
小白如何用免费GPU跑天池算法大赛!
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
作者:卢玉洁,辽宁大学硕士 张帆,天津大学硕士
一、进入阿里云实验室
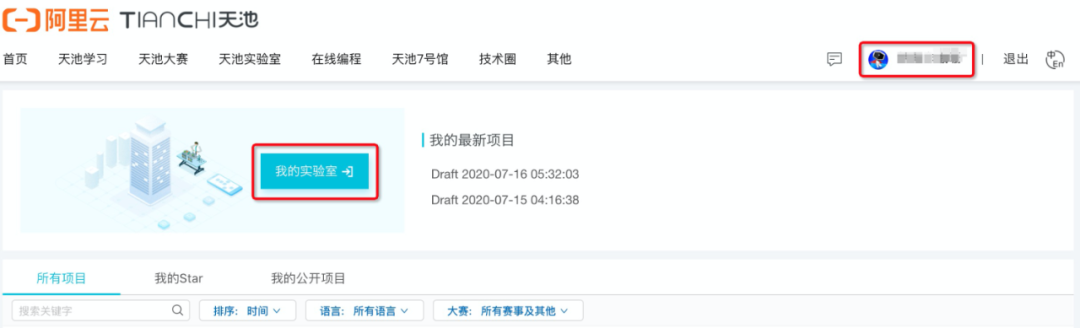
我这次参加比赛用的是阿里云的DWS平台,和Google的Colab类似,不用配置深度学习环境,同时有免费GPU资源,比较适合打比赛。下面我尽量从小白的角度讲下我是如何用DWS来打比赛的。首先从网页进入DWS地址:
二、打开DSW平台
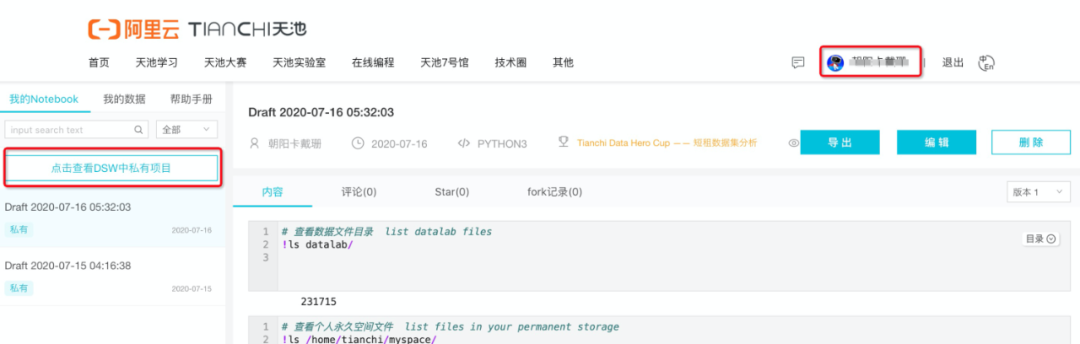
进入之后点击我的实验室,进入之后等待几秒后我们会看到如下页面:
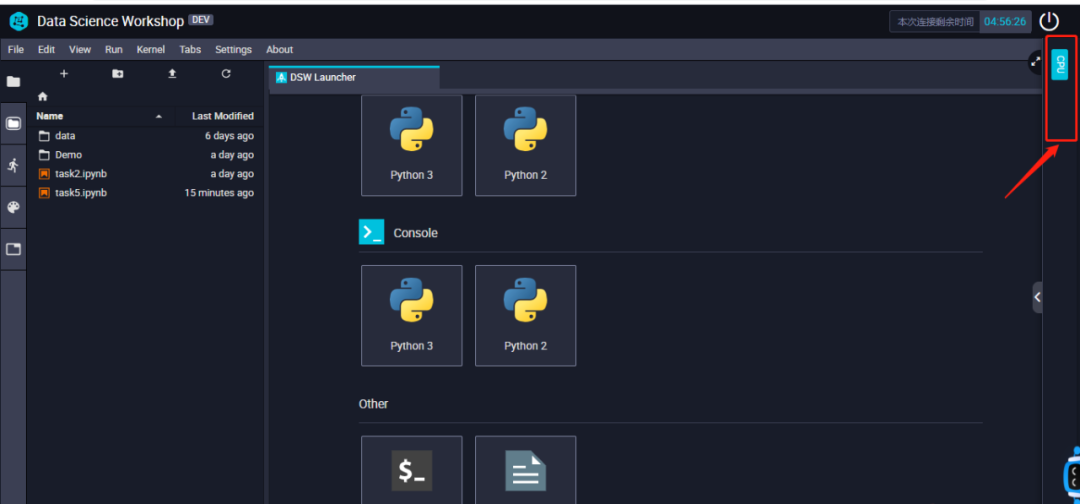
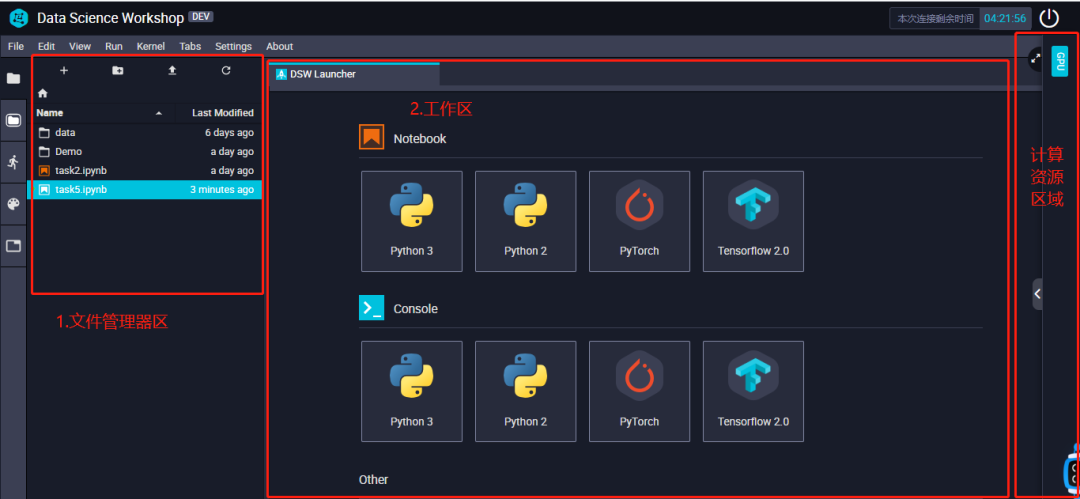 如上图所示,左侧是DSW实验室的⽂件区,在这⾥你可以看到在你的实验室⾥的所有⽂件夹和⽂件。双击⽂件夹即可进入这个⽂件夹。中间是⼯作区,所有被打开的⽂件都会在⼯作区显示出来。右侧是计算资源区域,在这⾥你可以看到你当前使⽤的资源类型。点击右边计算资源区的箭头,即可弹出资源详情,点击切换按钮就可以进行CPU和GPU环境的切换,如下图所示:
如上图所示,左侧是DSW实验室的⽂件区,在这⾥你可以看到在你的实验室⾥的所有⽂件夹和⽂件。双击⽂件夹即可进入这个⽂件夹。中间是⼯作区,所有被打开的⽂件都会在⼯作区显示出来。右侧是计算资源区域,在这⾥你可以看到你当前使⽤的资源类型。点击右边计算资源区的箭头,即可弹出资源详情,点击切换按钮就可以进行CPU和GPU环境的切换,如下图所示:
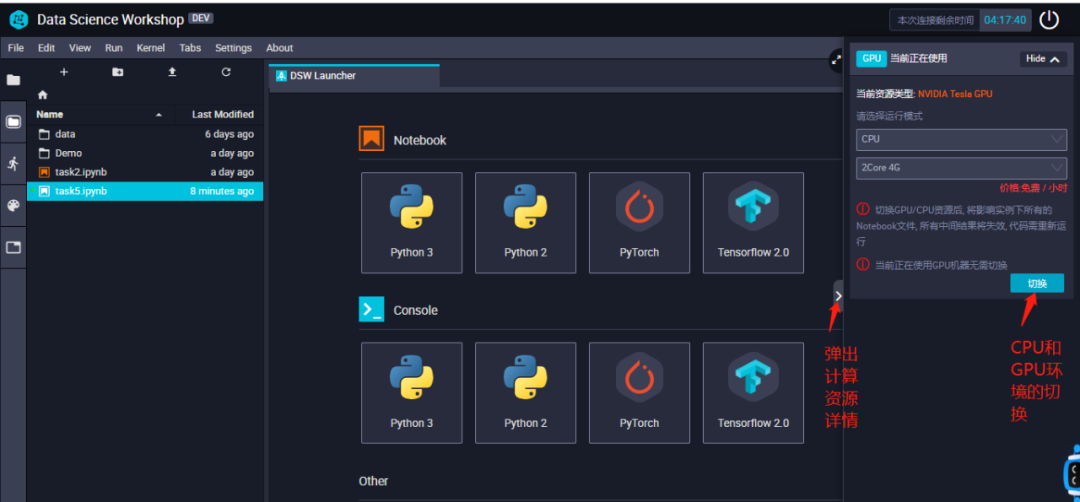
在⽂件资源管理区的顶部还有4个按钮,从左到右分别对应的是:打开DSW Launcher启动器,新建⽂件夹,上传⽂件以及刷新当前⽂件夹。
在⽂件夹左侧还有⼀栏Tab,每个图标从上到下分别代表了:⽂件资源管理器,案例代码,正在运⾏的Notebook,命令⾯板,在⼯作区打开的Tab。
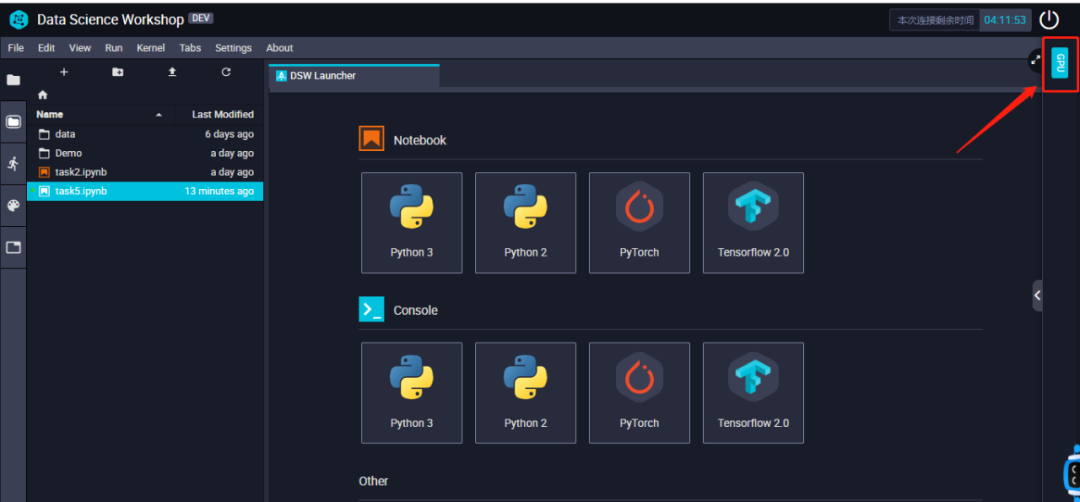
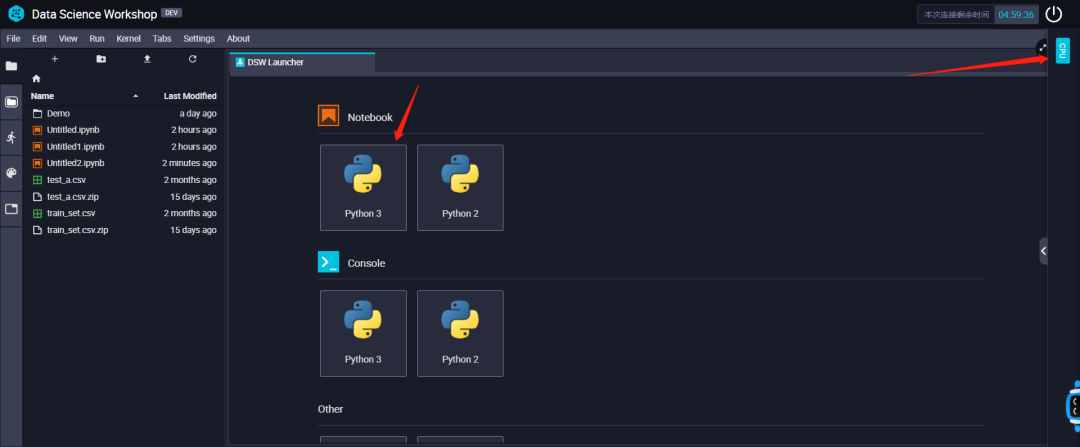
了解了DSW的环境以后,然后我们回到DSW Launcher启动器,也就是⼯作区默认打开的界⾯,我们可以看到cpu环境下和gpu环境下以及对应的kernel环境,可以根据自己的需求进行选择。
三、创建一个notebook实例
以GPU环境下为例,在工作区默认打开的界面,然后点击Notebook区域中的PyTorch为例,如下所示:
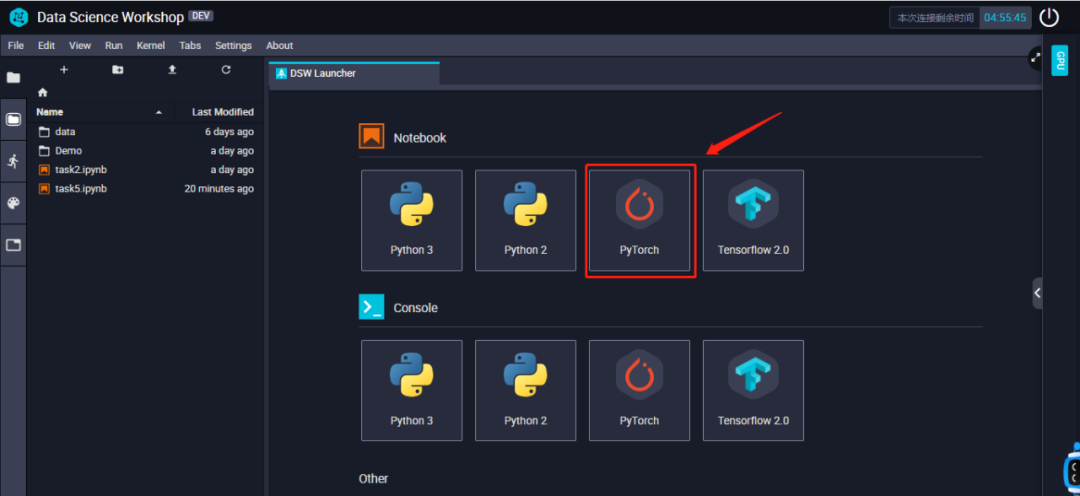
点击了PyTorch这个图标之后,DSW实验室就会⾃动为我们创建⼀个ipynb notebook⽂件。我们在左侧的资源管理器中也会看到。如下图所示:
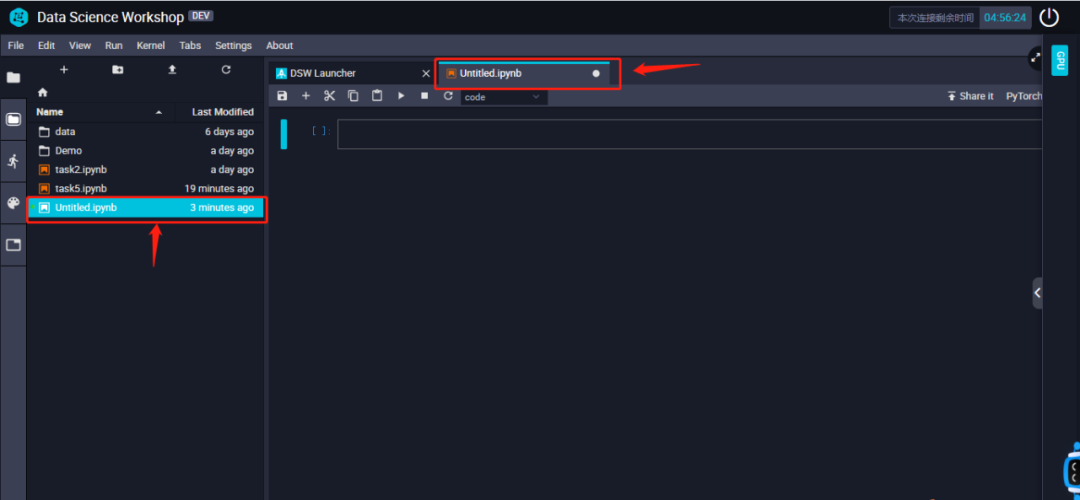
⽤⿏标点击第⼀个框框(我们下⾯以Cell称呼),我们就可以开始从只读模式进⼊编辑模式开始写代码了。
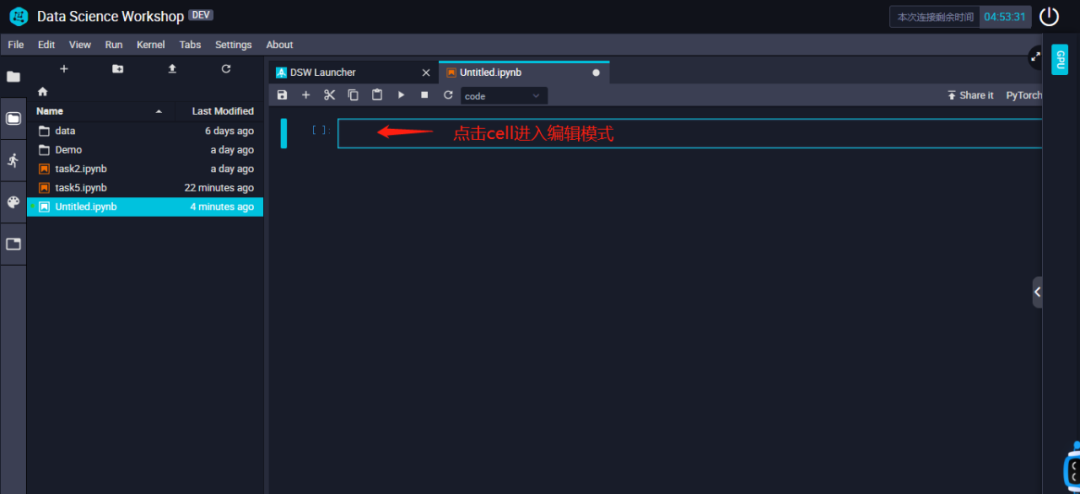
相信熟悉Notebook的你到这⼀步就很清楚之后怎么操作了~如果你以前没有⽤过也没关系,继续往下看。
四、数据获取(以NLP比赛为例)
4.1 数据获取
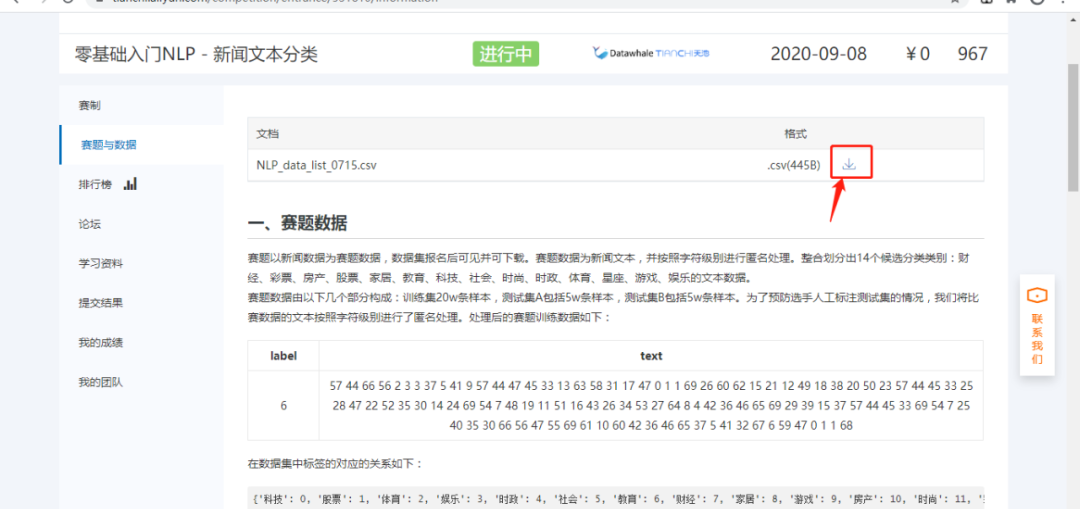
步骤1:首先需要在新闻文本分类挑战赛报名,在赛题与数据栏中,点击红框下载数据。
步骤2:打开所下载的文件,发现下载的并非是数据集本身,而是提供了训练集数据,测试集数据,sub提交样例的下载链接。
方式1:直接将数据下载至本地,再通过本地进行数据上传
将步骤2获取的训练集和测试集链接复制到浏览器中,下载数据集。下载后,上传至文件区。
方式2:通过!wget xxxx(所需数据的链接)进行下载,但是注意只能在CPU环境下,GPU环境不支持联网。具体操作如下:
 运行以下代码块。
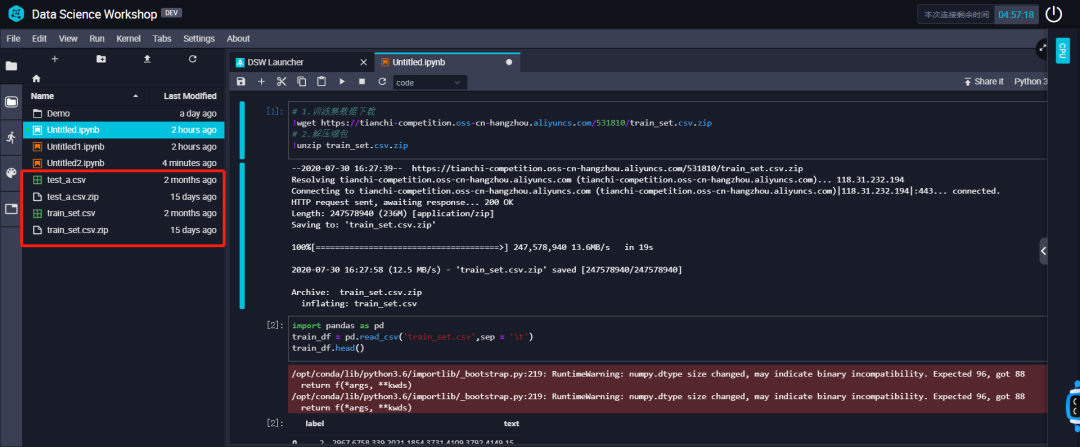
运行以下代码块。# 1.训练集数据下载!wget https://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531810/train_set.csv.zip# 2.解压缩包!unzip train_set.csv.zip# 1.训练集数据下载!wget https://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531810/test_a.csv.zip# 2.解压缩包!unzip test_a.csv.zip
拷贝上方的命令至cell后,我们按下 shift + enter回⻋ 这两个键,就可以看到我们的执⾏结果了,如下图所示:
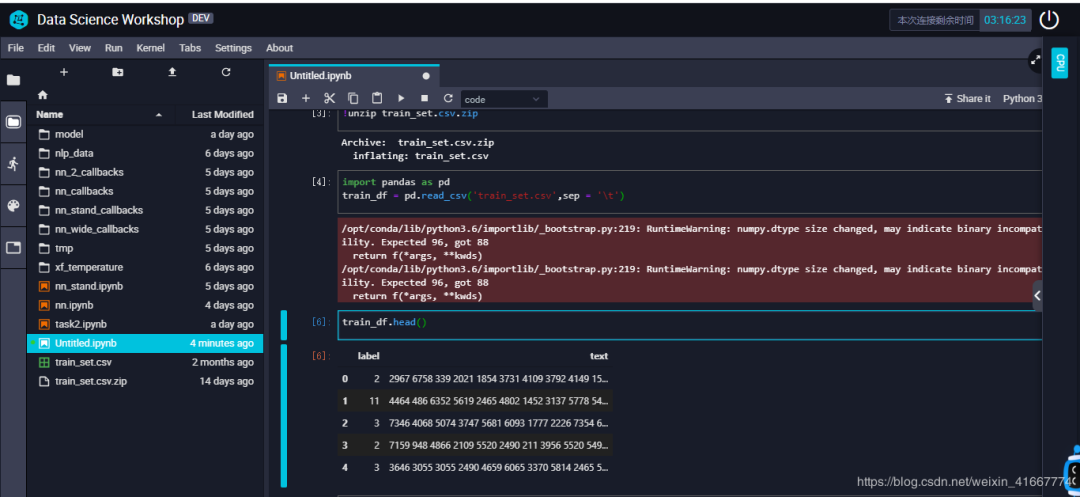
4.2 数据读取
import pandas as pdtrain_df = pd.read_csv('train_set.csv',sep = '\t')train_df.head()
五、训练模型
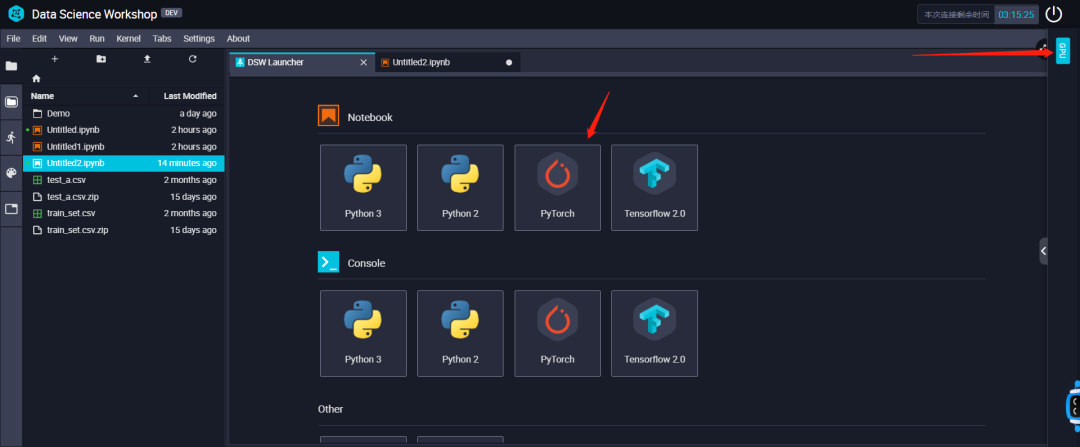
在这里,我们新建一个GPU环境下kernel选择PyTorch的文件。
在创建好的notebook中,首先安装所需的库
# Count Vectors+RidgeClassfierimport pandas as pdfrom sklearn.linear_model import RidgeClassifierfrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.metrics import f1_scor
读取数训练集及测试集数据
train_df = pd.read_csv('train_set.csv',sep='\t')test_df = pd.read_csv('test_a.csv')
我们查看一下数据的大小
test_df.shape# (50000, 1)
然后可以建模训练
# 建模训练vectorizer = CountVectorizer(max_features=3500)all_data_df = pd.concat([train_df,test_df],axis =0)train_test = vectorizer.fit_transform(all_data_df['text'])train_len = train_df.shape[0]train_count = train_test[:train_len]test_count = train_test[train_len:]clf = RidgeClassifier()num = int(train_len*0.9)clf.fit(train_count[:num], train_df['label'].values[:num])
若页面如下图所示,并非报错,计算时间较长,请耐心等待即可。
在测试集预测一下分数
# 最后在测试集预测一下分数val_pred = clf.predict(train_count[num:])print(f1_score(train_df['label'].values[num:], val_pred, average='macro'))
最后的最后求一波分享!
YOLOv4 trick相关论文已经下载并放在公众号后台
关注“AI算法与图像处理”,回复 “200714”获取
个人微信 请注明:地区+学校/企业+研究方向+昵称 如果没有备注不拉群!
