
好文推荐:图文并茂地带你入门正则表达式
共 2371字,需浏览 5分钟
·
2019-10-26 23:23

作者:Jan Meppe
来源:机器之心
对于大多数没有接受过正式 CS 教育的人来说,正则表达式似乎只有最核心的 Unix 程序员才敢碰。一个好的正则表达式看起来像魔法,但请记住:任何足够先进的技术都无法与魔法区分开来。
所以,就让我们揭开正则表达式的神秘面纱!
如果你理解正则表达式,它会突然变成一个超快速和强大的工具……但你首先需要理解它,老实说,我觉得新手可能会对它望而生畏!
让我们从基础开始。正则表达式(regex)是什么?它们的用途是什么?
Regex 新手上路
本质上来看,正则表达式是定义一种搜索模式的字符序列。
正则表达式通常用于 grep 等工具中,以在较长文本字符串中查找模式。
考虑以下一个 cat.txt 文件:
catcat2dog
如果我们使用正则表达式 cat 来搜索匹配项,我们会找到以下匹配项:
catcat2高级用户需要注意的是,本文存在一个技术上的错误,即正则表达式和使用正则表达式的工具(如 grep)混为了一谈。
正则表达式适用于字符,而不是单词
需要反复强调的一个重要问题是:正则表达式适用于字符,而不是单词。隐含串联。
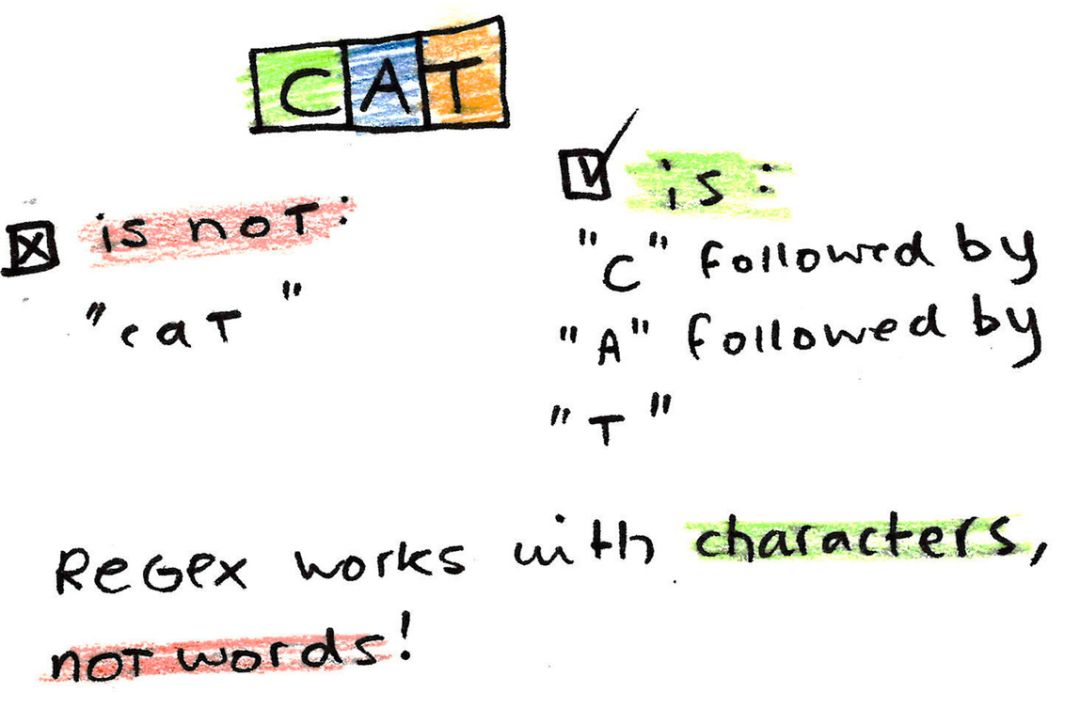
如果我们使用正则表达式搜索模式 cat,则不会查找单词「cat」,而会查找字符 c、a 和 t。
点和星号
最基本的字符是单个字符,如 a、b、c 等。现在让我们介绍以下两种特殊的字符。
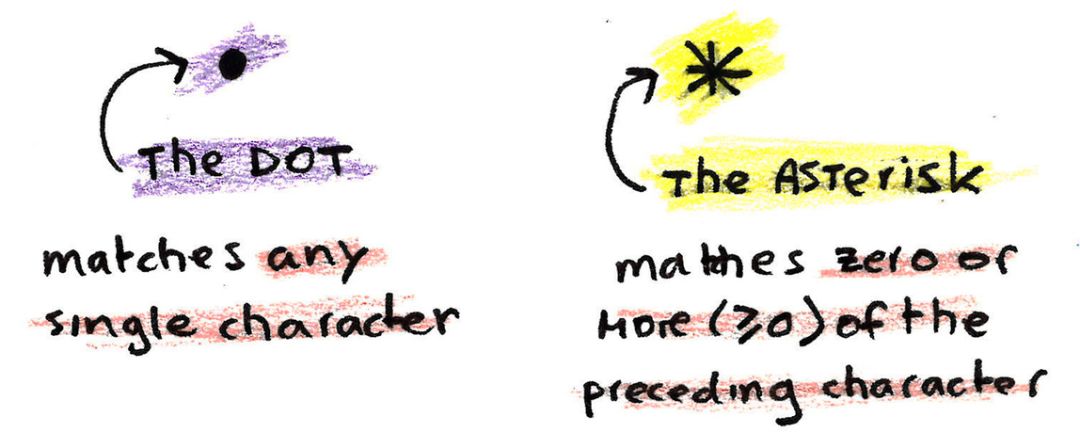
.(点)字符可以匹配*任何单个字符*。例如,如果我们搜索 c.t,则将匹配从 cat 到 c0t 或 cAt 的任何内容,并将匹配任何单个字符 c +任何字符+单个字符 t。
*(星号)字符有点困难。它修改它前面的字符,然后匹配该字符的*零个或多个字符*。的确如此。例如,cat*可以匹配 cat、catt、cattttt 以及 ca。
示例分析:The cat ate my homework
假设我们逐行读取一个文件,则第一行如下所示:
The cat ate my homework.让我们看看如何匹配该行中的模式 cat。
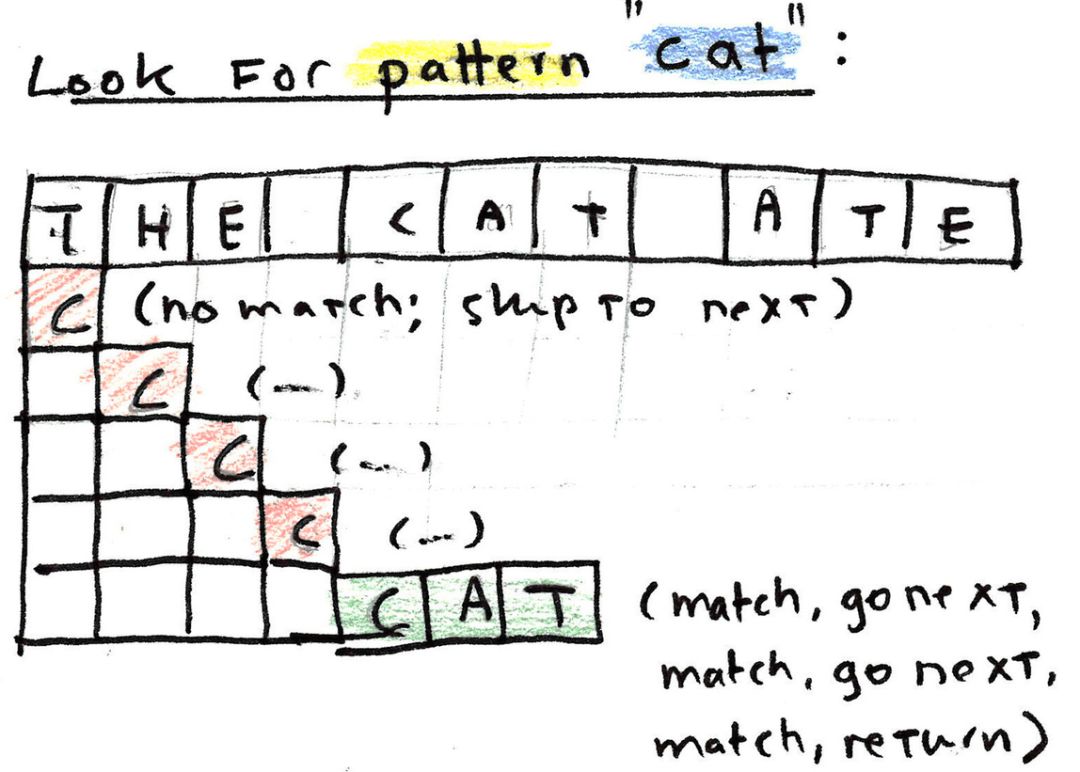
我们首先将该模式的首字符与句子中的首字符匹配。
如果找不到匹配项,则跳转至该行中的下一个字符,然后再从模式的首字符开始。
如果我们找到一个匹配项,则将跳转至模式和该行中的下一个字符,然后重复这个过程。当我们找到整个模式的匹配时,返回找到匹配项的行。
这就是正则表达式最基本、最常用的功能,即在较大的字符串中查找较小的搜索模式。
讲到这里,我想大家已经大致了解了什么是正则表达式以及它的两个特殊字符:.(点)和 *(星号)。接下来,我会为大家介绍更多其他内容。
正则表达式三叉戟
正则表达式的各个部分可以由三个不同的组件组成:
锚点
字符集
修饰符
这三部分构成了正则表达式的三叉戟!
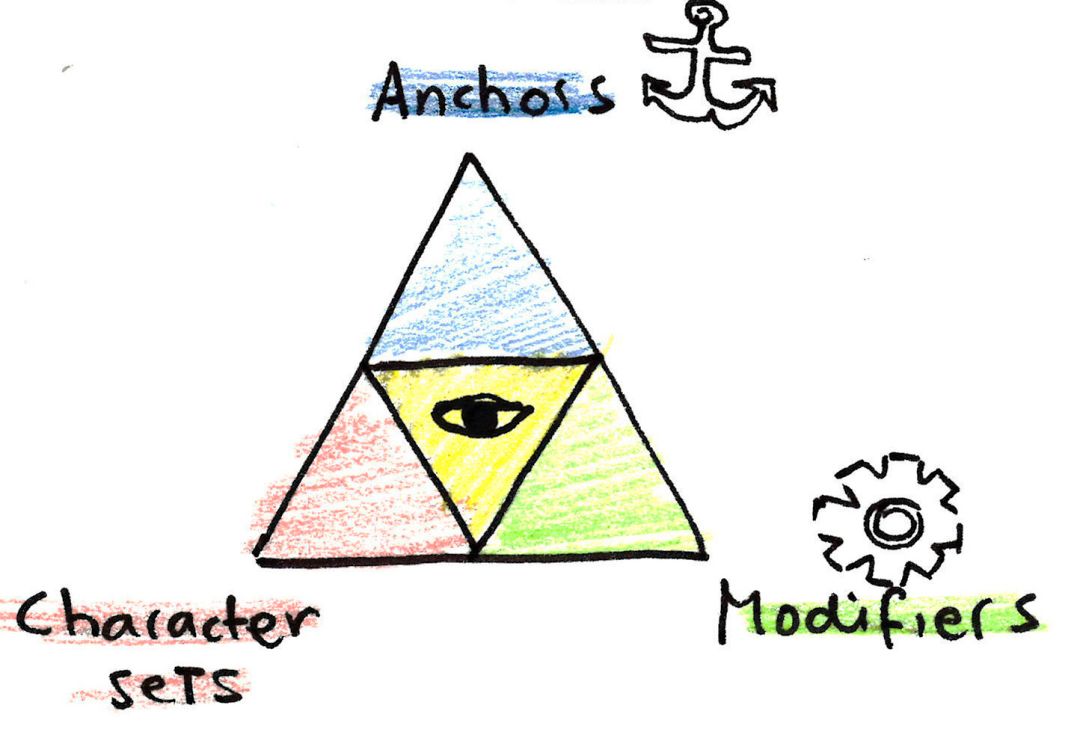
让我们从三叉戟的第一个部分开始:锚点!

锚点
锚点指定个各行的模式位置。下面是两个最重要的锚点:
^(插入符号)将模式固定到行首。例如,模式^1 匹配以 1 开头的任意行。
$(美元符)将模式固定到句尾。例如,9$匹配以 9 结尾的任意行。
注意,在以上两种情况下,锚点必须分别位于模式的开头和结尾。^1 匹配行首的 1,但 1^匹配后跟^的 1。类似地,1$匹配以 1 结尾的行,但$1 匹配一个该行任意位置后跟 1 的美元符号。
字符集
三叉戟的第二部分:字符集。字符集是正则表达式的基础。单个字符,比如 a,是最基本的字符集(一组元素)。但是 [0-9] 等正则表达式可以匹配任何一个数字,或者如果你能回想到 *的含义,则可以制作模式 [0-9][0-9](这个模式匹配的内容留给读者作为练习)。
其他一些重要的字符集:
[0-9] 匹配 0…9 中的任何一个数字
[a-z] 匹配任何小写字母
[A-Z] 匹配任何大写字母
我们还可以对多个字符集进行组合:
[A-ZA-Z0-9] 匹配任何大小写字母和单个数字。
修饰符
此部分内容没有深入展开,以前面遇到的一个修饰符 *(星号)为例。修饰符改变它前面字符的含义。还有很多其他的修饰符,但以* 为例进行讨论是一个很好的开始。
如下所示:让我们快速将文本转储到文件中。
$ echo "The cat jumps long time Then we also have the fact that these are words.1234 this is a test post please ignore." >> grep.txt这是现在文件中的内容。
$ cat grep.txtThe cat jumps long timeThen we also have the fact that these are words.1234 this is a test post please ignore.
寻找 cat。
$ grep "cat" grep.txtThe cat jumps long time
寻找任何以数字^[0-9] 开始的任意行。
$ grep "^[0-9]" grep.txt1234 this is a test post please ignore.
就是这样!你刚刚使用了正则表达式。太棒了。
总结
回顾一下这篇博客的内容:
正则表达式的基本功能;
正则表达式的三个主要组件:锚点、字符集和修饰符。
.(点)、*(星号)、^(插入符)和$(美元符号)。
一些字符集 [0-9]、[a-z]、[A-Z] 和它们的组合。
这篇博客的目的是通过带插图的介绍使用户更轻松地了解正则表达式。
如果能够克服技术上的困难,则最终可以掌握这种相对简单但功能却很强大的正则表达式工具,从而为任何数据科学家带来宝贵的价值。
原文地址:https://www.janmeppe.com/blog/regex-for-noobs/
觉得不错,点个在看呗!