
如何用决策树模型做数据分析?

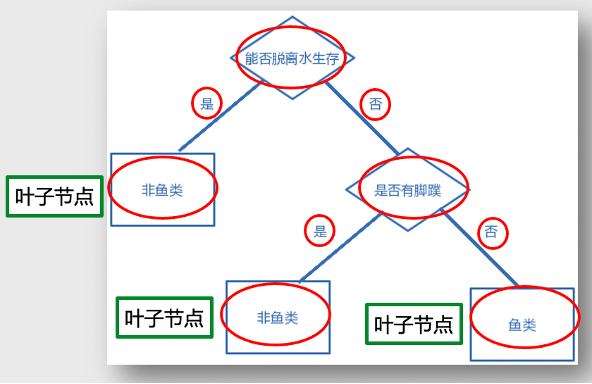
简单:逻辑相对简单,整个算法没有更复杂的逻辑,只是对节点进行分叉; 高效:模型训练速度较快; 强解释性:模型的判断逻辑可以用语言清晰的表达出来,比如上述决策树案例中的判断,就可以直接用语言表述成:脱离水不能生存的没有脚蹼的动物,我们判断它是鱼;
监督分层; 驱动力分析:某个因变量指标受多个因素所影响,分析不同因素对因变量驱动力的强弱(驱动力指相关性,不是因果性); 预测:根据模型进行分类的预测;

熵是什么?

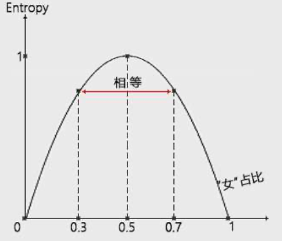
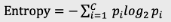

信息增益
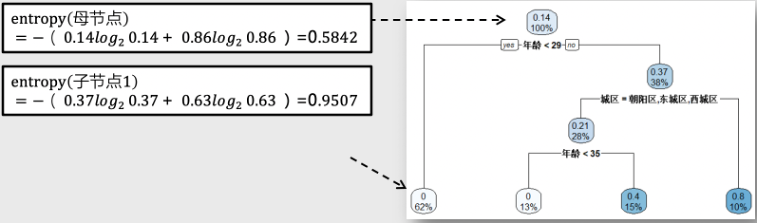

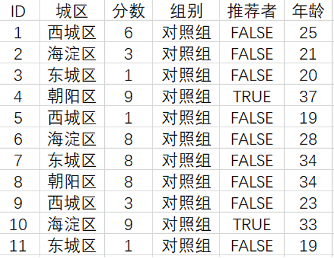
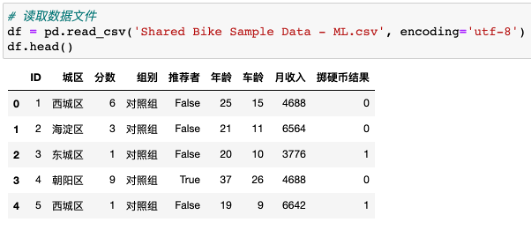
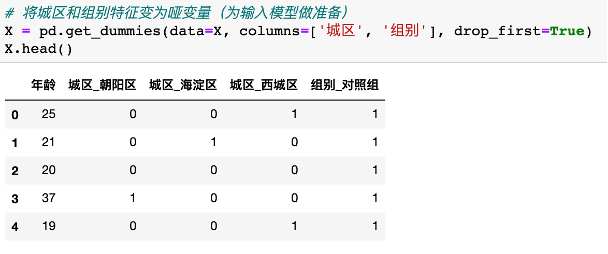
我们继续用上一篇文章《如何用线性回归模型做数据分析》中的共享单车服务满意分数据集来做案例,分析哪一类人群更加偏向于成为公司的推荐者,我们需要分析用户特征,更好的区分出推荐者。
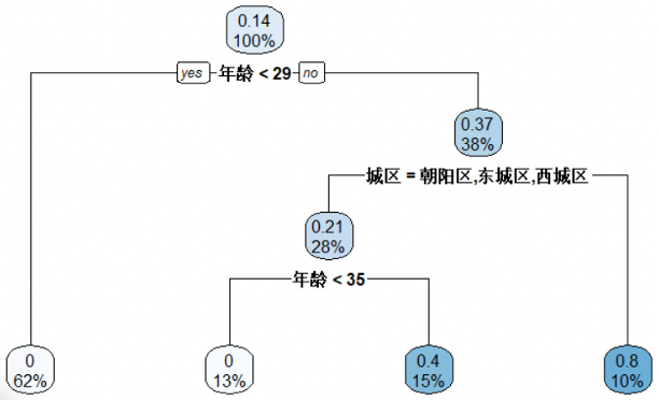
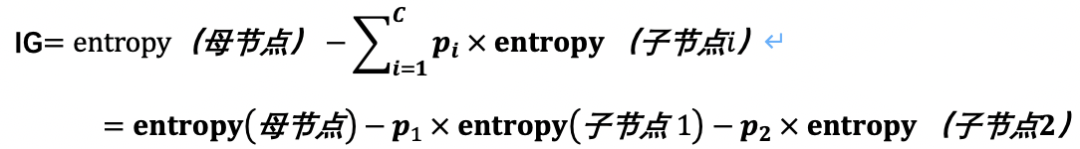
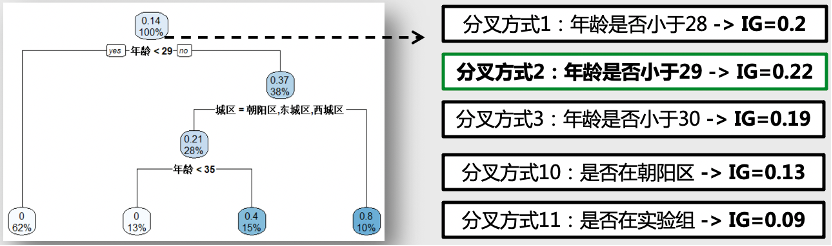
树的深度 — 如规定树的深度不能超过3
叶子结点样本数 — 如叶子结点样本数不能小于10
信息增益 — 如每一个分叉的信息增益不能小于0.2(R中的默认值)
 决策树在数据分析中的实战流程
决策树在数据分析中的实战流程


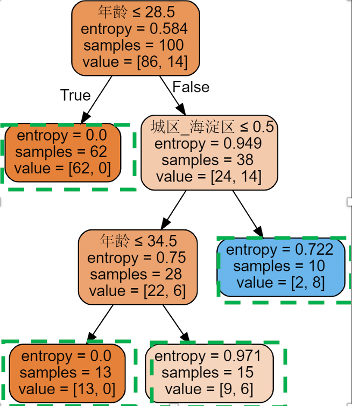
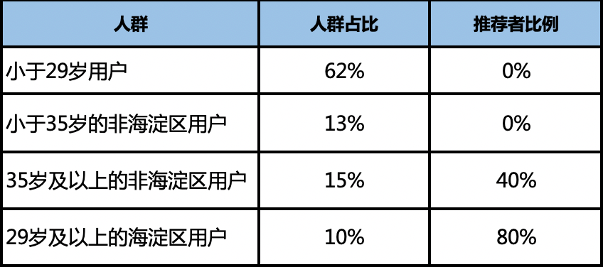
模型建立后,可以将模型用作分类预测; 决策树不只可应用于预测量为分类变量,还可应用于数值型因变量,只需将熵改为连续变量的方差; 特征划分的方法除了信息增益方法外,还可以用增益率(C4.5决策树)、基尼指数(CART决策树); 剪枝是决策树算法中防止过拟合的主要手段,分为预剪枝与后剪枝。预剪枝指在决策树生成过程中,对每个结点在划分前进行估计,若当前结点划分不能使决策树泛化能力提升则停止划分。后剪枝指先从训练集生成一颗决策树,自底向上对非叶结点进行考察,若该结点对应的子树替换为叶结点能使决策树泛化能力提升,则该子树替换为叶结点;
评论