
Flink 优化 | Flink 1.13,面向流批一体的运行时与 DataStream API 优化
回顾 Flink 流批一体的设计
介绍针对运行时的优化点
介绍针对 DataStream API 的优化点
总结以及后续的一些规划
 GitHub 地址
GitHub 地址 一. 流批一体的 Flink
1.1 架构介绍


1.2 优点
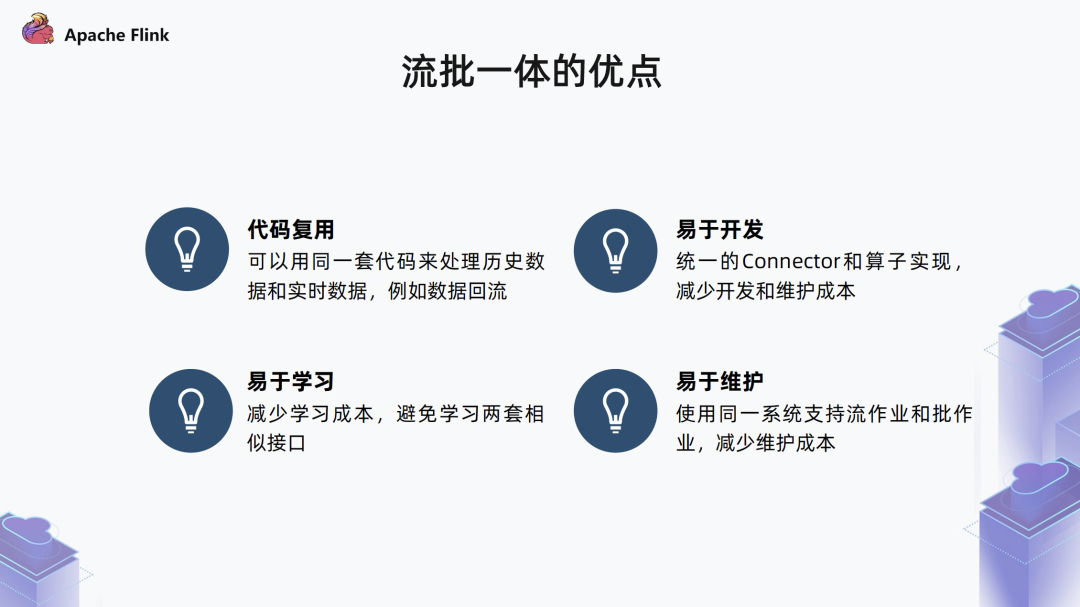
代码复用
易于开发
易于学习
易于维护
1.3 数据处理过程
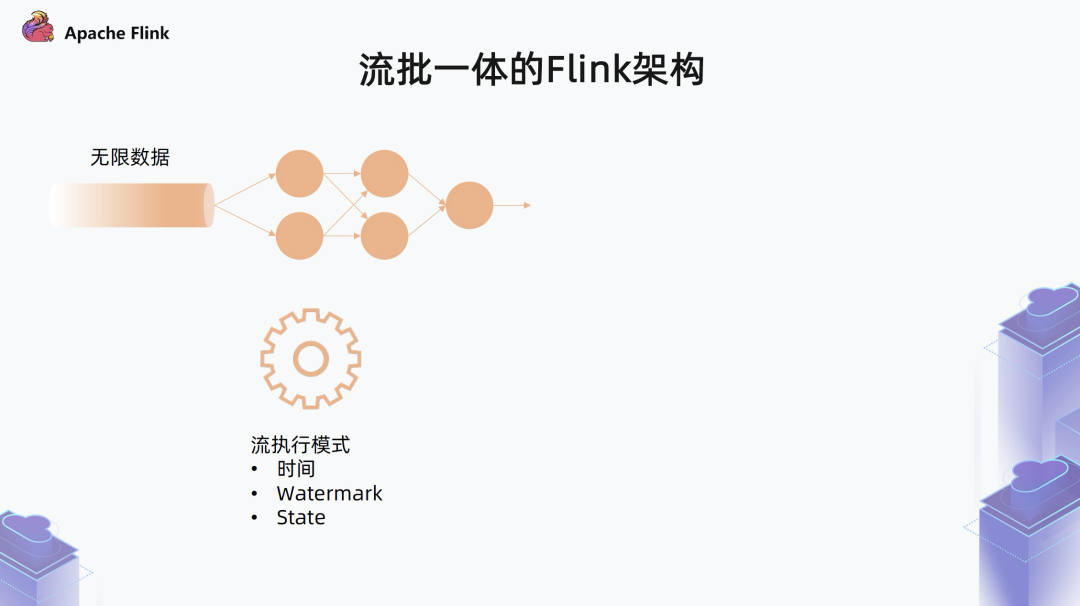
第一种类型的作业是处理无限数据的无限流的作业
这种作业就是我们平时所认知的流作业,对于这种作业,Flink 采用一个标准流的执行模式,需要考虑记录的时间,通过 Watermark 对齐的方式推进整个系统的时间以达到一些数据聚合和输出的目的,中间通过 State 来维护中间状态。
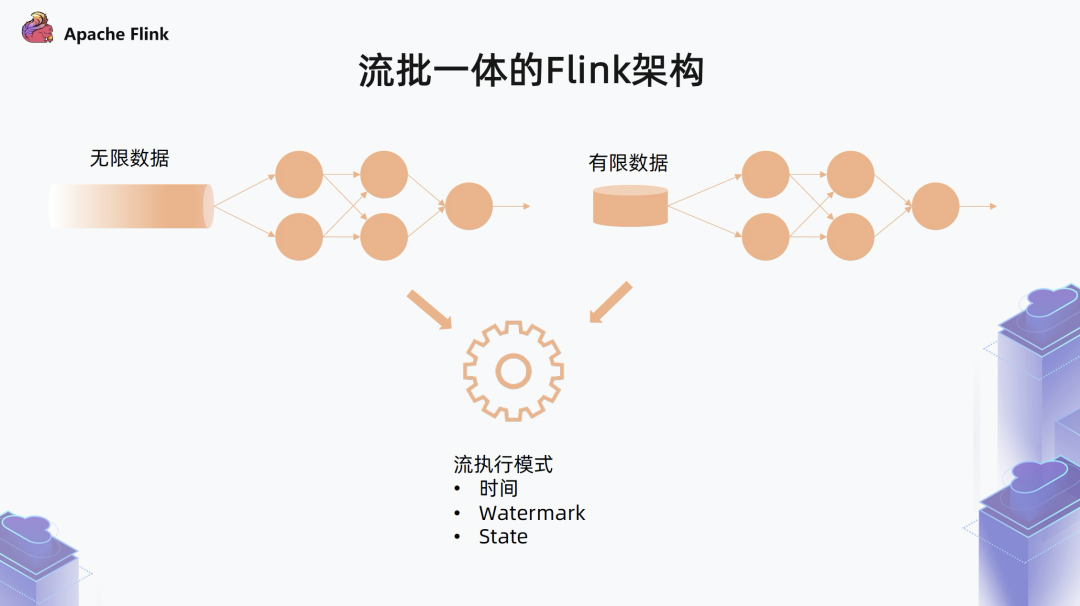
第二种类型的作业是处理有限数据集的作业
数据可能是保存在文件中,或者是以其他方式提前保留下来的一个有限数据集。此时可以把有限数据集看作是无限数据集的一个特例,所以它可以自然的跑在之前的流处理模式之上,无需经过代码修改,可以直接支持。
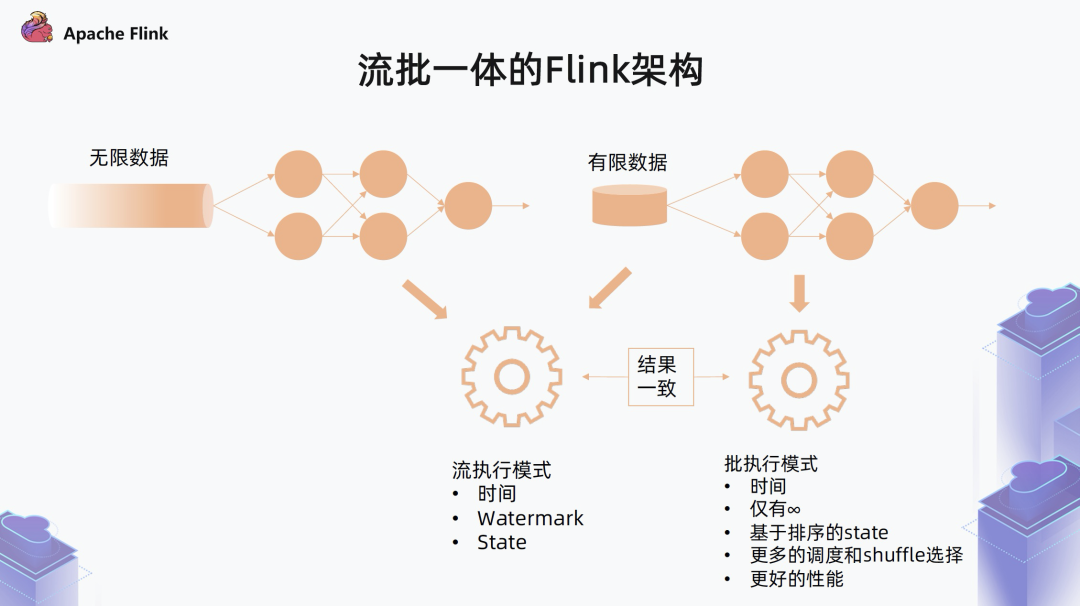
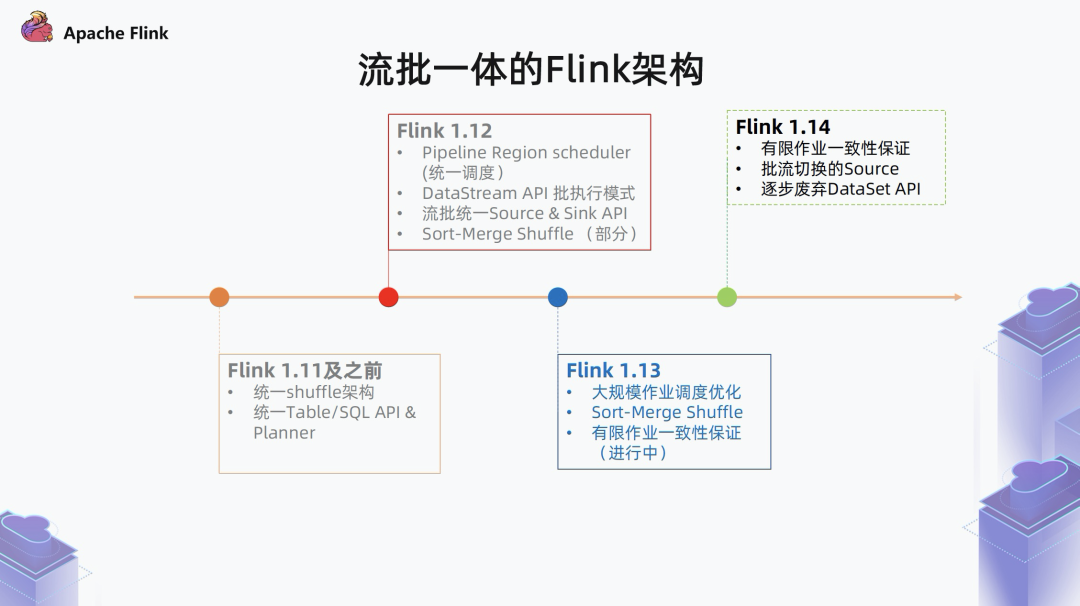
1.4 近期演进
在 Flink 1.11 及之前:
Flink 统一了 Table/SQL API,并引入了统一的 blink planner,blink planner 对流和批都会翻译到 DataStream 算子之上。此外,对流和批还引入了统一的 shuffle 架构。
在 Flink 1.12 中:
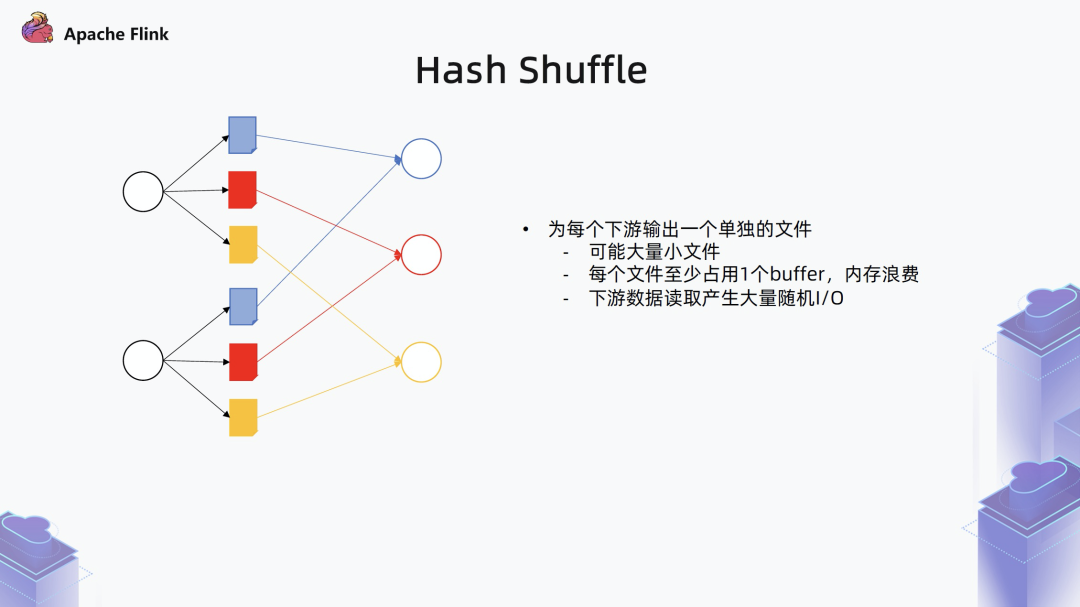
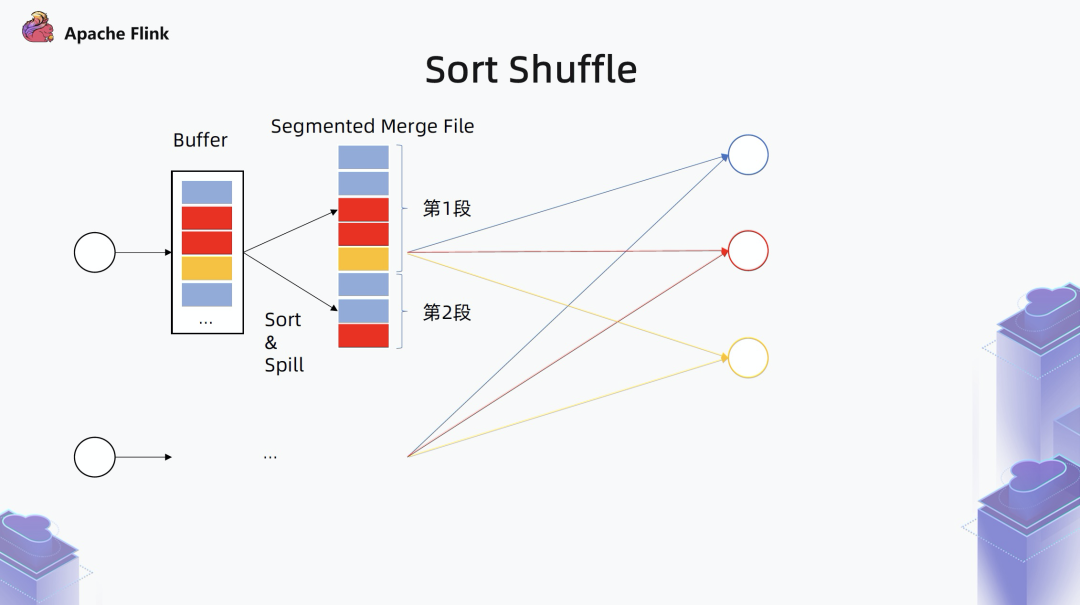
针对批的 shuffle 引入了一种新的基于 Sort-Merge 的 shuffle 模式,相对于之前 Flink 内置的 Hash shuffle,性能会有很大提升。在调度方面,Flink 引入了一种基于 Pipeline Region 的流批一体的调度器。
在 Flink 1.13 中:
完善了 Sort-Merge Shuffle,并对 Pipeline Region scheduler 在大规模作业下进行了性能优化。另外,前面提到过,对于有限流的两种执行模式,我们预期它的执行结果应该是一致的。但是现在 Flink 在作业执行结束的时候还有一些问题,导致它并不能完全达到一致。
所以在 1.13 中,还有一部分的工作是针对有限数据集作业,怎么在流批,尤其是在流的模式下,使它的结果和预期的结果保持一致。
未来的 Flink 1.14:
需要继续完成有限作业一致性保证、批流切换 Source、逐步废弃 DataSet API 等工作。
二. 运行时优化
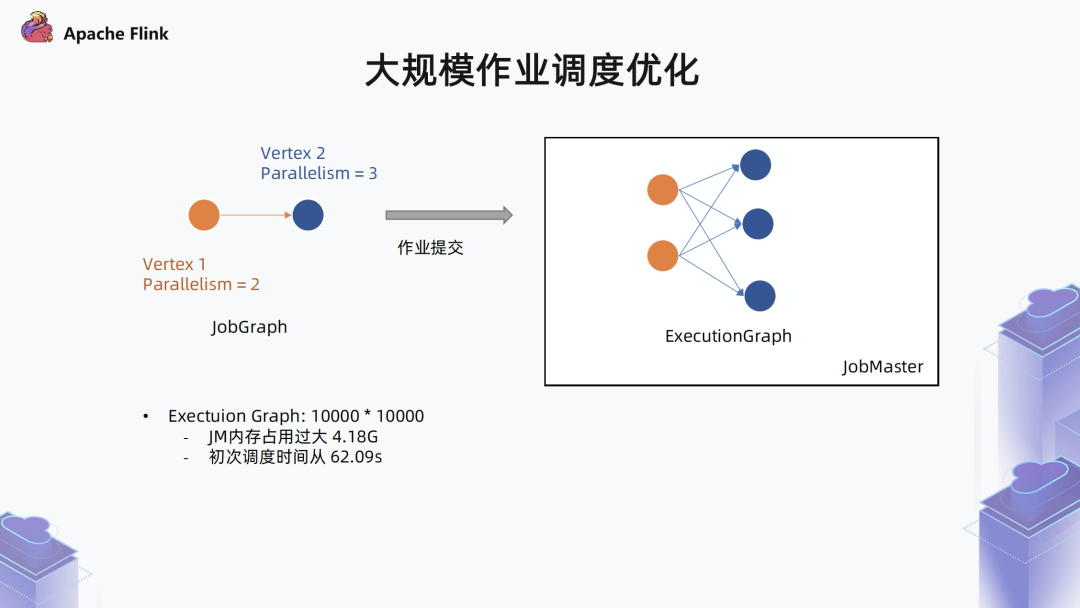
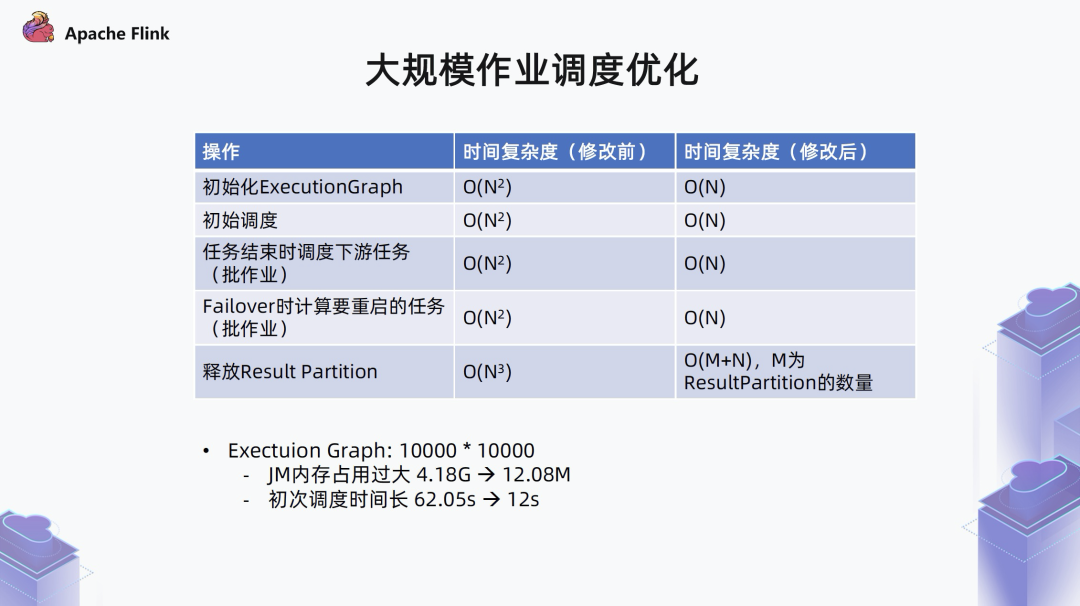
2.1 大规模作业调度优化
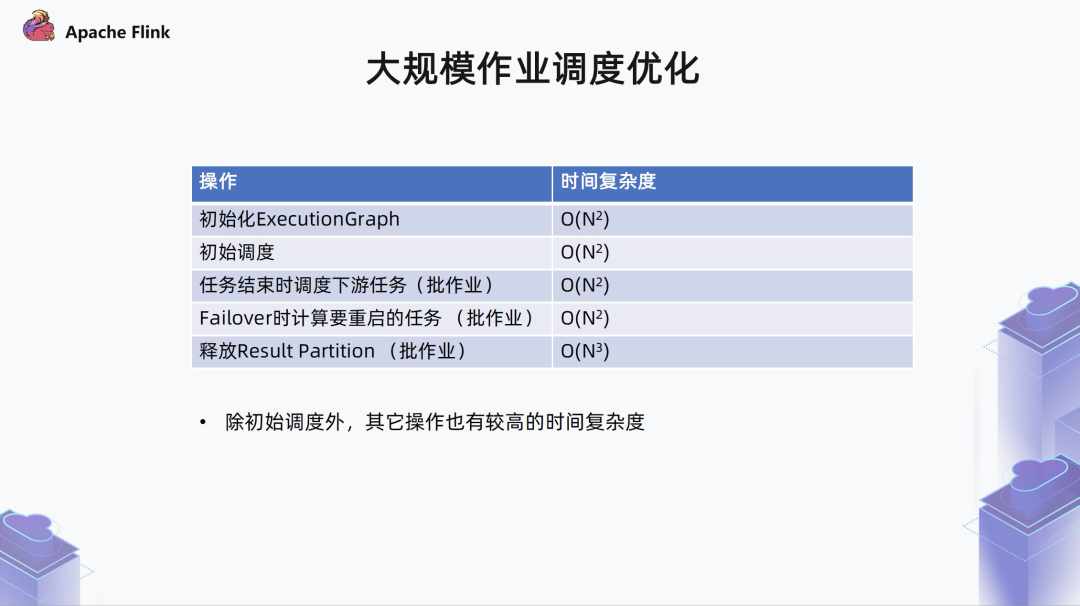
■ 1. 边的时间复杂度问题
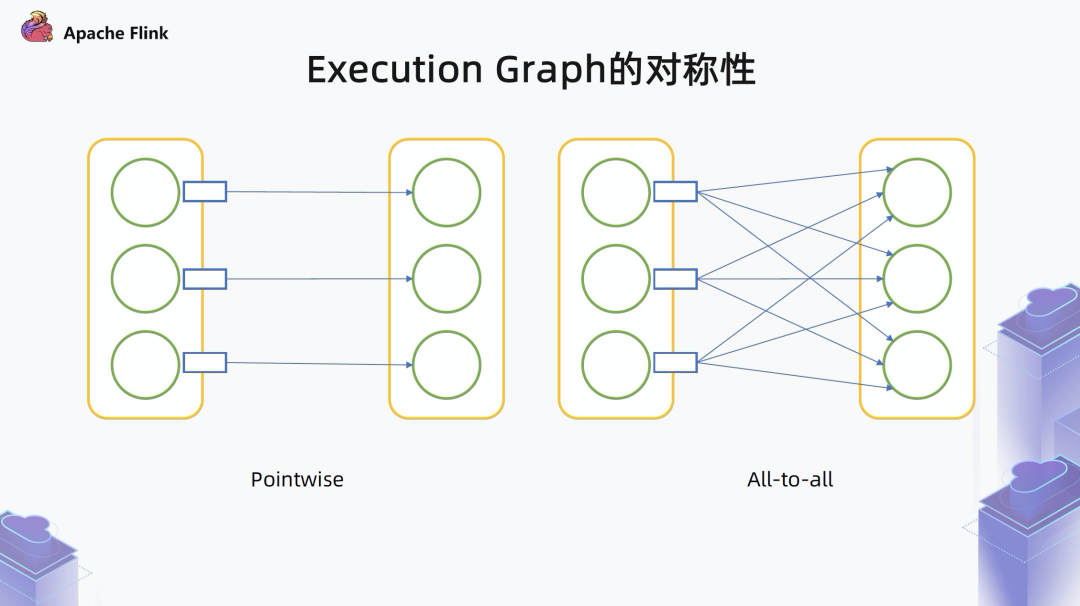
■ 2. Execution Graph 的对称性
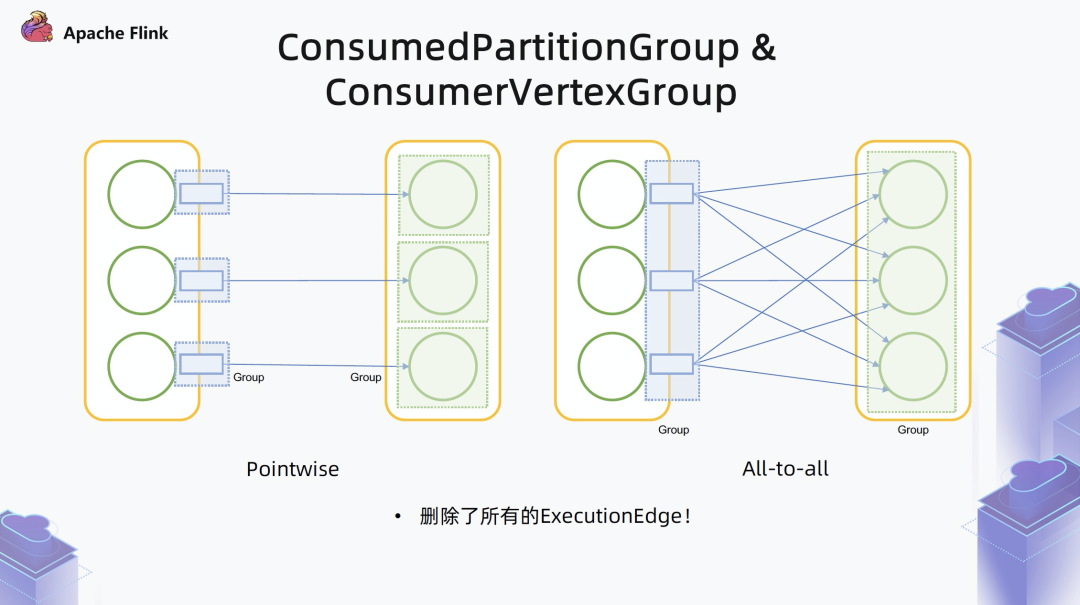
一种是 Pointwise 型,上游和下游是一一对应的,或者上游一个对应下游几个,不是全部相连的,这种情况下,边的数量基本是线性的 O(N), 和算子数在同一个量级。
另一种是 All-to-all 型,上游每一个 task 都要和下游的每一个 task 相连,在这种情况下可以看出,每一个上游的 task 产生的数据集都要被下游所有的 task 消费,实际上是一个对称的关系。只要记住上游的数据集会被下游的所有 task 来消费,就不用再单独存中间的边了。

■ 3. 优化结果
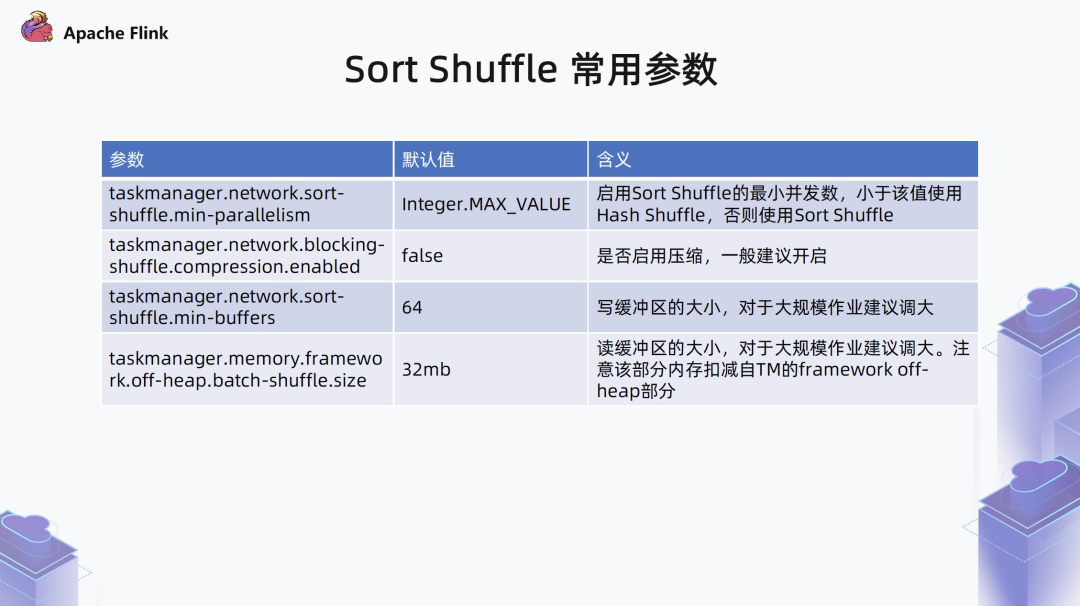
2.2 Sort-Merge Shuffle
■ Hash Shuffle
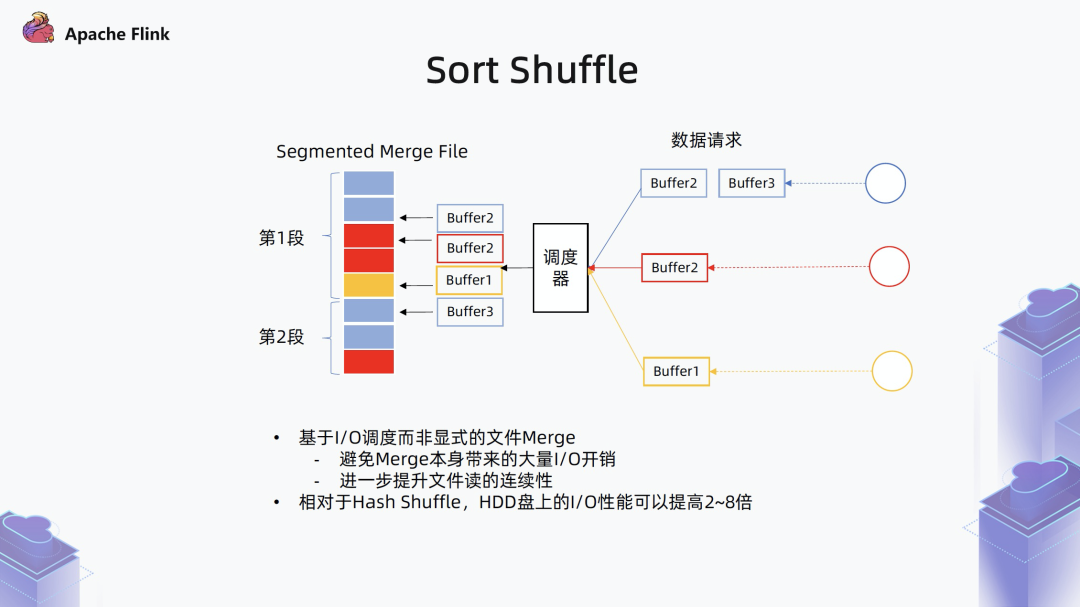
■ Sort Shuffle
三. DataStream API 优化
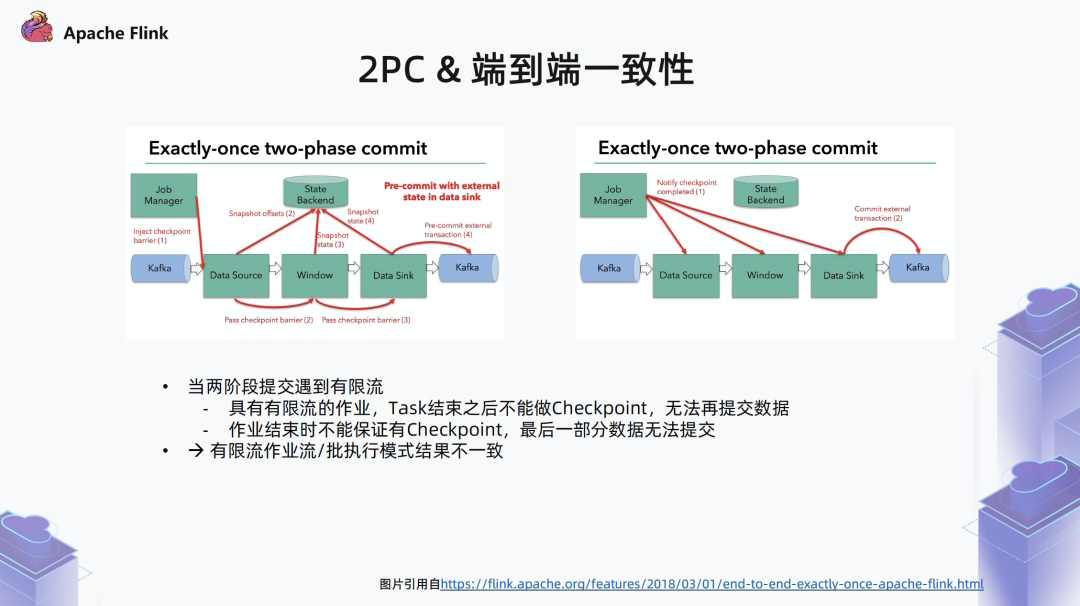
3.1 2PC & 端到端一致性
具有有限流的作业,task 结束之后,Flink 是不支持做 checkpoint 的,比如流批混合的作业,其中有一部分会结束,之后 Flink 就没办法再做 checkpoint,数据也就不会再提交了。
在有限流数据结束时,因为 checkpoint 是定时执行的,不能保证最后一个 checkpoint 一定能在处理完所有数据后执行,可能导致最后一部分数据无法提交。
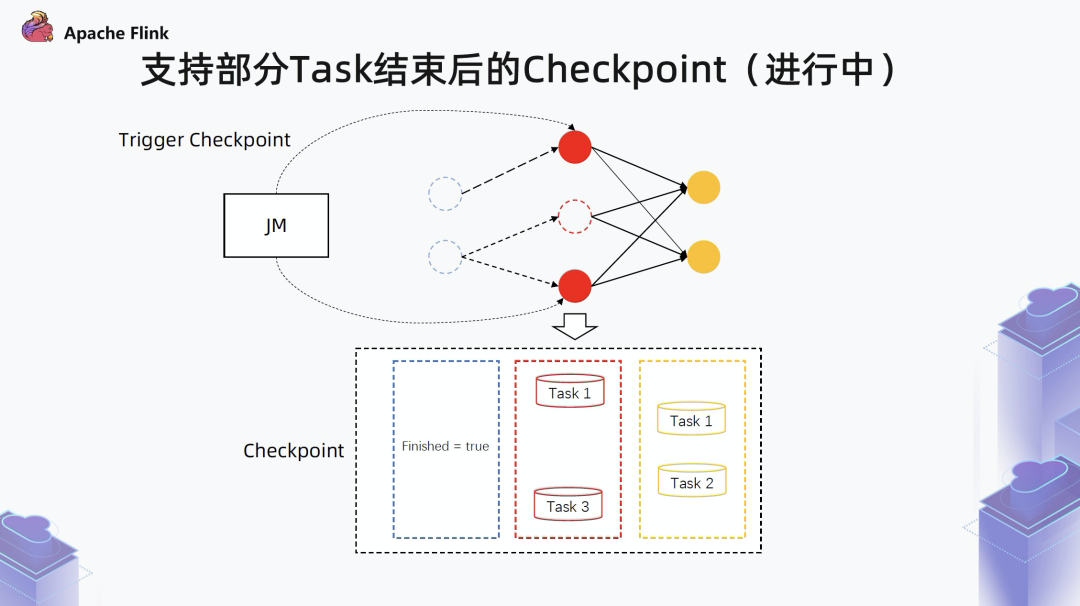
3.2 支持部分 Task 结束后的 Checkpoint (进行中)
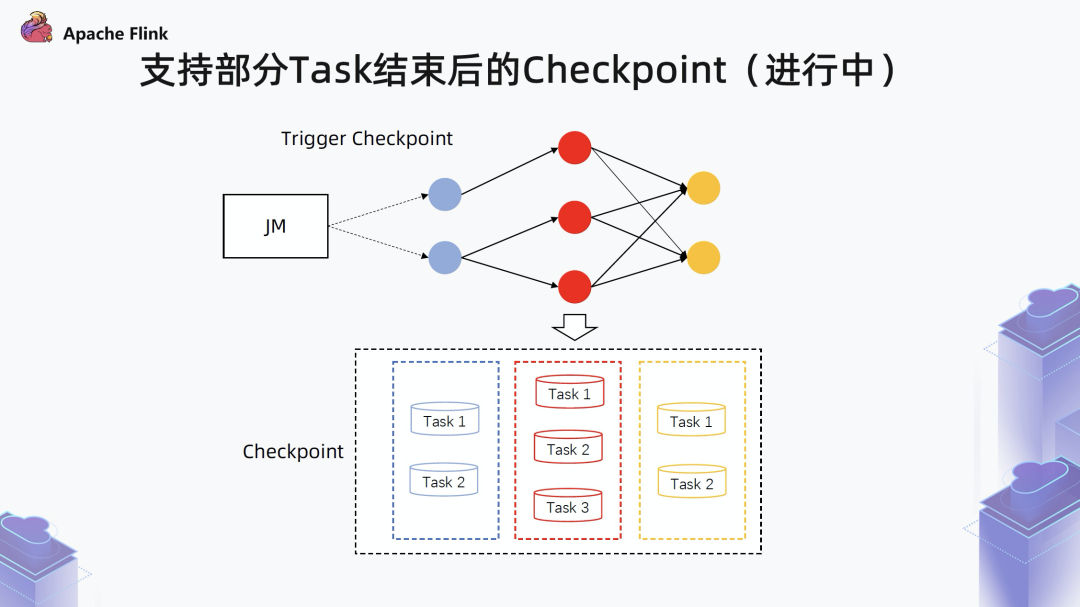
如果一个算子的所有 subtask 都已经结束了,就会为这个算子存一个 finished 标记。
如果一个算子只有部分 task 结束,就只存储未结束的 task 状态。
基于这个 checkpoint ,当 failover 之后还是会拉起所有算子,如果识别到算子的上一次执行已经结束,即 finsihed = true,就会跳过这个算子的执行。尤其是针对 Source 算子来说,如果已经结束,后面就不会再重新执行发送数据了。通过上述方式就可以保证整个状态的一致性,即使有一部分 task 结束,还是照样走 checkpoint。
作业结束:数据是有限的,有限流作业正常结束;
stop-with-savepoint ,采一个 savepoint 结束;
stop-with-savepoint --drain ,采一个 savepoint 结束,并会将 watermark 推进到正无穷大。
对作业结束和 stop-with-savepoint --drain 两种语义,预期作业是不会再重启的,都会对算子调 endOfInput() , 通知算子通过一套统一的方式做 checkpoint 。
对 stop-with-savepoint 语义,预期作业是会继续 savepoint 重启的,此时就不会对算子调 endOfInput()。后续会再做一个 checkpoint , 这样对于一定会结束并不再重启的作业,可以保证最后一部分数据一定可以被提交到外部系统中。

四. 总结
在 Flink 的整个目标里,其中有一点是期望做一个对有限数据集和无限数据集高效处理的统一平台。目前基本上已经有了一个初步的雏形,不管是在 API 方面,还是在 runtime 方面。下面来举个例子说明流批一体的好处。

更多 Flink 相关技术交流,可扫码加入社区钉钉大群~
 戳我,立即报名!
戳我,立即报名!