
ClickHouse在工业互联网场景的OLAP平台建设实践
京东科技开发者
共 2963字,需浏览 6分钟
·
2021-12-30 15:38
一、背景介绍
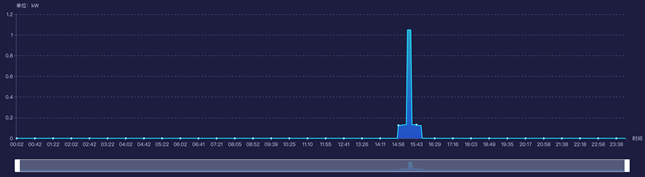
二、技术架构

架构1.0 存储聚合分离
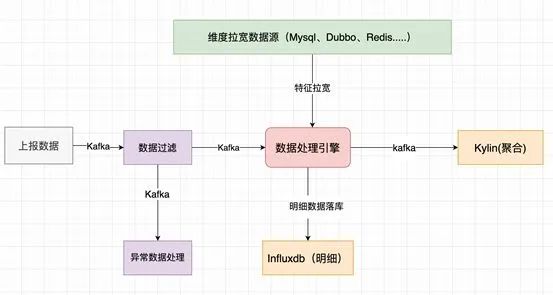
数据过滤
数据处理引擎
Influxdb
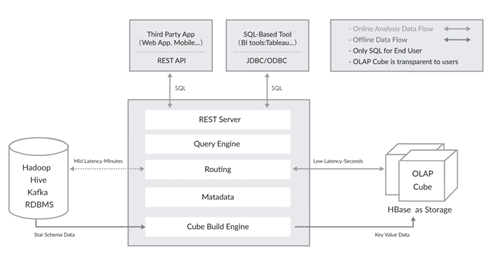
Kylin
业务表现和感受
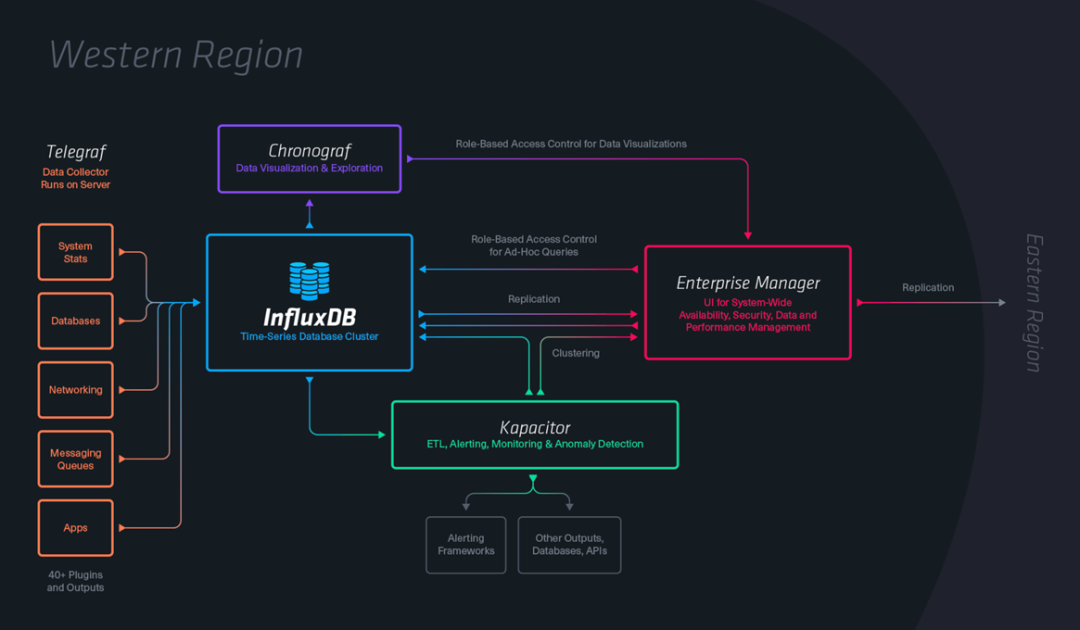
Influxdb实际业务表现
综合感受
架构2.0 ClickHouse合二为一
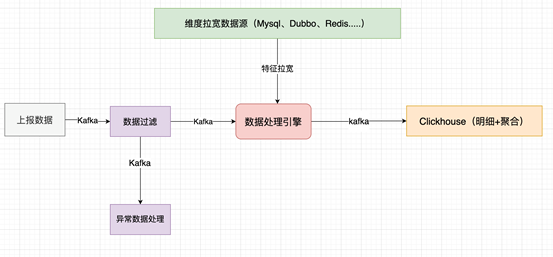
业务表现
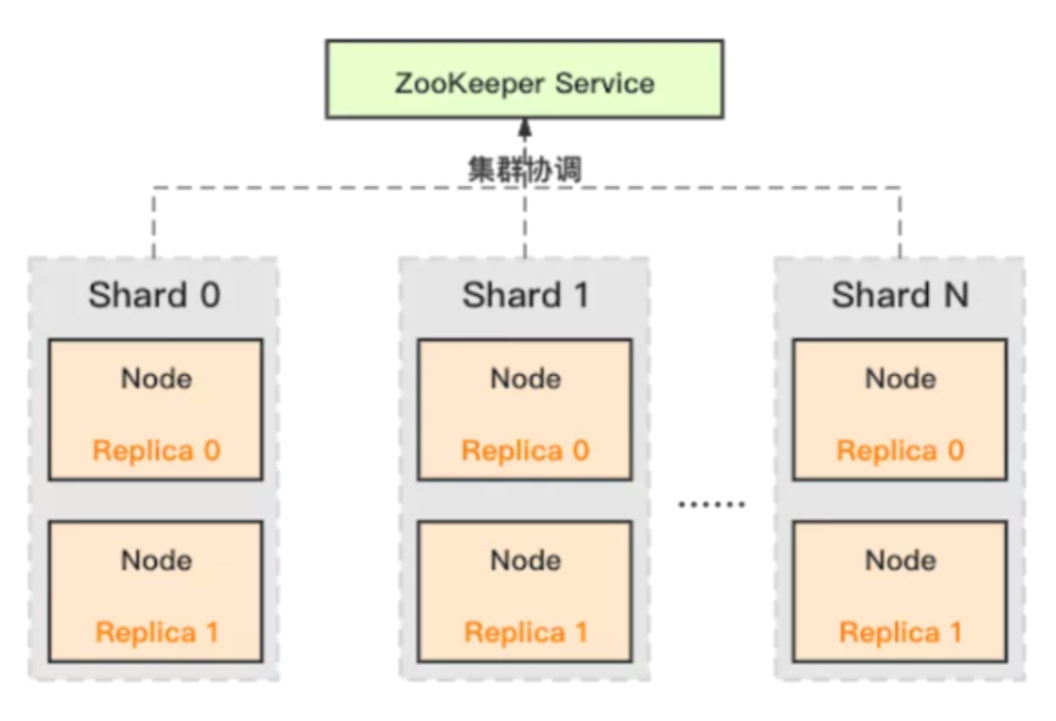
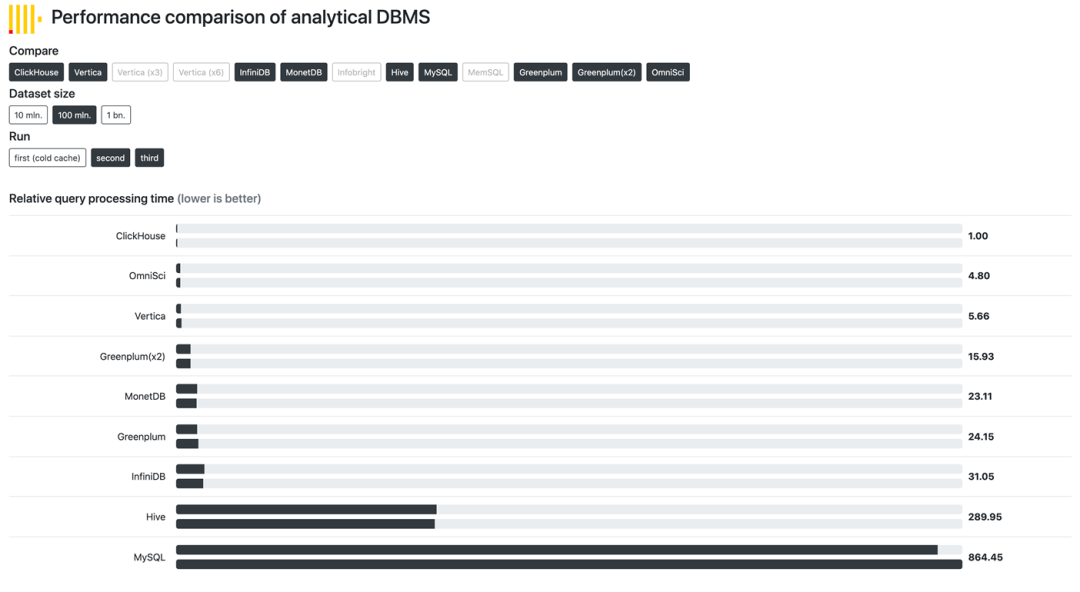
新的问题
大屏应用遭遇性能瓶颈
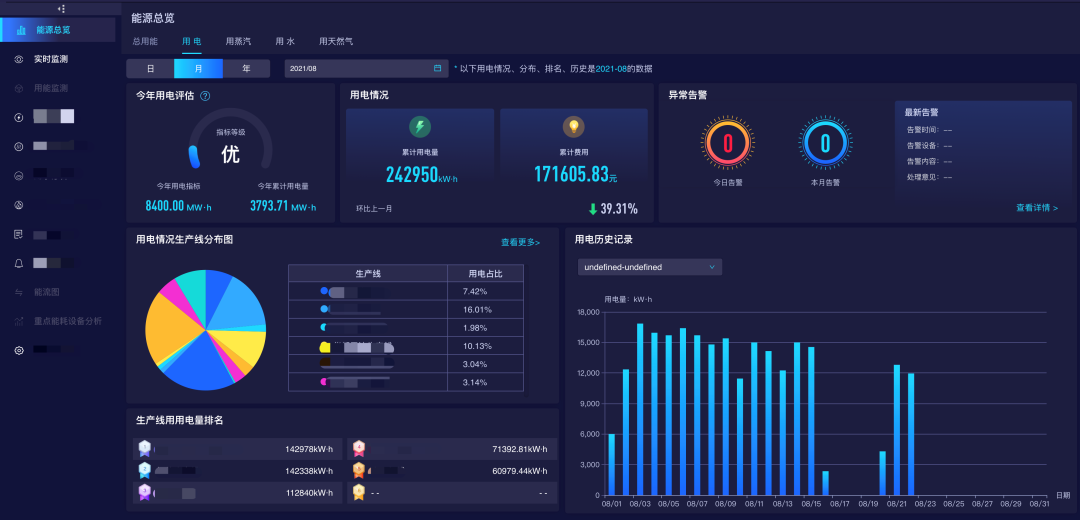

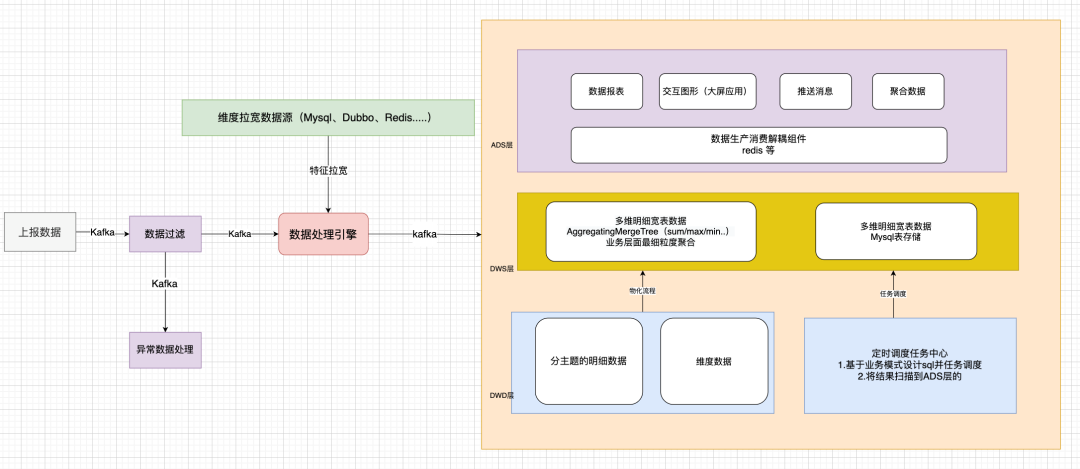
架构3.0 ClickHouse+实时数仓
三、ClickHouse 实践总结
ClickHouse的适用场景实践
评论