
鹅厂程序员爆肝整理,万字长文讲透MongoDB中的锁

👉 导读
MongoDB 作为世界领先的文档型数据库广受开发者的喜爱,而 MongoDB 中的锁又为数据库高并发的读写提供了保障。本文从 MongoDB 的慢日志引入 MongoDB 中的锁,通过介绍 MongoDB 中的资源分类、锁分类、锁结构、锁实现以及锁的使用情况与查询方法,深入浅出地介绍 MongoDB 中锁的相关技术。 长文干货,建议先点赞收藏再细细阅读~👉 目录
1 引子:从 MongoDB 的慢日志引入 2 MongoDB 的锁与资源分类 3 MongoDB 的锁矩阵 4 浅入:MongoDB 的锁实现01
引子:从 MongoDB 的慢日志引入
在我们日常的数据库使用中,经常会与慢日志打交道。而在使用 MongoDB 时,慢日志也常作为 MongoDB 读写性能的衡量标志之一。笔者刚入职时,自己也刚开始接触数据库中的慢日志概念,不经会发出疑问:
什么是慢日志?
慢日志的全称为“Slow Query Log”,正如其英文直译,代表着对返回较慢的查询请求的日志记录,最开始是 MySQL 中对执行较慢查询的统计,主要用于记录 MySQL 中执行时间超过指定时间的 SQL 语句;通过查询慢日志,我们可以查找出哪些语句的执行效率较低,并进行针对性的查询优化。
MongoDB 中慢日志的概念与 MySQL 中的相同,一般将执行时间大于 100ms 的请求称为慢请求,内核会在执行时统计请求的执行时间,并记录下执行时间大于 100ms 的请求相关信息,打印至内核运行日志中,记录为慢日志。通过查看 MongoDB 的慢日志,我们可以获得对应请求与内核当前运行状态的诸多信息,并可以依次为依据做出对应的优化策略。
MongoDB 也可以通过多种方式采集、记录慢请求的相关信息。
如在 MongoDB 中,可以通过以下语句设定 Database Profiler 用于过滤、采集请求,用于慢操作的分析。
# 查看Databaseprofiler配置db.getProfilingStatus()
# 设置Databaseprofiler用于采集慢请求db.setProfilingLevel(<level>, <options>)
其中 level 代表 profiling 的等级,有如下三个等级:
-
0:不开启 profiler(默认不开启);
-
1:开启 profiler 采集慢请求(默认采集 100ms 以上);
-
2:开启 profiler 采集所有的操作。
options 则包含以下选项:
-
slowMs:慢请求判断毫秒数,只有大于 slowMs 的请求才会被 profiler 标记并记录为慢请求,默认 100ms;
-
sampleRate:采集慢操作的采样率;
-
filter:采样的过滤规则。
在设置 Profiler 后,满足条件的慢请求将会被记录在 system.profile 表中,该表为一个 capped collection,可以通过 db.system.profile.find() 来过滤与查询慢请求的记录,举个例子:
>db.system.profile.find().pretty(){"op" : "query", # 操作类型,可为command、count、distinct、geoNear、getMore、group、insert、mapReduce、query、remove、update"ns" : "test.report", # 操作的目标namespace库表"command" : { # 操作的具体command"find" : "report",......},"cursorid" : 33629063128, # query与getMore使用的cursor id"keysExamined" : 101, # 为执行操作扫描的索引键数量"docsExamined" : 101, # 为执行操作扫描的文档数据"fromMultiPlanner" : true,"numYield" : 2, # 执行操作时让其他操作完成的次数"nreturned" : 101, # 返回的文档数量"queryHash" : "811451DD", # 查询的hash"planCacheKey" : "759981BA", # 查询计划的key"locks" : { # 锁信息"Global" : { # 全局锁"acquireCount" : {"r" : NumberLong(3),"w" : NumberLong(3)}},"Database" : { # Database锁"acquireCount" : { "r" : NumberLong(3) },"acquireWaitCount" : { "r" : NumberLong(1) },"timeAcquiringMicros" : { "r" : NumberLong(69130694) }},"Collection" : { # Collection锁"acquireCount" : { "r" : NumberLong(3) }}},"storage" : { # 存储情况"data" : {"bytesRead" : NumberLong(14736), # 从磁盘中读取的数据大小"timeReadingMicros" : NumberLong(17) # 从磁盘读取数据的耗时}},"responseLength" : 1305014, # response的大小"protocol" : "op_msg", # 消息的协议"millis" : 69132, # 执行时间,milliseconds"planSummary" : "IXSCAN { a: 1, _id: -1 }", # 执行计划,这里代表走索引查询"execStats" : { # 操作执行的详细步骤信息"stage" : "FETCH", # 操作类型,如COLLSCAN、IXSCAN、FETCH"nReturned" : 101, # 返回文档数......},"ts" : ISODate("2019-01-14T16:57:33.450Z"), # 时间戳"client" : "127.0.0.1", # 客户端信息"appName" : "MongoDB Shell", # appName"allUsers" : [{"user" : "someuser","db" : "admin"}],"user" : "someuser@admin" # 执行的用户信息}
上述信息记录了慢操作的详细的一些信息,可方便的用于慢操作的查询与分析,如以下几点:
-
command:记录的请求的内容,可以帮助我们分析慢请求的原因;
-
locks:请求与锁的相关信息,执行请求需要获取的锁,以及锁排队等待、获取时长等信息;
-
writeConflicts(只有写请求):写冲突,在同时写一个文档时即会造成些冲突;
-
millis:慢请求最终执行时长;
-
planSummary:如执行 COLLSCAN 全表扫就会比执行 IXSCAN 索引话费更多的资源与时间;
-
execStats:执行计划的具体执行情况,方便得知请求的执行全貌。
从以上几个方面分析,可以大致得知请求的执行情况,用于分析慢请求产生的原因。一般而言,慢请求的产生无非以下几点原因:
-
CPU负载高:如频繁的认证/建链接会使大量CPU消耗,导致请求执行慢;
-
等锁/锁冲突:一些请求需要获取锁,而如果有其他请求拿到锁未释放,则会导致请求执行慢;
-
全表扫描:查询未走索引,导致全表扫描,会导致请求执行慢;
-
内存排序:与上述情况类似,未走索引的情况下内存排序导致请求执行慢;
-
但开启分析器 Profiler 是需要一些代价的(如影响内核性能),且一般来说默认关闭,故在处理线上问题时,我们往往只能拿到内核日志中记录的慢日志信息。
一条典型的 MongoDB 慢日志举例如下:
{"t": { # 时间戳"$date": "2020-05-20T20:10:08.731+00:00"},"s": "I", # 日志等级,分为F、E、W、I,分别为Fatal、Error、Warning、Info"c": "COMMAND", # 执行请求类型,分为ACCESS、COMMAND、CONTROL、ELECTION、FTDC、GEO、INDEX等"id": 51803, # 慢日志的日志id"ctx": "conn281", # 链接的信息"msg": "Slow query", # 慢日志信息,代表是慢请求"attr": { # 参数详情"type": "command", # 请求类型"ns": "stocks.trades", # Namespace,请求的库表"appName": "MongoDB Shell", # client的app name"command": { # 请求详情"aggregate": "trades", # 请求为aggregate,且在trades表上执行......},"planSummary": "COLLSCAN", # 请求执行了COLLSCAN"cursorid": 1912190691485054700,"keysExamined": 0,"docsExamined": 1000001, # 查询的文档数,由于是COLLSCAN所以查询较多"hasSortStage": true,"usedDisk": true,"numYields": 1002, # 查询让渡其他请求执行数"nreturned": 101, # 返回的文档数,远远小于docsExamined,全表扫消耗了大量时间"reslen": 17738,"locks": { # 锁信息"ReplicationStateTransition": {"acquireCount": {"w": 1119}},"Global": {"acquireCount": {"r": 1119}},"Database": {"acquireCount": {"r": 1119}},"Collection": {"acquireCount": {"r": 1119}},"Mutex": {"acquireCount": {"r": 117}}},"storage": {......},"remote": "192.168.14.15:37666","protocol": "op_msg","durationMillis": 22427}}
从上述慢请求中,一些信息是比较直观的,如 planSummary 为 COLLSCAN 代表查询走了全表扫,而全表扫描一般意味着性能较差;如 docsExamied 若远大于 nreturned ,则代表着请求执行的效率较低,性能较差。而也有一些信息不那么直观,如locks虽然代表了请求的锁信息,但其中又分为不少子项目,第一眼看上去不禁会让人感到疑惑:
-
ReplicationStateTransation、Global、Database、Collection、Mutex 分别代表什么意思?
-
W、R、w、r 分别代表什么含义?
-
锁数量的大小意味着什么?
-
不同锁之间是什么关系?有什么联系?
-
MongoDB 中的锁是如何实现的?结构如何?
-
我们带着以上问题开始逐步了解 MongoDB 中的锁。
02
MongoDB 的锁与资源分类
MongoDB 支持并发读写操作,故需要用锁来确保并发时的数据一致性。在 MongoDB 中,不同的请求会对不同的资源执行请求,故加锁的操作也是在不同的资源上进行加锁。通过对资源进行分层与层级管理,以及使用不同类型的锁执行锁机制来避免并发冲突。
2.1 资源分类
在 MongoDB 中对资源进行了层级划分,锁本身的 lock_manager 并不区分自己属于哪个资源,且不同层级的资源之间永不互斥(不会互相影响)。一般而言,MongoDB 中的资源按以下类型进行分类,且从上到下优先级依次降低。
在4.4版本之前(包括),资源分类如下:
enum ResourceType {RESOURCE_INVALID = 0,
RESOURCE_PBWM, // 并发批量写资源锁
RESOURCE_RSTL, // 副本集成员状态转换锁,状态包括如STARTUP、PRIMARY、SECONDARY、RECOVERING等
RESOURCE_GLOBAL, // global操作的资源锁,如reIndex、renameCollection、replSetResizeOplog等操作都会acquire global W 锁
RESOURCE_DATABASE, // database级别操作的资源锁,如cloneCollectionCapped、collMod、compact、convertToCapped等操作都会acquire databsae W 锁RESOURCE_COLLECTION, // collection级别操作的资源锁,如createCollection、createIndexes、drop等操作都会acquire collection W 锁RESOURCE_METADATA, // 元数据相关的锁
RESOURCE_MUTEX, // 剩余的不与存储层相关的其他资源的锁
ResourceTypesCount};
在4.4版本之后,资源分类如下:
// 资源类型大致与4.4版本之前一致,只是global资源有所变化enum ResourceType {RESOURCE_INVALID = 0,RESOURCE_GLOBAL,RESOURCE_DATABASE,RESOURCE_COLLECTION,RESOURCE_METADATA,RESOURCE_MUTEX,ResourceTypesCount};
// 使用枚举来表示所有的global资源enum class ResourceGlobalId : uint8_t {kParallelBatchWriterMode,kFeatureCompatibilityVersion,kReplicationStateTransitionLock,kGlobal,
kNumIds};
从5.0开始,将 RESOURCE_PBWM、RESOURCE_RSTL、RESOURCE_GLOBAL 全部归为了 RESOURCE_GLOBAL,且使用一个 enum 对其进行划分。从5.0开始,还新增了一批 lock-free read 操作,这些操作在其他操作持有同 collection 的排他写锁时也不会被阻塞,如 find、count、distinct、aggregate、listCollections、listIndexes 等,其中 aggregate 中包含对 collection 的写入时,会持有 collection 的意向排他锁。
以上资源层级自上而下优先级依次降低。为了防止出现死锁,一般而言在对低优先级的资源加锁时,都需要先对更高优先级的资源加意向锁。如:在对 RESOURCE_COLLECTION 加排它锁之前,需要对 RESOURCE_DATABASE以及 RESOURCE_GLOBAL 加意向排他锁。
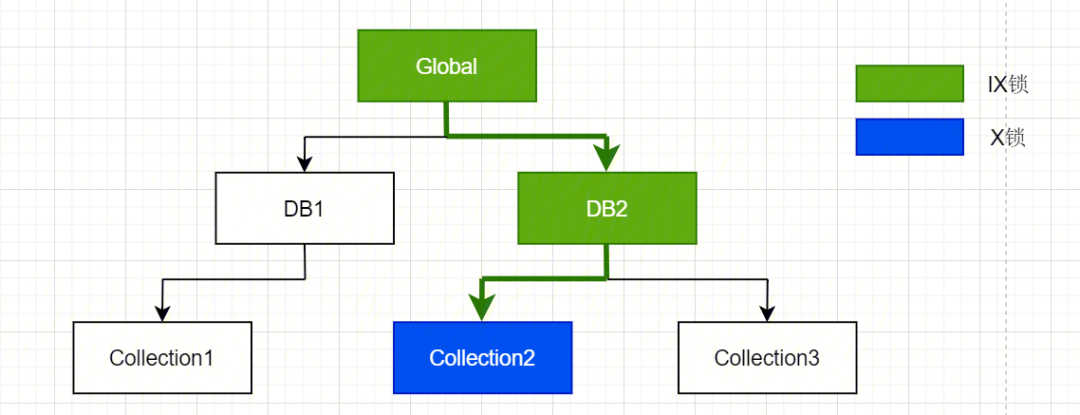
故该操作的锁获取情况为:
{"locks": {"Global": {"acquireCount": {"w": 1}},"Database": {"acquireCount": {"w": 1}},"Collection": {"acquireCount": {"W": 1}},}}
2.2 锁分类
MongoDB 中不仅对资源进行了层级划分,还对锁的类型进行了划分,如上文中提到的意向锁、排它锁、共享锁等。本节讲述在同一层级资源中,通过划分不同的锁类型,来高效地解决并发关系。
在 MongoDB 中为了提高并发效率,提供了类似读写锁的模式,即共享锁(Shared, S)(读锁)以及排他锁(Exclusive, X)(写锁),同时,为了解决多层级资源之间的互斥关系,提高多层级资源请求的效率,还在此基础上提供了意向锁(Intent Lock)。即锁可以划分为4中类型:
enum LockMode {MODE_NONE = 0,MODE_IS = 1, //意向共享锁,意向读锁,rMODE_IX = 2, // 意向排他锁,意向写锁,wMODE_S = 3, // 共享锁,读锁,RMODE_X = 4, // 排它锁,写锁,W
LockModesCount};
有了读写锁,为什么还要再划分意向锁?我们知道在多层级资源加锁过程中,对低层级资源加锁时还需要对高层级资源添加意向锁。由于往往高层级的资源对低层级的资源是包含关系,故加意向锁的操作目的是:在对低层级资源加锁时,通过对上一级资源加意向锁告诉外界,在高级资源中有某个低级资源被添加了锁。
意向锁有什么用呢?百科上的解释为:
如果另一个任务企图在某表级别上应用共享或排他锁,则受由第一个任务控制的表级别意向锁的阻塞,第二个任务在锁定该表前不需要检查各个页或行锁,而只需检查表上的意向锁。
话说的比较绕,举个例子:
-
假如有一个操作 A 锁住了某一个 collectionX,此时有另一个操作 B 需要对 DB1 进行操作,而 collectionX 又属于 DB1,此时在操作 B 加锁之前,需要进行以下步骤的 Check:
-
检查 DB1 的库锁是否被其他操作持有;
-
依次检查 DB1 下所有的 collection,确认是否有其他操作持有其中之一的 collection 锁;
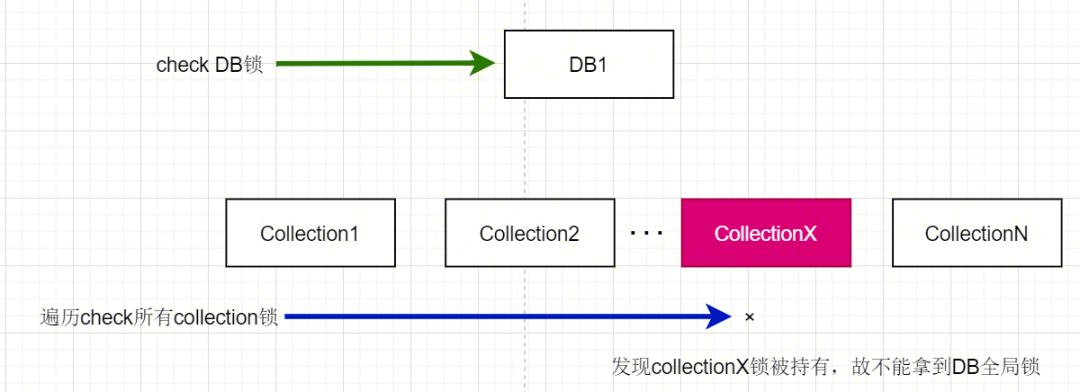
这里需要遍历所有的次级资源锁进行判断,若某 DB 下有很多的 collection,则遍历拿锁的时间线性增长,故引入了意向锁的概念。当添加意向锁后,操作 A 再给 collectionX 加锁前,还需要给 DB1 加一把意向锁;这样在操作 B 在给 DB1 加锁前,上述 check 步骤变为如下:
-
检查 DB1 的库锁是否被其他操作持有;
-
检查 DB1 的意向锁是否被其他操作持有。
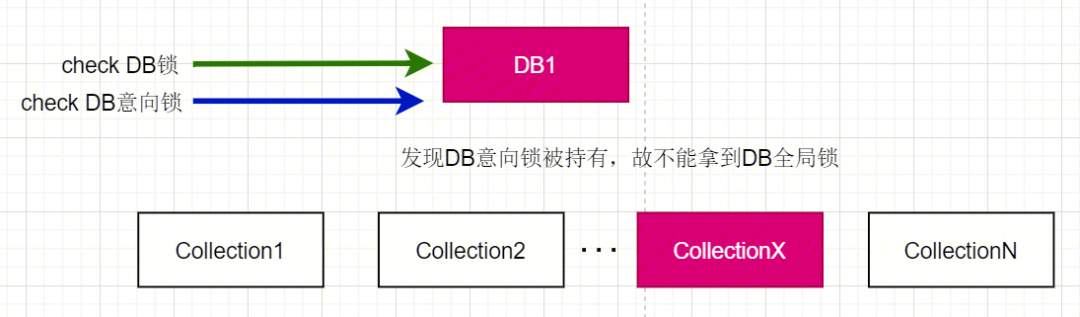
这样在请求上级资源的锁时,只需要 check 上级资源的意向锁是否被占用,如被占用则意味着有次级资源的锁被占用,这里不必再去遍历所有次级资源的锁占用情况,使锁获取的判断更加高效。
03
MongoDB 的锁矩阵
在有了共享/排他锁与意向锁的分类后,MongoDB 的锁可以被分为4类;同时,不同类型的锁与其他类型锁之间有不同的排他性,通过这种排他性关系可以实现提升锁的效率。这种特殊的排他性可以被归纳为锁矩阵。
MongoDB 的锁矩阵如下:
/*** MongoDB锁矩阵,可以根据锁矩阵快速查询当前想要加的锁与已经加锁的类型是否冲突** | Requested Mode | Granted Mode |* |----------------|:------------:|:-------:|:--------:|:------:|:--------:|* | | MODE_NONE | MODE_IS | MODE_IX | MODE_S | MODE_X |* | MODE_IS | + | + | + | + | |* | MODE_IX | + | + | + | | |* | MODE_S | + | + | | + | |* | MODE_X | + | | | | |*/
根据锁矩阵,可以根据请求所需的锁类型以及当前请求对应资源加锁的类型来直接得出结论是否可以加锁,同样举个例子:
如请求 A 在对 collection2 执行读操作,此时需要获取 collection2 的 IS 锁(Intent Shard Lock),由上述资源层级优先级关系,需要向上依次获得 DB2 的 IS 锁以及 Global 的 IS 锁:
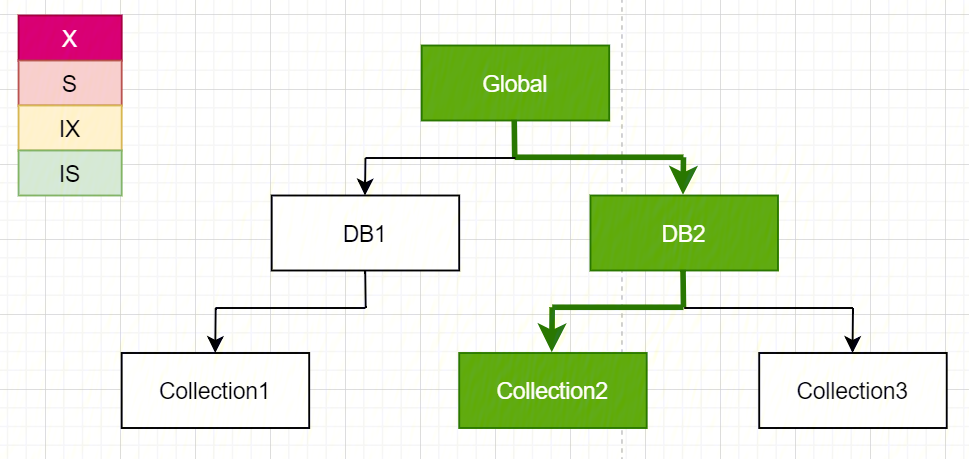
此时请求 B 需要对 DB2 执行 drop 操作,需要获取 DB2 的 X 锁(Exclusive Lock),由上述资源层级优先关系,需要向上获得 Global 的 IX 锁,根据 MongoDB 的锁矩阵:
-
Global:IX 锁与 IS 锁兼容,故可以获取到 Global 的 IX 锁;
-
DB2:X 锁与 IS 锁不兼容,故不能获取到 DB2 的 X 锁,需要等待 DB2 的 IS 锁释放;
故此时操作 B 对 DB2 的 drop 操作将无法执行,因为加锁不成功,会等待
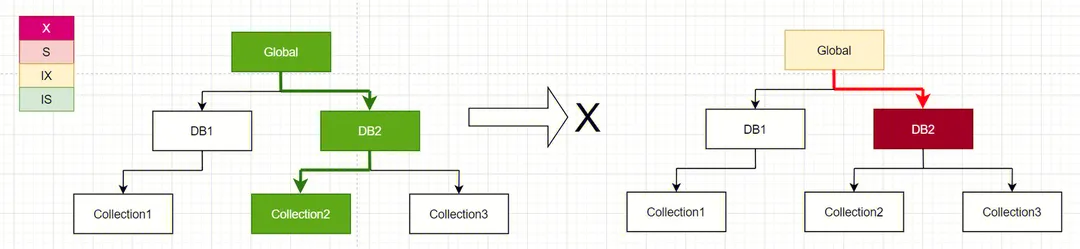
此时请求 C 需要对 collection2 执行写入操作,需要获取 collection2 的 IX 锁(Intent Exclusive Lock),由上述资源层级优先关系,需要依次向上获得 DB2 的 IX 锁,Global 的 IX 锁,根据 MongoDB 的锁矩阵:
● Global:IX 锁与 IS 锁兼容,故可以获取到 Global 的 IX 锁;
● DB2:IX 锁与 IS 锁兼容,故可以获取到 DB2l 的 IX 锁;
● Collection2:IX 锁与 IS 锁兼容,故可以获取到 Collection2l 的 IX 锁;
故此操作可以拿到锁,执行成功。
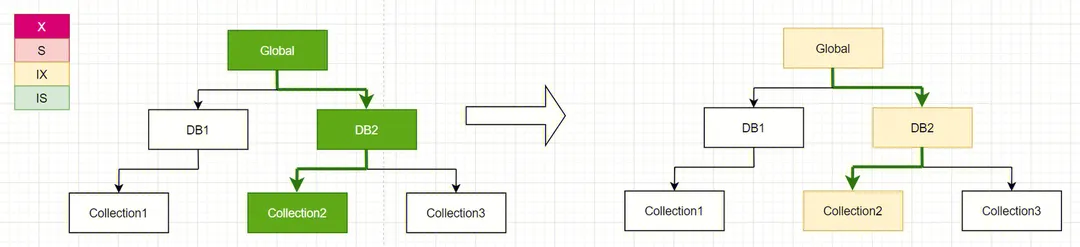
通过以上对资源的层级分类,以及通过使用意向锁、读写锁的分类,可以相对高效的通过锁做到高并发。
以上提到了 Global、Database、Collection 三个资源级别以及对应的锁,而 MongoDB 最小粒度的资源为 Document,而 Document 粒度的锁则使用的是 WT 引擎里的锁,在 MongoDB 中,操作一般为乐观并发控制,如写操作,会先假设没有冲突对数据进行修改,而只有真正修改数据时才会加锁,而 Document 锁加失败时则会遭遇写冲突(WriteConflict),而写冲突时 MongoDB 会自动重试,这里不多做讨论。
04
浅入:MongoDB 的锁实现
了解了 MongoDB 中资源类型与对应锁的行为后,我们从代码与实现层面来分析一下 MongoDB 锁的实现与调用。MongoDB 中粒度最细的资源锁为 collection 级别的锁,我们看下,在 MongoDB 的代码中如何获取 collection 的锁呢?
在 catalog_raii.h 中有与资源相关的定义与 RAII-style 的实现,有关 RAII-style 可以参考: wiki-RAII ,全称为“资源获取即初始化”,本质是 C++ 这类面向对象编程风格中将资源的获取与生命周期与对象的生命周期强绑定的一种方式,说得直白一点为:以对象代表需要获取的资源,在对象初始化时完成资源的获取(构造函数),在对象析构的时候完成资源的释放(析构)。
可以看到对于 Collection 资源,定义了以下类:
// catalog_raii.h
/*** RAII-style的类,在获取collection锁时会按照以下矩阵依次获取更高资源层级的锁** | modeColl | Global Lock Result | DB Lock Result | Collection Lock Result |* |----------+--------------------+----------------+------------------------|* | MODE_IX | MODE_IX | MODE_IX | MODE_IX |* | MODE_X | MODE_IX | MODE_IX | MODE_X |* | MODE_IS | MODE_IS | MODE_IS | MODE_IS |* | MODE_S | MODE_IS | MODE_IS | MODE_S |*/class AutoGetCollection {...
public:// 构造函数,用于调用获取资源AutoGetCollection(......);
......
protected:boost::optional<AutoGetDb> _autoDb;std::vector<Lock::CollectionLock> _collLocks;......};
在 AutoGetCollection 的实现中,也可以看到需要先获取 global/RSTL 与对应的 Database 锁,再会去获取 collection locks:
// catalog_raii.cpp
AutoGetCollection::AutoGetCollection(......) {invariant(!opCtx->isLockFreeReadsOp());
......
// 获取global/RSTL锁以及所有对应的DB锁_autoDb.emplace(opCtx,!nsOrUUID.dbname().empty() ? nsOrUUID.dbname() : nsOrUUID.nss()->db(),isSharedLockMode(modeColl) ? MODE_IS : MODE_IX,deadline,secondaryDbNames);......
// 获取collection锁if (secondaryDbNames.empty()) {uassertStatusOK(nsOrUUID.isNssValid());_collLocks.emplace_back(opCtx, nsOrUUID, modeColl, deadline);} else {acquireCollectionLocksInResourceIdOrder(opCtx, nsOrUUID, modeColl, deadline, secondaryNssOrUUIDs, &_collLocks);}......}
如上文中的定义,AutoGetCollection 中如果要获取某 mode 的 collection 锁,需要依次获取上层资源的意向锁;在定义中可以看到,有一个std::vector<CollectionLock>代表需要获取的 collection 对应的锁,而boost::optional<AutoGetDb>则代表了对应上级的 Database 资源。获取 collection 锁之前,会根据获取的 mode 进行转换,如果获取的是 S 或 IS,则会获取对应 Database 的 IS 锁;如果获取的是 X 或 IX,则会获取对应 Database 的 IX 锁。
获取 Collection 资源前需要先获取对应的 Database 资源,有以下定义:
// catalog_raii.h
// RAII-style class, 可获取DB级别的资源锁class AutoGetDb {......
public:// 构造函数,用于调用获取资源AutoGetDb(......);......private:std::string _dbName;Lock::DBLock _dbLock;Database* _db;std::vector<Lock::DBLock> _secondaryDbLocks;};
其中 Lock::DBLock 即为 Database 持有的资源锁,在获取 Database 级别的锁之前,首先要获取其中包含的 Global 级别的锁。
4.1 锁的分类实现
上述流程中描述了获取低级别的资源锁前需要先获取高级别的资源锁,分别包括:
-
GlobalLock:代表着全局的资源锁;
-
DBLock:代表着 Database 资源锁;
-
CollectionLock:代表着 Collection 资源锁。
以上锁的定义都在 d_concurrency.h 文件中,我们分别来看其实现:
// d_concurrency.h
/*** Collection 级别的锁* 该锁支持以下几种类型:* MODE_IS: concurrent collection access, requiring read locks* MODE_IX: concurrent collection access, requiring read or write locks* MODE_S: shared read access to the collection, blocking any writers* MODE_X: exclusive access to the collection, blocking all other readers and writers** 在获取collection锁之前需要获取对应的意向DB锁*/class CollectionLock {CollectionLock(const CollectionLock&) = delete;CollectionLock& operator=(const CollectionLock&) = delete;
public:CollectionLock(OperationContext* opCtx,const NamespaceStringOrUUID& nssOrUUID,LockMode mode,Date_t deadline = Date_t::max());
CollectionLock(CollectionLock&&);~CollectionLock();
private:ResourceId _id;OperationContext* _opCtx;};
从注释中可以看到,在获取 Collection 锁之前需要获取对应的 Database 锁。在 private 域中 ResourceId 代表了需要加锁的 Collection 对应的 ResourceId,在 MongoDB 所有的资源都通过 Resource 标识;而 OperationContext 中则有真正要加锁的内容,可以从 CollectionLock 的构造函数实现中看到具体的加锁过程:
// d_concurrency.cpp
Lock::CollectionLock::CollectionLock(......): _opCtx(opCtx) {if (nssOrUUID.nss()) {auto& nss = *nssOrUUID.nss();_id = {RESOURCE_COLLECTION, nss.ns()};
invariant(nss.coll().size(), str::stream() << "expected non-empty collection name:" << nss);dassert(_opCtx->lockState()->isDbLockedForMode(nss.db(),isSharedLockMode(mode) ? MODE_IS : MODE_IX));
_opCtx->lockState()->lock(_opCtx, _id, mode, deadline);return;}......bool locked = false;NamespaceString prevResolvedNss;do {if (locked) {_opCtx->lockState()->unlock(_id);}
_id = ResourceId(RESOURCE_COLLECTION, nss.ns());_opCtx->lockState()->lock(_opCtx, _id, mode, deadline);locked = true;
prevResolvedNss = nss;nss = CollectionCatalog::get(opCtx)->resolveNamespaceStringOrUUID(opCtx, nssOrUUID);} while (nss != prevResolvedNss);}
以上,是通过_opCtx->lockStat()->lock()获取对应的资源锁。而锁的定义在 OperationContext 中是这样定义的:
// operation_context.h
class OperationContext : public Interruptible, public Decorable<OperationContext> {OperationContext(const OperationContext&) = delete;OperationContext& operator=(const OperationContext&) = delete;public:......
// Interface for locking. Caller DOES NOT own pointer.Locker* lockState() const {return _locker.get();}
......
private:......
std::unique_ptr<Locker> _locker;......};
其中 _locker 为 Locker 的一个 unique 指针,其中 Locker 为一个虚类作为 Interface,定义锁的结构及行为,定义在 locker.h 文件中,其一般的实现为 LockerImpl,定义在 lock_state.h 文件中。现先不讨论 Locker 的具体结构、继承以及实现,只需要先知道是通过调用 OperationConetext->lockState()->lock() 接口来进行的锁的获取。
获取 Collection 锁之前需要先获取对应的 Database 锁,实现方式:
// d_concurrency.h/*** Database资源锁.** 该锁支持以下几种类型::* MODE_IS: concurrent database access, requiring further collection read locks* MODE_IX: concurrent database access, requiring further collection read or write locks* MODE_S: shared read access to the database, blocking any writers* MODE_X: exclusive access to the database, blocking all other readers and writers** 在获取DB锁前需要获取对应类型的global锁*/class DBLock {public:DBLock(OperationContext* opCtx,StringData db,LockMode mode,Date_t deadline = Date_t::max(),bool skipGlobalAndRSTLLocks = false);......
private:const ResourceId _id;OperationContext* const _opCtx;......
// Acquires the global lock on our behalf.boost::optional<GlobalLock> _globalLock;};
在 DBLock 的定义中,以 ResourceId 作为资源标识,同样通过 OperationContext 来访问真正的资源锁,但要注意,在 DBLock 的定义中多了 boost::optional<GlobalLock>,表示 global 级别的锁,即在为每个 Database 基本锁加锁前,理论上都需要先为 Global 锁加锁,可以看到 DBLock() 构造函数实现如下:
// concurrency.cpp
Lock::DBLock::DBLock(......): _id(RESOURCE_DATABASE, db), _opCtx(opCtx), _result(LOCK_INVALID), _mode(mode) {
if (!skipGlobalAndRSTLLocks) {_globalLock.emplace(opCtx,isSharedLockMode(_mode) ? MODE_IS : MODE_IX,deadline,InterruptBehavior::kThrow);}massert(28539, "need a valid database name", !db.empty() && nsIsDbOnly(db));
_opCtx->lockState()->lock(_opCtx, _id, _mode, deadline);_result = LOCK_OK;}
如果设定了 skipGlobalAndRSLocks,则无需获取 Global 锁,否则都需要获取对应 mode 的 Global 锁。同时通过 OperationContext->lockState()->lock() 接口获取对应的 Database 资源锁。
获取 Database 锁之前需要先获取 Global 级别的锁,我们继续看 Global 锁的实现如下:
// d_concurrency.h
// Global级别的资源锁.class GlobalLock {public:GlobalLock(OperationContext* opCtx, LockMode lockMode): GlobalLock(opCtx, lockMode, Date_t::max(), InterruptBehavior::kThrow) {}
// A GlobalLock with a deadline requires the interrupt behavior to be explicitly defined.GlobalLock(OperationContext* opCtx,LockMode lockMode,Date_t deadline,InterruptBehavior behavior,bool skipRSTLLock = false);......
private:......OperationContext* const _opCtx;LockResult _result;ResourceLock _pbwm;ResourceLock _fcvLock;......};// Global exclusive lockclass GlobalWrite : public GlobalLock {};// Global shared lockclass GlobalRead : public GlobalLock {};
除了 GlobalLock 外,还有 GlobalRead 与 GlobalWrite,这里不详细讨论,仅讨论 GlobalLock。可以看到,GlobalLock 中定义了两个接口:
-
_takeGlobalLockOnly():仅占用 Global 锁;
-
_takeGlobalAndRSTLLocks():同时占用 RSTL 与 Global 锁;
同时可以看到还有 _pbwm 锁以及 _fcv 锁,这两个锁均以 ResourceLock 对象的形式实现。
// General purpose RAII wrapper for a resource managed by the lock managerclass ResourceLock {ResourceLock(const ResourceLock&) = delete;ResourceLock& operator=(const ResourceLock&) = delete;
public:......// Acquires lock on this specified resource in the specified mode.void lock(OperationContext* opCtx, LockMode mode, Date_t deadline = Date_t::max());void unlock();bool isLocked() const;
private:const ResourceId _rid;Locker* const _locker;LockResult _result;};
ResourceLock 中同样有代表资源的 ResourceId,以及代表实际锁的 Locker。下面来看 GlobalLock 的构造函数的实现中是如何获取锁的:
Lock::GlobalLock::GlobalLock(OperationContext* opCtx,LockMode lockMode,Date_t deadline,InterruptBehavior behavior,bool skipRSTLLock): _opCtx(opCtx),_result(LOCK_INVALID),_pbwm(opCtx->lockState(), resourceIdParallelBatchWriterMode),_fcvLock(opCtx->lockState(), resourceIdFeatureCompatibilityVersion),_interruptBehavior(behavior),_skipRSTLLock(skipRSTLLock),_isOutermostLock(!opCtx->lockState()->isLocked()) {_opCtx->lockState()->getFlowControlTicket(_opCtx, lockMode);
try {......_result = LOCK_INVALID;if (skipRSTLLock) {_takeGlobalLockOnly(lockMode, deadline);} else {_takeGlobalAndRSTLLocks(lockMode, deadline);}......} catch (const ExceptionForCat<ErrorCategory::Interruption>&) {......}......}
void Lock::GlobalLock::_takeGlobalLockOnly(LockMode lockMode, Date_t deadline) {_opCtx->lockState()->lockGlobal(_opCtx, lockMode, deadline);}
void Lock::GlobalLock::_takeGlobalAndRSTLLocks(LockMode lockMode, Date_t deadline) {_opCtx->lockState()->lock(_opCtx, resourceIdReplicationStateTransitionLock, MODE_IX, deadline);ScopeGuard unlockRSTL([this] { _opCtx->lockState()->unlock(resourceIdReplicationStateTransitionLock); });
_opCtx->lockState()->lockGlobal(_opCtx, lockMode, deadline);
unlockRSTL.dismiss();}
可以看到最终还是通过 OperationContext->lockState()->lockGlobal() 接口来获取全局锁。
4.2 锁结构
上文可知,无论是 CollectionLock、DBLock、GlobalLock 还是 ResourceLock,其最终都是通过Locker类的对象来实现锁的获取与释放。Locker 类定义了锁的获取、释放等行为,以一个虚类的形式存在作为 MongoDB 中 lock 概念的 Interface,其定义在 locker.h 文件中,类的接口比较多,我们挑重点来看:
// locker.h
// Interface for acquiring locks. One of those objects will have to be instantiated for each request (transaction).class Locker {Locker(const Locker&) = delete;Locker& operator=(const Locker&) = delete;
friend class UninterruptibleLockGuard;
public:virtual ~Locker() {}/*** This is what the lock modes on the global lock mean:* IX - Regular write operation* IS - Regular read operation* S - Stops all *write* activity. Used for administrative operations (repl, etc).* X - Stops all activity. Used for administrative operations (repl state changes,* shutdown, etc).*/virtual void lockGlobal(OperationContext* opCtx,LockMode mode,Date_t deadline = Date_t::max()) = 0;virtual bool unlockGlobal() = 0;/*** Requests the RSTL to be acquired in the requested mode (typically mode X) . This should only* be called inside ReplicationStateTransitionLockGuard.*/virtual LockResult lockRSTLBegin(OperationContext* opCtx, LockMode mode) = 0;virtual void lockRSTLComplete(OperationContext* opCtx, LockMode mode, Date_t deadline) = 0;/*** Acquires lock on the specified resource in the specified mode and returns the outcome* of the operation. See the details for LockResult for more information on what the* different results mean.*/virtual void lock(OperationContext* opCtx,ResourceId resId,LockMode mode,Date_t deadline = Date_t::max()) = 0;virtual void lock(ResourceId resId, LockMode mode, Date_t deadline = Date_t::max()) = 0;virtual bool unlock(ResourceId resId) = 0;void skipAcquireTicket();void setAcquireTicket();shouldAcquireTicket();protected:......private:......};
其中 lockGlobal() 与 unlockGlobal() 是对 Global 基本资源的获取/释放锁,lockRSTLBegin() 与 lockRSTLComplete() 为对 RSTL 锁的获取/释放,lock() 与 unlock() 接口则是对其他指定 ResourceId 对应资源锁的获取/释放。
Locker 仅定义了一组 interface,而一般我们在 MongoDB 中使用的锁,都是通过 LockerImpl 实现的,其定义在 lock_state.h 中:
// lock_state.h
/*** Interface for acquiring locks. One of those objects will have to be instantiated for each request (transaction).*/class LockerImpl : public Locker {public:......private:/*** Allows for lock requests to be requested in a non-blocking way. There can be only one* outstanding pending lock request per locker object.** _lockBegin posts a request to the lock manager for the specified lock to be acquired,* which either immediately grants the lock, or puts the requestor on the conflict queue* and returns immediately with the result of the acquisition. The result can be one of:** LOCK_OK - Nothing more needs to be done. The lock is granted.* LOCK_WAITING - The request has been queued up and will be granted as soon as the lock* is free. If this result is returned, typically _lockComplete needs to be called in* order to wait for the actual grant to occur. If the caller no longer needs to wait* for the grant to happen, unlock needs to be called with the same resource passed* to _lockBegin.*/LockResult _lockBegin(OperationContext* opCtx, ResourceId resId, LockMode mode);void _lockComplete(OperationContext* opCtx, ResourceId resId, LockMode mode, Date_t deadline);/*** Acquires a ticket for the Locker under 'mode'.* Returns true if a ticket is successfully acquired.* false if it cannot acquire a ticket within 'deadline'.* It may throw an exception when it is interrupted.*/bool _acquireTicket(OperationContext* opCtx, LockMode mode, Date_t deadline);......};
LockerImpl 实现了 Locker 的接口,同时新增了许多 private 的接口,上文中重点挑出了三个接口,分别是:
-
_lockBegin:通过 lockManager 来获取锁或者在队列中等待锁;
-
_lockComplete:等待锁的获取;
-
_acquireTicket:获取 ticket。
为什么把他们三个单独拎出来,看看 LockerImpl 对于两个重要接口 lockGlobal() 与 lock() 的实现便知:
// lock_state.cpp
void LockerImpl::lockGlobal(OperationContext* opCtx, LockMode mode, Date_t deadline) {dassert(isLocked() == (_modeForTicket != MODE_NONE));if (_modeForTicket == MODE_NONE) {if (_uninterruptibleLocksRequested) {// Ignore deadline and _maxLockTimeout.invariant(_acquireTicket(opCtx, mode, Date_t::max()));} else {auto beforeAcquire = Date_t::now();deadline = std::min(deadline,_maxLockTimeout ? beforeAcquire + *_maxLockTimeout : Date_t::max());uassert(ErrorCodes::LockTimeout,str::stream() << "Unable to acquire ticket with mode '" << mode<< "' within a max lock request timeout of '"<< Date_t::now() - beforeAcquire << "' milliseconds.",_acquireTicket(opCtx, mode, deadline));}_modeForTicket = mode;}
const LockResult result = _lockBegin(opCtx, resourceIdGlobal, mode);// Fast, uncontended pathif (result == LOCK_OK)return;
invariant(result == LOCK_WAITING);_lockComplete(opCtx, resourceIdGlobal, mode, deadline);}
void LockerImpl::lock(OperationContext* opCtx, ResourceId resId, LockMode mode, Date_t deadline) {// `lockGlobal` must be called to lock `resourceIdGlobal`.invariant(resId != resourceIdGlobal);
const LockResult result = _lockBegin(opCtx, resId, mode);
// Fast, uncontended pathif (result == LOCK_OK)return;
invariant(result == LOCK_WAITING);_lockComplete(opCtx, resId, mode, deadline);}
由以上实现可知:
无论是 lockGlobal() 还是 lock() 最终都是通过调用 _lockBegin() 与 _lockComplete() 通过 lockManager 来获取对应级别的资源锁;
Global 锁在获取前还需要调用 _acquireTicket() 来获取 Ticket。
于是我们分别讨论 ticket 与 lockManager。
4.3 有关 ticket
MongoDB 中有两种类型的 Ticket,一种是开启流控(FlowControl)时,在获取 Global 锁之前,需要调用 getFlowContrlTicket() 来获取流控的 ticket,本质是通过漏桶、令牌桶等方式执行限流操作。另一种则是在获取 Global 锁时,需要先通过 _acquireTicket() 接口获取对应的 ticket,MongoDB 通过 ticket 来控制请求的并发度,理论上大多数请求(除非设置了 skipAcquireTicket)都需要获取 Global 锁(IX、IS、X),故所有请求都需要获取 Ticket,_acquireTicket() 的实现如下:
// lock_state.cpp
bool LockerImpl::_acquireTicket(OperationContext* opCtx, LockMode mode, Date_t deadline) {const bool reader = isSharedLockMode(mode);auto holder = shouldAcquireTicket() ? _ticketHolders->getTicketHolder(mode) : nullptr;if (holder) {_clientState.store(reader ? kQueuedReader : kQueuedWriter);
// If the ticket wait is interrupted, restore the state of the client.ScopeGuard restoreStateOnErrorGuard([&] { _clientState.store(kInactive); });
// Acquiring a ticket is a potentially blocking operation.if (opCtx)invariant(!opCtx->recoveryUnit()->isTimestamped());
auto waitMode = _uninterruptibleLocksRequested ? TicketHolder::WaitMode::kUninterruptible: TicketHolder::WaitMode::kInterruptible;if (deadline == Date_t::max()) {_ticket = holder->waitForTicket(opCtx, &_admCtx, waitMode);} else if (auto ticket = holder->waitForTicketUntil(opCtx, &_admCtx, deadline, waitMode)) {_ticket = std::move(*ticket);} else {return false;}restoreStateOnErrorGuard.dismiss();}_clientState.store(reader ? kActiveReader : kActiveWriter);return true;}
通过 _ticketHolders 来获取一个 ticketHolder 对象,再通过 ticketHolder->waitForTicket() 或 ticketHolder->waitForTicketUntil() 来获取 ticket。MongoDB 通过 TicketHolders 来管理 TicketHolder,分别通过 _openWriteTransaction 与 _openReadTransaction 来管理写与读的 ticket。
// ticketHolders.h
class TicketHolders {public:......
static TicketHolders& get(ServiceContext* svcCtx);static TicketHolders& get(ServiceContext& svcCtx);/*** Sets the TicketHolder implementation to use to obtain tickets from 'reading' (for MODE_S and* MODE_IS), and from 'writing' (for MODE_IX) in order to throttle database access. There is no* throttling for MODE_X, as there can only ever be a single locker using this mode. The* throttling is intended to defend against large drops in throughput under high load due to too* much concurrency.*/void setGlobalThrottling(std::unique_ptr<TicketHolder> reading,std::unique_ptr<TicketHolder> writing);
TicketHolder* getTicketHolder(LockMode mode);
private:std::unique_ptr<TicketHolder> _openWriteTransaction;std::unique_ptr<TicketHolder> _openReadTransaction;};
// ticketHolders.cpp
TicketHolder* TicketHolders::getTicketHolder(LockMode mode) {switch (mode) {case MODE_S:case MODE_IS:return _openReadTransaction.get();case MODE_IX:return _openWriteTransaction.get();default:return nullptr;}}
在 MongoDB 启动时会调用 initializeStorageEngine(),而在其中则会初始化 TicketHolder 的类型以及数量:
// storage_engine_init.cpp
StorageEngine::LastShutdownState initializeStorageEngine(OperationContext* opCtx,const StorageEngineInitFlags initFlags) {......
// This should be set once during startup.if (storageGlobalParams.engine != "ephemeralForTest" &&(initFlags & StorageEngineInitFlags::kForRestart) == StorageEngineInitFlags{}) {auto readTransactions = gConcurrentReadTransactions.load();static constexpr auto DEFAULT_TICKETS_VALUE = 128;readTransactions = readTransactions == 0 ? DEFAULT_TICKETS_VALUE : readTransactions;auto writeTransactions = gConcurrentWriteTransactions.load();writeTransactions = writeTransactions == 0 ? DEFAULT_TICKETS_VALUE : writeTransactions;
auto svcCtx = opCtx->getServiceContext();auto& ticketHolders = TicketHolders::get(svcCtx);if (feature_flags::gFeatureFlagExecutionControl.isEnabledAndIgnoreFCV()) {LOGV2_DEBUG(5190400, 1, "Enabling new ticketing policies");switch (gTicketQueueingPolicy) {case QueueingPolicyEnum::Semaphore:LOGV2_DEBUG(6382201, 1, "Using Semaphore-based ticketing scheduler");ticketHolders.setGlobalThrottling(std::make_unique<SemaphoreTicketHolder>(readTransactions, svcCtx),std::make_unique<SemaphoreTicketHolder>(writeTransactions, svcCtx));break;case QueueingPolicyEnum::FifoQueue:LOGV2_DEBUG(6382200, 1, "Using FIFO queue-based ticketing scheduler");ticketHolders.setGlobalThrottling(std::make_unique<FifoTicketHolder>(readTransactions, svcCtx),std::make_unique<FifoTicketHolder>(writeTransactions, svcCtx));break;}} else {ticketHolders.setGlobalThrottling(std::make_unique<SemaphoreTicketHolder>(readTransactions, svcCtx),std::make_unique<SemaphoreTicketHolder>(writeTransactions, svcCtx));}}
......}
从代码中可知,默认的读与写的 ticket 数目均为128个,且 TicketHolder 分为两种类型:
-
SemaphoreTicketHolder:通过信号量控制同时持有 ticket 数目的TicketHolder,当请求数大于128时,未拿到 ticket 的线程将由于信号量控制而阻塞,当有多余资源被释放时则通过信号量中断调用获取资源;
-
FifoTicketHolder:通过 FIFO 队列来控制同时持有ticket数目的TicketHolder,当请求数大于128时,未拿到 ticket 的线程将进入一个先进先出的等待队列等待 ticket 释放。
两个 TicketHolder 的 waitForTicket() 接口本质最终都是调用 waitForTicketUntil() 接口,具体可以看 SemaphoreTicketHolder::waitForTicketUntil() 与 FifoTicketHolder::waitForTicketUntil() 的实现,均在 ticketHolder.cpp 文件中。
我们得到的结论是:MongoDB 在获取 Global 锁之前,要先获取 Ticket, Ticket 是 MongoDB 用于控制并发度的工具,在初始化 StorageEngine 时会初始化 TicketHolder,并初始化读写 Ticket 各128个(默认值,可改),同时 TicketHolder 有两种类型,分别是使用信号量中断通知等待线程的 SemaphoreTicketHolder,以及通过 FIFO 队列使等待线程获取 Ticket 的 FifoTicketHolder,两种 Holder 的主要区别在于如何通知等待获取资源的线程。
通过排队/立即获取完 Ticket 后,便可通过 _lockBegin 与 _lockComplete 获取锁。
4.4 锁排队&防饿死机制
下面我们来一起讨论 _lockBegin() 与 _lockComplete() 两个接口,首先看 _lockBegin():
// lock_state.cpp
MONGO_TSAN_IGNORELockResult LockerImpl::_lockBegin(OperationContext* opCtx, ResourceId resId, LockMode mode) {dassert(!getWaitingResource().isValid());......
// Making this call here will record lock re-acquisitions and conversions as well.globalStats.recordAcquisition(_id, resId, mode);_stats.recordAcquisition(resId, mode);
// Give priority to the full modes for Global, PBWM, and RSTL resources so we don't stall global// operations such as shutdown or stepdown.const ResourceType resType = resId.getType();if (resType == RESOURCE_GLOBAL) {if (mode == MODE_S || mode == MODE_X) {request->enqueueAtFront = true;request->compatibleFirst = true;}} else if (resType != RESOURCE_MUTEX) {// This is all sanity checks that the global locks are always be acquired// before any other lock has been acquired and they must be in sync with the nesting.if (kDebugBuild) {const LockRequestsMap::Iterator itGlobal = _requests.find(resourceIdGlobal);invariant(itGlobal->recursiveCount > 0);invariant(itGlobal->mode != MODE_NONE);};}
// The notification object must be cleared before we invoke the lock manager, because// otherwise we might reset state if the lock becomes granted very fast._notify.clear();
LockResult result = isNew ? getGlobalLockManager()->lock(resId, request, mode): getGlobalLockManager()->convert(resId, request, mode);
......
return result;}
在 _lockBegin() 中,会通过 globalStats 与 _stats 来记录 ResId 对应的资源请求以及锁的 mode;同时,还会根据 resType 以及 mode 的类型来设置排队的优先级,以实现防饿死机制。在获取完 ticket 后,在获取锁的时候依然会进行排队,这里通过为 S 与 X 的 Global 锁设置了更高的排队优先级,通过 request->enqueueAtFront=true 与 request->compatibleFirst=true 来保证 Global 级别的 S 与 X 锁在锁排队时有更高的优先级,以确保如 shutdown 或 stepdown 这类的请求不会被阻塞很久。我们这里先有个印象,即 MongoDB 在获取锁时依旧有一个排队队列的情况,后续再详细讲解如何排队,以及如何防饿死。
最后,通过 getGlobalLockManager()->lock() 与 getGlobalManager()->convert() 接口来对锁进行获取,并返回获取的结果:
// lock_manager_defs.h
/*** Return values for the locking functions of the lock manager.*/enum LockResult {
// 成功获取到锁LOCK_OK,
// 存在锁冲突,等待获取锁LOCK_WAITING,
// 获取锁超时LOCK_TIMEOUT,
// 初始化值,不应被使用LOCK_INVALID};
可知,结果为 LOCK_OK 则代表成功获取了对应资源的锁,而结果 LOCK_WAITING 则代表了当前需要获取的锁已被其他操作占有,进入锁冲突等待队列;LOCK_TIMEOUT 则意味着在等待队列中等待的时间已经超时。
这里继续看 _lockComplete() 的实现:
// lock_state.cpp
void LockerImpl::_lockComplete(OperationContext* opCtx,ResourceId resId,LockMode mode,Date_t deadline) {......
while (true) {if (opCtx && _uninterruptibleLocksRequested == 0) {result = _notify.wait(opCtx, waitTime);} else {result = _notify.wait(waitTime);}
// Account for the time spent waiting on the notification objectconst uint64_t curTimeMicros = curTimeMicros64();const uint64_t elapsedTimeMicros = curTimeMicros - startOfCurrentWaitTime;startOfCurrentWaitTime = curTimeMicros;
globalStats.recordWaitTime(_id, resId, mode, elapsedTimeMicros);_stats.recordWaitTime(resId, mode, elapsedTimeMicros);
if (result == LOCK_OK)break;
// If infinite timeout was requested, just keep waitingif (timeout == Milliseconds::max()) {continue;}
......}
invariant(result == LOCK_OK);unlockOnErrorGuard.dismiss();_setWaitingResource(ResourceId());}
如上述代码,只有在调用 _lockBegin() 返回的结果不是 LOCK_OK 时才会继续调用 _lockComplete() 进行等待,在 _lockComplete() 中、将会执行等待,如果等待的锁被释放且成功拿到,则会通过 _notifyWait() 进行通知,同时 _lockComplete() 中还会统计等锁的时间等信息。
上述文章描述了是如何等待与获取锁的,最终都是通过 LockManager->lock() 来执行的锁获取与排队等待,下面我们分析 LockManager 的结构以及是如何防止锁饿死的。
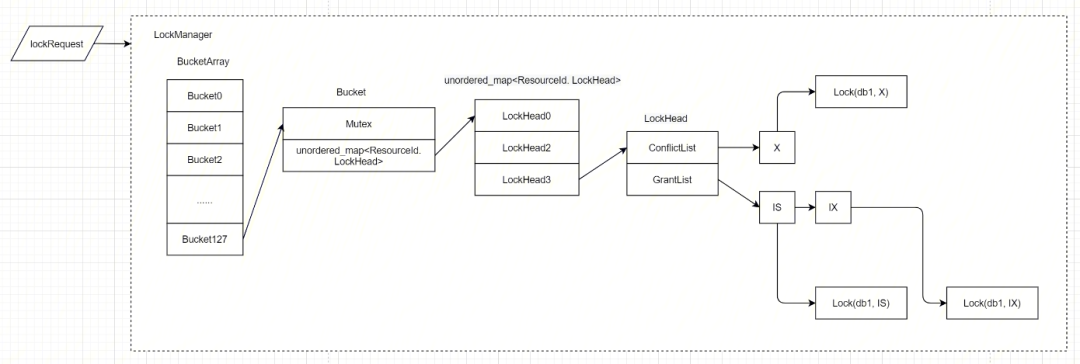
LockManager 的结构如下:
// lock_manager.h
/*** Entry point for the lock manager scheduling functionality. Don't use it directly, but* instead go through the Locker interface.*/class LockManager {......
public:......
/*** Acquires lock on the specified resource in the specified mode and returns the outcome* of the operation. See the details for LockResult for more information on what the* different results mean.*/LockResult lock(ResourceId resId, LockRequest* request, LockMode mode);LockResult convert(ResourceId resId, LockRequest* request, LockMode newMode);bool unlock(LockRequest* request);......
private:// The lockheads need access to the partitionsfriend struct LockHead;
// These types describe the locks hash tablestruct LockBucket {SimpleMutex mutex;typedef stdx::unordered_map<ResourceId, LockHead*> Map;Map data;LockHead* findOrInsert(ResourceId resId);};
struct Partition {PartitionedLockHead* find(ResourceId resId);PartitionedLockHead* findOrInsert(ResourceId resId);typedef stdx::unordered_map<ResourceId, PartitionedLockHead*> Map;SimpleMutex mutex;Map data;};
LockBucket* _getBucket(ResourceId resId) const;Partition* _getPartition(LockRequest* request) const;......static const unsigned _numLockBuckets;LockBucket* _lockBuckets;
static const unsigned _numPartitions;Partition* _partitions;};
在LockManager中,比较重要的接口即lock()、convert()、unlock(),以及其中一些比较重要的结构对象:
-
LockHead:结构体用于真正的获取锁,其中包括了 grantedList 与等待的 connflictList;
-
LockBucket:结构体用于定义 ResourceId-->LockHead 的哈希表;
-
_lockBuckets:为一个由 _numLockBuckets 定义长度的 LockBucket 数组;
-
_numLockBuckets:定义了 LockBucket 的长度,代码中定死了为128。
上述共同组成了 LockManager 的结构,可以用如下图来表述
下面分别讨论:首先 LockManager 中存在一个长度为128的 BucketArray,其可以无锁访问,在每一个 lock() 操作中都首先通过 resId % 128来找到对应的 bucket,这里利用了 ResourceId 彼此之间的无关性执行了分桶操作,提高了并发。
// lock_manager.cpp
LockResult LockManager::lock(ResourceId resId, LockRequest* request, LockMode mode) {......// Use regular LockHead, maybe start partitioningLockBucket* bucket = _getBucket(resId);......LockHead* lock = bucket->findOrInsert(resId);
// Start a partitioned lock if possibleif (request->partitioned && !(lock->grantedModes & (~intentModes)) && !lock->conflictModes) {Partition* partition = _getPartition(request);stdx::lock_guard<SimpleMutex> scopedLock(partition->mutex);PartitionedLockHead* partitionedLock = partition->findOrInsert(resId);invariant(partitionedLock);lock->partitions.push_back(partition);partitionedLock->newRequest(request);return LOCK_OK;}
......}
// Have more buckets than CPUs to reduce contention on lock and cachesconst unsigned LockManager::_numLockBuckets(128);
LockManager::LockBucket* LockManager::_getBucket(ResourceId resId) const {return &_lockBuckets[resId % _numLockBuckets];}
每个 bucket 中存储了一张 <ResourceId,LockHead> 的哈希 map,方便快速定位,且该哈希表受该 bucket 中的 mutex 锁保护。当获取 ResourceId 对应的 LockHead 时,先通过 stdx::lock_guard<SimpleMutex> 获取锁,再通过 LockHead* lock = bucket->findOrInsert(resId) 获取对应的 LockHead。
// lock_manager.h
struct LockBucket {SimpleMutex mutex;typedef stdx::unordered_map<ResourceId, LockHead*> Map;Map data;LockHead* findOrInsert(ResourceId resId);};
LockHead 则是 MongoDB 中锁的具象化对象,其简要结构如下:
// lock_manager.cpp
/*** There is one of these objects for each resource that has a lock request. Empty objects (i.e.* LockHead with no requests) are allowed to exist on the lock manager's hash table.*/struct LockHead {....../*** Finish creation of request and put it on the LockHead's conflict or granted queues. Returns* LOCK_WAITING for conflict case and LOCK_OK otherwise.*/LockResult newRequest(LockRequest* request) {invariant(!request->partitionedLock);request->lock = this;
// New lock request. Queue after all granted modes and after any already requested conflicting modesif (conflicts(request->mode, grantedModes) ||(!compatibleFirstCount && conflicts(request->mode, conflictModes))) {request->status = LockRequest::STATUS_WAITING;
// Put it on the conflict queue. Conflicts are granted front to back.if (request->enqueueAtFront) {conflictList.push_front(request);} else {conflictList.push_back(request);}
incConflictModeCount(request->mode);
return LOCK_WAITING;}
// No conflict, new requestrequest->status = LockRequest::STATUS_GRANTED;
grantedList.push_back(request);incGrantedModeCount(request->mode);
if (request->compatibleFirst) {compatibleFirstCount++;}
return LOCK_OK;}
// Id of the resource which is protected by this lock. Initialized at construction time and does not change.ResourceId resourceId;
// Granted queueLockRequestList grantedList;uint32_t grantedCounts[LockModesCount];uint32_t grantedModes;
// Conflict queueLockRequestList conflictList;uint32_t conflictCounts[LockModesCount];uint32_t conflictModes;
......};
LockHead 是对应于某个 ResourceId的锁对象,维护着所有对该 ResourceId 的锁请求。LockHead 中有两个重要的组成部分:ConflictList 与 GrantList 为两个双向链表,分别代表着锁的等待队列与当前锁的持有队列,其中 ConflictList 为一个 FIFO 的队列,同时还有 ConflictCounts 与 GrantCounts 来维护等待队列与持有队列的长度,GrantedModes 与 ConflictModes 则作为 bit-mask 来标识当前队列中存在锁的 mode 类型。为什么要这么做?试想当有一个新的请求到达时,需要遍历所有 GrantList 中的元素来检测请求中的 mode 与队列中是否冲突,这样做时间复杂度为 O(n),并不高效。
// 伪代码
def lock(newNode):foreach node in GrandList:if conflict(node.mode, newNode.mode):return ConflictList.add(newNode);return GrantList.add(newNode);
为了解决这个问题,MongoDB 为 ConflictList 与 GrantList 增加了引用计数的数组,在将一个对象添加到 GrantList 中时,同时需要对 GrantCounts[mode] 进行累加,如果 GrantCounts[mode] 是从0到1的变化,则需要将 GrantModes 对应 mode 的 bitMask 设置为1。从 GrantList 中删除对象时则是一个逆向的对称操作。这样,GrantCounts[mode] 表示了每一个 mode 对应的在 GrantList 中的数量,而 GrantModes 则表示当前 GrantList 中是否存在对应 mode 的锁持有。由此,在判断某个 mode 是否与当前 GrantList 中已有对象冲突时,只需将待加节点的 mode 与 GrantModes 中对应的 bitMask 进行比较,时间复杂度从 O(n) 降低到 0(1)。
// lock_manager.cpp
uint_32 conflictCounts[LockModesCount];uint_32 conflictModes;
// Methods to maintain the conflict queuevoid incConflictModeCount(LockMode mode) {invariant(conflictCounts[mode] >= 0);if (++conflictCounts[mode] == 1) {invariant((conflictModes & modeMask(mode)) == 0);conflictModes |= modeMask(mode); // 算出mode的bit-map,再进行按位或赋值}}
void decConflictModeCount(LockMode mode) {invariant(conflictCounts[mode] >= 1);if (--conflictCounts[mode] == 0) {invariant((conflictModes & modeMask(mode)) == modeMask(mode));conflictModes &= ~modeMask(mode); // 算出mode的bit-map,再进行取反按位与取消赋值}}enum LockMode {MODE_NONE = 0,MODE_IS = 1,MODE_IX = 2,MODE_S = 3,MODE_X = 4,
LockModesCount};uint32_t modeMask(LockMode mode) {return 1 << mode; // 对1左移mode代表的位构建bit-mask}// Helper functions for the lock modesbool conflicts(LockMode newMode, uint32_t existingModesMask) {return (LockConflictsTable[newMode] & existingModesMask) != 0;}// Map of conflicts.static const int LockConflictsTable[] = {0, // MODE_NONE(1 << MODE_X), // MODE_IS(1 << MODE_S) | (1 << MODE_X), // MODE_IX(1 << MODE_IX) | (1 << MODE_X), // MODE_S(1 << MODE_S) | (1 << MODE_X) | (1 << MODE_IS) | (1 << MODE_IX), // MODE_X};
上述代码解决了意向锁中获取与排队等待的问题,并提高了获取锁的效率。对于一个锁请求,如果与当前 GrantList 中的请求类型无冲突,就将其添加到 GrantList 中加锁成功,否则将其添加到 ConflictList 中,并等待 grantedModes 变更时,从 ConflictList 中选择一批与 grantedModes 兼容的加锁请求进入 GrantList。但是上述策略会有一个问题:
-
试想以下场景:如果 ConflictList 中有 X 锁在等待,而 GrantList 中的 IS/IX 锁请求源源不断的进来,那么 X 锁就会一直无法被调度,即锁会被饿死。
为了避免这种排它锁被共享锁饿死的情况,在 ConflictList 的 FIFO 队列基础上,引入了排队优先级概念。MongoDB 通过添加 enqueueAtFront 与 compatibleFirst 这两个参数来解决排它锁饿死的问题。其位于在获取 lock 时传入的 LockRequest 中:
// lock_manager_defs.h
/*** There is one of those entries per each request for a lock. They hang on a linked list off* the LockHead or off a PartitionedLockHead and also are in a map for each Locker. This* structure is not thread-safe.*/struct LockRequest {enum Status {STATUS_NEW,STATUS_GRANTED,STATUS_WAITING,STATUS_CONVERTING,
// Counts the rest. Always insert new status types above this entry.StatusCount};
......
// If the request cannot be granted right away, whether to put it at the front or at the end of// the queue. By default, requests are put at the back. If a request is requested to be put at// the front, this effectively bypasses fairness. Default is FALSE.bool enqueueAtFront;
// When this request is granted and as long as it is on the granted queue, the particular// resource's policy will be changed to "compatibleFirst". This means that even if there are// pending requests on the conflict queue, if a compatible request comes in it will be granted// immediately. This effectively turns off fairness.bool compatibleFirst;
......};
如,在_lockBegin()中,就会将 Global 级别的 X 锁设置高优先级:
// lock_state.cpp
MONGO_TSAN_IGNORELockResult LockerImpl::_lockBegin(OperationContext* opCtx, ResourceId resId, LockMode mode) {......// Give priority to the full modes for Global, PBWM, and RSTL resources so we don't stall global// operations such as shutdown or stepdown.const ResourceType resType = resId.getType();if (resType == RESOURCE_GLOBAL) {if (mode == MODE_S || mode == MODE_X) {request->enqueueAtFront = true;request->compatibleFirst = true;}} else if (resType != RESOURCE_MUTEX) {// This is all sanity checks that the global locks are always be acquired// before any other lock has been acquired and they must be in sync with the nesting.if (kDebugBuild) {const LockRequestsMap::Iterator itGlobal = _requests.find(resourceIdGlobal);invariant(itGlobal->recursiveCount > 0);invariant(itGlobal->mode != MODE_NONE);};}......}
其中 enqueueAtFront 参数决定了当当前请求的 mode 冲突时,是将请求插入 ConflictList 的最前面还是最后面,即设置了 enqueueAtFront 参数的请求将会在等待队列的最前面插队:
// lock_manager.cpp
LockResult newRequest(LockRequest* request) {......
// New lock request. Queue after all granted modes and after any already requested conflicting modesif (conflicts(request->mode, grantedModes) ||(!compatibleFirstCount && conflicts(request->mode, conflictModes))) {request->status = LockRequest::STATUS_WAITING;
// Put it on the conflict queue. Conflicts are granted front to back.if (request->enqueueAtFront) {conflictList.push_front(request);} else {conflictList.push_back(request);}
incConflictModeCount(request->mode);
return LOCK_WAITING;}// No conflict, new requestrequest->status = LockRequest::STATUS_GRANTED;
grantedList.push_back(request);incGrantedModeCount(request->mode);
if (request->compatibleFirst) {compatibleFirstCount++;}......}
而 compatibleFrist 参数则是配合 enqueueAtFront 一起配合防止排它锁饿死,上述代码所示:
-
如果锁请求与当前 GrantedModes 冲突,则进入ConflictList等待,且根据 enqueueAtFront 来判断是插入等待队列的队头/队尾;
-
如果锁请求与当前 GrantedModes 不冲突,也未必能加锁成功,还需要检测当前 GrantList 持有锁的资源中的 complatiblecFristCount,即:GrantList 中 compatibleFist=true 的锁请求的个数,如果 GrantList 中无 complatibleFirst 的锁请求,且请求的锁 mode 与当前 ConflictList 中的请求mode冲突,则依旧要将新的请求加入 ConflictList 等待队列进行等待,这里保证了当有排它锁在 ConflictList 中等待时,新的共享锁不会不断的进入 GrantList 获取锁而导致排它锁饿死。
-
如果获取锁成功,则将锁请求加入 GrantList 中,并将 compatibleFristCount++;
-
现在我们来分析有 Global 的 X 锁进入排队的情况:
-
当有 Global 的 X 锁请求时,MongoDB 会为当前请求设置 enqueueAtFirst=true 以及 compatibleFirst=true;
-
此时 GrantList 中的锁请求 mode 均为 IX/IS 类型;
-
请求到达时,由于 mode 与 GrantList 冲突,Global 的 X 锁请求被加入 ConflictList 队列等待,且由于 enqueueAtFirst=true,请求被直接加到 ConflictList 的队头;
-
再有新的 IX/IS 请求到达时,由于此时 compatibleFristCount==0,且请求的 IX/IS 类型锁与 ConflictList 中的 Global 的 X 锁类型冲突,导致新的 IX/IS 锁请求也依旧进入 ConflictList 队尾进行等待。
-
由于新的请求不断的进入 ConflictList 进行等待,且 Global 的 X 锁请求位于 ConflictList 的 FIFO 队列第一位,防止了排它锁被源源不断的共享锁饿死。
本文主要从 MongoDB 的慢日志引入,为你详细拆解了 MongoDB 的锁与相关实现问题。在下一篇中,我们将对 MongoDB 的操作和锁使用进行深入的阐述,敬请期待。

你为什么选择 MongoDB,以及它有什么优缺点? 欢迎评论留言。我们将选取1则优质的评论,送出腾讯Q哥公仔 1个 (见下图)。2月29日中午12点开奖。

📢📢欢迎加入腾讯云开发者社群,享前沿资讯、大咖干货,找兴趣搭子,交同城好友,更有鹅厂招聘机会、限量周边好礼等你来~

(长按图片立即扫码)




