
SeaTunnel 实践 | 如何升级 OLAP 平台?SeaTunnel 在唯品会的实践!

分享嘉宾:王玉 唯品会 OLAP团队负责人
编辑整理:张德通
出品平台:DataFunTalk
导读:本文主要带来 SeaTunnel 在唯品会的多维度实践。从选型组件方案,到 OLAP 方案的使用,到与唯品会数据平台的集成方案,到人群方案中的使用。也同时会分享唯品会在使用 SeaTunnel 的一些集成和使用改造。
本文将围绕下面几点展开:
ClickHouse数据导入的需求和痛点
ClickHouse出仓入仓工具选型
Hive to ClickHouse
ClickHouse to Hive
SeaTunnel与唯品会数据平台的集成
未来展望
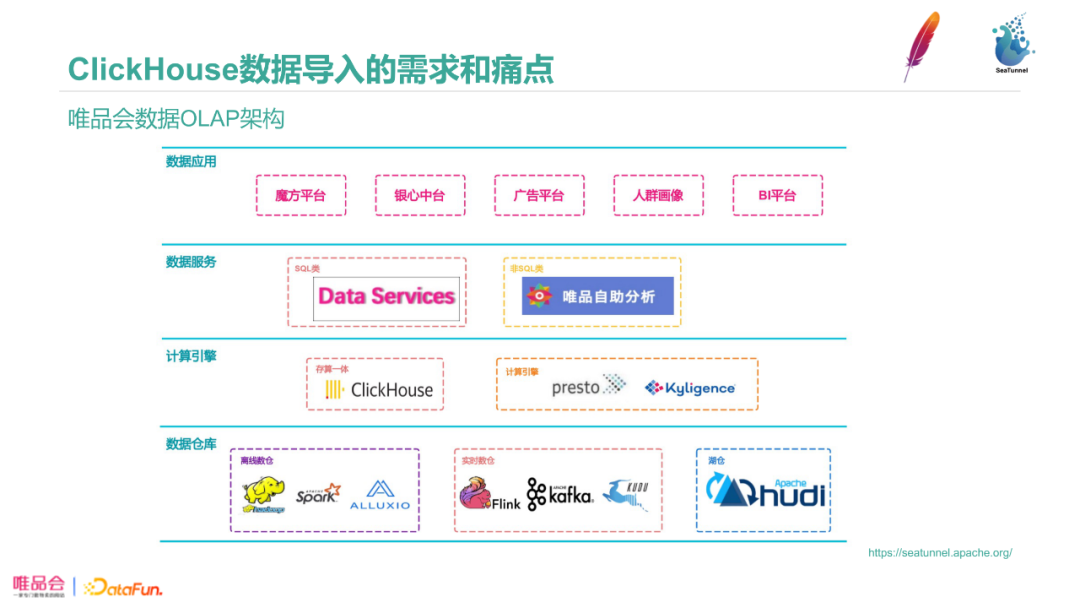
1. 唯品会数据OLAP架构
图中是唯品会OLAP架构,我们负责的模块是图中的数据服务和计算引擎两大部分。底层依赖的数据仓库分为离线数仓、实时数仓和湖仓。计算引擎方面,我们使用Presto、Kylin和Clickhouse。虽然Clickhouse是一个存储一体的OLAP数据库,我们为了利用Clickhouse的优秀计算性能而将它归入了计算引擎部分。基于OLAP组件之上,我们提供了SQL类数据服务和非SQL的唯品会自主分析,为不同智能服务。例如非SQL服务是为BI和商务提供更贴近业务的数据分析的服务。在数据服务至上抽象了多个数据应用。
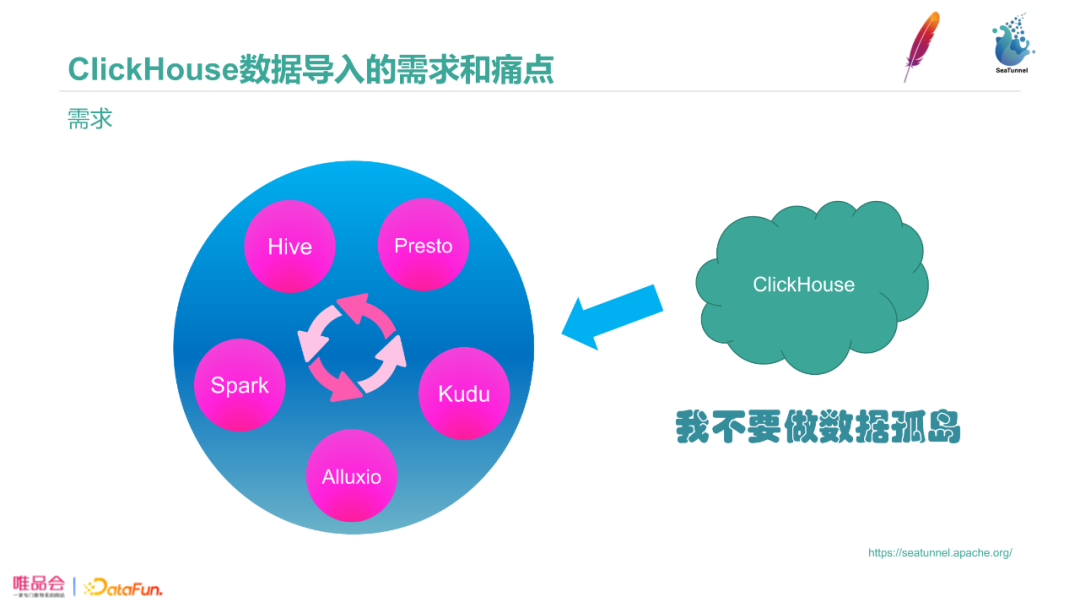
2. 需求
我们通过Presto Connector和Spark组件,把底层的Hive、Kudu、Alluxio组件打通。大数据组件之间可以互相导入导出数据,可以根据数据分析的需求和场景任意利用合适的组件分析数据。但我们引入Clickhouse时,它是一个数据孤岛,数据的导入和导出比较困难。Hive和Clickhouse之间需要做很多工作才能实现导入导出。我们的第一个数据导入导出需求就是提升导入导出效率,把Clickhouse纳入大数据体系中。
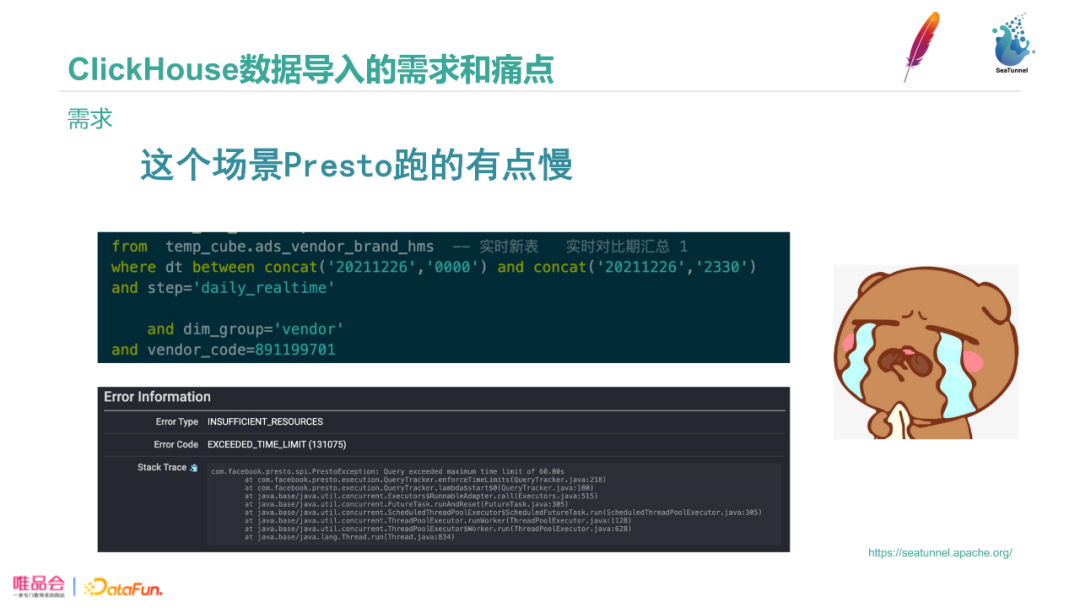
第二个需求是Presto跑SQL比较慢,图中是一个慢SQL的例子。图中的SQL where条件设置了日期、时间范围和具体过滤条件,这类SQL使用由于Presto使用分区粒度下推,运行比较慢。即使用Hive的Bucket表和分桶等其他方式优化后也是几秒的返回时间、不能满足业务要求。这种情况下,我们需要利用Clickhouse做离线的OLAP计算加速。
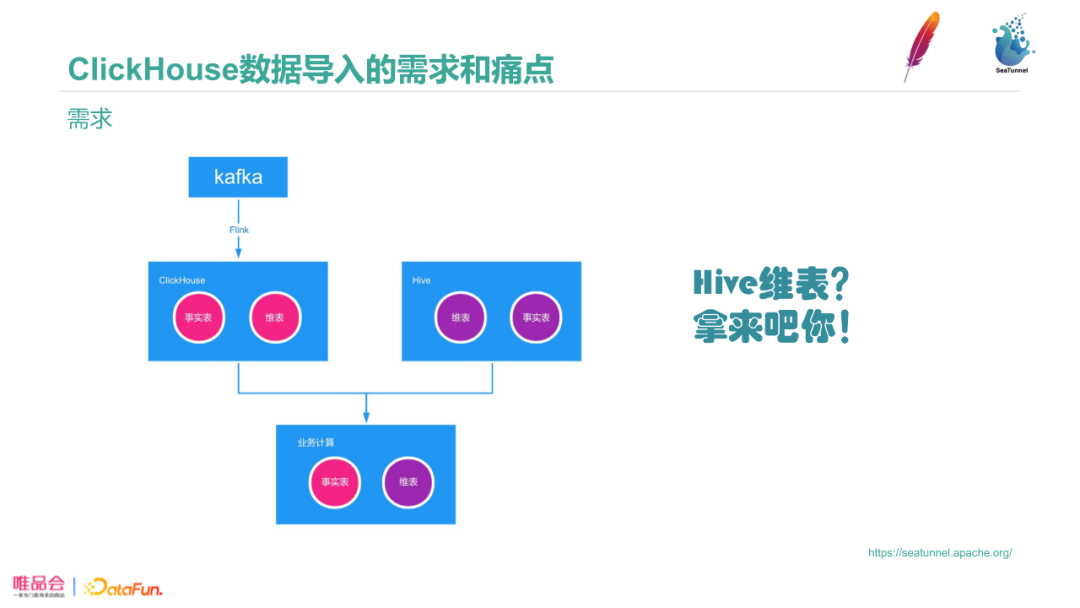
我们的实时数据是通过Kafka、Flink SQL方式写入到Clickhouse中。但分析时只用实时数据是不够的,需要用Hive维度表和已经ETL计算号的T+1实时表一起在Clickhouse中做加速运输。这需要把Hive的数据导入到Clickhouse中,这就是我们的第三个需求。
3. 痛点
首先,我们引入一项数据组件时要考虑其性能。Hive表粒度是五分钟,是否有组件可以支撑五分钟内完成一个短小ETL流程并把ETL结果导入到Clickhouse中?第二,我们需要保证数据质量,数据的准确性需要有保障。Hive和Clickhouse的数据条数需要保障一致性,如果数据质量出问题能否通过重跑等机制修复数据?第三,数据导入需要支持的数据类型是否完备?不同数据库之间的数据类型和一些机制不同,我们有HiperLogLog和BitMap这类在某一存储引擎中利用得比较多得数据类型,是否可以正确传输和识别,且可以较好地使用。
基于数据业务上的痛点,我们对数据出仓入仓工具进行了对比和选择。我们主要在开源工具中进行选择,没有考虑商业出入仓工具,主要对比DataX、SeaTunnel和编写Spark程序并用jdbc插入ClickHouse这三个方案中取舍。
SeaTunnel和Spark依赖唯品会自己的Yarn集群,可以直接实现分布式读取和写入。DataX是非分布式的,且Reader、Writer之间的启动过程耗时时间长,性能普通,SeaTunnel和Spark处理数据的性能可以达到DataX的数倍。
十亿以上的数据可以平稳地在SeaTunnel和Spark中运行,DataX在数据量大以后性能压力大,处理十亿以上数据吃力。
在读写插件扩展性方面,SeaTunnel支持了多种数据源,支持用户开发插件。SeaTunnel支持了数据导入Redis。
稳定性上,SeaTunnel和DataX由于是自成体系的工具,稳定性会更好。Spark的稳定性方面需要关注代码质量。

我们的曝光表数据量每天在几十亿级,我们有5min内完成数据处理的性能要求,我们存在数据导入导出到Redis的需求,我们需要导入导出工具可以接入到数据平台上进行任务调度。出于数据量级、性能、可扩展性、平台兼容性几方面的考虑,我们选择了SeaTunnel作为我们的数仓导入导出工具。
下面将介绍我们对SeaTunnel的使用。
图中是一张Hive表,它是我们三级的商品维度表,包含品类商品、维度品类和用户人群信息。表的主键是一个三级品类ct_third_id,下面的value是两个uid的位图,是用户id的bitmap类型,我们要把这个Hive表导入到Clickhouse。
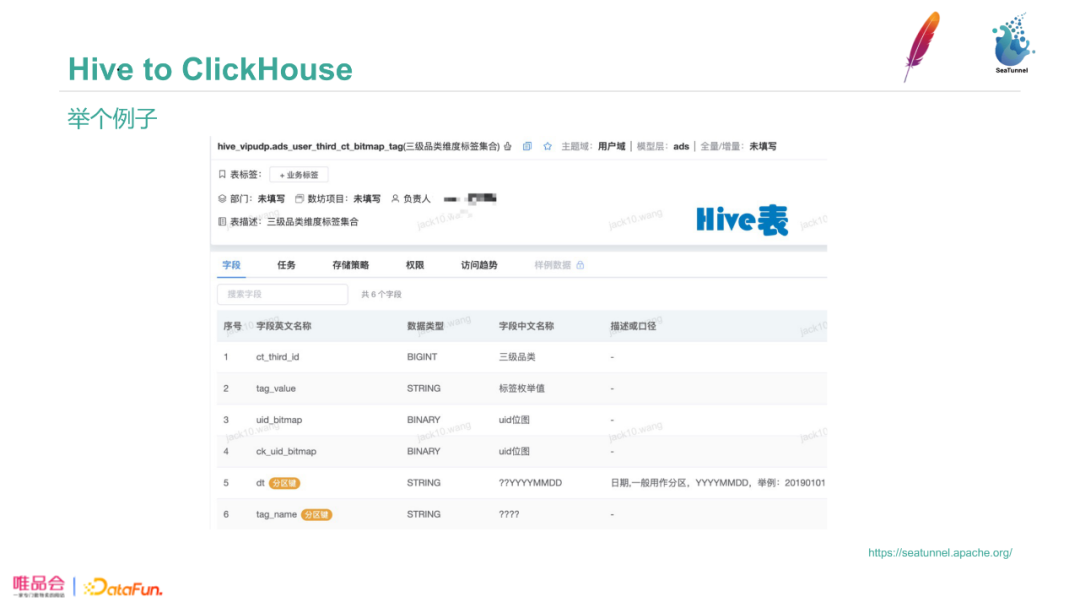
SeaTunnel安装简单,官网文档有介绍如何安装。下图中是SeaTunnel的配置,配置中env、source和sink是必不可少的。env部分,图中的例子是Spark配置,配置了包括并发度等,可以调整这些参数。source部分是数据来源,这里配置了Hive数据源,包括一条Hive Select语句,Spark运行source配置中的SQL把数据读出,此处支持UDF进行简单ETL;sink部分配置了Clickhouse,可以看到output_type=rowbinary,rowbinary是唯品会自研加速方案;pre_sql和check_sql是自研的用于数据校验的功能,后面也会详细介绍;clickhouse.socket_timeout和bulk_size都是可以根据实际情况进行调整的。
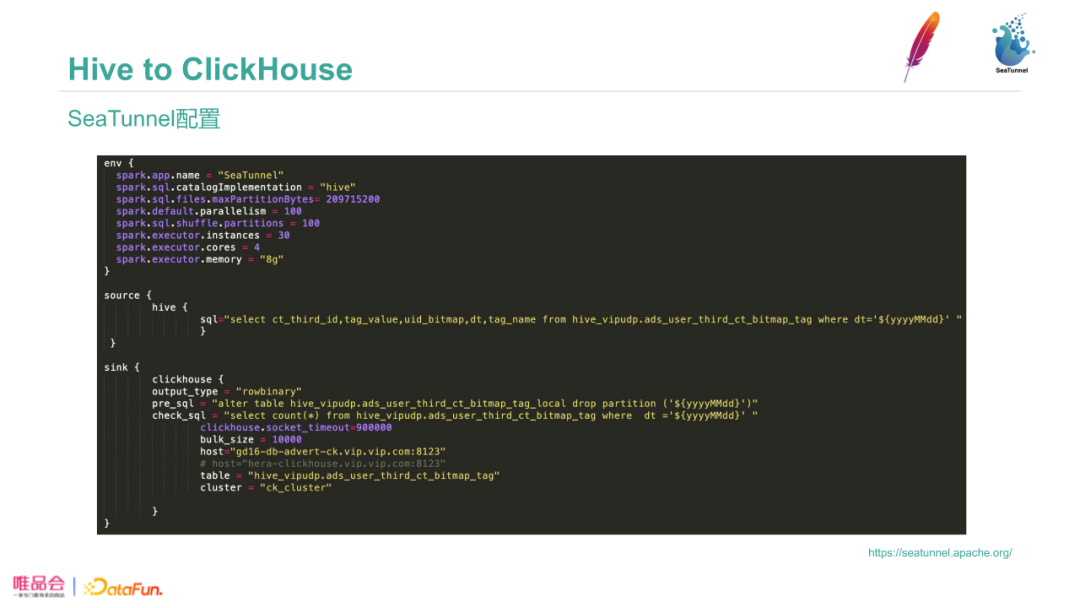
运行SeaTunnel,执行sh脚本文件、配置conf文件地址和yarn信息,后即可。
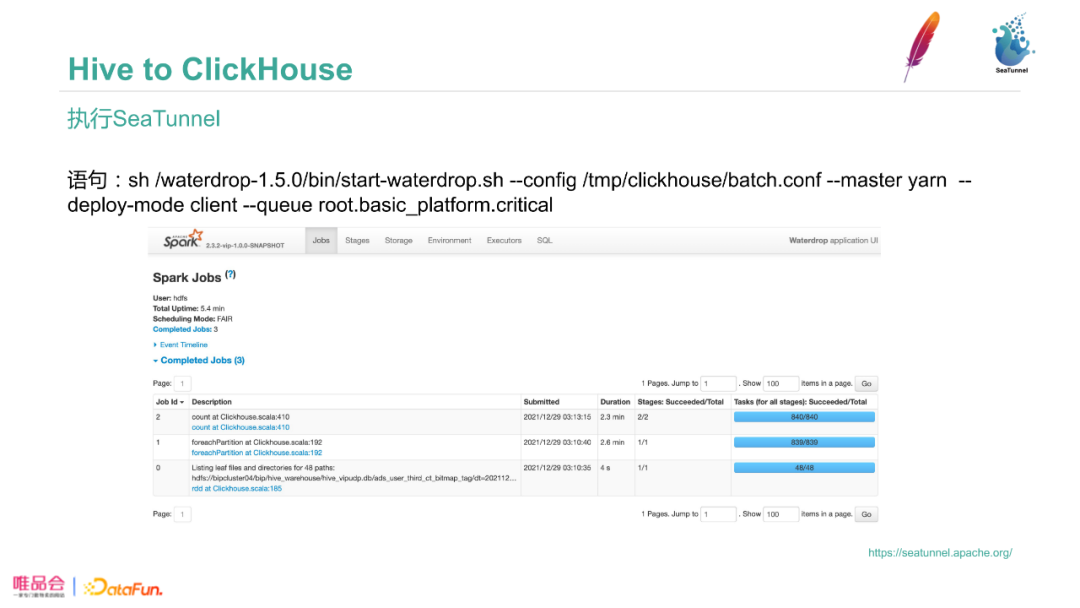
运行过程中会产生Spark日志,运行成功和运行中错误都可以在日志中查看。

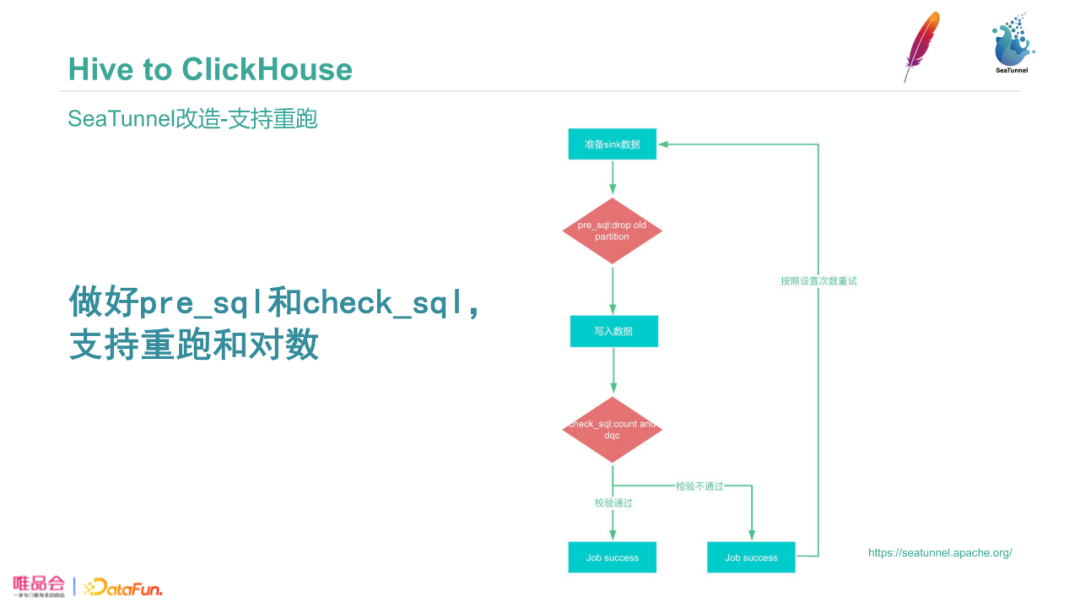
为了更贴合业务,唯品会对SeaTunnel做了一些改进。我们的ETL任务都是需要重跑的,我们支持了pre_sql和check_sql实现数据的重跑和对数。主要流程是在数据准备好后,执行pre_sql进行预处理,在Clickhouse中执行删除旧分区数据、存放到某一目录下在失败时恢复该分区、rename这类操作。check_sql会检验,校验通过后整个流程结束;如果检验不通过,根据配置进行重跑,重跑不通过则报警到对应负责人。
唯品会基于1.0版本SeaTunnel增加了RowBinary做加速,也让HuperLogLog和BinaryBitmap的二进制文件能更容易地从Hive导入到Clickhouse。我们在ClickHouse-jdbc、bulk_size、Hive-source几处进行了修改。使用CK-jdbc的extended api,以rowbinary方式将数据写入CK,bulk_size引入了以rowbinary方式写入CK的控制逻辑,Hive-source
RDD以HashPartitioner进行分区将数据打散,防止数据倾斜。
我们还让SeaTunnel支持了多类型,为了圈人群的功能,需要在Clickhouse、Preso、Spark中实现对应的方法。我们在Clickhouse-jdbc中增加支持Batch特性的Callback、HttpEntity、RowBinaryStream,在Clickhouse-jdbc和Clickhouse-sink代码中增加了bitmap类型映射,在Presto和Spark中实现了Clickhouse的Hyperloglog和Bitmap的function的UDF。
前面的配置中,Clickhouse-sink部分可以指定表名,这里有写入本地表和分布式表的差异。写入分布式表的性能比写入本地表差对Clickhouse集群的压力会更大,但在计算曝光表、流量表,ABTest等场景中需要两表Join,两张表量级均在几十亿。这时我们希望Join key落在本机,Join成本更小。我们建表时在Clickhouse的分布式表分布规则中配置murmurHash64规则,然后在Seatunnel的sink里直接配置分布式表,把写入规则交给Clickhouse,利用了分布式表的特性进行写入。写入本地表对Clickhouse的压力会更小,写入的性能也会更好。我们在Seatunnel里,根据sink的本地表,去Clickhouse的System.cluster表里获取表的分布信息和机器分布host。然后根据均分规则写入这些host。把数据分布式写入的事情放到Seatunnel里来做。
针对本地表和分布式表的写入,我们未来的改造方向是在Seatunnel实现一致性哈希,直接按照一定规则写如Clickhouse、不依赖Clickhouse自身做数据分发,改善Clickhouse高CPU负载问题。
我们有圈人群的需求,每天唯品会为供应商圈20万个人群,比如80后、高富帅、白富美的人群集合。这些在Clickhouse中的Bitmap人群信息需要导出到Hive表,在Hive中与其他ETL任务进行配合,最后推到PIKA交给外部媒体使用。我们使SeaTunnel将Clickhouse Bitmap人群数据反推到Hive。
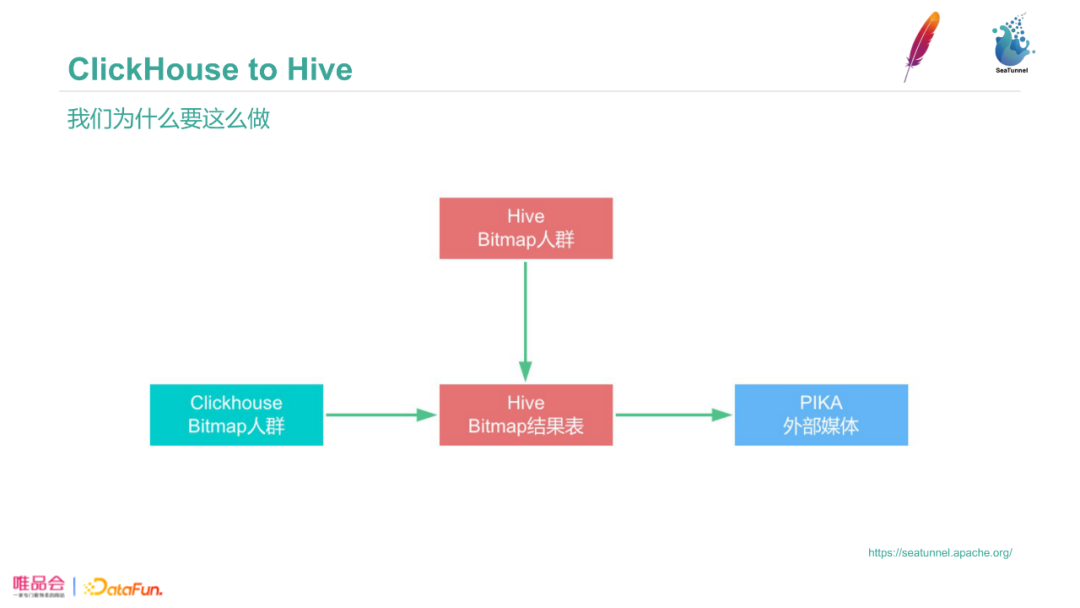
图中是SeaTunnel配置,我们把source配置为Clickhouse、sink配置为Hive,数据校验也配置在Hive内。

由于我们接入SeaTunnel较早,我们对一些模块间进行了加工,包括新增plugin-spark-sink-hive模块、plugin-spark-source-ClickHouse模块,重写Spark Row相关方法,使其能封装经过Schem映射后的Clickhouse数据,重新构造StructField并生成最终需要落地Hive的DataFrame。最新版本已经有了很多source和sink组件,在SeaTunnel使用上更方便。现在也可以在SeaTunnel中直接集成Flink connector。
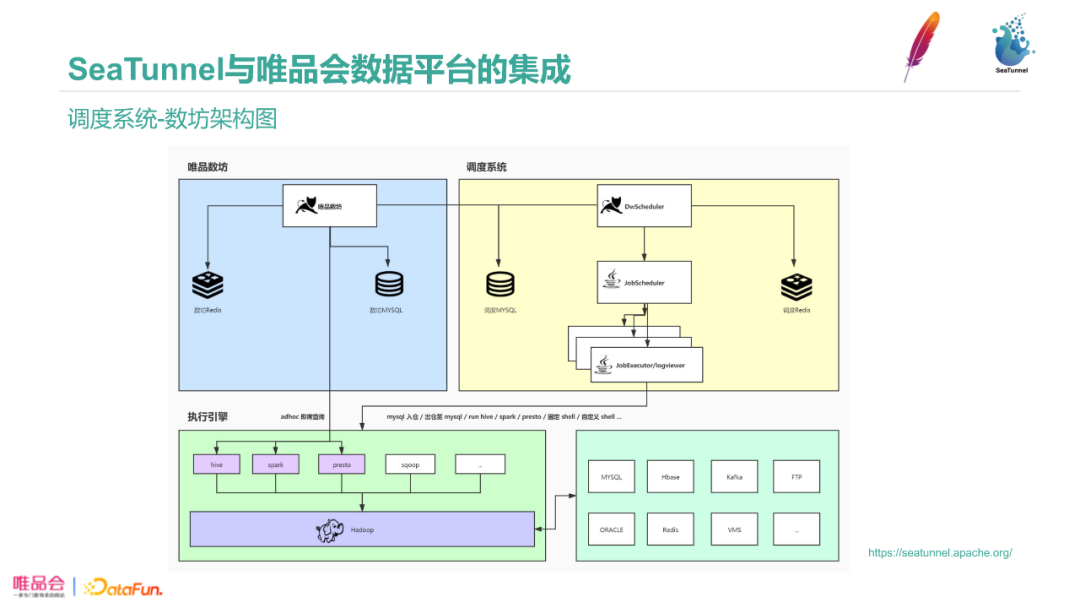
各个公司都有自己的调度系统,例如白鲸、宙斯。唯品会的调度工具是数坊,调度工具中集成了数据传输工具。下面是调度系统架构图,其中包含各类数据的出入仓。
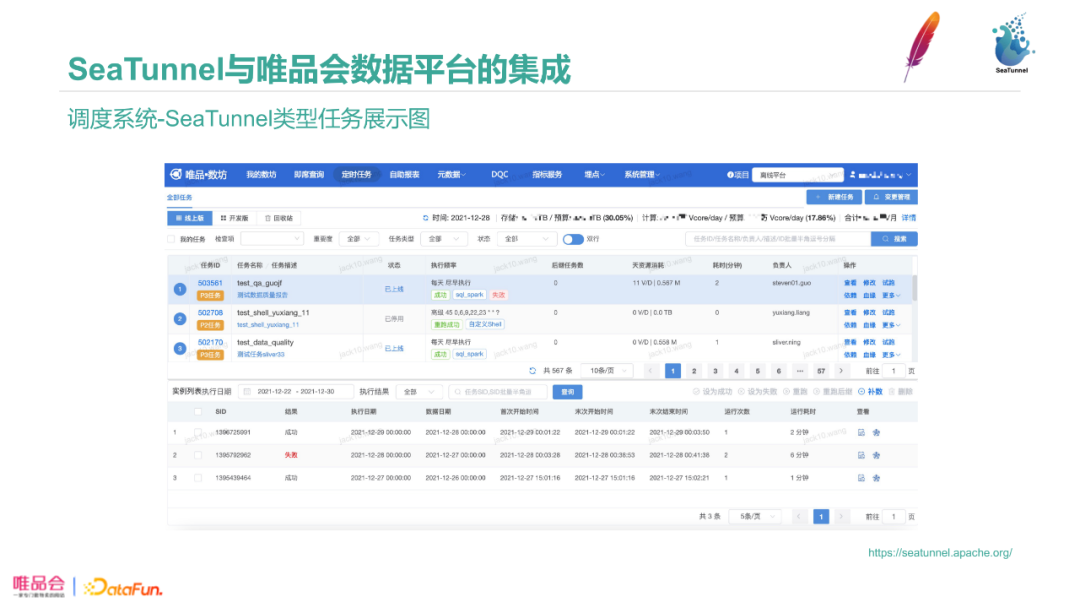
SeaTunnel任务类型集成到平台中,图中是数坊的定时任务截图,可以看到选中的部分,是一个配置好的SeaTunnel任务,负责人、最近一次耗时,前后依赖任务的血缘信息,消耗的资源信息。下面展示了历史运行实例信息。
我们把SeaTunnel集成到了调度系统中,数坊调度Master会根据任务类型把任务分配到对应的Agent上,根据Agent负载情况分配到合适的机器上运行,管控器把前台的任务调度配置和信息拉取到后生成SeaTunnel cluster,在类似于k8s pod、cgroup隔离的虚拟环境内进行执行。运行结果会由调度平台的数据质量监控判断任务是否完成、是否运行成功,失败时进行重跑和告警。
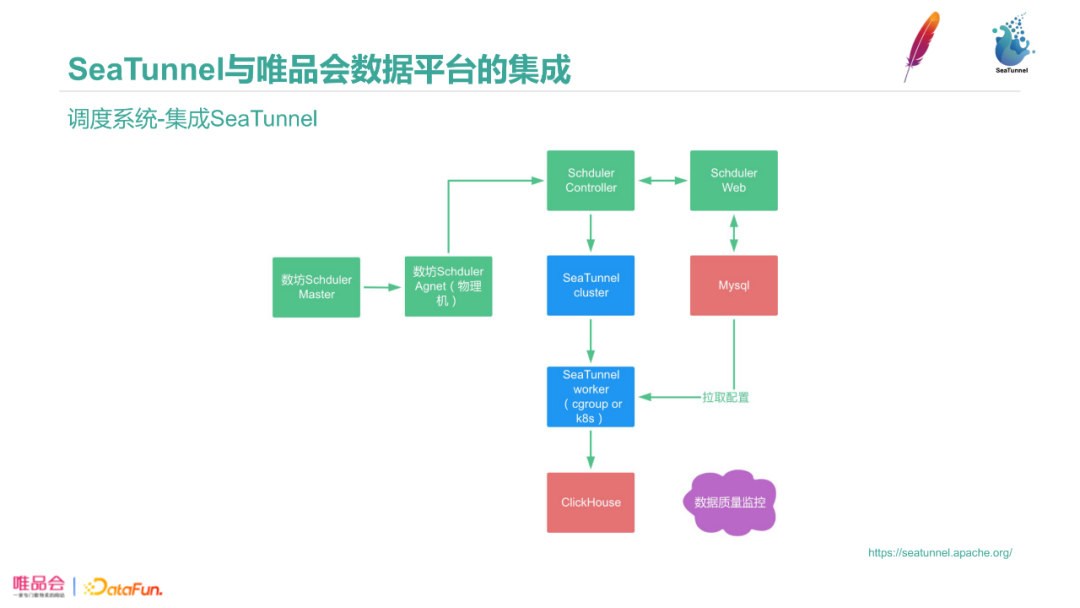
SeaTunnel本身是一个工具化的组件,是为了进行数据血缘,数据质量,历史记录,高警监控,还包括资源分配这些信息的管控。我们把SeaTunnel集成到平台中,可以利用平台优势利用好SeaTunnel。
圈存人群中利用了SeaTunnel进行处理。我们通过打点数据,把圈存人群按照路径和使用情况分为不同的人,或称千人千面,把用户打上标签,圈出的某一类人群推送给用户、分析师和供应商。
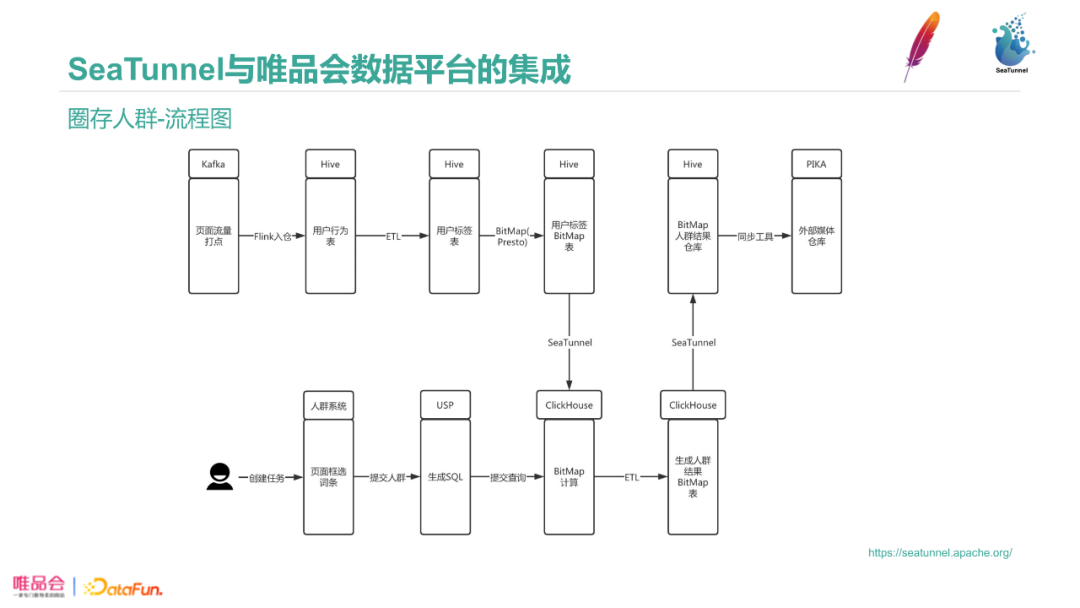
流量进入Kafka,通过Flink入仓,再通过ETL形成用户标签表,用户标签表生成后,我们通过Presto实现了的BitMap方法,把数据打成Hive中的宽表。用户通过在人群系统页面中框选词条创建任务,提交腾群,生成SQL查询Clickhouse BitMap。Clickhouse的BitMap查询速度非常快,由天生优势,我们需要把Hive的BitMap表通过SeaTunnel导入到Clickhouse中。圈完人群后我们需要把表落地,形成Clickhouse的一个分区或一条记录,再把生成的结果BitMap表通过SeaTunnel存储到Hive中去。最后同步工具会将Hive的BitMap人群结果同步给外部媒体仓库Pika。每天圈20w个人群左右。
整个过程中SeaTunnel负责把数据从Hive导出到Clickhouse,Clickhouse的ETL流程完成后SeaTunnel把数据从Clickhouse导出到Hive。
为了完成这样的需求,我们在Presto和Spark端现ClickHouse的Hyperloglog和BitMap的function的UDF;我们还开发Seatunnel接口,使得用户在ClickHouse里使用Bitmap方法圈出来的人群,可以直接通过SeaTunnel写入Hive表,无需中间落地步骤。用户也可以在Hive里通过spark圈人群或者反解人群bitmap,调用SeaTunnel接口,使数据直接传输到ClickHouse的结果表,而无需中间落地。
后续我们会进一步改善Clickhouse写入数据时CPU负载高的问题,下一步会在SeaTunnel中实现Clickhouse数据源和读取端的CK-local模式,读写分离,减轻Clickhouse压力。未来我们也会增加更多sink支持,如数据推送到Pika和相应的数据检查。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

🧐分享、点赞、在看,给个3连击呗!👇