
Flink生产环境TOP难题与优化,阿里巴巴藏经阁YYDS
点击上方蓝色字体,选择“设为星标”
回复”面试“获取更多惊喜

我曾经在之前的文章中提到过关于Flink生产环境中遇到的各种问题。直到有一天,我在阿里巴巴藏经阁看到了阿里的工程师们在生产环境中的问题合集,如获至宝,在此整理了其中的TOP经典问题给大家参考。
小编第一次使用Flink已经是2019年了,这中间经历过Flink从1.6版本到最新的1.13版本的各种优化和坑,大家可以参考:《生产上的坑才是真的坑 | 盘一盘Flink那些经典线上问题》,其中也提到了一些经典的线上问题例如反压,资源和部署问题,作业问题等等。
现在跟我一起来看看,阿里的工程师们遇到的一些常见问题和解法吧。
如何规划生产中的集群大小?
第一步是仔细考虑应用程序的运维指标,以达到所需资源的基线。需要考虑的关键指标是:
每秒记录数和每条记录的大小
已有的不同键(key)的数量和每个键对应的状态大小
状态更新的次数和状态后端的访问模式
最后,一个更实际的问题是与客户之间围绕停机时间、延迟和最大吞吐量的服务级别协议(SLA),因为这些直接影响容量规划。接下来,根据预算,看看有什么可用的资源。例如:
网络容量,同时把使用网络的外部服务也纳入考虑,如 Kafka、HDFS 等。
磁盘带宽,如果您依赖于基于磁盘的状态后端,如 RocksDB(并考虑其他磁 盘使用,如 Kafka 或 HDFS)
可用的机器数量、CPU 和内存
Flink CheckPoint问题如何排查?
Flink 的 Checkpoint 包括如下几个部分:
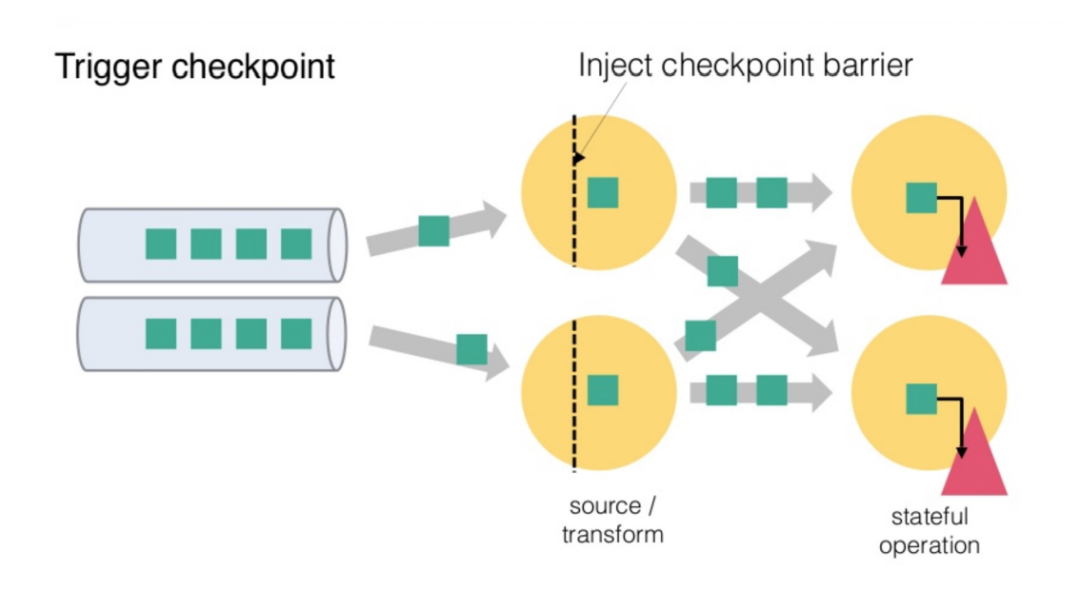
JM trigger checkpoint
Source 收到 trigger checkpoint 的 PRC,自己开始做 snapshot,并往下游发送 barrier
下游接收 barrier(需要 barrier 都到齐才会开始做 checkpoint)
Task 开始同步阶段 snapshot
Task 开始异步阶段 snapshot
Task snapshot 完成,汇报给 JM
上面的任何一个步骤不成功,整个 checkpoint 都会失败。
Checkpoint问题可以分为下面几个大类:
Checkpoint失败
假如我们在 Checkpoint 界面看到如下图所示,下图中 Checkpoint 10423 失败了。点击Checkpoint10423 的详情,我们可以看到类系下图所示的表格。
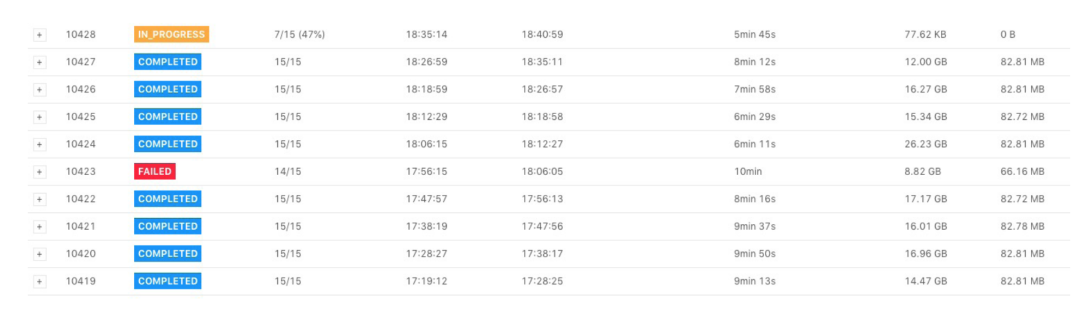
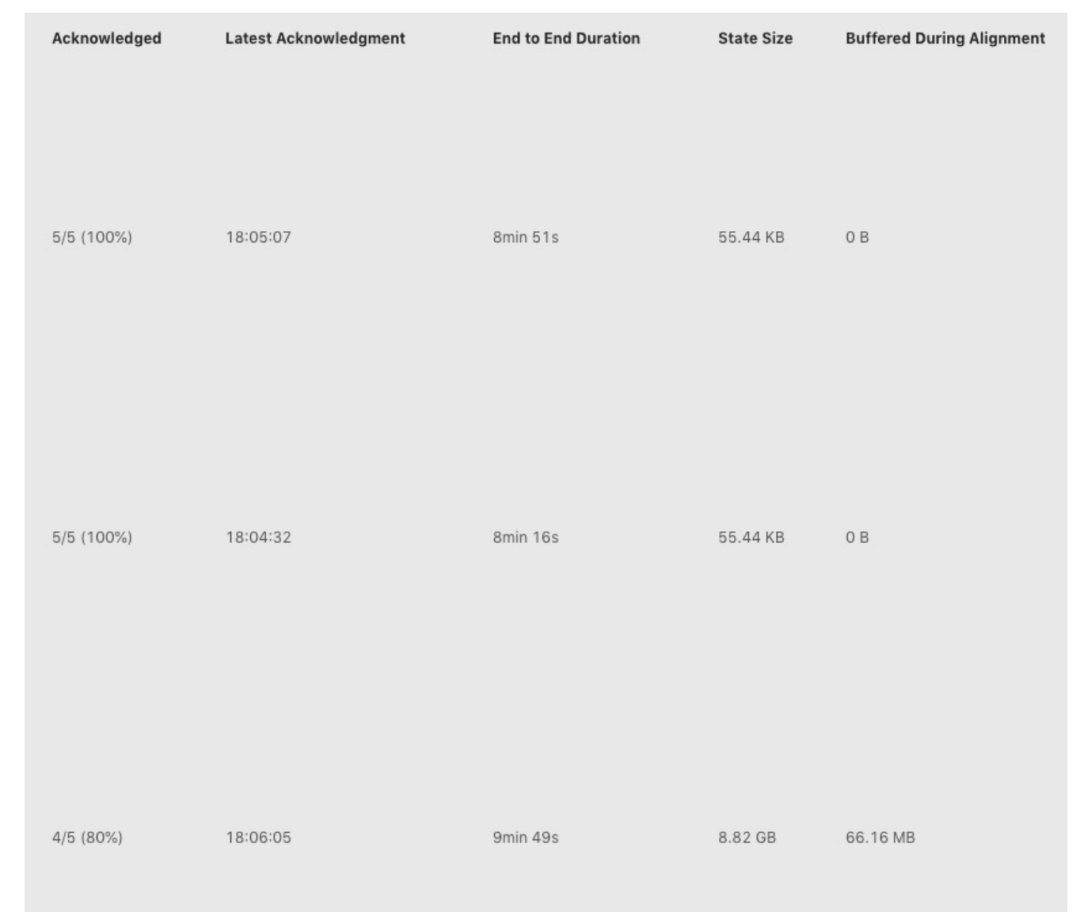
Checkpoint 失败大致分为两种情况:Checkpoint Decline和CheckpointExpire。
Checkpoint Decline发生时我们可以在日志汇总发现类似下面这样的日志:
Decline checkpoint 10423 by task 0b60f08bf8984085b59f8d9bc74ce2e1 of job 85d268e6fbc19411185f7e4868a44178. 其中 10423 是 checkpointID,0b60f08bf8984085b59f8d9bc74ce2e1 是 execution id,85d268e6fbc19411185f7e4868a44178 是 job id,我们可以在 jobmanager.log 中查找 execution id,找到被调度到哪个 taskmanager 上,类似如下所示:
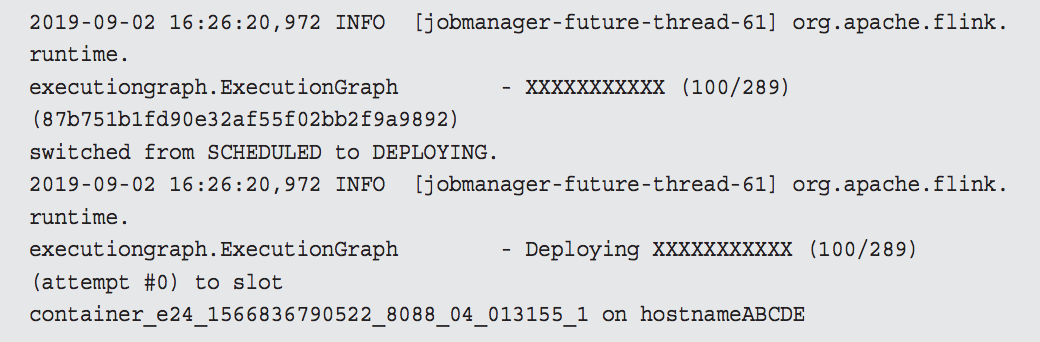
从上面的日志我们知道该 execution 被调度到 hostnameABCDE 的 container_e24_1566836790522_8088_04_013155_1 slot 上,接下来我们就可以到 container container_e24_1566836790522_8088_04_013155 的 taskmanager.log 中查找Checkpoint 失败的具体原因了。
Checkpoint Expire
如果 Checkpoint 做的非常慢,超过了 timeout 还没有完成,则整个 Checkpoint 也会失败。当一个 Checkpoint 由于超时而失败是,会在 jobmanager.log 中看到如下的日志:
Checkpoint 1 of job 85d268e6fbc19411185f7e4868a44178 expired before completing.
表示 Chekpoint 1 由于超时而失败,这个时候可以可以看这个日志后面是否有类似下面的日志:
Received late message for now expired checkpoint attempt 1 from 0b60f08bf8984085b59f8d9bc74ce2e1 of job 85d268e6fbc19411185f7e4868a44178.
我们就可以按照上面的方法找到对应的 taskmanager.log 查看具体信息。
Checkpoint 慢
Checkpoint 慢的情况如下:比如 Checkpoint interval 1 分钟,超时 10 分钟,Checkpoint 经常需要做 9 分钟(我们希望 1 分钟左右就能够做完),而且我们预期 state size 不是非常大。对于 Checkpoint 慢的情况,我们可以按照下面的顺序逐一检查。
Source Trigger Checkpoint 慢
使用增量 Checkpoint
作业存在反压或者数据倾斜
Barrier 对齐慢
主线程太忙,导致没机会做 snapshot
同步阶段做的慢
异步阶段做的慢
反压问题如何排查?
反压(backpressure)是实时计算应用开发中,特别是流式计算中,十分常见的问题。反压意味着数据管道中某个节点成为瓶颈,处理速率跟不上上游发送数据的速率,而需要对上游进行限速。由于实时计算应用通常使用消息队列来进行生产端和消费端的解耦,消费端数据源是 pull-based 的,所以反压通常是从某个节点传导至数据源并降低数据源(比如 Kafka consumer)的摄入速率。
要解决反压首先要做的是定位到造成反压的节点,这主要有两种办法 :
通过 Flink Web UI 自带的反压监控面板
通过 Flink Task Metrics
Flink Web UI 的反压监控提供了 SubTask 级别的反压监控,原理是通过周期性对 Task 线程的栈信息采样,得到线程被阻塞在请求 Buffer(意味着被下游队列阻塞)的频率来判断该节点是否处于反压状态。默认配置下,这个频率在 0.1 以下则为OK,0.1 至 0.5 为 LOW,而超过 0.5 则为 HIGH。
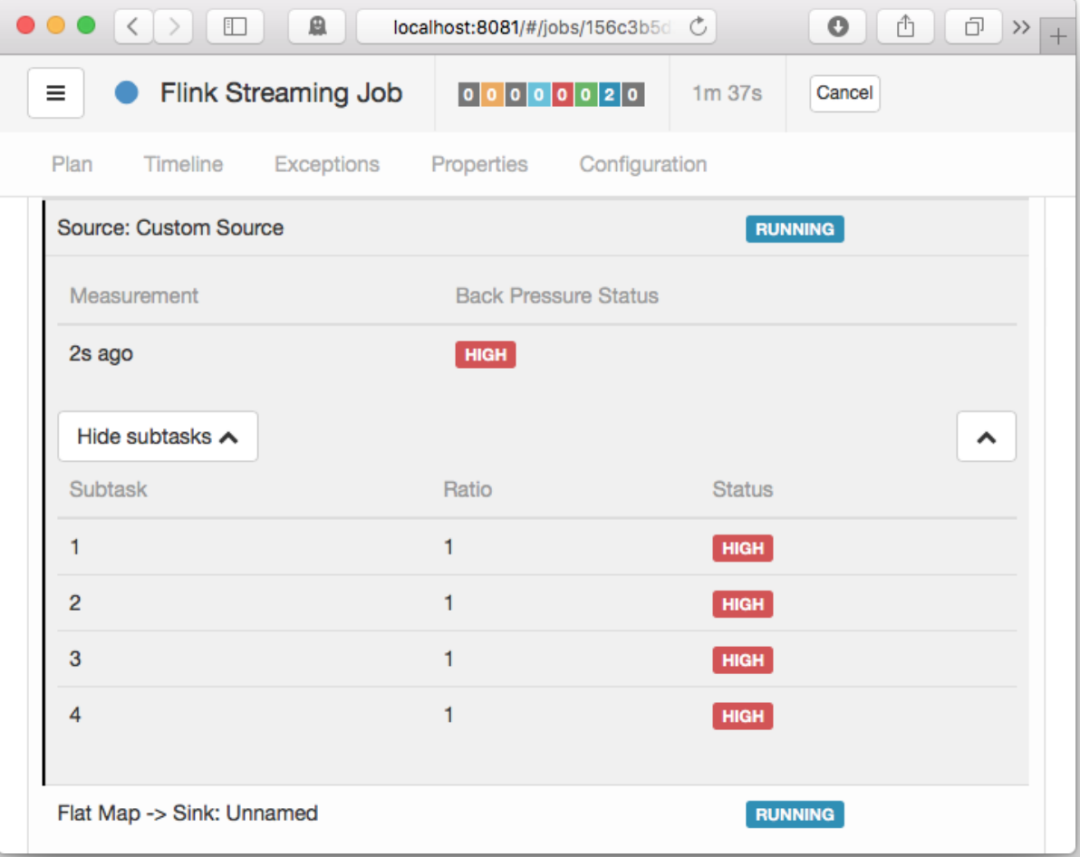
如果处于反压状态,那么有两种可能性:
该节点的发送速率跟不上它的产生数据速率。这一般会发生在一条输入多条 输出的 Operator(比如 flatmap)。
下游的节点接受速率较慢,通过反压机制限制了该节点的发送速率。
如果是第一种状况,那么该节点则为反压的根源节点,它是从 Source Task 到Sink Task 的第一个出现反压的节点。如果是第二种情况,则需要继续排查下游节点。
值得注意的是,反压的根源节点并不一定会在反压面板体现出高反压,因为反压面板监控的是发送端,如果某个节点是性能瓶颈并不会导致它本身出现高反压,而是导致它的上游出现高反压。总体来看,如果我们找到第一个出现反压的节点,那么反压根源要么是就这个节点,要么是它紧接着的下游节点。
此外,Flink 提供的 Task Metrics 是更好的反压监控手段,我们在监控反压时会用到的 Metrics 主要和 Channel 接受端的 Buffer 使用率有关,最为有用的是以下几个 Metrics:

分析反压的大致思路是:如果一个 Subtask 的发送端 Buffer 占用率很高,则表明它被下游反压限速了;如果一个 Subtask 的接受端 Buffer 占用很高,则表明它将反压传导至上游。反压情况可以根据以下表格进行对号入座:
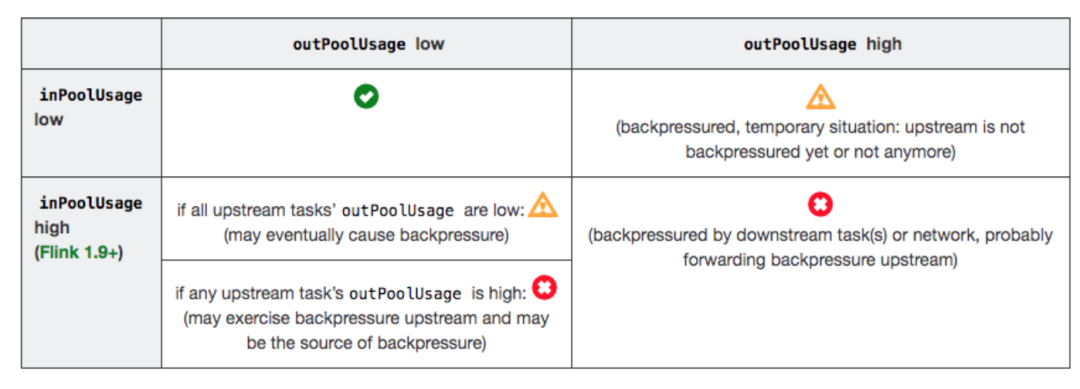
outPoolUsage 和 inPoolUsage 同为低或同为高分别表明当前 Subtask 正常或处于被下游反压,这应该没有太多疑问。而比较有趣的是当 outPoolUsage 和 inPoolUsage 表现不同时,这可能是出于反压传导的中间状态或者表明该 Subtask就是反压的根源。
如果一个 Subtask 的 outPoolUsage 是高,通常是被下游 Task 所影响,所以可以排查它本身是反压根源的可能性。如果一个 Subtask 的 outPoolUsage 是低,但其 inPoolUsage 是高,则表明它有可能是反压的根源。因为通常反压会传导至其上游,导致上游某些 Subtask 的 outPoolUsage 为高,我们可以根据这点来进一步判断。值得注意的是,反压有时是短暂的且影响不大,比如来自某个 Channel 的短暂网络延迟或者 TaskManager 的正常 GC,这种情况下我们可以不用处理。
在实践中,很多情况下的反压是由于数据倾斜造成的,这点我们可以通过 Web UI 各个 SubTask 的 Records Sent 和 Record Received 来确认,另外 Checkpoint detail 里不同 SubTask 的 State size 也是一个分析数据倾斜的有用指标。
此外,最常见的问题可能是用户代码的执行效率问题(频繁被阻塞或者性能问题)。最有用的办法就是对 TaskManager 进行 CPU profile,从中我们可以分析到Task Thread 是否跑满一个 CPU 核:如果是的话要分析 CPU 主要花费在哪些函数里面,比如我们生产环境中就偶尔遇到卡在 Regex 的用户函数(ReDoS);如果不是的话要看 Task Thread 阻塞在哪里,可能是用户函数本身有些同步的调用,可能是checkpoint 或者 GC 等系统活动导致的暂时系统暂停。
另外 TaskManager 的内存以及 GC 问题也可能会导致反压,包括 TaskManager JVM 各区内存不合理导致的频繁 Full GC 甚至失联。推荐可以通过给TaskManager 启用 G1 垃圾回收器来优化 GC,并加上 -XX:+PrintGCDetails 来打印 GC 日志的方式来观察 GC 的问题。
客户端常见问题
应用提交控制台异常信息:Could not build the program from JAR file.
这个问题的迷惑性较大,很多时候并非指定运行的 JAR 文件问题,而是提交过程中发生了异常,需要根据日志信息进一步排查。最常见原因是未将依赖的 Hadoop JAR 文件加到 CLASSPATH,找不到依赖类(例如:ClassNotFoundException:org.apache.hadoop.yarn.exceptions.YarnException)导致加载客户端入口类(FlinkYarnSessionCli)失败。
用户应用和框架 JAR 包版本冲突问题
该问题通常会抛出 NoSuchMethodError/ClassNotFoundException/IncompatibleClassChangeError 等异常,要解决此类问题:
首先需要根据异常类定位依赖库,然后可以在项目中执行 mvn dependency:tree 以树形结构展示全部依赖链,再从中定位冲突的依赖库,也可以增加参数 -Dincludes 指定要显示的包,格式为 [groupId]:[artifactId]:[-type]:[version],支持匹配,多个用逗号分隔,例如:mvn dependency:tree-Dincludes=power,javaassist。
定位冲突包后就要考虑如何排包,简单的方案是用 exclusion 来排除掉其从他依赖项目中传递过来的依赖,不过有的应用场景需要多版本共存,不同组件依赖不同版本,就要考虑用 Maven Shade 插件来解决,详情请参考Maven Shade Plugin。
Flink 应用资源分配问题排查思路
如果 Flink 应用不能正常启动达到 RUNNING 状态,可以按以下步骤进行排查:
步骤1. 需要先检查应用当前状态,根据上述对启动流程的说明,我们知道:
处于 NEW_SAVING 状态时正在进行应用信息持久化,如果持续处于这个状态我们需要检查 RM 状态存储服务(通常是 ZooKeeper 集群)是否正常;
如果处于 SUBMITTED 状态,可能是 RM 内部发生一些 hold 读写锁的耗时操作导致事件堆积,需要根据 YARN 集群日志进一步定位.
如果处于 ACCEPTED 状态,需要先检查 AM 是否正常,跳转到步骤 2;
如果已经是 RUNNING 状态,但是资源没有全部拿到导致 JOB 无法正常运行,跳转到步骤 3;
步骤2. 检查 AM 是否正常,可以从 YARN 应用展示界面(http:// /cluster/app/)或YARN 应用 REST API(http:///ws/v1/cluster/apps/)查看 diagnostics 信 息,根据关键字信息明确问题原因与解决方案:
Queue’s AM resource limit exceeded. 原因是达到了队列 AM 可用资源上限,即队列的 AM 已使用资源和 AM 新申请资源之和超出了队列的AM 资源上限,可以适当调整队列 AM 可用资源百分比的配置项:yarn.scheduler.capacity..maximum-am-resource-percent。
User’s AM resource limit exceeded. 原因是达到了应用所属用户在该队列的 AM 可用资源上限,即应用所属用户在该队列的 AM 已使用资源和 AM新申请资源之和超出了应用所属用户在该队列的 AM 资源上限,可以适当提高用户可用 AM 资源比例来解决该问题,相关配置项:yarn.scheduler.capacity..user-limit-factor 与 yarn.scheduler.capacity..minimum-user-limit-percent。
AM container is launched, waiting for AM container to Register with RM. 大致原因是 AM 已启动,但内部初始化未完成,可能有 ZK 连接超时等问题,具体原因需排查 AM 日志,根据具体问题来解决。
Application is Activated, waiting for resources to be assigned for AM.该信息表示应用 AM 检查已经通过,正在等待调度器分配,此时需要进行调度器层面的资源检查,跳转到步骤 4。
步骤3. 确认应用确实有 YARN 未能满足的资源请求:从应用列表页点击问题应用ID 进入应用页面,再点击下方列表的应用实例 ID 进入应用实例页面,看 Total Outstanding Resource Requests 列表中是否有 Pending 资源,如果没有,说明 YARN 已分配完毕,退出该检查流程,转去检查 AM;如果有,说明调度器未能完成分配,跳转到步骤 4。
步骤4.调度器分配问题排查YARN-9050 支持在 WebUI 上或通过 REST API 自动诊断应用问题,将在 Hadoop3.3.0 发布,之前的版本仍需进行人工排查:
检查集群或 queue 资源,scheduler 页面树状图叶子队列展开查看资源信息:Effective Max Resource、Used Resources:
(1)检查集群资源或所在队列资源或其父队列资源是否已用完;
(2)检查叶子队列某维度资源是否接近或达到上限;
检查是否存在资源碎片:
(1)检查集群 Used 资源和 Reserved 资源之和占总资源的比例,当集群资源接近用满时(例如 90% 以上),可能存在资源碎片的情况,应用的分配速度就会受影响变慢,因为大部分机器都没有资源了,机器可用资源不足会被 reserve,reserved 资源达到一定规模后可能导致大部分机器资源被锁定,后续分配可能就会变慢;
(2)检查 NM 可用资源分布情况,即使集群资源使用率不高,也有可能是因为各维度资源分布不同造成,例如 1/2 节点上的内存资源接近用满 CPU 资源剩余较多,1/2 节点上的 CPU 资源接近用满内存资源剩余较多,申请资源中某一维度资源值配置过大也可能造成无法申请到资源;
检查是否有高优先级的问题应用频繁申请并立即释放资源的问题,这种情况会造成调度器忙于满足这一个应用的资源请求而无暇顾及其他应用;
检查是否存在 Container 启动失败或刚启动就自动退出的情况,可以查看Container 日志 ( 包括 localize 日志、launch 日志等 )、YARN NM 日志或YARN RM 日志进行排查。
TaskManager 启动异常
org.apache.hadoop.yarn.exceptions.YarnException: Unauthorized request to start container. This token is expired. current time is ... found ...
该异常在 Flink AM 向 YARN NM 申请启动 token 已超时的 Container 时抛出,通常原因是 Flink AM 从 YARN RM 收到这个 Container 很久之后(超过了Container 有效时间,默认 10 分钟,该 Container 已经被释放)才去启动它,进一步原因是 Flink 内部在收到 YARN RM 返回的 Container 资源后串行启动。
当待启动的 Container 数量较多且分布式文件存储如 HDFS 性能较慢(启动前需上传 TaskManager配置)时 Container启动请求容易堆积在内部,FLINK-13184 对这个问题进行了优化,一是在启动前增加了有效性检查,避免了无意义的配置上传流程,二是进行了异步多线程优化,加快启动速度。
PyFlink如何定义UDF
在 Apache Flink 1.10 中我们有多种方式进行 UDF 的定义,比如:
Extend ScalarFunction, e.g.:
class HashCodeMean(ScalarFunction):
def eval(self, i, j):
return (hash(i) + hash(j)) / 2
Lambda Functio
lambda i, j: (hash(i) + hash(j)) / 2Named Function
def hash_code_mean(i, j):
return (hash(i) + hash(j)) / 2
Callable Function
class CallableHashCodeMean(object):
def __call__(self, i, j):
return (hash(i) + hash(j)) / 2
现上面定义函数除了第一个扩展 ScalaFunction 的方式是 PyFlink 特有的,其他方式都是 Python 语言本身就支持的,也就是说,在 Apache Flink 1.10中PyFlink 允许以任何 Python 语言所支持的方式定义 UDF。
那么定义完 UDF 我们应该怎样使用呢?Apache Flink 1.10 中提供了2种Decorators,如下:
Decorators - udf(), e.g. :
udf(lambda i, j: (hash(i) + hash(j)) / 2,
[for input types], [for result types])
Decorators - @udf, e.g. :
@udf(input_types=..., result_type=...)
def hash_code_mean(…):
然后在使用之前进行注册,如下:
st_env.register_function("hash_code", hash_code_mean)
接下来就可以在 Table API/SQL 中进行使用了,如下:
my_table.select("hash_code_mean(a, b)").insert_into("Results")
你好,我是王知无,一个大数据领域的硬核原创作者。
做过后端架构、数据中间件、数据平台&架构、算法工程化。
专注大数据领域实时动态&技术提升&个人成长&职场进阶,欢迎关注。