
AeronCluster学习笔记-AeronCluster与数据库
本文将介绍AeronCluster与数据库之间的关系与协作方式。
首先我们要强调,数据库可以是 Aeron Cluster 的有力补充,但数据库其实是可选的。每个 Aeron Cluster 在落地投产之前都需要回答以下问题:
cluster要对系统进行记录吗(数据要落盘吗)? 集群将如何进行启动? 你想为关键的集群事件应用哪些可靠性选项?
我们分别对这几个问题进行说明。
记录型系统(System of Record)
一般来说,如果Cluster进程不是记录型系统,那么数据库是可选的可能性更大。
对于记录型系统而言,必要的事件可以通过网关进程发送到记录系统。
请记住:
始终考虑数据库对特定使用场景的影响。如果你有监控或其他原因需要依赖数据库,那么就请使用数据库。不要直接跳过数据库,因为它在理论上是可供选择使用的(按需架构)。 对系统的状态打快照,并对其进行标记(一般都是基于版本号,或者时间戳), 这可能是一项复杂的任务,特别是考虑到项目生命周期中涉及到数据结构的变化。仔细考虑如何更好地使用版本控制进行快照。
引导Cluster启动(Bootstrapping the Cluster)
引导Cluster启动,也就是加载Cluster运行时所需的所有数据的启动阶段。这个过程通常可以基于两种方式完成:
通过命令和快照引导Cluster启动。在这种情况下,集群管理客户端会被授予将引用和其他操作数据写入集群的权限。而一旦加载了必要的数据,集群就能够完全从快照中启动。 通过数据库引导启动,可选择是否使用快照。在这个场景中,一些外部进程和Cluster之间会约定通信协议,该协议会在集群启动时被引导。外部进程从配置文件/数据库中读取数据。随着数据发生变化,此过程可以向集群提交必要的命令。
在集群启动时,开发者可以选择从快照启动,或清除任何快照——这取决于 SLA 和集群重启频率。
(扯了这么多,其实就是说,在有状态的cluster启动阶段,是可以从数据库中加载必要的数据到内存中,以还原之前状态。)
集群事件和可靠性(Cluster Events & Reliability)
如果你正在将关键的Cluster事件写入数据库,你需要考虑所需的可靠性级别(事务隔离级别等),以及你将希望如何处理恢复场景。
这里举一个场景:
集群、数据库网关、数据库均运行正常 交易 1、2 和 3 下单完成,并由数据库网关写入数据库 此时数据库服务器出现故障 交易 4、5 和 6 下单成功。
简单分析一下,1,2,3请求在内存中成功,但是写db失败,只要重启,数据就会丢失。
那现在怎么办?目前来看,至少有两个选择:
在集群内引入重试机制。思考一下,如果将重试放在数据库网关内,如果失败会怎样(丢数据啊)? 将关键事件append到在集群中运行的专用 Aeron 存档(Aeron Archive)。使用存档偏移量( Archive offset)作为数据库中的高水位线( high watermark)。如果数据库出现故障,重新启动数据库网关。在数据库网关启动时,从数据库中读取最后写入的高水位线并从该点处理集群的存档。
第二种方案是可靠的,其实就是说,处理数据的时候记录一下日志处理的进度,然后崩溃恢复之后从该位置继续往后处理。这种方式的好处是,Aeron Archive底层会对Cluster的raftLog进行重放和恢复,保证幂等的前提下,这种机制不会因为重试而导致脏数据。
回想一下Archive的特性:
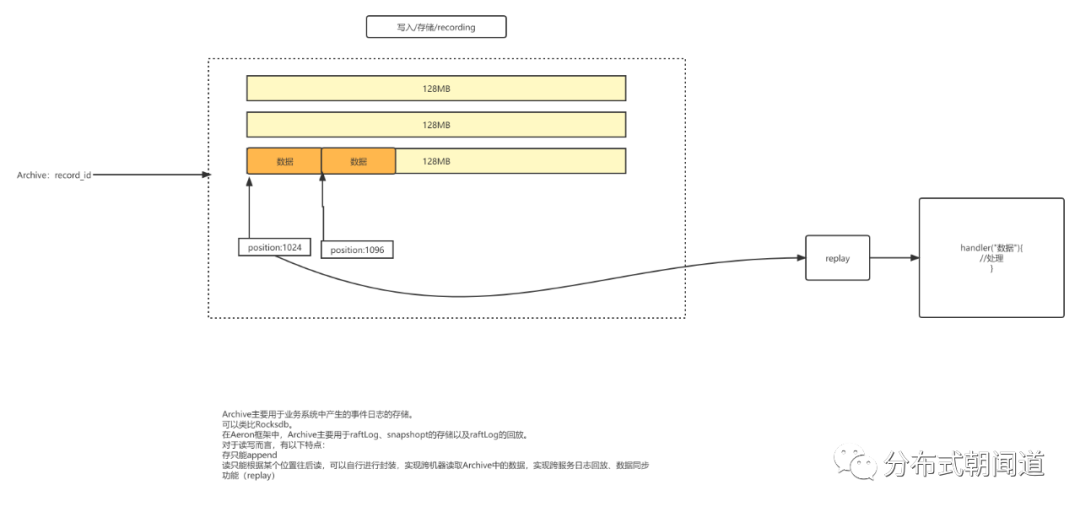
!! Archive主要用于业务系统中产生的事件日志的存储。
我们可以将其类比Rocksdb。
在Aeron框架中,Archive主要用于raftLog、snapshopt的存储以及raftLog的回放。
对于读写而言,有以下特点:
!! 存只能append
!! 读只能根据某个位置往后读,可以自行进行封装,实现跨机器读取Archive中的数据,实现跨服务日志回放、数据同步功能(replay)