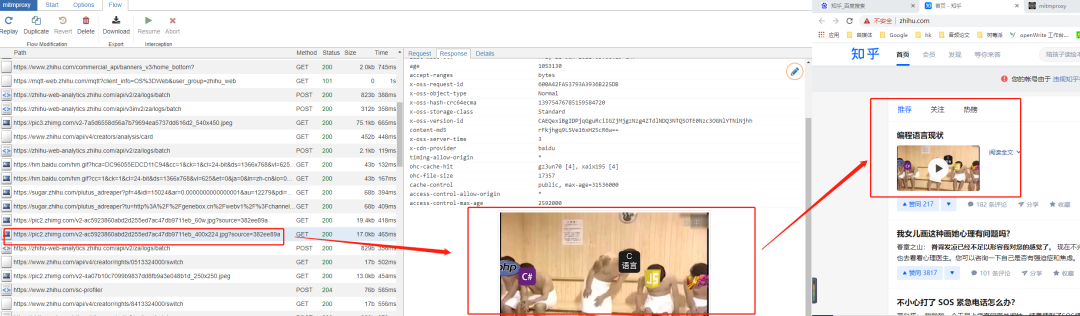
4
配合 Python 脚本
mitmproxy代理(抓包)工具最强大之处在于对python脚步的支持(可以在python代码中直接处理数据包)
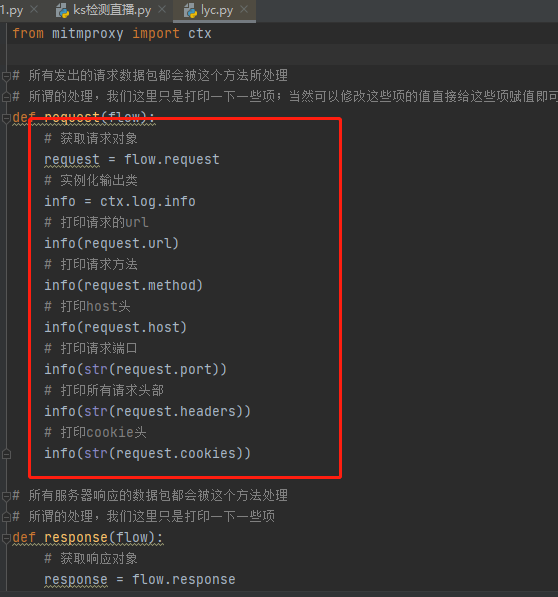
下面开始演示,先新建一个py文件(lyc.py)
from mitmproxy import ctx# 所有发出的请求数据包都会被这个方法所处理# 所谓的处理,我们这里只是打印一下一些项;当然可以修改这些项的值直接给这些项赋值即可def request(flow):# 获取请求对象request = flow.request# 实例化输出类info = ctx.log.info# 打印请求的urlinfo(request.url)# 打印请求方法info(request.method)# 打印host头info(request.host)# 打印请求端口info(str(request.port))# 打印所有请求头部info(str(request.headers))# 打印cookie头info(str(request.cookies))# 所有服务器响应的数据包都会被这个方法处理# 所谓的处理,我们这里只是打印一下一些项def response(flow):# 获取响应对象response = flow.response# 实例化输出类info = ctx.log.info# 打印响应码info(str(response.status_code))# 打印所有头部info(str(response.headers))# 打印cookie头部info(str(response.cookies))# 打印响应报文内容info(str(response.text))
在终端中输入一下命令启动
mitmdump.exe -s lyc.py
(PS:这里需要通过另一个端启动浏览器)
"C:\Users\Administrator\AppData\Local\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors然后访问某个网站
在终端中就可以看到信息
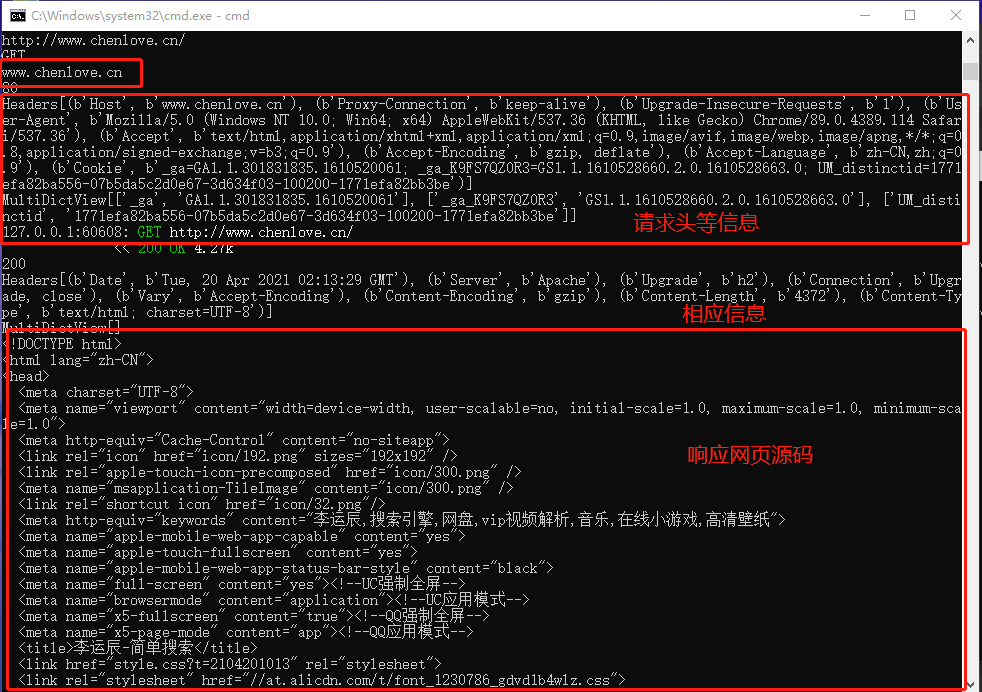
这些信息就是我们在 lyc.py 中指定的显示信息
PS:在手机上配置好代理之后,mitmproxy 同样可以抓取手机端数据
5
小结
不需要安装软件,直接在线(浏览器)进行抓包(包括手机端和 PC 端)
配合 Python 脚本抓包改包
抓包过程的所有数据包都可以自动保留到 txt 里面,方便过滤分析
使用相对简单,易上手