
PyTorch版:集成注意力和MobileNet的YOLOv4
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

距离 YOLO v4 的推出,已经过去 5 个多月。YOLO 框架采用 C 语言作为底层代码,这对于惯用 Python 的研究者来说,实在是有点不友好。因此网上出现了很多基于各种深度学习框架的 YOLO 复现版本。近日,就有研究者在 GitHub 上更新了基于 PyTorch 的 YOLOv4。
「有没有同学复现 YOLOv4 的, 可以交流一下么」。
由于原版 YOLO 使用 C 语言进行编程,光凭这一点就让不少同学望而却步。网上有很多基于 TF/Keras 和 Caffe 等的复现版本,但不少项目只给了代码,并没有给出模型在 COCO、PASCAL VOC 数据集上的训练结果。
近日,有研究者在 GitHub 上开源了一个项目:基于 PyTorch 深度学习框架的 YOLOv4 复现版本,该版本基于 YOLOv4 作者给出的实现 AlexeyAB/darknet,并在 PASCAL VOC、COCO 和自定义数据集上运行。
项目地址:https://github.com/argusswift/YOLOv4-PyTorch
除此以外,该项目还向主干网络添加了一些有用的注意力方法,并实现了mobilenetv2-YOLOV4 和 mobilenetv3-YOLOV4。
attentive YOLOv4
该项目向主干网络添加了一些注意力方法,如 SEnet、CBAM。
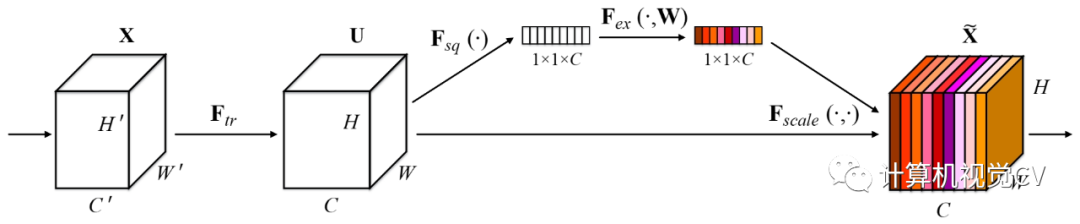
SEnet (CVPR 2017)
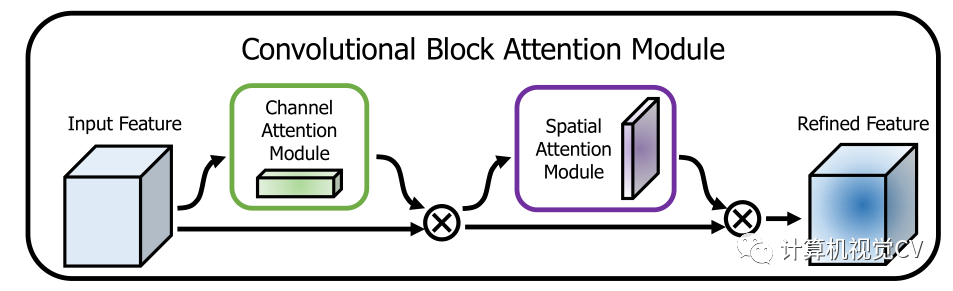
CBAM (CVPR 2018)
mobilenet YOLOv4
该研究还实现了 mobilenetv2-YOLOV4 和 mobilenetv3-YOLOV4(只需更改 config/yolov4_config.py 中的 MODEL_TYPE 即可)。
下表展示了 mobilenetv2-YOLOV4 的性能结果:

现在我们来看该项目的详细内容和要求。
Nvida GeForce RTX 2080TI
CUDA10.0
CUDNN7.0
windows 或 linux 系统
python 3.6
特性
DO-Conv (https://arxiv.org/abs/2006.12030) (torch>=1.2)
Attention
fp_16 training
Mish
Custom data
Data Augment (RandomHorizontalFlip, RandomCrop, RandomAffine, Resize)
Multi-scale Training (320 to 640)
focal loss
CIOU
Label smooth
Mixup
cosine lr
运行脚本安装依赖项。你需要提供 conda 安装路径(例如 ~/anaconda3)以及所创建 conda 环境的名称(此处为 YOLOv4-PyTorch)。
pip3 install -r requirements.txt --user
需要注意的是:安装脚本已在 Ubuntu 18.04 和 Window 10 系统上进行过测试。如果出现问题,请查看详细的安装说明:https://github.com/argusswift/YOLOv4-PyTorch/blob/master/INSTALL.md。
准备工作
1. git 复制 YOLOv4 库
准备工作的第一步是复制 YOLOv4。
git clone github.com/argusswift/YOLOv4-PyTorch.git
然后更新配置文件「config/yolov4_config.py」中「PROJECT_PATH」。
2. 数据集准备
该项目准备了 Pascal VOC 和 MSCOCO 2017 数据集。其中 PascalVOC 数据集包括 VOC 2012_trainval、VOC 2007_trainval 和 VOC2007_test,MSCOCO 2017 数据集包括 train2017_img、train2017_ann、val2017_img、val2017_ann、test2017_img、test2017_list。
PascalVOC 数据集下载命令:
# Download the data.cd $HOME/data
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar# Extract the data.
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar
MSCOCO 2017 数据集下载命令:
#step1: download the following data and annotation
2017 Train images [118K/18GB]
2017 Val images [5K/1GB]
2017 Test images [41K/6GB]
2017 Train/Val annotations [241MB]
#step2: arrange the data to the following structure
COCO
---train
---test
---val
---annotations
在数据集下载好后,需要进行以下操作:
将数据集放入目录,更新 config/yolov4_config.py 中的 DATA_PATH 参数。
(对于 COCO 数据集)使用 coco_to_voc.py 将 COCO 数据类型转换为 VOC 数据类型。
转换数据格式:使用 utils/voc.py 或 utils/coco.py 将 pascal voc *.xml 格式(或 COCO *.json 格式)转换为 *.txt 格式(Image_path xmin0,ymin0,xmax0,ymax0,class0 xmin1,ymin1,xmax1,ymax1,class1 ...)。
3. 下载权重文件
1)darknet 预训练权重:yolov4(https://drive.google.com/file/d/1cewMfusmPjYWbrnuJRuKhPMwRe_b9PaT/view)。
2)Mobilenet 预训练权重:
mobilenetv2:(https://pan.baidu.com/share/init?surl=sjixK2L9L0YgQnvfDuVTJQ,提取码:args);
mobilenetv3:(https://pan.baidu.com/share/init?surl=75wKejULuM0ZD05b9iSftg,提取码:args)。
3)在根目录下创建 weight 文件夹,将下载好的权重文件放到 weight / 目录下。
4)训练时在 config/yolov4_config.py 中设置 MODEL_TYPE。
4. 转换成自定义数据集(基于自定义数据集进行训练)
1)将自定义数据集的图片放入 JPEGImages 文件夹,将注释文件放入 Annotations 文件夹。
2)使用 xml_to_txt.py 文件将训练和测试文件列表写入 ImageSets/Main/*.txt。
3)转换数据格式:使用 utils/voc.py 或 utils/coco.py 将 pascal voc *.xml 格式(或 COCO *.json 格式)转换为 *.txt 格式(Image_path xmin0,ymin0,xmax0,ymax0,class0 xmin1,ymin1,xmax1,ymax1,class1 ...)。
运行以下命令开始训练,详情参见 config / yolov4_config.py。训练时应将 DATA_TYPE 设置为 VOC 或 COCO。
CUDA_VISIBLE_DEVICES=0 nohup python -u train.py --weight_path weight/yolov4.weights --gpu_id 0 > nohup.log 2>&1 &
它还支持 resume 训练,添加 --resume,使用以下命令即可自动加载 last.pt。
CUDA_VISIBLE_DEVICES=0 nohup python -u train.py --weight_path weight/last.pt --gpu_id 0 > nohup.log 2>&1 &
修改检测图像路径:DATA_TEST=/path/to/your/test_data# your own images。
for VOC dataset:
CUDA_VISIBLE_DEVICES=0 python3 eval_voc.py --weight_path weight/best.pt --gpu_id 0 --visiual $DATA_TEST --eval --mode det
for COCO dataset:
CUDA_VISIBLE_DEVICES=0 python3 eval_coco.py --weight_path weight/best.pt --gpu_id 0 --visiual $DATA_TEST --eval --mode det
结果可以在 output / 中查看,如下所示:

修改评估数据集路径:DATA_PATH=/path/to/your/test_data # your own images
for VOC dataset:
CUDA_VISIBLE_DEVICES=0 python3 eval_voc.py --weight_path weight/best.pt --gpu_id 0 --visiual $DATA_TEST --eval -
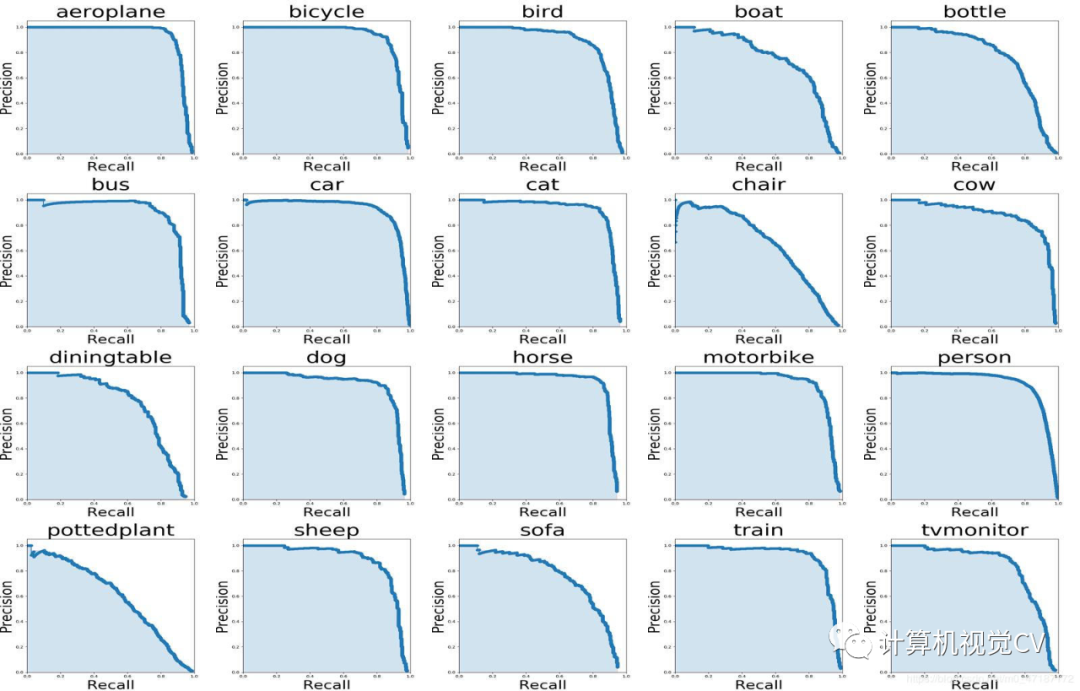
评估(COCO 数据集)
修改评估数据集路径:DATA_PATH=/path/to/your/test_data # your own images
CUDA_VISIBLE_DEVICES=0 python3 eval_coco.py --weight_path weight/best.pt --gpu_id 0 --visiual $DATA_TEST --eval --mode val
type=bbox
Running per image evaluation... DONE (t=0.34s).
Accumulating evaluation results... DONE (t=0.08s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.438
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.607
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.469
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.253
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.486
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.567
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.342
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.571
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.632
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.458
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.691
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.790
在 val_voc.py 中设置 showatt=Ture,网络即可输出热图。
for VOC dataset:
CUDA_VISIBLE_DEVICES=0 python3 eval_voc.py --weight_path weight/best.pt --gpu_id 0 --visiual $DATA_TEST --eval
for COCO dataset:
CUDA_VISIBLE_DEVICES=0 python3 eval_coco.py --weight_path weight/best.pt --gpu_id 0 --visiual $DATA_TEST --eval
在 output / 中可以查看热图,如下所示:

好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~