
如何用数据并行训练万亿参数模型?
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
近期,Facebook发布了FSDP(Fully Sharded Data Parallel),这个是对标微软在DeepSpeed中提出的ZeRO,FSDP可以看成PyTorch中的DDP优化版本,本身也是数据并行,但是和DDP不同的是,FSDP采用了parameter sharding,所谓的parameter sharding就是将模型参数也切分到各个GPUs上,而DDP每个GPU都要保存一份parameter,FSDP可以实现更好的训练效率(速度和显存使用)。这背后的优化逻辑可以从谷歌和微软的论文中找到。
Sharding weight update
对于典型的数据并行实现(PyTorch的DDP和TF的tf.distribute.MirroredStrategy)来说,每个replica(GPU)都拥有一份模型参数和一套optimizer,每个训练step,数据被均分到每个replica上,每个replica基于被分到的数据单独计算自己的local gradients,然后所有的replicas基于all-reduce操作来得到local gradients的summed gradients,这样每个replica其实都拿到了global gradients,最后基于global gradients更新模型参数(weight update)。这个过程如下图所示:
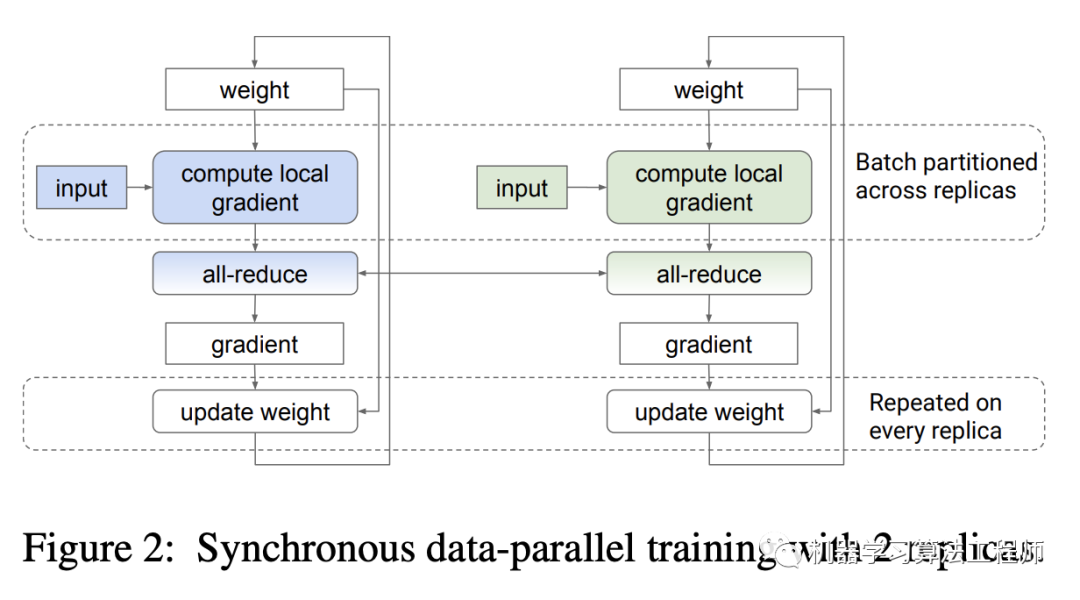 其中all-reduce操作(ring all-reduce)包含两个操作:reduce-scatter和all-gather。在reduce-scatter阶段,gradients被均分成不同的blocks或shards,通过N-1轮交换数据,每个replica都得到一份reduced后的shards;在all-grather阶段,通过N-1轮数据交换,每个replica都将自己的那份reduced后的shards广播到其它的replicas,这样所有的replicas就能得到全部reduced后的gradients。不论有多少replicas,all-reduce的通信成本上是恒定的,这样就可以实现线性加速。
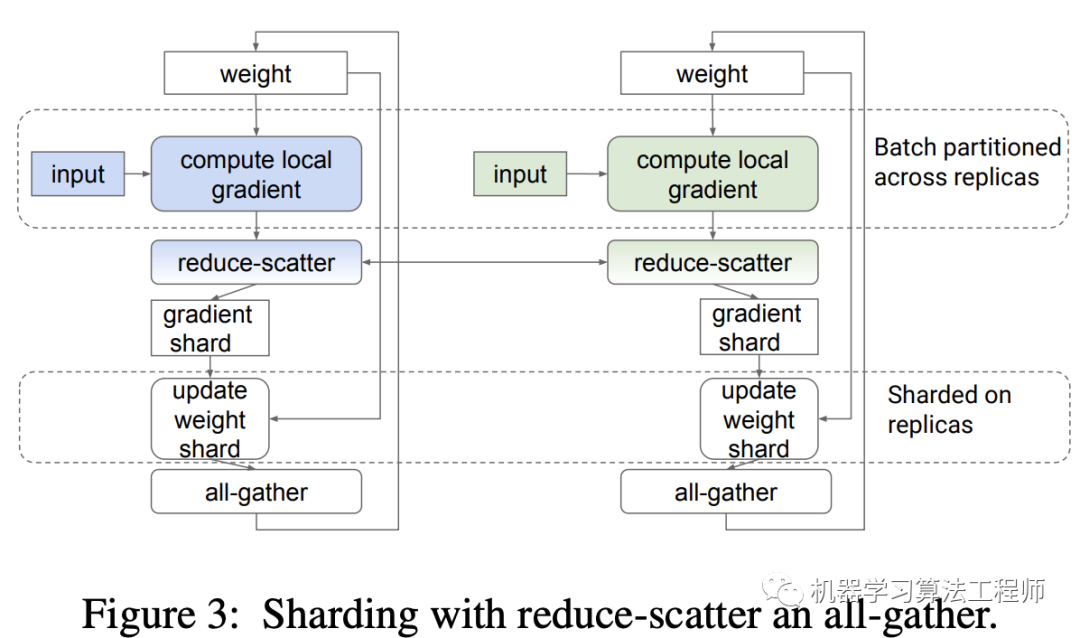
其中all-reduce操作(ring all-reduce)包含两个操作:reduce-scatter和all-gather。在reduce-scatter阶段,gradients被均分成不同的blocks或shards,通过N-1轮交换数据,每个replica都得到一份reduced后的shards;在all-grather阶段,通过N-1轮数据交换,每个replica都将自己的那份reduced后的shards广播到其它的replicas,这样所有的replicas就能得到全部reduced后的gradients。不论有多少replicas,all-reduce的通信成本上是恒定的,这样就可以实现线性加速。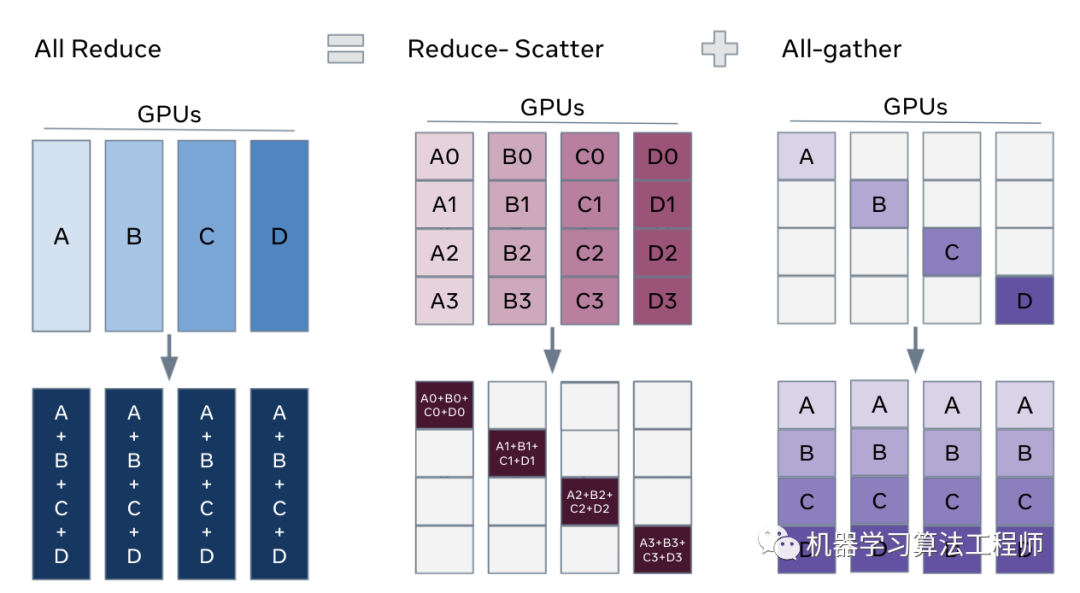 每个replicas拿到reduced gradients后都在做重复的update weight,因为每个replicas都有模型参数的一个copy。如果模型(如NLP中的Transformer)比较大,参数量多,这个update weight在训练step中就会占据不可忽略的耗时;对于小模型的大规模分布式训练,一般每个device会采用较小的batch size以防止global batch size过大,此时update weight也会成为训练step中的重要耗时项。为了解决这个问题,谷歌在2020年提出了sharding weight update,如下图所示,经过reduce-scatter后每个replica得到一个gradient shard,每个replica先更新自己的shard的weight,然后再进行all-gather,这样其实是和原始的all-reduce是等价的。但是经过这个调整,每个replica只是update weight shard,耗时就会降低了,相当于update weight也被各个replica给分担了。
每个replicas拿到reduced gradients后都在做重复的update weight,因为每个replicas都有模型参数的一个copy。如果模型(如NLP中的Transformer)比较大,参数量多,这个update weight在训练step中就会占据不可忽略的耗时;对于小模型的大规模分布式训练,一般每个device会采用较小的batch size以防止global batch size过大,此时update weight也会成为训练step中的重要耗时项。为了解决这个问题,谷歌在2020年提出了sharding weight update,如下图所示,经过reduce-scatter后每个replica得到一个gradient shard,每个replica先更新自己的shard的weight,然后再进行all-gather,这样其实是和原始的all-reduce是等价的。但是经过这个调整,每个replica只是update weight shard,耗时就会降低了,相当于update weight也被各个replica给分担了。
另外一点就是要考虑optimizer,因为optimizer往往包含额外的参数,比如SGD包含一套参数:gradient的EMA,而Adam包含两套参数:gradient的EMA和variance,这些参数可以统称为optimizer states,它们也是需要同步更新的。当模型参数较大时,optimizer states也会很大,比如Adam就是模型参数的2倍,如果也对optimizer states进行all-gather的话,通信成本就会比较大(原始的all-reduce并不需要)。optimizer states只参与weight update中,但是在下一个forward和backward中并不需要,不过optimizer states应该被包含在模型的checkpoints中,因为它们也是training state,比较好的方案是只有当需要时才对optimizer states进行all-gather,这就变成如下图所示: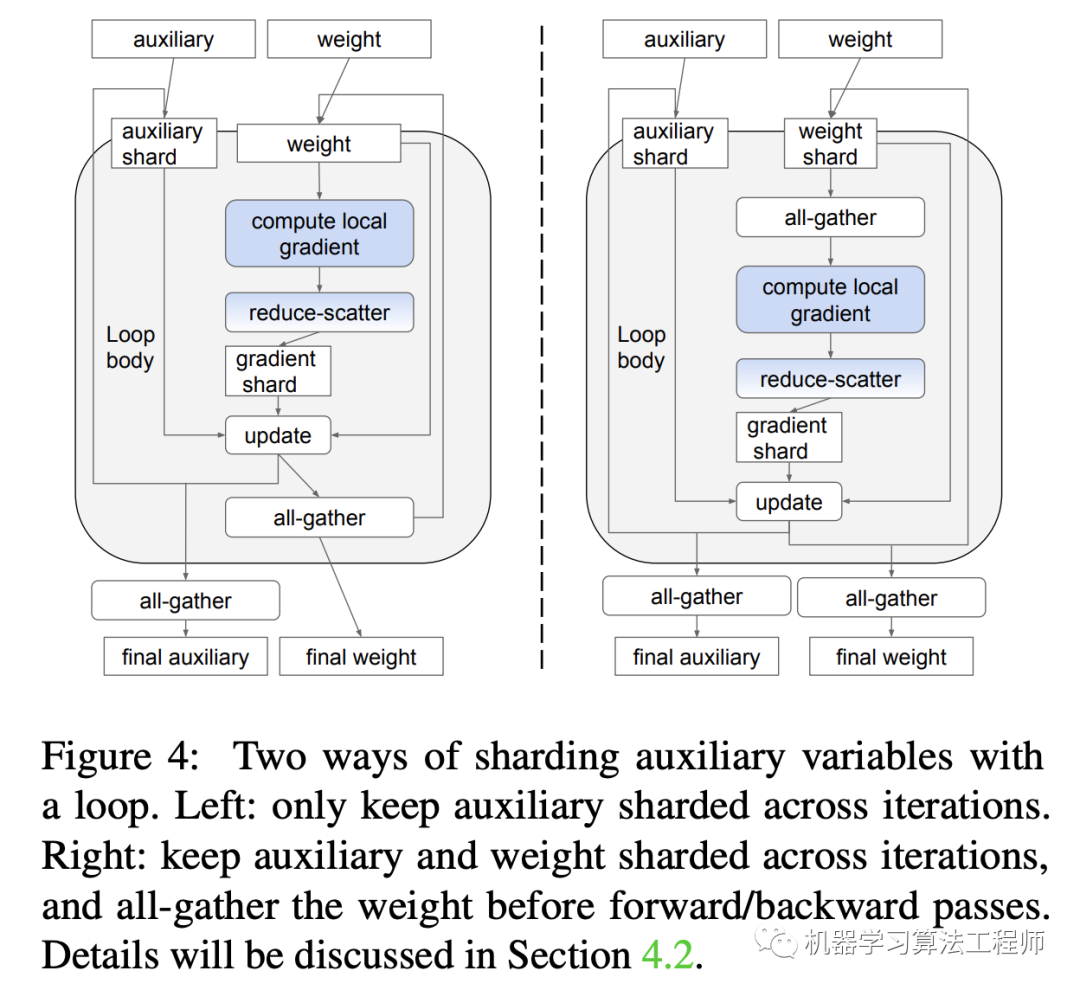 这里optimizer的auxliary只在Loop body外面才进行all-gather以得到final auxliary。另外左图和右图的区别是weight的all-gather的位置不同,左图weight的all-gather是在update后立即进行的,而右图是在需要的时候(forward和backward)才进行all-gather,看起来像是左边的方案更好一点,因为在最后得到final weight时右图还需要一次all-gather。但是右图方案有更大的优化空间,这是因为在forward和backward过程中往往不需要高精度的weight,比如TPU中可以采用bfloat16,虽然update weight需要float32。在右图方案中,可以采用低精度bfloat16来all-gather来得到所需要的全部weight,这样就大大降低了内存使用和通信成本。另外weight和auxliary weight的生存周期也减少了。特别是optimizer的auxliary weight,在training loop中其实只需要shard,这样就节省一部分内存空间,可以用来存储forward和backward中activations和gradients。假定模型参数大小是W,而auxliary weight大小是V,共有N个shards,orward和backward中activations和gradients的峰值大小是P,那么训练的峰值大小就从W+V+P降低为max(W+V/N+P,W+V),这带来的一个好处是Adam将和SGD一样高效(Adam比SGD要多一份auxliary weight)。
这里optimizer的auxliary只在Loop body外面才进行all-gather以得到final auxliary。另外左图和右图的区别是weight的all-gather的位置不同,左图weight的all-gather是在update后立即进行的,而右图是在需要的时候(forward和backward)才进行all-gather,看起来像是左边的方案更好一点,因为在最后得到final weight时右图还需要一次all-gather。但是右图方案有更大的优化空间,这是因为在forward和backward过程中往往不需要高精度的weight,比如TPU中可以采用bfloat16,虽然update weight需要float32。在右图方案中,可以采用低精度bfloat16来all-gather来得到所需要的全部weight,这样就大大降低了内存使用和通信成本。另外weight和auxliary weight的生存周期也减少了。特别是optimizer的auxliary weight,在training loop中其实只需要shard,这样就节省一部分内存空间,可以用来存储forward和backward中activations和gradients。假定模型参数大小是W,而auxliary weight大小是V,共有N个shards,orward和backward中activations和gradients的峰值大小是P,那么训练的峰值大小就从W+V+P降低为max(W+V/N+P,W+V),这带来的一个好处是Adam将和SGD一样高效(Adam比SGD要多一份auxliary weight)。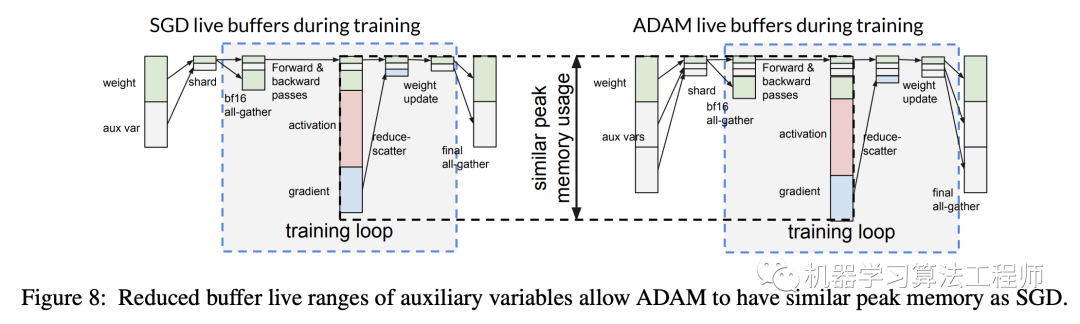 可以看到谷歌提出的sharding weight update不仅可以加速训练,而且也会节省显存,这里只是简单介绍了论文最核心的优化逻辑,论文中还有关于graph和shard具体实现细节讨论。论文中基于ResNet-50,Transformer和NCF三个模型做实验,实验配置如下:
可以看到谷歌提出的sharding weight update不仅可以加速训练,而且也会节省显存,这里只是简单介绍了论文最核心的优化逻辑,论文中还有关于graph和shard具体实现细节讨论。论文中基于ResNet-50,Transformer和NCF三个模型做实验,实验配置如下: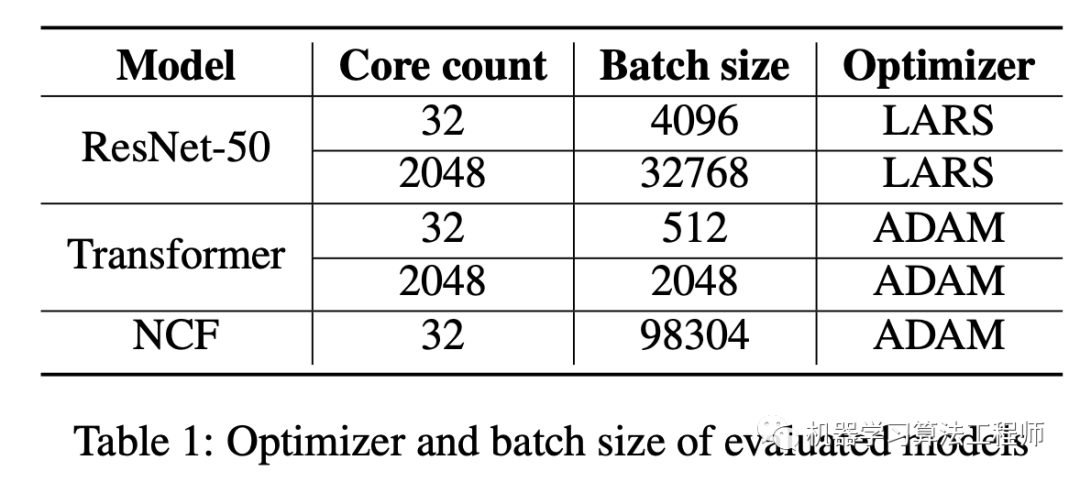 从实验结果来看,无论是CV还是NLP模型在训练耗时和显存使用上均有提升,特别是对大规模训练的场景(replica batch size小)和模型较大的场景(Transformer模型):
从实验结果来看,无论是CV还是NLP模型在训练耗时和显存使用上均有提升,特别是对大规模训练的场景(replica batch size小)和模型较大的场景(Transformer模型):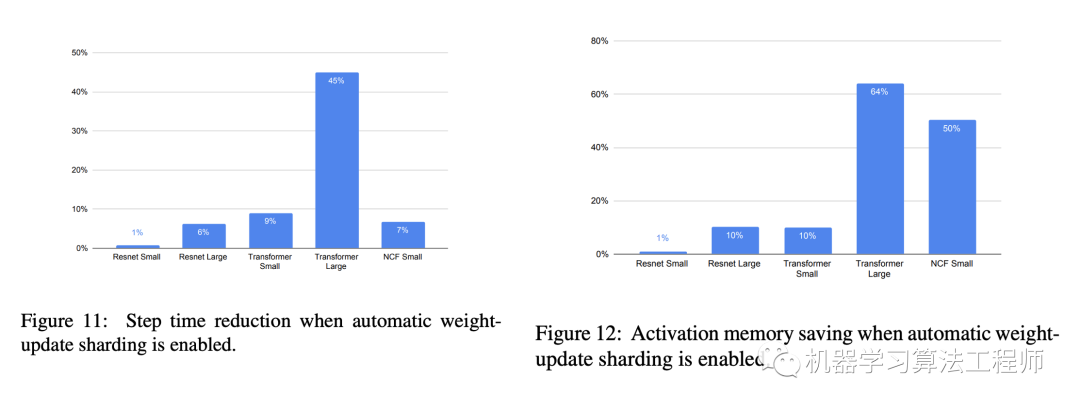
ZeRO-DP
微软在DeepSpeed中提出的ZeRO(Zero Redundancy Optimizer)出发点是优化内存使用,从而提高训练速度,并且可以实现训练更大的模型。ZeRO包含模型并行ZeRO-R和数据并行ZeRO-DP,这里我们只讨论数据并行ZeRO-DP。ZeRO-DP的出发点是优化model states,这里的model states包括:optimizer states, gradients and parameters,其中optimizer states前面已经说过,就是optimizer所需要的参数,对于Adam其optimizer states是parameters的2倍,而且使用混合精度训练时,optimizer states是fp32,这将成为显存占用的大头。
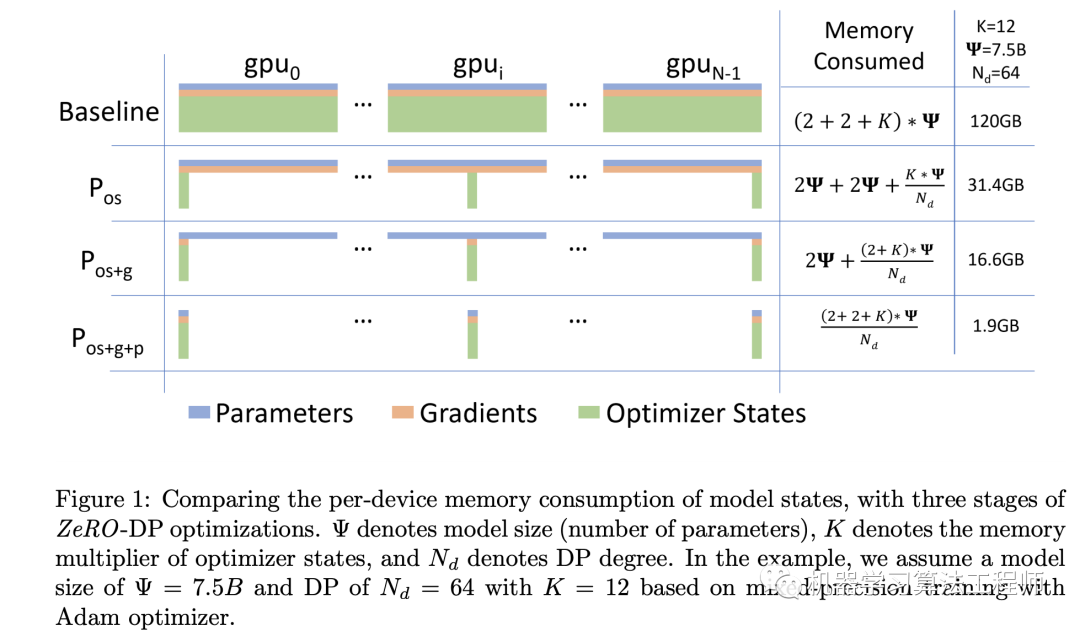 在混合精度训练中,训练的forward和backward采用的是fp16 weights,activations和gradients,但是weight update需要采用fp32,这就需要optimizer保存一份fp32 weights,而且optimizer states也要采用fp32。假定模型大小是 Ψ,而gradients和parameters均采用fp16,那么消耗的显存是2Ψ+2Ψ。而Adam需要fp32的parameters,momentum和variance(optimizer states),其消耗的显存是4Ψ+4Ψ+4Ψ。用K来表示optimizer states的multiplier,那么model states消耗的显存是(4+K)*Ψ,对于Adam来说K=12,那么model states消耗的显存是16Ψ。ZeRO-DP的优化策略就是分别对model states各个部分进行partitioning:
在混合精度训练中,训练的forward和backward采用的是fp16 weights,activations和gradients,但是weight update需要采用fp32,这就需要optimizer保存一份fp32 weights,而且optimizer states也要采用fp32。假定模型大小是 Ψ,而gradients和parameters均采用fp16,那么消耗的显存是2Ψ+2Ψ。而Adam需要fp32的parameters,momentum和variance(optimizer states),其消耗的显存是4Ψ+4Ψ+4Ψ。用K来表示optimizer states的multiplier,那么model states消耗的显存是(4+K)*Ψ,对于Adam来说K=12,那么model states消耗的显存是16Ψ。ZeRO-DP的优化策略就是分别对model states各个部分进行partitioning:
Optimizer State Partitioning
如果DP的并行度为(replicas数量),那么可以将optimizer state均分为个partitions,这样第i个节点只需要更新optimizer state第i个partition。此时每个节点只需要存储和更新所有optimizer state的,而且也只更新parameter的。在每个training step的最后,只需要执行all-gather,每个节点就可以获得更新后的全部parameter。可以计算,optimizer State partitioning()消耗的显存就减少为。这个优化其实前面谷歌的工作也做了。
Gradient Partitioning
既然每个节点只需要更新parameter的,那么其实每个节点也只需要对应参数的gradient。具体地,在backward过程的每个layer,一旦得到了gradient,每个节点就对自己所需那部分参数的gradient做reduce(等价于做一个reduce-scatter),得到summed gradients,由于其它部分的gradient并不需要了就可以释放了,从而减少了显存使用,这可以称为gradient partitioning()。此时显存的消耗降为。
Parameter Partitioning
更进一步地,其实每个节点只需要存储要更新的那部分参数就好,在forward和backward过程中,需要全部的weight时再进行all-gather,然后再丢弃,这就是parameter partitioning(),此时显存的消耗进一步减低为。但是采用parameter partitioning是通信开销的,论文中实验说明使用后通信成本增大1.5倍。
基于ZeRO-DP,当时,1T Model(万亿参数)消耗的显存为15.6GB,模型可以放在一张32GB的V100卡上。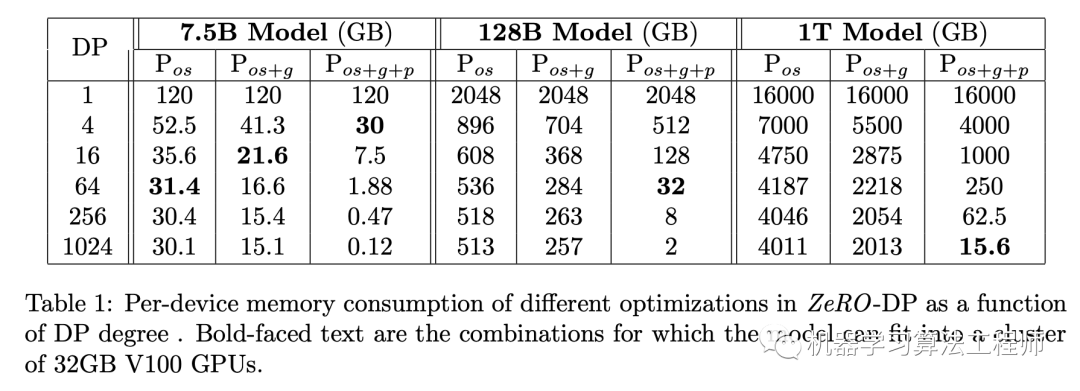 其实可以看到,谷歌的sharding weight update近似等价于采用的ZeRO-DP,虽然两个工作的出发点不一样,但是殊途同归。
其实可以看到,谷歌的sharding weight update近似等价于采用的ZeRO-DP,虽然两个工作的出发点不一样,但是殊途同归。
FSDP
其实在FSDP之前,Facebook已经实现了optimizer state+gradient sharding DP,这就是采用的ZeRO-DP,或者叫ZeRO-DP-2,这个实现包含在fairscale库中,一个具体的使用case如下所示:
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
from fairscale.optim.oss import OSS
from fairscale.nn.data_parallel import ShardedDataParallel as ShardedDDP
def train(
rank: int,
world_size: int,
epochs: int):
# DDP init example
dist.init_process_group(backend='nccl', init_method="tcp://localhost:29501", rank=rank, world_size=world_size)
# Problem statement
model = myAwesomeModel().to(rank)
dataloader = mySuperFastDataloader()
loss_fn = myVeryRelevantLoss()
base_optimizer = torch.optim.SGD # pick any pytorch compliant optimizer here
base_optimizer_arguments = {} # pass any optimizer specific arguments here, or directly below when instantiating OSS
# Wrap the optimizer in its state sharding brethren
optimizer = OSS(params=model.parameters(), optim=base_optimizer, **base_optimizer_arguments)
# Wrap the model into ShardedDDP, which will reduce gradients to the proper ranks
model = ShardedDDP(model, optimizer)
# Any relevant training loop, nothing specific to OSS. For example:
model.train()
for e in range(epochs):
for batch in dataloader:
# Train
model.zero_grad()
outputs = model(batch["inputs"])
loss = loss_fn(outputs, batch["label"])
loss.backward()
optimizer.step()
dist.destroy_process_group()
if __name__ == "__main__":
# Supposing that WORLD_SIZE and EPOCHS are somehow defined somewhere
mp.spawn(
train,
args=(
WORLD_SIZE,
EPOCHS,
),
nprocs=WORLD_SIZE,
join=True,
)
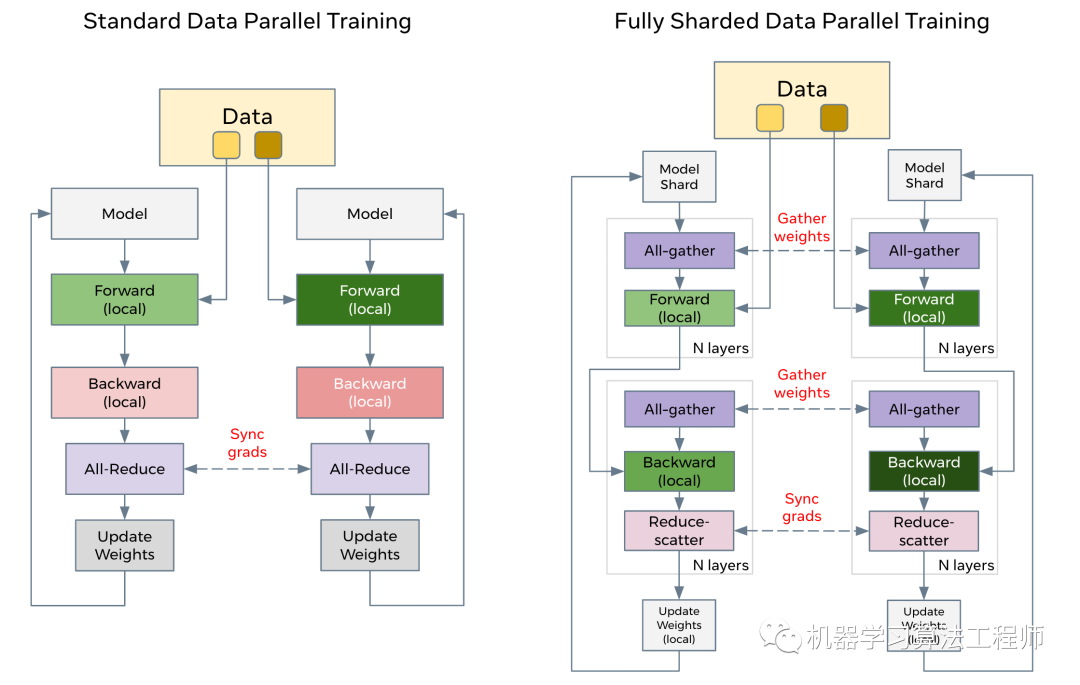
而最近发布的FSDP更是实现了完全的ZeRO-DP,而且据官方说效率更高,更重要的是FSDP可以直接替换PyTorch的DDP,FSDP的特点如下:
FSDP对parameters (FP16 + FP32)和optimizer state进行sharding; 当reshard_after_forward=False,和PyTorch DDP通信成本一样,类似ZeRO-DP-2; 当reshard_after_forward=True通信成本增加50%,类似ZeRO-DP-3,速度会慢,但是显存开销最小,此时行为如下:
FSDP forward pass:
for layer_i in layers:
all-gather full weights for layer_i
forward pass for layer_i
discard full weights for layer_i
FSDP backward pass:
for layer_i in layers:
all-gather full weights for layer_i
backward pass for layer_i
discard full weights for layer_i
reduce-scatter gradients for layer_i
FSDP通常情况下要比PyTorch DDP快,因为optimizer step is sharded, 而且额外的通信可以和forward过程交叉; FSDP用8 GPUs可以训练13B parameter models,用128 GPUs可以训练175B parameter models。当设置cpu_offload=True,可以用256 GPUs训练 1T parameter models。 FSDP只兼容pointwise Optimizers(Adam, AdamW, Adadelta, Adamax, SGD等),如果是non-pointwise Optimizers(Adagrad, Adafactor, LAMB等),sharding将得到稍微不一样的结果。
 使用FSDP很简单,只需要在代码中简单地替换原来的DDP:
使用FSDP很简单,只需要在代码中简单地替换原来的DDP:
from fairscale.nn.data_parallel import FullyShardedDataParallel as FSDP
...
sharded_module = DDP(my_module) -> FSDP(my_module)
optim = torch.optim.Adam(sharded_module.parameters(), lr=0.0001)
for sample, label in dataload.next_batch:
out = sharded_module(x=sample, y=3, z=torch.Tensor([1]))
loss = criterion(out, label)
loss.backward()
optim.step()
结语
未来,随着算力的增强,大模型应该是趋势,那么类似FSDP这样的工具将会发挥价值。PS:本文只是简单地回顾了FSDP背后所涉及的优化逻辑,但是背后的实现细节应该远不止此,如果错误,请见解。
参考
Fully Sharded Data Parallel: faster AI training with fewer GPUs https://github.com/microsoft/DeepSpeed ZeRO: Memory Optimizations Toward Training Trillion Parameter Models Automatic Cross-Replica Sharding of Weight Update in Data-Parallel Training
推荐阅读
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
