
Python 中组合分类和回归的神经网络模型
一些预测问题需要为每个输入示例预测数字和类别标签值。 如何针对需要多个输出的问题开发单独的回归和分类模型。 如何开发和评估能够同时进行回归和分类预测的神经网络模型。
回归和分类的单一模型 单独的回归和分类模型 鲍鱼数据集 回归模型 分类模型 组合回归和分类模型
# load and summarize the abalone dataset
from pandas import read_csv
from matplotlib import pyplot
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/abalone.csv'
dataframe = read_csv(url, header=None)
# summarize shape
print(dataframe.shape)
# summarize first few lines
print(dataframe.head())
(4177, 9)
012345678
0 M 0.4550.3650.0950.51400.22450.10100.15015
1 M 0.3500.2650.0900.22550.09950.04850.0707
2 F 0.5300.4200.1350.67700.25650.14150.2109
3 M 0.4400.3650.1250.51600.21550.11400.15510
4 I 0.3300.2550.0800.20500.08950.03950.0557
# split into input (X) and output (y) variables
X, y = dataset[:, 1:-1], dataset[:, -1]
X, y = X.astype('float'), y.astype('float')
n_features = X.shape[1]
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
# define the keras model
model = Sequential()
model.add(Dense(20, input_dim=n_features, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(10, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(1, activation='linear'))
# compile the keras model
model.compile(loss='mse', optimizer='adam')
# fit the keras model on the dataset
model.fit(X_train, y_train, epochs=150, batch_size=32, verbose=2)
# evaluate on test set
yhat = model.predict(X_test)
error = mean_absolute_error(y_test, yhat)
print('MAE: %.3f'% error)
# regression mlp model for the abalone dataset
from pandas import read_csv
from tensorflow.keras.models importSequential
from tensorflow.keras.layers importDense
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/abalone.csv'
dataframe = read_csv(url, header=None)
dataset = dataframe.values
# split into input (X) and output (y) variables
X, y = dataset[:, 1:-1], dataset[:, -1]
X, y = X.astype('float'), y.astype('float')
n_features = X.shape[1]
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
# define the keras model
model = Sequential()
model.add(Dense(20, input_dim=n_features, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(10, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(1, activation='linear'))
# compile the keras model
model.compile(loss='mse', optimizer='adam')
# fit the keras model on the dataset
model.fit(X_train, y_train, epochs=150, batch_size=32, verbose=2)
# evaluate on test set
yhat = model.predict(X_test)
error = mean_absolute_error(y_test, yhat)
print('MAE: %.3f'% error)
Epoch145/150
88/88- 0s- loss: 4.6130
Epoch146/150
88/88- 0s- loss: 4.6182
Epoch147/150
88/88- 0s- loss: 4.6277
Epoch148/150
88/88- 0s- loss: 4.6437
Epoch149/150
88/88- 0s- loss: 4.6166
Epoch150/150
88/88- 0s- loss: 4.6132
MAE: 1.554
# encode strings to integer
y = LabelEncoder().fit_transform(y)
n_class = len(unique(y))
# define the keras model
model = Sequential()
model.add(Dense(20, input_dim=n_features, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(10, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(n_class, activation='softmax'))
# compile the keras model
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')
# evaluate on test set
yhat = model.predict(X_test)
yhat = argmax(yhat, axis=-1).astype('int')
acc = accuracy_score(y_test, yhat)
print('Accuracy: %.3f'% acc)
# classification mlp model for the abalone dataset
from numpy import unique
from numpy import argmax
from pandas import read_csv
from tensorflow.keras.models importSequential
from tensorflow.keras.layers importDense
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing importLabelEncoder
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/abalone.csv'
dataframe = read_csv(url, header=None)
dataset = dataframe.values
# split into input (X) and output (y) variables
X, y = dataset[:, 1:-1], dataset[:, -1]
X, y = X.astype('float'), y.astype('float')
n_features = X.shape[1]
# encode strings to integer
y = LabelEncoder().fit_transform(y)
n_class = len(unique(y))
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
# define the keras model
model = Sequential()
model.add(Dense(20, input_dim=n_features, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(10, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(n_class, activation='softmax'))
# compile the keras model
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')
# fit the keras model on the dataset
model.fit(X_train, y_train, epochs=150, batch_size=32, verbose=2)
# evaluate on test set
yhat = model.predict(X_test)
yhat = argmax(yhat, axis=-1).astype('int')
acc = accuracy_score(y_test, yhat)
print('Accuracy: %.3f'% acc)
Epoch145/150
88/88- 0s- loss: 1.9271
Epoch146/150
88/88- 0s- loss: 1.9265
Epoch147/150
88/88- 0s- loss: 1.9265
Epoch148/150
88/88- 0s- loss: 1.9271
Epoch149/150
88/88- 0s- loss: 1.9262
Epoch150/150
88/88- 0s- loss: 1.9260
Accuracy: 0.274
# encode strings to integer
y_class = LabelEncoder().fit_transform(y)
n_class = len(unique(y_class))
# split data into train and test sets
X_train, X_test, y_train, y_test, y_train_class, y_test_class = train_test_split(X, y, y_class, test_size=0.33, random_state=1)
# input
visible = Input(shape=(n_features,))
hidden1 = Dense(20, activation='relu', kernel_initializer='he_normal')(visible)
hidden2 = Dense(10, activation='relu', kernel_initializer='he_normal')(hidden1)
# regression output
out_reg = Dense(1, activation='linear')(hidden2)
# classification output
out_clas = Dense(n_class, activation='softmax')(hidden2)
# define model
model = Model(inputs=visible, outputs=[out_reg, out_clas])
# compile the keras model
model.compile(loss=['mse','sparse_categorical_crossentropy'], optimizer='adam')
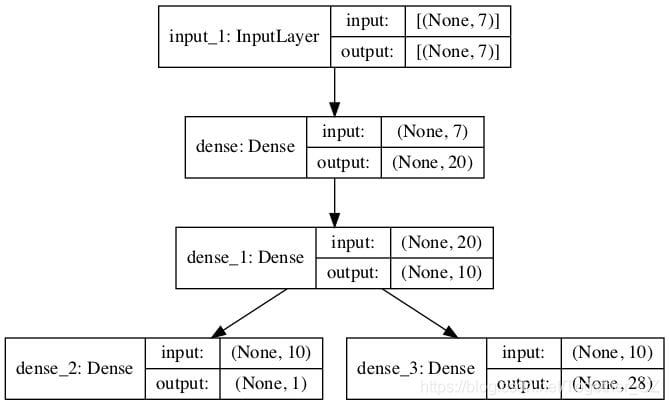
plot_model()函数的import语句。
# plot graph of model
plot_model(model, to_file='model.png', show_shapes=True)
# fit the keras model on the dataset
model.fit(X_train, [y_train,y_train_class], epochs=150, batch_size=32, verbose=2)
# make predictions on test set
yhat1, yhat2 = model.predict(X_test)
# calculate error for regression model
error = mean_absolute_error(y_test, yhat1)
print('MAE: %.3f'% error)
# evaluate accuracy for classification model
yhat2 = argmax(yhat2, axis=-1).astype('int')
acc = accuracy_score(y_test_class, yhat2)
print('Accuracy: %.3f'% acc)
# mlp for combined regression and classification predictions on the abalone dataset
from numpy import unique
from numpy import argmax
from pandas import read_csv
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing importLabelEncoder
from tensorflow.keras.models importModel
from tensorflow.keras.layers importInput
from tensorflow.keras.layers importDense
from tensorflow.keras.utils import plot_model
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/abalone.csv'
dataframe = read_csv(url, header=None)
dataset = dataframe.values
# split into input (X) and output (y) variables
X, y = dataset[:, 1:-1], dataset[:, -1]
X, y = X.astype('float'), y.astype('float')
n_features = X.shape[1]
# encode strings to integer
y_class = LabelEncoder().fit_transform(y)
n_class = len(unique(y_class))
# split data into train and test sets
X_train, X_test, y_train, y_test, y_train_class, y_test_class = train_test_split(X, y, y_class, test_size=0.33, random_state=1)
# input
visible = Input(shape=(n_features,))
hidden1 = Dense(20, activation='relu', kernel_initializer='he_normal')(visible)
hidden2 = Dense(10, activation='relu', kernel_initializer='he_normal')(hidden1)
# regression output
out_reg = Dense(1, activation='linear')(hidden2)
# classification output
out_clas = Dense(n_class, activation='softmax')(hidden2)
# define model
model = Model(inputs=visible, outputs=[out_reg, out_clas])
# compile the keras model
model.compile(loss=['mse','sparse_categorical_crossentropy'], optimizer='adam')
# plot graph of model
plot_model(model, to_file='model.png', show_shapes=True)
# fit the keras model on the dataset
model.fit(X_train, [y_train,y_train_class], epochs=150, batch_size=32, verbose=2)
# make predictions on test set
yhat1, yhat2 = model.predict(X_test)
# calculate error for regression model
error = mean_absolute_error(y_test, yhat1)
print('MAE: %.3f'% error)
# evaluate accuracy for classification model
yhat2 = argmax(yhat2, axis=-1).astype('int')
acc = accuracy_score(y_test_class, yhat2)
print('Accuracy: %.3f'% acc)
Epoch145/150
88/88- 0s- loss: 6.5707- dense_2_loss: 4.5396- dense_3_loss: 2.0311
Epoch146/150
88/88- 0s- loss: 6.5753- dense_2_loss: 4.5466- dense_3_loss: 2.0287
Epoch147/150
88/88- 0s- loss: 6.5970- dense_2_loss: 4.5723- dense_3_loss: 2.0247
Epoch148/150
88/88- 0s- loss: 6.5640- dense_2_loss: 4.5389- dense_3_loss: 2.0251
Epoch149/150
88/88- 0s- loss: 6.6053- dense_2_loss: 4.5827- dense_3_loss: 2.0226
Epoch150/150
88/88- 0s- loss: 6.5754- dense_2_loss: 4.5524- dense_3_loss: 2.0230
MAE: 1.495
Accuracy: 0.256
作者:沂水寒城,CSDN博客专家,个人研究方向:机器学习、深度学习、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
赞 赏 作 者




点击下方阅读原文加入社区会员