
Redis 击穿、穿透、雪崩产生原因以及解决思路

- 前言 -
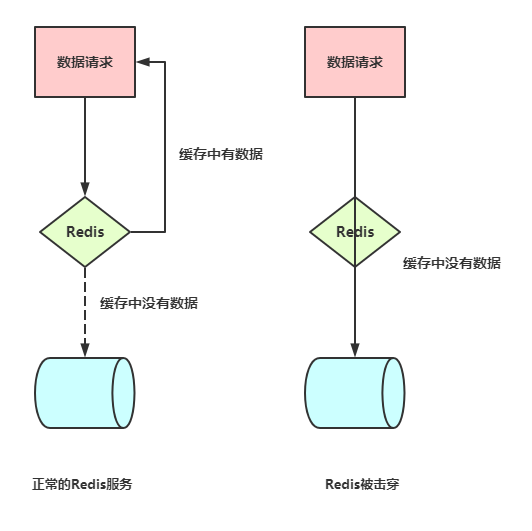
- 问题起因 -
1、Key过期;
2、Key被页面置换淘汰。
- 应对击穿的处理思路 -
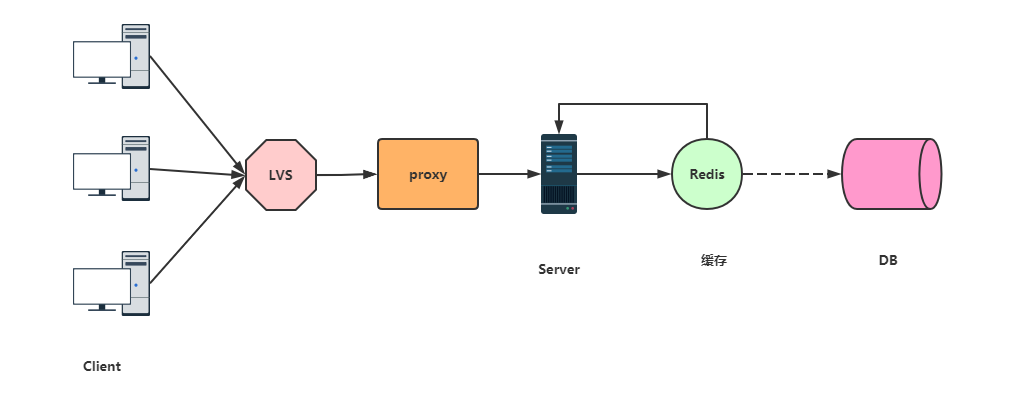
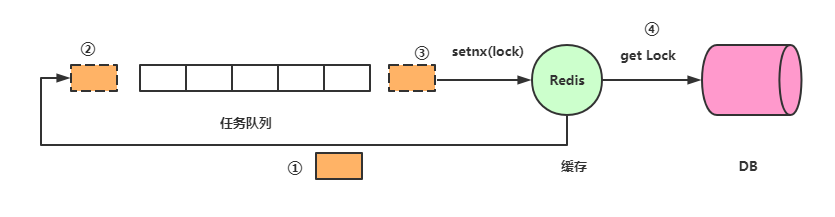
请求到达Redis,发现Redis Key过期,查看有没有锁,没有锁的话回到队列后面排队 设置锁,注意,这儿应该是setnx(),而不是set(),因为可能有其他线程已经设置锁了 获取锁,拿到锁了就去数据库取数据,请求返回后释放锁。
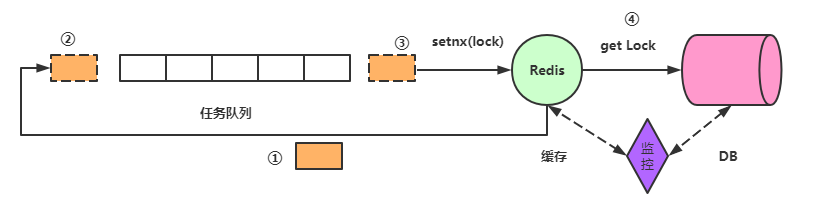
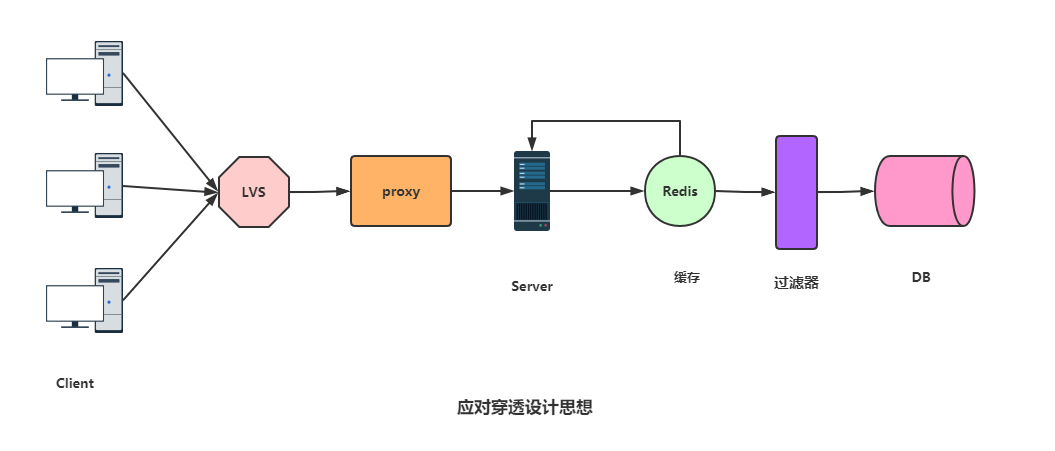
- 穿透 -
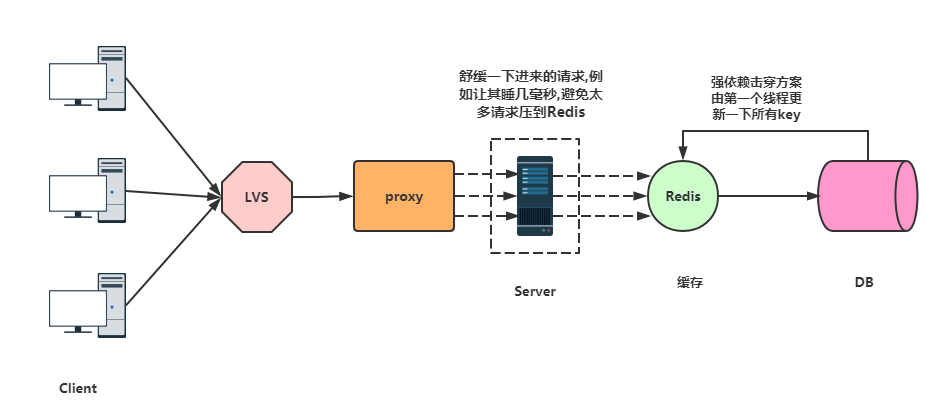
- 雪崩 -
作者:等不到的口琴
来源:
www.cnblogs.com/Courage129/p/14348720.html
评论