
playwright网络爬虫实战案例分享
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是Python进阶者。
一、前言
前几天在Python白银交流群【HugoLB】分享了一个playwright网络爬虫利器,如下图所示。
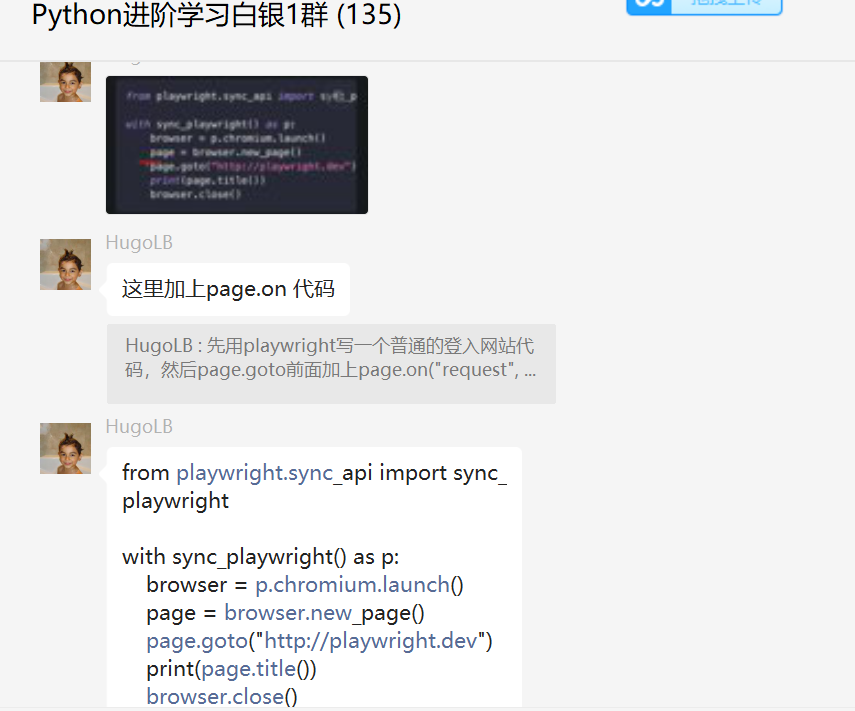
感觉挺有意思,上手难度也不算太大,这里整理一份小教程分享给大家,后面遇到常规爬不动的网站,不妨试试看这个利器,兴许会事半功倍哦!
二、实现过程
这里使用新发地网站做一个简单的示例,新发地网站最开始的时候是get请求,去年的时候开始使用post请求方式,网页发生了变化,其实你正常使用网络爬虫的常规方式,也是可以获取到数据的,而且效率也很高,这里我是为了给大家做一个playwright网络爬虫示例,拿这个网站小试下牛刀。言归正传,一起来看看吧!
新发地网站的首页如下图所示:
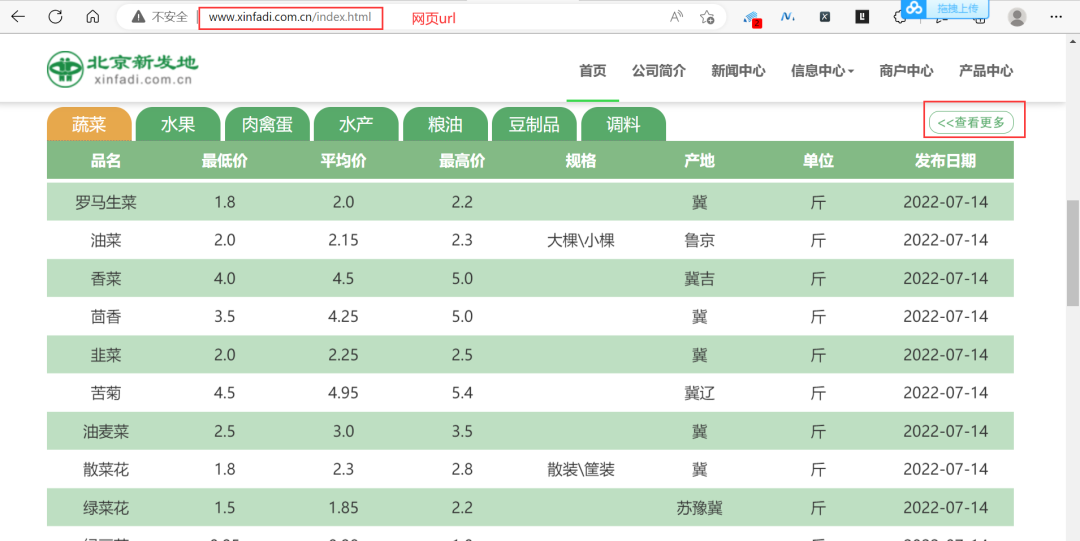
进入网页之后,可以看到网页的url,然后点击右侧的查看更多,即可进入到详情页,如下图所示:
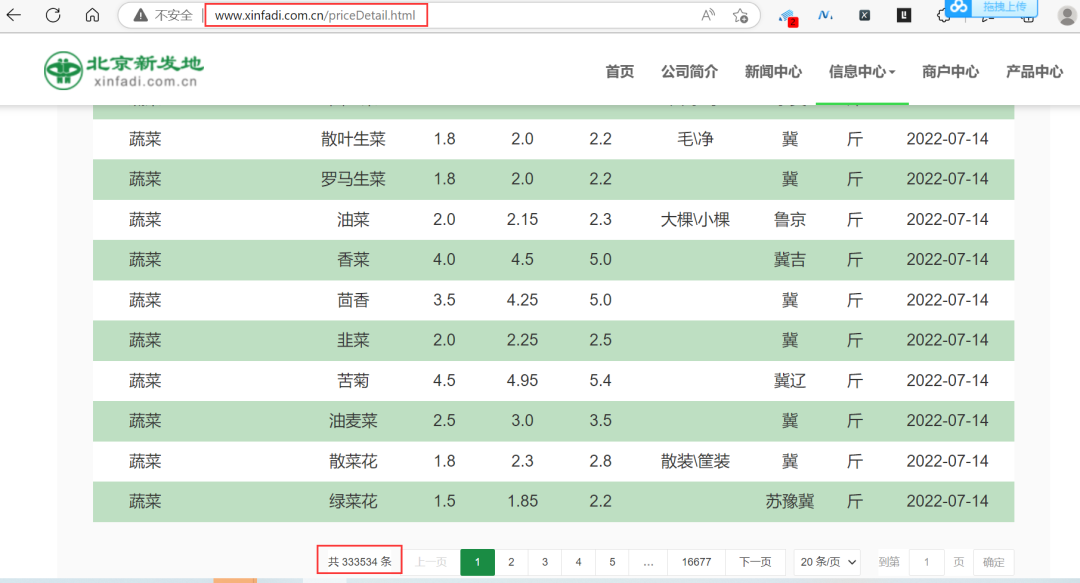
此时可以看得到更多的数据量了,这里只是用一两个页面做一个示例,更多的页面等大家自己去挖掘。
启动浏览器抓包,点击网页的下一页,可以看到响应数据如下图所示:
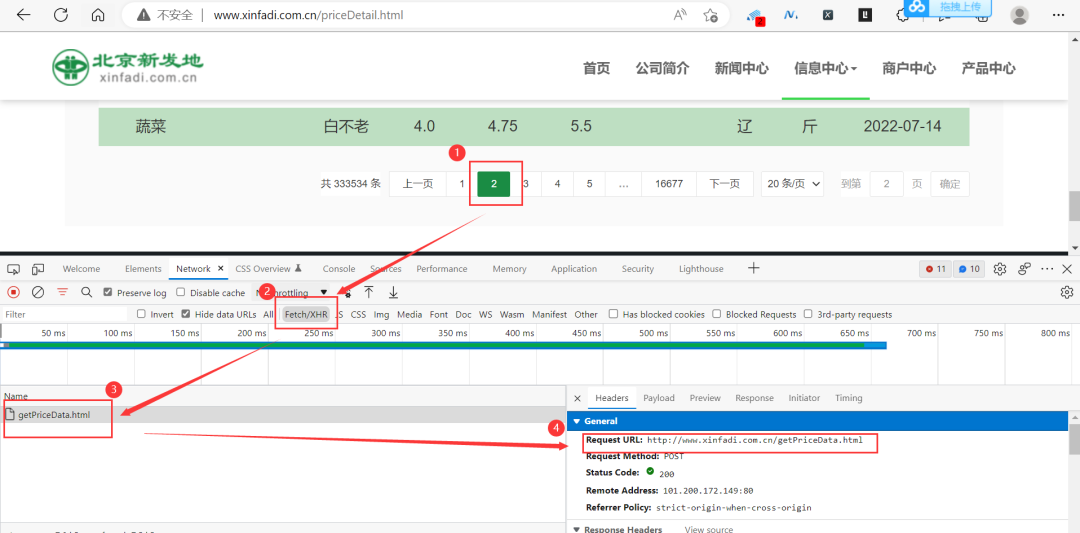
此时的请求参数如下图所示:
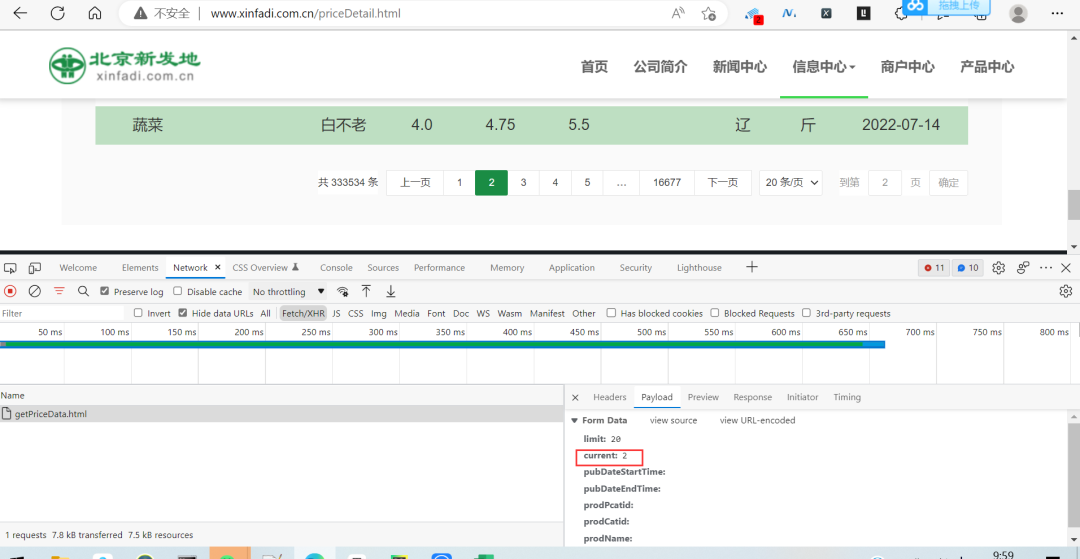
依次再点击下一页,可以看到Request URL是不变的,变化的是Payload里边的current参数。
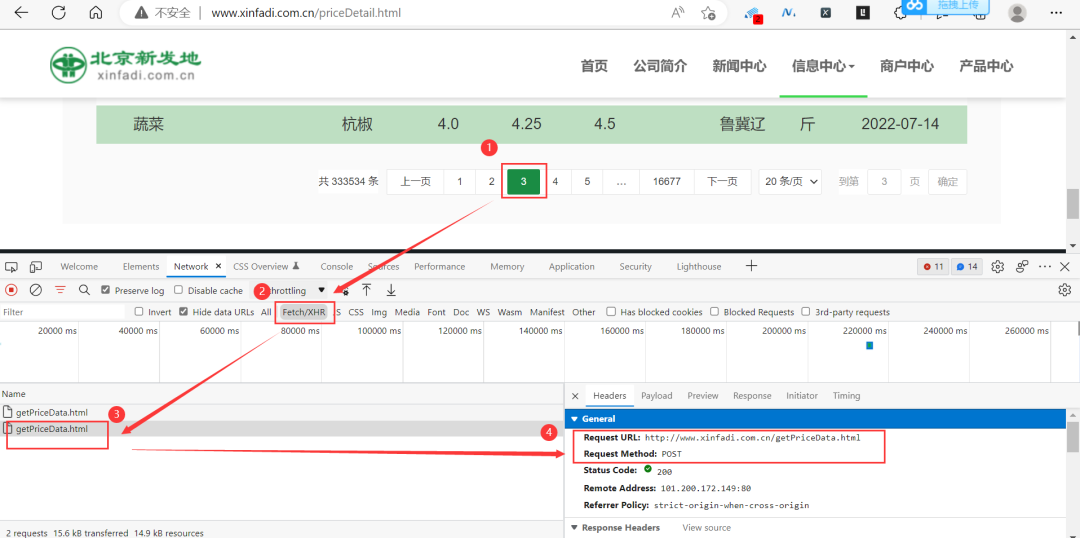
此时的请求参数如下图所示:
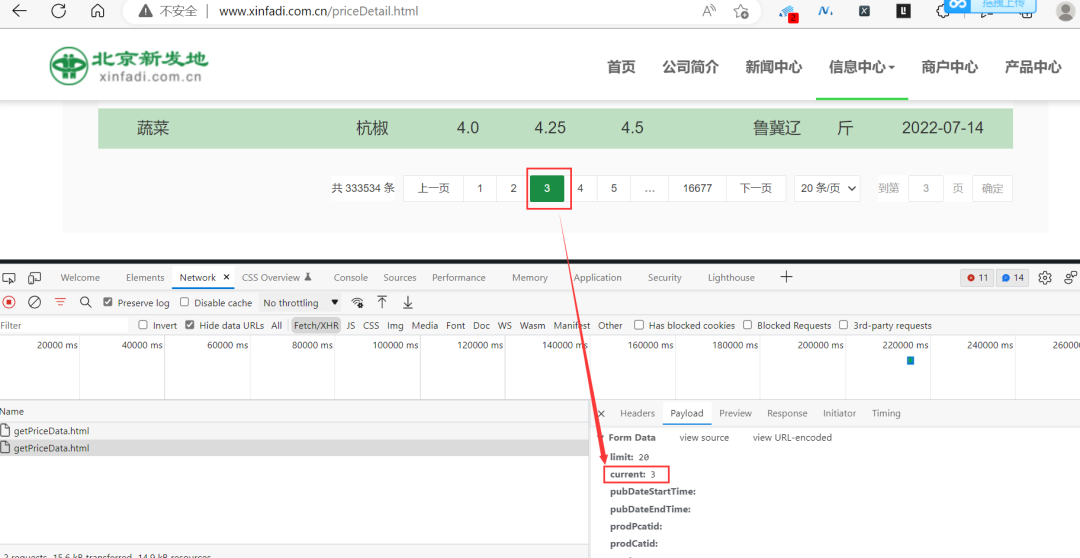
那么到这里的话,网页变化的规律其实已经很明显了,接下来我们只需要上playwright代码就行了,代码框架是固定的,只需要更改两个url即可,第一个是主页的url,第二个就是响应数据的response.url,具体的代码如下所示:
from playwright.sync_api import Playwright, sync_playwright
import datetime
from pprint import pprint
import traceback
import logging
from tqdm import tqdm
import json
# pip install playwright,然后终端 playwright install
"""
先用playwright写一个普通的登入网站代码,然后page.goto前面加上
page.on("request", lambda request: handle(request=request, response=None))
page.on("response", lambda response: handle(response=response, request=None))
然后可以写一个handle自定义函数,args为response和request,然后后面想怎么处理数据都可以
"""
# setup logging
logging.basicConfig(format='%(asctime)s | %(levelname)s : %(message)s', level=logging.INFO)
def handle_json(json):
# process our json data
# print(json)
for i in range(20):
data_list = json['list'][i]
# print(data_list)
id = data_list['id']
prodName = data_list['prodName']
prodCat = data_list['prodCat']
place = data_list['place']
print(id, prodName, prodCat, place)
def handle(request, response):
if response is not None:
# response url 是网站请求数据的url
if response.url == 'http://www.xinfadi.com.cn/getPriceData.html':
handle_json(response.json())
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context(ignore_https_errors=True)
# Open new page
page = context.new_page()
page.on("request", lambda request: handle(request=request, response=None))
page.on("response", lambda response: handle(response=response, request=None))
# url是网页加载的URL
url = 'http://www.xinfadi.com.cn/index.html'
page.goto(url)
# 然后之前看到有说道网站动态加载,拖动的问题。playwright可以直接用page.mouse.wheel(0, 300)解决
page.wait_for_timeout(50000)
# ---------------------
context.close()
page.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
运行之后的结果如下所示:
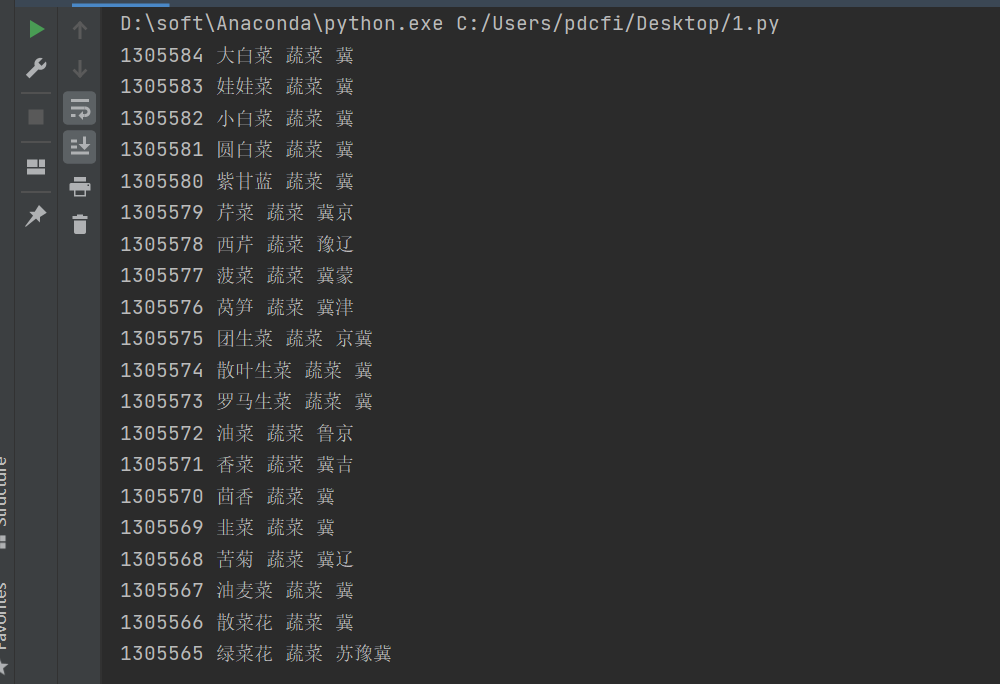
可以看到数据已经成功拿下了。在handle_json()这个函数里边,你可以针对获取到的数据做进一步的处理,如提取,保存等,也可以直接打印出来看效果,看你自己的需求了。
如果有遇到问题,随时联系我解决,欢迎加入我的Python学习交流群。

三、总结
大家好,我是Python进阶者。这篇文章主要分享了一个playwright网络爬虫实战案例教程,文中针对该问题给出了具体的解析和代码实现。
最后感谢粉丝【HugoLB】分享,感谢【月神】、【瑜亮老师】、【此类生物】、【猫药师Kelly】、【冯诚】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~