
[源码解析] 模型并行分布式训练Megatron (2) --- 整体架构
0x00 摘要0x01 启动1.1 分布式启动1.2 构造基础1.2.1 获取模型1.2.2 获取数据集1.2.3 步进函数1.2.3.1 广播数据0x02 Pretrain0x03 初始化3.1 initialize_megatron3.2 初始化分布式环境3.3 初始化进程组全局变量0x04 设置模型4.1 setup_model_and_optimizer4.2 模型4.2.1 BertModel4.2.2 语言模型4.2.3 ParallelTransformer4.2.3.1 获取层数4.2.3.2 前向传播4.3 get_model0x05 数据并行5.1 设置数据5.2 DDP5.2.1 定义5.2.2 初始化5.2.3 内存5.2.4 支撑函数5.2.5 梯度规约0x06 训练6.1 训练主体6.2 训练step6.3 获取schedule0xFF 参考
0x00 摘要
NVIDIA Megatron 是一个基于 PyTorch 的分布式训练框架,用来训练超大Transformer语言模型,其通过综合应用了数据并行,Tensor并行和Pipeline并行来复现 GPT3,值得我们深入分析其背后机理。
本系列大概有6~7篇文章,通过论文和源码和大家一起学习研究。本文将对 Megatron 的基本架构做一下梳理。
0x01 启动
1.1 分布式启动
启动脚本在 examples/pretrain_bert_distributed.sh,其利用了 torch.distributed.launch 来启动多个进程。具体业务代码是 pretrain_bert.py。
因为 GPUS_PER_NODE 是8,所以 nproc_per_node 是8,这样,在本机上就启动了8个进程,每个进程之中含有模型的一部分。进程的 rank 是被 torch.distributed.launch 调用 elastic 自动分配的。
#!/bin/bash
GPUS_PER_NODE=8
# Change for multinode config
MASTER_ADDR=localhost
MASTER_PORT=6000
NNODES=1
NODE_RANK=0
WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES))
DATA_PATH=<Specify path and file prefix>_text_sentence
CHECKPOINT_PATH=<Specify path>
DISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE --nnodes $NNODES --node_rank $NODE_RANK --master_addr $MASTER_ADDR --master_port $MASTER_PORT"
python -m torch.distributed.launch $DISTRIBUTED_ARGS \
pretrain_bert.py \
--num-layers 24 \
--hidden-size 1024 \
--num-attention-heads 16 \
--micro-batch-size 4 \
--global-batch-size 32 \
--seq-length 512 \
--max-position-embeddings 512 \
--train-iters 1000000 \
--save $CHECKPOINT_PATH \
--load $CHECKPOINT_PATH \
--data-path $DATA_PATH \
--vocab-file bert-vocab.txt \
--data-impl mmap \
--split 949,50,1 \
--distributed-backend nccl \
--lr 0.0001 \
--lr-decay-style linear \
--min-lr 1.0e-5 \
--lr-decay-iters 990000 \
--weight-decay 1e-2 \
--clip-grad 1.0 \
--lr-warmup-fraction .01 \
--log-interval 100 \
--save-interval 10000 \
--eval-interval 1000 \
--eval-iters 10 \
--fp16
1.2 构造基础
pretrain_bert.py 会调用 pretrain 进行预训练。
if __name__ == "__main__":
pretrain(train_valid_test_datasets_provider, model_provider,
ModelType.encoder_or_decoder,
forward_step, args_defaults={'tokenizer_type': 'BertWordPieceLowerCase'})
1.2.1 获取模型
model_provider返回模型普通版本(vanilla version)。所谓vanilla,我们指的是一个简单的cpu模型,没有 fp16或 ddp,但是已经被 Megatron 改造为并行的版本。
def model_provider(pre_process=True, post_process=True):
"""Build the model."""
print_rank_0('building BERT model ...')
args = get_args()
num_tokentypes = 2 if args.bert_binary_head else 0
model = BertModel(
num_tokentypes=num_tokentypes,
add_binary_head=args.bert_binary_head,
parallel_output=True,
pre_process=pre_process,
post_process=post_process)
return model
1.2.2 获取数据集
train_valid_test_datasets_provider 会接受train/valid/test数据集的大小,并返回 “train,valid,test” 数据集。
def train_valid_test_datasets_provider(train_val_test_num_samples):
"""Build train, valid, and test datasets."""
args = get_args()
print_rank_0('> building train, validation, and test datasets '
'for BERT ...')
train_ds, valid_ds, test_ds = build_train_valid_test_datasets(
data_prefix=args.data_path,
data_impl=args.data_impl,
splits_string=args.split,
train_valid_test_num_samples=train_val_test_num_samples,
max_seq_length=args.seq_length,
masked_lm_prob=args.mask_prob,
short_seq_prob=args.short_seq_prob,
seed=args.seed,
skip_warmup=(not args.mmap_warmup),
binary_head=args.bert_binary_head)
print_rank_0("> finished creating BERT datasets ...")
return train_ds, valid_ds, test_ds
1.2.3 步进函数
forward_step函数接受一个“数据迭代器”和“模型”,并返回一个“loss”标量,该标量带有一个字典,其中key:value是希望在训练期间监视的信息,例如“lm loss:value”。还要求此函数将“batch generator”添加到timers类中。
def forward_step(data_iterator, model):
"""Forward step."""
args = get_args()
# Get the batch.
tokens, types, sentence_order, loss_mask, lm_labels, padding_mask = get_batch(
data_iterator)
if not args.bert_binary_head:
types = None
# Forward pass through the model.
output_tensor = model(tokens, padding_mask, tokentype_ids=types,
lm_labels=lm_labels)
return output_tensor, partial(loss_func, loss_mask, sentence_order)
1.2.3.1 广播数据
forward_step 会调用 get_batch 获取batch 数据,其内部会从迭代器获取数据,然后使用broadcast_data函数把输入数据从 rank 0 广播到所有tensor-model-parallel 其他 ranks之上。
注意,数据并行是把不同数据加载到不同的rank之上,而 Tensor模型并行组之中每个rank都加载同样数据。
def get_batch(data_iterator):
"""Build the batch."""
# Items and their type.
keys = ['text', 'types', 'labels', 'is_random', 'loss_mask', 'padding_mask']
datatype = torch.int64
# Broadcast data.
if data_iterator is not None:
data = next(data_iterator) # 获取数据
else:
data = None
data_b = mpu.broadcast_data(keys, data, datatype) # 把数据广播到各个GPU
# Unpack.
tokens = data_b['text'].long()
types = data_b['types'].long()
sentence_order = data_b['is_random'].long()
loss_mask = data_b['loss_mask'].float()
lm_labels = data_b['labels'].long()
padding_mask = data_b['padding_mask'].long()
return tokens, types, sentence_order, loss_mask, lm_labels, padding_mask
broadcast_data 在每个model parallel group之上,把数据从rank 0发送到同组其他成员。
def broadcast_data(keys, data, datatype):
"""Broadcast data from rank zero of each model parallel group to the
members of the same model parallel group.
Arguments:
keys: list of keys in the data disctionary to be broadcasted
data: data dictionary of string keys and cpu tensor values.
datatype: torch data type of all tensors in data associated
with keys.
"""
# Build (key, size) and (key, number of elements) dictionaries along
# with the total number of elements on all ranks.
key_size, key_numel, total_numel = _build_key_size_numel_dictionaries(keys,
data)
# Pack on rank zero.
if get_tensor_model_parallel_rank() == 0: # rank 0才压缩
# Check that all keys have the same data type.
_check_data_types(keys, data, datatype)
# Flatten the data associated with the keys
flatten_data = torch.cat(
[data[key].contiguous().view(-1) for key in keys], dim=0).cuda()
else:
flatten_data = torch.empty(total_numel,
device=torch.cuda.current_device(),
dtype=datatype)
# Broadcast
torch.distributed.broadcast(flatten_data, get_tensor_model_parallel_src_rank(),
group=get_tensor_model_parallel_group())
# Unpack
output = {}
offset = 0
for key in keys:
size = key_size[key]
numel = key_numel[key]
output[key] = flatten_data.narrow(0, offset, numel).view(size)
offset += numel
return output
get_tensor_model_parallel_src_rank 计算与张量模型并行组中第一个local rank对应的全局rank。
def get_tensor_model_parallel_src_rank():
"""Calculate the global rank corresponding to the first local rank
in the tensor model parallel group."""
global_rank = torch.distributed.get_rank()
local_world_size = get_tensor_model_parallel_world_size()
return (global_rank // local_world_size) * local_world_size
逻辑图具体如下,三个不同的函数分别为预训练提供不同的功能输入,做到了解耦。
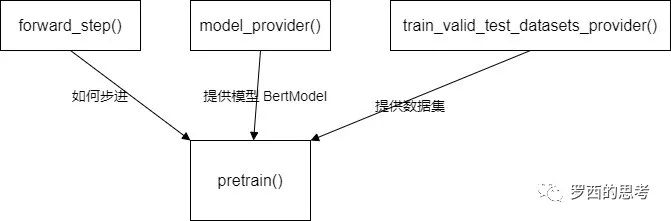
0x02 Pretrain
BERT训练主要分为两步:
Pre-train:pre-train是迁移学习的基础,是训练token-level的语义理解。
Fine-tuning:在已经训练好的语言模型基础之上,加入特定领域(比如金融医疗)的参数来重新训练,比如对于分类问题就可以在pre-train模型基础之上加上一个softmax,再使用语料 fine-tune。
Pre-train 主要如下:
初始化Megatron。
使用model_provider设置模型、优化器和lr计划。
调用train_val_test_data_provider以获取train/val/test数据集。
使用forward_step_func训练模型。
具体代码如下:
def pretrain(train_valid_test_dataset_provider,
model_provider,
model_type,
forward_step_func,
extra_args_provider=None,
args_defaults={}):
"""Main training program.
This function will run the followings in the order provided:
1) initialize Megatron.
2) setup model, optimizer and lr schedule using the model_provider.
3) call train_val_test_data_provider to get train/val/test datasets.
4) train the modle using the forward_step_func.
"""
# Initalize and get arguments, timers, and Tensorboard writer.
initialize_megatron(extra_args_provider=extra_args_provider,
args_defaults=args_defaults)
# Adjust the startup time so it reflects the largest value.
# This will be closer to what scheduler will see (outside of
# image ... launches.
global _TRAIN_START_TIME
start_time_tensor = torch.cuda.DoubleTensor([_TRAIN_START_TIME])
torch.distributed.all_reduce(start_time_tensor,
op=torch.distributed.ReduceOp.MIN)
_TRAIN_START_TIME = start_time_tensor.item()
args = get_args()
timers = get_timers()
# Model, optimizer, and learning rate. 使用model_provider设置模型、优化器和lr计划
model, optimizer, lr_scheduler = setup_model_and_optimizer(model_provider,
model_type)
# Data stuff. 调用train_val_test_data_provider以获取train/val/测试数据集
if args.virtual_pipeline_model_parallel_size is not None:
all_data_iterators = [
build_train_valid_test_data_iterators(train_valid_test_dataset_provider)
for _ in range(len(model))
]
train_data_iterator = [data_iterators[0] for data_iterators in all_data_iterators]
valid_data_iterator = [data_iterators[1] for data_iterators in all_data_iterators]
test_data_iterator = [data_iterators[2] for data_iterators in all_data_iterators]
else:
train_data_iterator, valid_data_iterator, test_data_iterator \
= build_train_valid_test_data_iterators(
train_valid_test_dataset_provider)
iteration = 0
if args.do_train and args.train_iters > 0:
iteration = train(forward_step_func, # 训练模型
model, optimizer, lr_scheduler,
train_data_iterator, valid_data_iterator)
if args.do_valid:
prefix = 'the end of training for val data'
evaluate_and_print_results(prefix, forward_step_func,
valid_data_iterator, model,
iteration, False)
if args.save and iteration != 0:
save_checkpoint(iteration, model, optimizer, lr_scheduler)
if args.do_test:
# Run on test data.
prefix = 'the end of training for test data'
evaluate_and_print_results(prefix, forward_step_func,
test_data_iterator, model,
0, True)
对于我们分析来说,initialize_megatron 是重点,这里初始化了 megatron。
0x03 初始化
3.1 initialize_megatron
initialize_megatron 方法会设置全局变量,初始化分布式环境等等。
def initialize_megatron(extra_args_provider=None, args_defaults={},
ignore_unknown_args=False, allow_no_cuda=False):
"""Set global variables, initialize distributed, and
set autoresume and random seeds.
`allow_no_cuda` should not be set unless using megatron for cpu only
data processing. In general this arg should not be set unless you know
what you are doing.
Returns a function to finalize distributed env initialization
(optionally, only when args.lazy_mpu_init == True)
"""
if not allow_no_cuda:
# Make sure cuda is available.
assert torch.cuda.is_available(), 'Megatron requires CUDA.'
# Parse args, build tokenizer, and set adlr-autoresume,
# tensorboard-writer, and timers.
set_global_variables(extra_args_provider=extra_args_provider, # 设置全局变量
args_defaults=args_defaults,
ignore_unknown_args=ignore_unknown_args)
# torch.distributed initialization
def finish_mpu_init():
args = get_args()
# Pytorch distributed.
_initialize_distributed() # 设置分布式
# Random seeds for reproducibility.
if args.rank == 0:
print('> setting random seeds to {} ...'.format(args.seed))
_set_random_seed(args.seed)
# Set pytorch JIT layer fusion options.
_set_jit_fusion_options()
args = get_args()
if args.lazy_mpu_init:
args.use_cpu_initialization=True
# delayed initialization of DDP-related stuff
# We only set basic DDP globals
set_tensor_model_parallel_world_size(args.tensor_model_parallel_size)
# and return function for external DDP manager
# to call when it has DDP initialized
set_tensor_model_parallel_rank(args.rank)
return finish_mpu_init
else:
# Megatron's MPU is the master. Complete initialization right away.
finish_mpu_init()
# Autoresume.
_init_autoresume()
# Compile dependencies.
_compile_dependencies()
# No continuation function
return None
3.2 初始化分布式环境
_initialize_distributed 代码位于 megatron/initialize.py,此方法会:
调用 torch.distributed.init_process_group 初始化分布式环境。
调用 mpu.initialize_model_parallel 来设置模型并行,数据并行等各种进程组,我们下文会重点讨论。
创建完worker进程之后,程序需要知道哪些进程在训练同一个模型,torch.distributed.init_process_group 就实现了这个功能。torch.distributed.init_process_group 会生成一个进程组,同组内进程训练同一个模型,也能确定用什么方式进行通信。进程组会给组内每个进程一个序号,就是gloabl rank,如果是多机并行,每个机器创建的进程之间也有一个序号,就是 local rank。如果是单机多卡并行,local rank 和 global rank是一致的。
def _initialize_distributed():
"""Initialize torch.distributed and mpu."""
args = get_args()
device_count = torch.cuda.device_count()
if torch.distributed.is_initialized():
args.rank = torch.distributed.get_rank()
args.world_size = torch.distributed.get_world_size()
else:
# Manually set the device ids.
if device_count > 0:
device = args.rank % device_count
if args.local_rank is not None:
assert args.local_rank == device, \
'expected local-rank to be the same as rank % device-count.'
else:
args.local_rank = device
torch.cuda.set_device(device)
# Call the init process
torch.distributed.init_process_group( # 初始化PyTorch分布式环境
backend=args.distributed_backend,
world_size=args.world_size, rank=args.rank,
timeout=timedelta(minutes=10))
# Set the tensor model-parallel, pipeline model-parallel, and
# data-parallel communicators.
if device_count > 0:
if mpu.model_parallel_is_initialized():
print('model parallel is already initialized')
else:
# 初始化模型并行,比如设置各种进程组
mpu.initialize_model_parallel(args.tensor_model_parallel_size,
args.pipeline_model_parallel_size,
args.virtual_pipeline_model_parallel_size,
args.pipeline_model_parallel_split_rank)
3.3 初始化进程组全局变量
因为调用了 mpu.initialize_model_parallel 来设置模型并行,数据并行等各种进程组,所以我们假定目前进程组都已经设置成功,所以每个 rank 对应的进程都有自己的全局变量。假定目前有16个GPU,属于两个node,rank 0 ~7 属于第一个节点,rank 8 ~ 15 属于第二个节点。下面的 gi 指的是第 i 个 GPU。
_TENSOR_MODEL_PARALLEL_GROUP :当前 rank 所属于的Intra-layer model parallel group,就是tensor 并行进程组。
假如每一层分为两个tensor,则 _TENSOR_MODEL_PARALLEL_GROUP 例子为:[g0, g1], [g2, g3], [g4, g5], [g6, g7], [g8, g9], [g10, g11], [g12, g13], [g14, g15]。
_PIPELINE_MODEL_PARALLEL_GROUP :当前 rank 所属于的Intra-layer model parallel group,就是流水线进程组。
假如流水线深度为4,则例子为 [g0, g4, g8, g12], [g1, g5, g9, g13], [g2, g6, g10, g14], [g3, g7, g11, g15]。
_MODEL_PARALLEL_GROUP :当前 rank 所属于的模型并行进程组,包括了以上两组。
针对我们例子,就是完整模型被复制了两份,两份分别对应的 GPU 具体是[0, 1, 4, 5, 8, 9, 12, 13],[2, 3, 6, 7, 10, 11, 14, 15]
_EMBEDDING_GROUP :嵌入对应的进程组。
_DATA_PARALLEL_GROUP :当前 rank 所属于的Data parallel group。
假如数据并行度数为2,则例子为[g0, g2], [g1, g3], [g4, g6], [g5, g7], [g8, g10], [g9, g11], [g12, g14], [g13, g15]。
# Intra-layer model parallel group that the current rank belongs to.
_TENSOR_MODEL_PARALLEL_GROUP = None
# Inter-layer model parallel group that the current rank belongs to.
_PIPELINE_MODEL_PARALLEL_GROUP = None
# Model parallel group (both intra- and pipeline) that the current rank belongs to.
_MODEL_PARALLEL_GROUP = None
# Embedding group.
_EMBEDDING_GROUP = None
# Data parallel group that the current rank belongs to.
_DATA_PARALLEL_GROUP = None
0x04 设置模型
在 Pretrain 之中,会调用如下来设置模型,优化器等等。
# Model, optimizer, and learning rate. 使用model_provider设置模型、优化器和lr计划
model, optimizer, lr_scheduler = setup_model_and_optimizer(model_provider,
model_type)
4.1 setup_model_and_optimizer
setup_model_and_optimizer 方法会设置模型和优化器,其中重点是get_model。
def setup_model_and_optimizer(model_provider_func, model_type):
"""Setup model and optimizer."""
args = get_args()
model = get_model(model_provider_func, model_type)
unwrapped_model = unwrap_model(model,
(torchDDP, LocalDDP, Float16Module))
optimizer = get_megatron_optimizer(unwrapped_model)
lr_scheduler = get_learning_rate_scheduler(optimizer)
if args.load is not None:
timers = get_timers()
# Extra barrier is added to make sure all ranks report the
# max time.
torch.distributed.barrier()
args.iteration = load_checkpoint(model, optimizer, lr_scheduler)
torch.distributed.barrier()
else:
args.iteration = 0
# We only support local DDP with multiple micro-batches.
if len(model) > 1 or mpu.get_pipeline_model_parallel_world_size() > 1:
assert args.DDP_impl == 'local'
# get model without FP16 and/or TorchDDP wrappers
if args.iteration == 0 and len(unwrapped_model) == 1 \
and hasattr(unwrapped_model[0], 'init_state_dict_from_bert'):
unwrapped_model[0].init_state_dict_from_bert()
if args.fp16:
optimizer.reload_model_params()
return model, optimizer, lr_scheduler
4.2 模型
4.2.1 BertModel
我们首先看看 BertModel 的初始化函数,略过其他功能函数。其主要调用了 get_language_model。
class BertModel(MegatronModule):
"""Bert Language model."""
def __init__(self,
num_tokentypes=2,
add_binary_head=True,
parallel_output=True,
pre_process=True,
post_process=True):
super(BertModel, self).__init__()
args = get_args()
self.fp16_lm_cross_entropy = args.fp16_lm_cross_entropy
self.add_binary_head = add_binary_head
self.parallel_output = parallel_output
self.pre_process = pre_process
self.post_process = post_process
init_method = init_method_normal(args.init_method_std)
scaled_init_method = scaled_init_method_normal(args.init_method_std,
args.num_layers)
# 获取语言模型
self.language_model, self._language_model_key = get_language_model(
num_tokentypes=num_tokentypes,
add_pooler=self.add_binary_head,
encoder_attn_mask_type=AttnMaskType.padding,
init_method=init_method,
scaled_init_method=scaled_init_method,
pre_process=self.pre_process,
post_process=self.post_process)
self.initialize_word_embeddings(init_method_normal)
if self.post_process: # 如果是最后一层,会特殊处理
self.lm_head = BertLMHead(
self.word_embeddings_weight().size(0),
args.hidden_size, init_method, args.layernorm_epsilon, parallel_output)
self._lm_head_key = 'lm_head'
self.binary_head = None
if self.add_binary_head:
self.binary_head = get_linear_layer(args.hidden_size, 2,
init_method)
self._binary_head_key = 'binary_head'
4.2.2 语言模型
get_language_model 会获取一个 TransformerLanguageModel。
def get_language_model(num_tokentypes, add_pooler,
encoder_attn_mask_type, init_method=None,
scaled_init_method=None, add_encoder=True,
add_decoder=False,
decoder_attn_mask_type=AttnMaskType.causal,
pre_process=True, post_process=True):
"""Build language model and return along with the key to save."""
args = get_args()
if init_method is None:
init_method = init_method_normal(args.init_method_std)
if scaled_init_method is None:
scaled_init_method = scaled_init_method_normal(args.init_method_std,
args.num_layers)
# Language model.
language_model = TransformerLanguageModel(
init_method,
scaled_init_method,
encoder_attn_mask_type,
num_tokentypes=num_tokentypes,
add_encoder=add_encoder,
add_decoder=add_decoder,
decoder_attn_mask_type=decoder_attn_mask_type,
add_pooler=add_pooler,
pre_process=pre_process,
post_process=post_process
)
# key used for checkpoints.
language_model_key = 'language_model'
return language_model, language_model_key
TransformerLanguageModel 就是具体的语言模型,其中重要的是 ParallelTransformer。这里会依据传入的配置来进行生成。
如果是第一层,即有 pre_process,则会加入 embedding layer。
如果是中间层,则会根据 encoder 还是 decoder 来生成对应的 ParallelTransformer。
如果是最后一层,即有 post_process,则会加入 Pooler,在外层 BertModel 也会有对应处理。
class TransformerLanguageModel(MegatronModule):
"""Transformer language model.
Arguments:
transformer_hparams: transformer hyperparameters
vocab_size: vocabulary size
max_sequence_length: maximum size of sequence. This
is used for positional embedding
embedding_dropout_prob: dropout probability for embeddings
num_tokentypes: size of the token-type embeddings. 0 value
will ignore this embedding
"""
def __init__(self,
init_method,
output_layer_init_method,
encoder_attn_mask_type,
num_tokentypes=0,
add_encoder=True,
add_decoder=False,
decoder_attn_mask_type=AttnMaskType.causal,
add_pooler=False,
pre_process=True,
post_process=True):
super(TransformerLanguageModel, self).__init__()
args = get_args()
self.pre_process = pre_process
self.post_process = post_process
self.hidden_size = args.hidden_size
self.num_tokentypes = num_tokentypes
self.init_method = init_method
self.add_encoder = add_encoder
self.encoder_attn_mask_type = encoder_attn_mask_type
self.add_decoder = add_decoder
self.decoder_attn_mask_type = decoder_attn_mask_type
self.add_pooler = add_pooler
self.encoder_hidden_state = None
# Embeddings.
if self.pre_process:
self.embedding = Embedding(self.hidden_size,
args.padded_vocab_size,
args.max_position_embeddings,
args.hidden_dropout,
self.init_method,
self.num_tokentypes)
self._embedding_key = 'embedding'
# Transformer.
# Encoder (usually set to True, False if part of an encoder-decoder
# architecture and in encoder-only stage).
if self.add_encoder:
self.encoder = ParallelTransformer(
self.init_method,
output_layer_init_method,
self_attn_mask_type=self.encoder_attn_mask_type,
pre_process=self.pre_process,
post_process=self.post_process
)
self._encoder_key = 'encoder'
else:
self.encoder = None
# Decoder (usually set to False, True if part of an encoder-decoder
# architecture and in decoder-only stage).
if self.add_decoder:
# Temporary assertion until we verify correctness of pipeline parallelism
# implementation of T5.
self.decoder = ParallelTransformer(
self.init_method,
output_layer_init_method,
layer_type=LayerType.decoder,
self_attn_mask_type=self.decoder_attn_mask_type,
pre_process=self.pre_process,
post_process=self.post_process)
self._decoder_key = 'decoder'
else:
self.decoder = None
if self.post_process:
# Pooler.
if self.add_pooler:
self.pooler = Pooler(self.hidden_size, self.init_method)
self._pooler_key = 'pooler'
4.2.3 ParallelTransformer
这里会调用 ParallelTransformerLayer 生成具体的 Transformer层,我们会在后文中进行分析。
即,ParallelTransformer 包括多个 Transformer,其中每层 Transformer 是一个 ParallelTransformerLayer。
class ParallelTransformer(MegatronModule):
"""Transformer class."""
def __init__(self, init_method, output_layer_init_method,
layer_type=LayerType.encoder,
self_attn_mask_type=AttnMaskType.padding,
pre_process=True, post_process=True):
super(ParallelTransformer, self).__init__()
args = get_args()
self.bf16 = args.bf16
self.fp32_residual_connection = args.fp32_residual_connection
self.pre_process = pre_process
self.post_process = post_process
self.input_tensor = None
# Store activation checkpoiting flag.
self.activations_checkpoint_method = args.activations_checkpoint_method
self.activations_checkpoint_num_layers = args.activations_checkpoint_num_layers
self.distribute_checkpointed_activations = args.distribute_checkpointed_activations
# Number of layers.
self.num_layers = mpu.get_num_layers( # 获得本Transformer的具体层数
args, args.model_type == ModelType.encoder_and_decoder)
# Transformer layers.
def build_layer(layer_number):
return ParallelTransformerLayer( # 返回一层 Transformmer
init_method,
output_layer_init_method,
layer_number,
layer_type=layer_type,
self_attn_mask_type=self_attn_mask_type)
if args.virtual_pipeline_model_parallel_size is not None:
# Number of layers in each model chunk is the number of layers in the stage,
# divided by the number of model chunks in a stage.
self.num_layers = self.num_layers // args.virtual_pipeline_model_parallel_size
# With 8 layers, 2 stages, and 4 model chunks, we want an assignment of
# layers to stages like (each list is a model chunk):
# Stage 0: [0] [2] [4] [6]
# Stage 1: [1] [3] [5] [7]
# With 8 layers, 2 stages, and 2 virtual stages, we want an assignment of
# layers to stages like (each list is a model chunk):
# Stage 0: [0, 1] [4, 5]
# Stage 1: [2, 3] [6, 7]
offset = mpu.get_virtual_pipeline_model_parallel_rank() * (
args.num_layers // args.virtual_pipeline_model_parallel_size) + \
(mpu.get_pipeline_model_parallel_rank() * self.num_layers)
else:
# Each stage gets a contiguous set of layers.
offset = mpu.get_pipeline_model_parallel_rank() * self.num_layers
self.layers = torch.nn.ModuleList( # 生成 num_layers 个 Transformer
[build_layer(i + 1 + offset) for i in range(self.num_layers)])
if self.post_process:
# Final layer norm before output.
self.final_layernorm = LayerNorm(
args.hidden_size,
eps=args.layernorm_epsilon,
no_persist_layer_norm=args.no_persist_layer_norm)
目前逻辑如下,我们假定有两个 transformer:
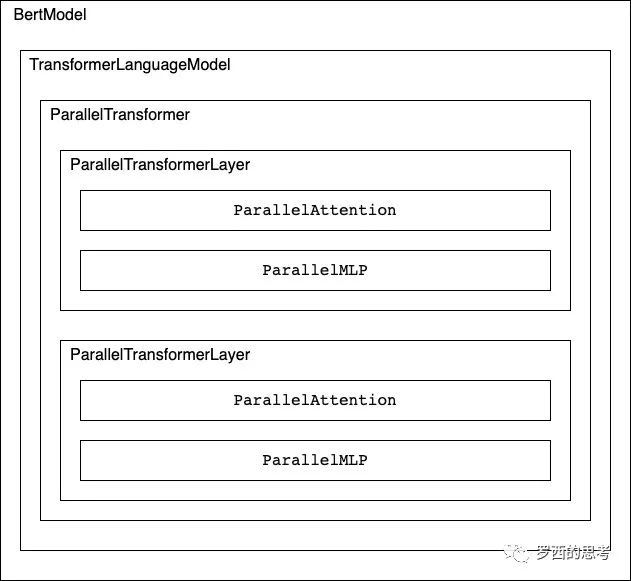
4.2.3.1 获取层数
这里一个重点就是获取层数,即获取本模型在并行处理状况下,应该拥有多少层。如果模型一共64层,流水线深度为16,则并行每个阶段有4层,则本子模型拥有4层。
def get_num_layers(args, is_encoder_and_decoder_model):
"""Compute the number of transformer layers resident on the current rank."""
if get_pipeline_model_parallel_world_size() > 1:
if is_encoder_and_decoder_model:
assert args.pipeline_model_parallel_split_rank is not None
num_ranks_in_encoder = args.pipeline_model_parallel_split_rank
num_ranks_in_decoder = get_pipeline_model_parallel_world_size() - num_ranks_in_encoder
if is_pipeline_stage_before_split():
num_layers = args.num_layers // num_ranks_in_encoder
else:
num_layers = args.num_layers // num_ranks_in_decoder
else:
num_layers = args.num_layers // get_pipeline_model_parallel_world_size()
else:
num_layers = args.num_layers
return num_layers
get_pipeline_model_parallel_world_size 获取本流水线组world size数目,就是流水线深度。
def get_pipeline_model_parallel_world_size():
"""Return world size for the pipeline model parallel group."""
global _MPU_PIPELINE_MODEL_PARALLEL_WORLD_SIZE
if _MPU_PIPELINE_MODEL_PARALLEL_WORLD_SIZE is not None:
return _MPU_PIPELINE_MODEL_PARALLEL_WORLD_SIZE
return torch.distributed.get_world_size(group=get_pipeline_model_parallel_group())
_MPU_PIPELINE_MODEL_PARALLEL_WORLD_SIZE 的意思是流水线深度 p,就是纵向切 p-1刀。比如一共 12 层,纵向切 5 刀,则有 6 个stage,每个 stage 有 2 层。
4.2.3.2 前向传播
我们接着看看其前向传播函数,这里主要就是调用内部 ParallelTransformerLayer 的 forward 方法,如果是第一层或者最后一层,则做特殊处理。
def forward(self, hidden_states, attention_mask,
encoder_output=None, enc_dec_attn_mask=None,
inference_params=None):
if self.pre_process:
# Data format change to avoid explicit tranposes : [b s h] --> [s b h].
# If the input flag for fp32 residual connection is set, convert for float.
if self.fp32_residual_connection:
hidden_states = hidden_states.transpose(0, 1).contiguous().float()
# Otherwise, leave it as is.
else:
hidden_states = hidden_states.transpose(0, 1).contiguous()
else:
# See set_input_tensor()
hidden_states = self.input_tensor
if encoder_output is not None:
encoder_output = encoder_output.transpose(0, 1).contiguous()
if self.activations_checkpoint_method is not None:
hidden_states = self._checkpointed_forward(hidden_states,
attention_mask,
encoder_output,
enc_dec_attn_mask)
else:
for index in range(self.num_layers):
layer = self._get_layer(index)
hidden_states = layer( # 调用ParallelTransformerLayer的forward函数
hidden_states,
attention_mask,
encoder_output=encoder_output,
enc_dec_attn_mask=enc_dec_attn_mask,
inference_params=inference_params)
# Final layer norm.
if self.post_process:
# Reverting data format change [s b h] --> [b s h].
hidden_states = hidden_states.transpose(0, 1).contiguous()
output = self.final_layernorm(hidden_states)
else:
output = hidden_states
return output
4.3 get_model
现在让我们回到 get_model,把生成模型的流程整理出来。
BERT之中含有多个transformer,所以直接按照层数切分,每一层是一模一样的transformer layer。前面提到了,在我们样例之中启动了8个进程,每个进程里面有一个子模型,即原始BERT模型的部分层。但是怎么知道每个子模型包含了多少层?答案是:因为已经建立了各种进程组,所以 get_model 方法会依据目前进程组情况进行处理。单个进程内模型获取如下:
如果是有 virtual 设置,则会遍历 virtual size,生成对应数目的模型(BertModel)。
否则如果是 encoder_and_decoder,则针对split进行配置。
设置 tensor model parallel 属性。
把本模型放置到GPU之上。
如果需要数据并行,则配置DDP。
具体代码如下:
def get_model(model_provider_func, model_type=ModelType.encoder_or_decoder, wrap_with_ddp=True):
"""Build the model."""
args = get_args()
args.model_type = model_type
# Build model.
if mpu.get_pipeline_model_parallel_world_size() > 1 and \
args.virtual_pipeline_model_parallel_size is not None: # 有virtual设置,后续会提到
model = []
for i in range(args.virtual_pipeline_model_parallel_size): # 遍历virtual
# 设置rank,主要是为了看是不是第一层,最后一层
mpu.set_virtual_pipeline_model_parallel_rank(i)
# Set pre_process and post_process only after virtual rank is set.
pre_process = mpu.is_pipeline_first_stage()
post_process = mpu.is_pipeline_last_stage()
this_model = model_provider_func( # 获取原始模型 BertModel
pre_process=pre_process,
post_process=post_process
)
this_model.model_type = model_type
model.append(this_model) # 模型列表之中添加一个新的 BertModel
else:
pre_process = mpu.is_pipeline_first_stage() # 是不是第一层
post_process = mpu.is_pipeline_last_stage() # 是不是最后一层
add_encoder = True
add_decoder = True
if model_type == ModelType.encoder_and_decoder:
if mpu.get_pipeline_model_parallel_world_size() > 1:
rank = mpu.get_pipeline_model_parallel_rank()
split_rank = args.pipeline_model_parallel_split_rank
world_size = mpu.get_pipeline_model_parallel_world_size()
pre_process = rank == 0 or rank == split_rank # 是不是第一层
post_process = (rank == (split_rank - 1)) or ( # 是不是最后一层
rank == (world_size - 1))
add_encoder = mpu.is_pipeline_stage_before_split()
add_decoder = mpu.is_pipeline_stage_after_split()
model = model_provider_func( # 获取原始模型
pre_process=pre_process,
post_process=post_process,
add_encoder=add_encoder,
add_decoder=add_decoder)
else:
model = model_provider_func( # 获取原始模型
pre_process=pre_process,
post_process=post_process
)
model.model_type = model_type
if not isinstance(model, list):
model = [model]
# Set tensor model parallel attributes if not set.
# Only parameters that are already tensor model parallel have these
# attributes set for them. We should make sure the default attributes
# are set for all params so the optimizer can use them.
for model_module in model:
for param in model_module.parameters():
mpu.set_defaults_if_not_set_tensor_model_parallel_attributes(param)
# GPU allocation.
for model_module in model: # 把本模型放置到GPU之上
model_module.cuda(torch.cuda.current_device())
# Fp16 conversion.
if args.fp16 or args.bf16:
model = [Float16Module(model_module, args) for model_module in model]
if wrap_with_ddp: # 如果需要数据并行,则配置DDP
if args.DDP_impl == 'torch':
i = torch.cuda.current_device()
model = [torchDDP(model_module, device_ids=[i], output_device=i,
process_group=mpu.get_data_parallel_group())
for model_module in model]
elif args.DDP_impl == 'local':
model = [LocalDDP(model_module,
args.accumulate_allreduce_grads_in_fp32,
args.use_contiguous_buffers_in_local_ddp)
for model_module in model]
else:
raise NotImplementedError('Unknown DDP implementation specified: '
'{}. Exiting.'.format(args.DDP_impl))
return model
单个进程内的逻辑大致如下,这里 torchDDP 的意思是把 BertModel 之中的 module 用 torchDDP 来封装。
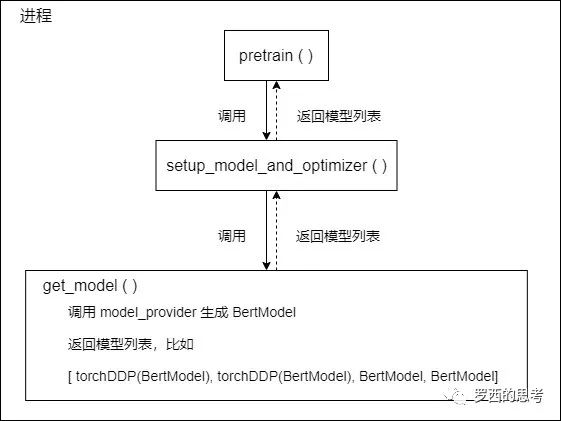
0x05 数据并行
5.1 设置数据
build_train_valid_test_data_iterators 方法会对数据进行处理,提供了 train,valid,test 三种不同的数据集。
def build_train_valid_test_data_iterators(
build_train_valid_test_datasets_provider):
"""XXX"""
args = get_args()
(train_dataloader, valid_dataloader, test_dataloader) = (None, None, None)
# Backward compatibility, assume fixed batch size.
if args.iteration > 0 and args.consumed_train_samples == 0:
args.consumed_train_samples = args.iteration * args.global_batch_size
if args.iteration > 0 and args.consumed_valid_samples == 0:
if args.train_samples is None:
args.consumed_valid_samples = (args.iteration // args.eval_interval) * \
args.eval_iters * args.global_batch_size
# Data loader only on rank 0 of each model parallel group.
if mpu.get_tensor_model_parallel_rank() == 0:
# Number of train/valid/test samples.
if args.train_samples:
train_samples = args.train_samples
else:
train_samples = args.train_iters * args.global_batch_size
eval_iters = (args.train_iters // args.eval_interval + 1) * \
args.eval_iters
test_iters = args.eval_iters
train_val_test_num_samples = [train_samples,
eval_iters * args.global_batch_size,
test_iters * args.global_batch_size]
# Build the datasets.
train_ds, valid_ds, test_ds = build_train_valid_test_datasets_provider(
train_val_test_num_samples)
# Build dataloders.
train_dataloader = build_pretraining_data_loader(
train_ds, args.consumed_train_samples)
valid_dataloader = build_pretraining_data_loader(
valid_ds, args.consumed_valid_samples)
test_dataloader = build_pretraining_data_loader(test_ds, 0)
# Flags to know if we need to do training/validation/testing.
do_train = train_dataloader is not None and args.train_iters > 0
do_valid = valid_dataloader is not None and args.eval_iters > 0
do_test = test_dataloader is not None and args.eval_iters > 0
# Need to broadcast num_tokens and num_type_tokens.
flags = torch.cuda.LongTensor(
[int(do_train), int(do_valid), int(do_test)])
else:
flags = torch.cuda.LongTensor([0, 0, 0])
# Broadcast num tokens.
torch.distributed.broadcast(flags,
mpu.get_tensor_model_parallel_src_rank(),
group=mpu.get_tensor_model_parallel_group())
args.do_train = flags[0].item()
args.do_valid = flags[1].item()
args.do_test = flags[2].item()
# Build iterators.
dl_type = args.dataloader_type
if train_dataloader is not None:
train_data_iterator = iter(train_dataloader) if dl_type == 'single' \
else iter(cyclic_iter(train_dataloader))
else:
train_data_iterator = None
if valid_dataloader is not None:
valid_data_iterator = iter(valid_dataloader) if dl_type == 'single' \
else iter(cyclic_iter(valid_dataloader))
else:
valid_data_iterator = None
if test_dataloader is not None:
test_data_iterator = iter(test_dataloader) if dl_type == 'single' \
else iter(cyclic_iter(test_dataloader))
else:
test_data_iterator = None
return train_data_iterator, valid_data_iterator, test_data_iterator
5.2 DDP
在 get_model 之中,有如下代码使用 DDP。
from megatron.model import DistributedDataParallel as LocalDDP
from torch.nn.parallel.distributed import DistributedDataParallel as torchDDP
if wrap_with_ddp:
if args.DDP_impl == 'torch':
i = torch.cuda.current_device()
model = [torchDDP(model_module, device_ids=[i], output_device=i,
process_group=mpu.get_data_parallel_group())
for model_module in model]
elif args.DDP_impl == 'local':
model = [LocalDDP(model_module,
args.accumulate_allreduce_grads_in_fp32,
args.use_contiguous_buffers_in_local_ddp)
for model_module in model]
else:
raise NotImplementedError('Unknown DDP implementation specified: '
'{}. Exiting.'.format(args.DDP_impl))
所以我们看看 megatron 自己的 DDP实现。
5.2.1 定义
定义只有注释可以看看,使用连续的(contiguous)内存来存储和累积梯度,每一种类型的张量属于一个统一的内存,可以统一做 allreduce。
class DistributedDataParallel(DistributedDataParallelBase):
"""DDP with contiguous buffers options to storre and accumulate gradients.
This class:
- has the potential to reduce memory fragmentation.
- provides the option to do the gradient accumulation
in a type other than the params type (for example fp32)
Arguments:
module: input model.
accumulate_allreduce_grads_in_fp32: if true do the gradient accumulation
and the gradient all-reduce all in in float32. If this option is
true, we require `use_contiguous_buffers` to be true too.
use_contiguous_buffers: if true, use a contiguous buffer to store the
gradients.
"""
5.2.2 初始化
初始化方法的目的是把同类型梯度连续存储。
def __init__(self, module,
accumulate_allreduce_grads_in_fp32,
use_contiguous_buffers):
super(DistributedDataParallel, self).__init__(module)
self.accumulate_allreduce_grads_in_fp32 \
= accumulate_allreduce_grads_in_fp32
self.use_contiguous_buffers = use_contiguous_buffers
# If we are using fp32-accumulate-allreduce explicitly
# this means we need main grads in a continous buffer.
if self.accumulate_allreduce_grads_in_fp32:
assert self.use_contiguous_buffers
# ===================================
# Rest of this part applies only to
# the case we use continuous buffers.
# ===================================
self._grad_buffers = None
if self.use_contiguous_buffers: # 这里只考虑连续内存
self._grad_buffers = {} # 定义buffer
# Simple function to define buffer type.
def _get_buffer_type(param): # 返回buffer类型
return torch.float if \
self.accumulate_allreduce_grads_in_fp32 else param.dtype
# First calculate total number of elements per type.
type_num_elements = {}
for param in self.module.parameters(): # 遍历模型参数
if param.requires_grad: # 如果需要计算梯度
dtype = _get_buffer_type(param) # 获取参数类型
type_num_elements[dtype] = type_num_elements.get(dtype, 0) \
+ param.data.nelement() # 该类型参数数目做相应增加
# 目前 type_num_elements 是各种类型参数的个数
# Allocate the buffer.
for dtype, num_elements in type_num_elements.items(): # 遍历各种类型
self._grad_buffers[dtype] = MemoryBuffer(num_elements, dtype) # 分配内存
# 这里是假定反向传播是参数的反方向,存储每个参数梯度的起始位置
# Assume the back prop order is reverse the params order,
# store the start index for the gradients.
for param in self.module.parameters(): # 遍历模型参数
if param.requires_grad: # 如果需要计算梯度
dtype = _get_buffer_type(param) # 获取参数类型
type_num_elements[dtype] -= param.data.nelement() # 减少size
# 确定该参数在MemoryBuffer的位置
param.main_grad = self._grad_buffers[dtype].get( # 获取该参数对应的内存
param.data.shape, type_num_elements[dtype])
# Backward hook.
# Accumalation function for the gradients. We need
# to store them so they don't go out of scope.
self.grad_accs = []
# Loop over all the parameters in the model.
for param in self.module.parameters(): # 遍历模型参数
if param.requires_grad: # 如果需要计算梯度
# Expand so we get access to grad_fn.
param_tmp = param.expand_as(param)
# Get the gradient accumulator functtion.
grad_acc = param_tmp.grad_fn.next_functions[0][0] # 得到参数对应的梯度函数
grad_acc.register_hook(self._make_param_hook(param)) # 注册了hook
self.grad_accs.append(grad_acc) # 统一管理梯度函数,其实就是book keeping作用
5.2.3 内存
MemoryBuffer 是内存抽象。
class MemoryBuffer:
def __init__(self, numel, dtype):
self.numel = numel
self.dtype = dtype
self.data = torch.zeros(self.numel, # 初始化内存
dtype=self.dtype,
device=torch.cuda.current_device(),
requires_grad=False)
def zero(self):
"""Reset the buffer to zero."""
self.data.zero_()
def get(self, shape, start_index):
"""Return a tensor with the input `shape` as a view into the
1-D data starting at `start_index`."""
end_index = start_index + shape.numel() # 定位到该张量在内存buffer之中的位置
assert end_index <= self.numel, \
'requested tensor is out of the buffer range.'
buffer_tensor = self.data[start_index:end_index] # 拿到内存
buffer_tensor = buffer_tensor.view(shape)
return buffer_tensor #
5.2.4 支撑函数
下面是两个支撑函数,分别是用于拷贝梯度和将buffer清零。
def _make_param_hook(self, param):
"""Create the all-reduce hook for backprop."""
# Hook used for back-prop.
def param_hook(*unused):
# Add the gradient to the buffer.
if param.grad.data is not None:
param.main_grad.add_(param.grad.data) # 把梯度拷贝到连续内存之中
# Now we can deallocate grad memory.
param.grad = None
return param_hook
def zero_grad_buffer(self):
"""Set the grad buffer data to zero. Needs to be called at the
begining of each iteration."""
assert self._grad_buffers is not None, 'buffers are not initialized.'
for _, buffer_ in self._grad_buffers.items():
buffer_.zero()
我们假定模型有6个参数,3个 fp32,3 个 fp16,所以被组合成两个连续内存 MemoryBuffer。
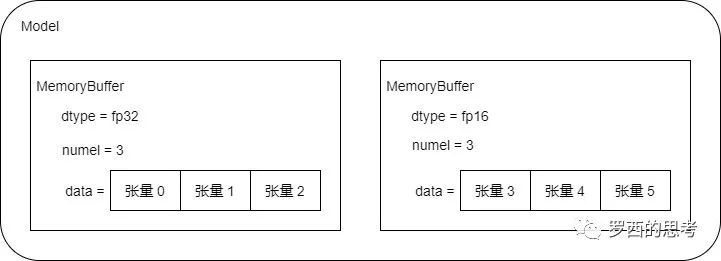
5.2.5 梯度规约
allreduce_gradients 是 DDP 对外提供的 API,在后面 train step 之中会调用到。
def allreduce_gradients(self):
"""Reduce gradients across data parallel ranks."""
# If we have buffers, simply reduce the data in the buffer.
if self._grad_buffers is not None:
# 连续内存
for _, buffer_ in self._grad_buffers.items(): # 遍历各种类型的buffer
buffer_.data /= mpu.get_data_parallel_world_size()
torch.distributed.all_reduce( # 统一归并
buffer_.data, group=mpu.get_data_parallel_group())
else:
# Otherwise, bucketize and all-reduce
buckets = {} # 否则还是用桶来归并
# Pack the buckets.
for param in self.module.parameters(): # 遍历梯度
if param.requires_grad and param.grad is not None:
tp = param.data.type()
if tp not in buckets:
buckets[tp] = []
buckets[tp].append(param) # 同类型的梯度放到对应类型的桶之中
param.main_grad = param.grad
# For each bucket, all-reduce and copy all-reduced grads.
for tp in buckets:
bucket = buckets[tp]
grads = [param.grad.data for param in bucket] # 把桶里的梯度拿出来
coalesced = _flatten_dense_tensors(grads) # 打平梯度
coalesced /= mpu.get_data_parallel_world_size()
torch.distributed.all_reduce( # 归并
coalesced, group=mpu.get_data_parallel_group())
for buf, synced in zip(grads, _unflatten_dense_tensors(
coalesced, grads)):
buf.copy_(synced)
运行时候,分别对两种类型的连续内存做 AllReduce。
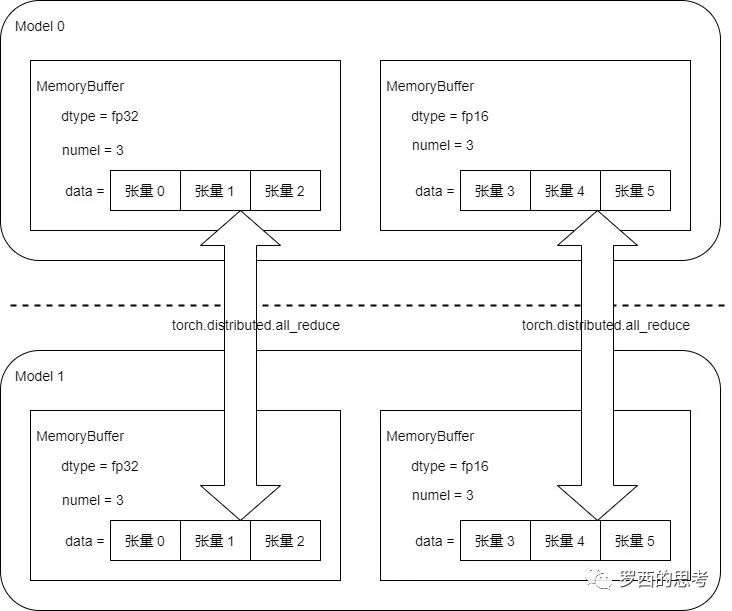
0x06 训练
Pretrain 之中会调用 train 来进行训练。
if args.do_train and args.train_iters > 0:
iteration = train(forward_step_func,
model, optimizer, lr_scheduler,
train_data_iterator, valid_data_iterator)
6.1 训练主体
train 是常规的套路,大家基本上按照名字就可以理解。
def train(forward_step_func, model, optimizer, lr_scheduler,
train_data_iterator, valid_data_iterator):
"""Train the model function."""
args = get_args()
timers = get_timers()
# Write args to tensorboard
write_args_to_tensorboard()
# Turn on training mode which enables dropout.
for model_module in model:
model_module.train() #
# Tracking loss.
total_loss_dict = {}
# Iterations.
iteration = args.iteration
report_memory_flag = True
while iteration < args.train_iters:
update_num_microbatches(args.consumed_train_samples)
loss_dict, skipped_iter, grad_norm, num_zeros_in_grad = \
train_step(forward_step_func, # 训练
train_data_iterator,
model,
optimizer,
lr_scheduler)
iteration += 1
args.consumed_train_samples += mpu.get_data_parallel_world_size() * \
args.micro_batch_size * \
get_num_microbatches()
# Logging.
loss_scale = optimizer.get_loss_scale().item()
params_norm = None
if args.log_params_norm:
params_norm = calc_params_l2_norm(model)
report_memory_flag = training_log(loss_dict, total_loss_dict,
optimizer.param_groups[0]['lr'],
iteration, loss_scale,
report_memory_flag, skipped_iter,
grad_norm, params_norm, num_zeros_in_grad)
# Autoresume
if args.adlr_autoresume and \
(iteration % args.adlr_autoresume_interval == 0):
check_adlr_autoresume_termination(iteration, model, optimizer,
lr_scheduler)
# Evaluation
if args.eval_interval and iteration % args.eval_interval == 0 and \
args.do_valid:
prefix = 'iteration {}'.format(iteration)
evaluate_and_print_results(prefix, forward_step_func,
valid_data_iterator, model,
iteration, False)
# Checkpointing
saved_checkpoint = False
if args.exit_signal_handler:
signal_handler = get_signal_handler()
if any(signal_handler.signals_received()):
save_checkpoint_and_time(iteration, model, optimizer,
lr_scheduler)
sys.exit()
if args.save and args.save_interval and \
iteration % args.save_interval == 0:
save_checkpoint_and_time(iteration, model, optimizer,
lr_scheduler)
saved_checkpoint = True
# Exiting based on duration
if args.exit_duration_in_mins:
train_time = (time.time() - _TRAIN_START_TIME) / 60.0
done_cuda = torch.cuda.IntTensor(
[train_time > args.exit_duration_in_mins])
torch.distributed.all_reduce(
done_cuda, op=torch.distributed.ReduceOp.MAX)
done = done_cuda.item()
if done:
if not saved_checkpoint:
save_checkpoint_and_time(iteration, model, optimizer,
lr_scheduler)
sys.exit()
# Exiting based on iterations
if args.exit_interval and iteration % args.exit_interval == 0:
if not saved_checkpoint:
save_checkpoint_and_time(iteration, model, optimizer,
lr_scheduler)
torch.distributed.barrier()
sys.exit()
return iteration
6.2 训练step
train_step 会获取 get_forward_backward_func 得到 schedule,因为是流水线并行,所以需要 schedule 如何具体训练。
def train_step(forward_step_func, data_iterator,
model, optimizer, lr_scheduler):
"""Single training step."""
args = get_args()
timers = get_timers()
# Set grad to zero.
if args.DDP_impl == 'local' and args.use_contiguous_buffers_in_local_ddp:
for partition in model:
partition.zero_grad_buffer()
optimizer.zero_grad()
# 获取训练schedule
forward_backward_func = get_forward_backward_func()
losses_reduced = forward_backward_func( # 进行训练
forward_step_func, data_iterator, model,
optimizer, timers, forward_only=False)
# Empty unused memory
if args.empty_unused_memory_level >= 1:
torch.cuda.empty_cache()
# All-reduce if needed.
if args.DDP_impl == 'local':
for model_module in model:
model_module.allreduce_gradients()
# All-reduce word_embeddings' grad across first and last stages to ensure
# that word_embeddings parameters stay in sync.
# This should only run for models that support pipelined model parallelism
# (BERT and GPT-2).
if mpu.is_rank_in_embedding_group(ignore_virtual=True) and \
mpu.get_pipeline_model_parallel_world_size() > 1:
if mpu.is_pipeline_first_stage(ignore_virtual=True):
unwrapped_model = model[0]
elif mpu.is_pipeline_last_stage(ignore_virtual=True):
unwrapped_model = model[-1]
else: # We do not support the interleaved schedule for T5 yet.
unwrapped_model = model[0]
unwrapped_model = unwrap_model(
unwrapped_model, (torchDDP, LocalDDP, Float16Module))
if unwrapped_model.share_word_embeddings:
word_embeddings_weight = unwrapped_model.word_embeddings_weight()
if args.DDP_impl == 'local':
grad = word_embeddings_weight.main_grad
else:
grad = word_embeddings_weight.grad
torch.distributed.all_reduce(grad, group=mpu.get_embedding_group())
# Update parameters.
update_successful, grad_norm, num_zeros_in_grad = optimizer.step()
# Update learning rate.
if update_successful:
increment = get_num_microbatches() * \
args.micro_batch_size * \
args.data_parallel_size
lr_scheduler.step(increment=increment)
skipped_iter = 0
else:
skipped_iter = 1
# Empty unused memory
if args.empty_unused_memory_level >= 2:
torch.cuda.empty_cache()
if mpu.is_pipeline_last_stage(ignore_virtual=True):
# Average loss across microbatches.
loss_reduced = {}
for key in losses_reduced[0]:
losses_reduced_for_key = [x[key] for x in losses_reduced]
loss_reduced[key] = sum(losses_reduced_for_key) / len(losses_reduced_for_key)
return loss_reduced, skipped_iter, grad_norm, num_zeros_in_grad
return {}, skipped_iter, grad_norm, num_zeros_in_grad
6.3 获取schedule
get_forward_backward_func 获取 pipeline 的schedule,这里分为 flush 和 interleaving 两种,我们后续会分析这两种schedule。
def get_forward_backward_func():
args = get_args()
if mpu.get_pipeline_model_parallel_world_size() > 1:
if args.virtual_pipeline_model_parallel_size is not None:
forward_backward_func = forward_backward_pipelining_with_interleaving
else:
forward_backward_func = forward_backward_pipelining_without_interleaving
else:
forward_backward_func = forward_backward_no_pipelining
return forward_backward_func
训练逻辑大体拓展为:
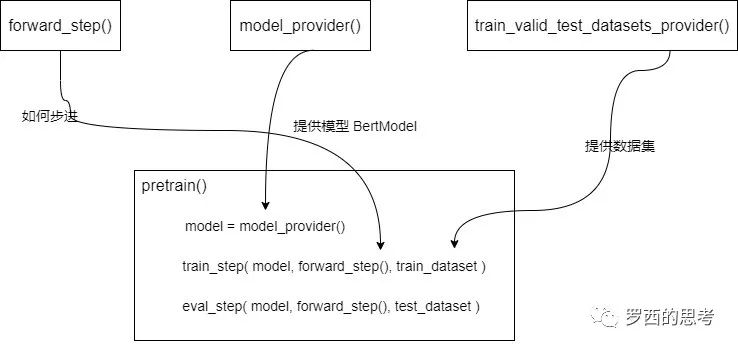
至此,Megatron 基本架构分析完毕,下一篇我们介绍模型并行设置。
0xFF 参考
[细读经典]Megatron论文和代码详细分析(2)
[细读经典]Megatron论文和代码详细分析(1)
Megatron-LM源码阅读(一)
Megatron-LM源码阅读(二)
megatron学习总结
GTC 2020: Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
www.DeepL.com/Translator
https://developer.nvidia.com/gtc/2020/slides/s21496-megatron-lm-training-multi-billion-parameter-language-models-using-model-parallelism.pdf
NVIDIA解决方案架构师深度解析大规模参数语言模型Megatron-BERT