摘要:本文由社区志愿者佳伟整理,内容来源自 Apache Flink Committer、阿里巴巴高级开发工程师唐云(茶干) 在 5 月 22 日北京站 Flink Meetup 分享的 《State backend Flink – 1.13 优化及生产实践分享》。内容包括:
鸟瞰 Flink 1.13 state-backend 变化
RocksDB state-backend 内存管控优化
Flink state-backend 模块发展规划
Tips:点击文末「阅读原文」即可查看更多技术干货~ GitHub 地址
GitHub 地址
一、鸟瞰 Flink 1.13 state-backend 变化
1. State 访问的性能监控
首先,Flink 1.13 中引入了 State 访问的性能监控,即 latency trackig state。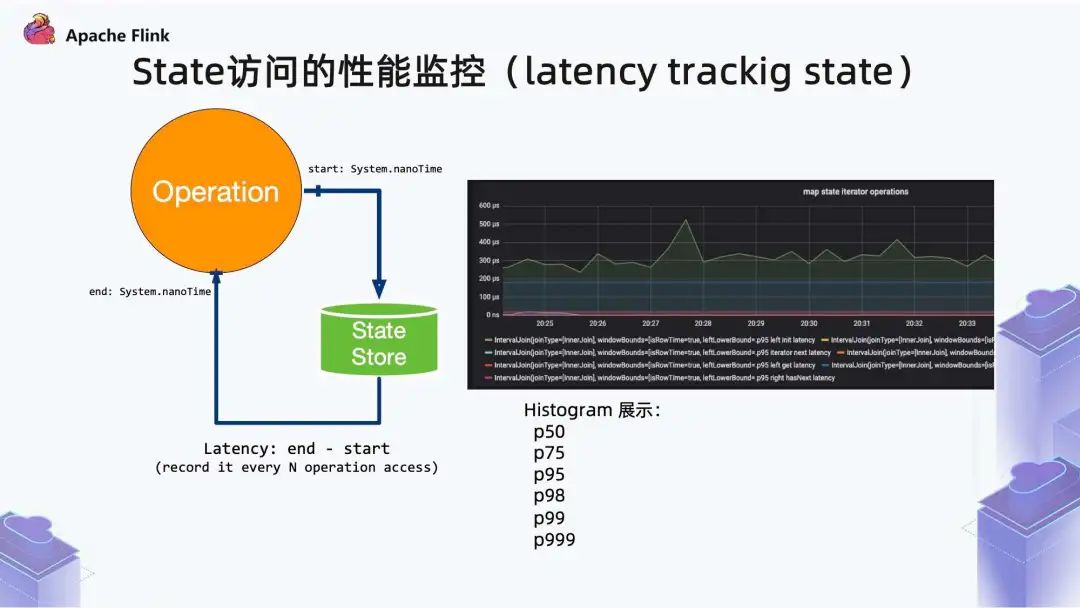
通过对每次访问前后的 System#nanoTime 求差,得到 state 访问延迟值(latency)。此功能不局限于 State Backend 的类型,自定义实现的 State Backend 也可以复用此功能。State 访问的性能监控会产生一定的性能影响,所以,默认每 100 次做一次取样(sample)。上图即监控结果展示。State 访问的性能监控开启后,对不同的 State Backend 性能损失影响不同:

上图所示是三个相关的配置项,默认情况下此功能是关闭的,需通过指定参数 state.backend.latency-track.keyed-state-enabled=true 来手动开启。2. 统一的 Savepoint 格式
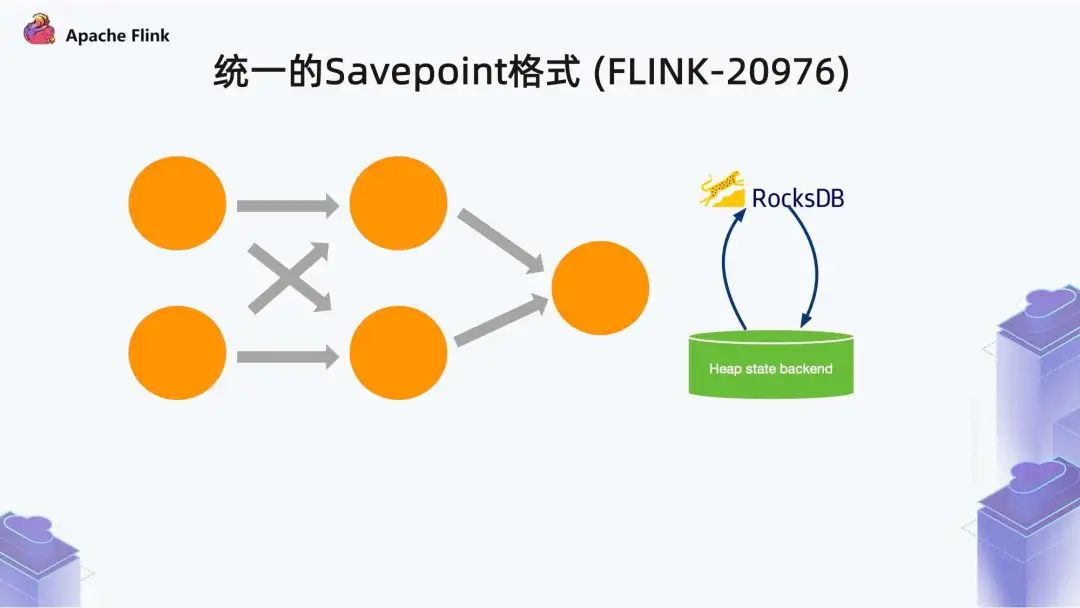
Flink 1.1.3 之后,Savepoint 支持切换 State Backend,极大提升了系统应用性。创建 Savepoint 后,可修改作业拓扑中 State Backend 的类型,如从 RocksDB 切换成 Heap,或从 Heap 切换成 RocksDB,但切换仅限于 Savepoint。Checkpoint 所存储的文件格式与 State Backend 类型相关,而非通用格式,Checkpoint 目前暂不支持该功能。3. 更清晰的 API
还有一个比较重要的改动,就是关于概念上的清晰化。Flink 1.13 中将状态和检查点两者区分开来。在 Flink 中,State Backend 有两个功能:提供状态的访问、查询;
如果开启了 Checkpoint,会周期向远程的 Durable storage 上传数据和返回元数据 (meta) 给 Job Manager (以下简称 JM)。
在之前的 Flink 版本中,以上两个功能是混在一起的,即把状态存储和检查点的创建概念笼统的混在一起,导致初学者对此部分感觉很混乱,很难理解。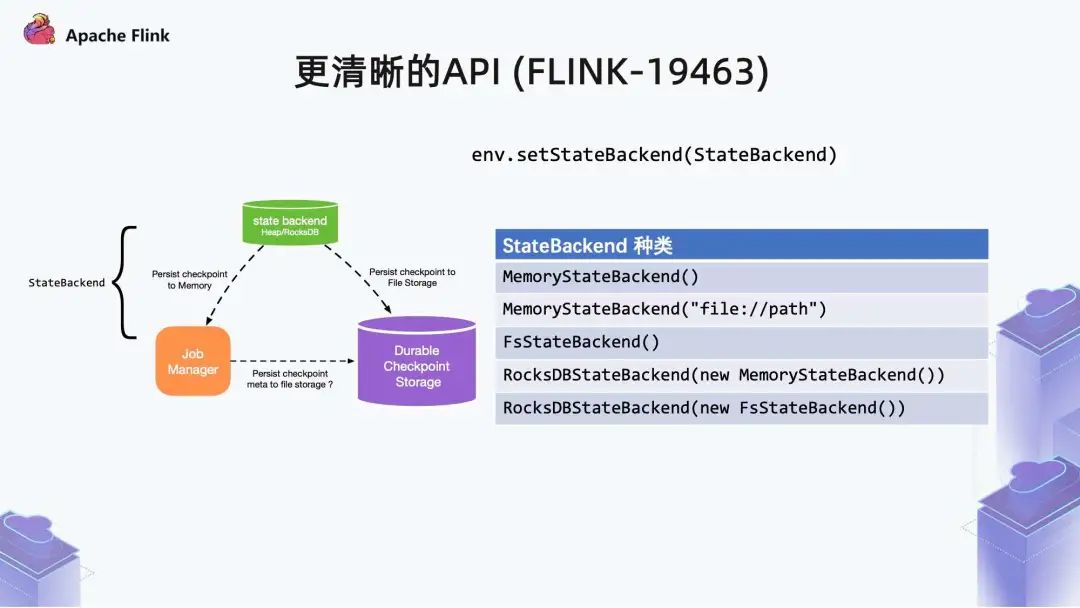
目前,State Backend 的种类如上图所示,由于概念的混乱,导致之前的写法中,RocksDB State Backend 中是可以嵌入 Memory State Backend 或 Heap State Backend 的。实际上,RocksDB 里面嵌入的 State Backend,描述的是其内部 Checkpoint 数据传输方向。对于 Memory State Backend,在原始构建下,未指定任何的 filepath。且在不开启 HA 的模式下,会将所有 Checkpoint 数据返回给 JM。当 Memory State Backend 指定 filepath,满足上传条件时,Checkpoint 数据直接上传到指定 filepath 下,数据内容不会返回给 JM。对于 Fs State Backend,数据会直接上传到所定义的 filepath 下。当然,大家线上用的最多的还是 RocksDB State Backend 搭配上一个远程 fs 地址,旧的写法对于使用 Flink 的用户来说,容易造成状态和检查点理解混乱。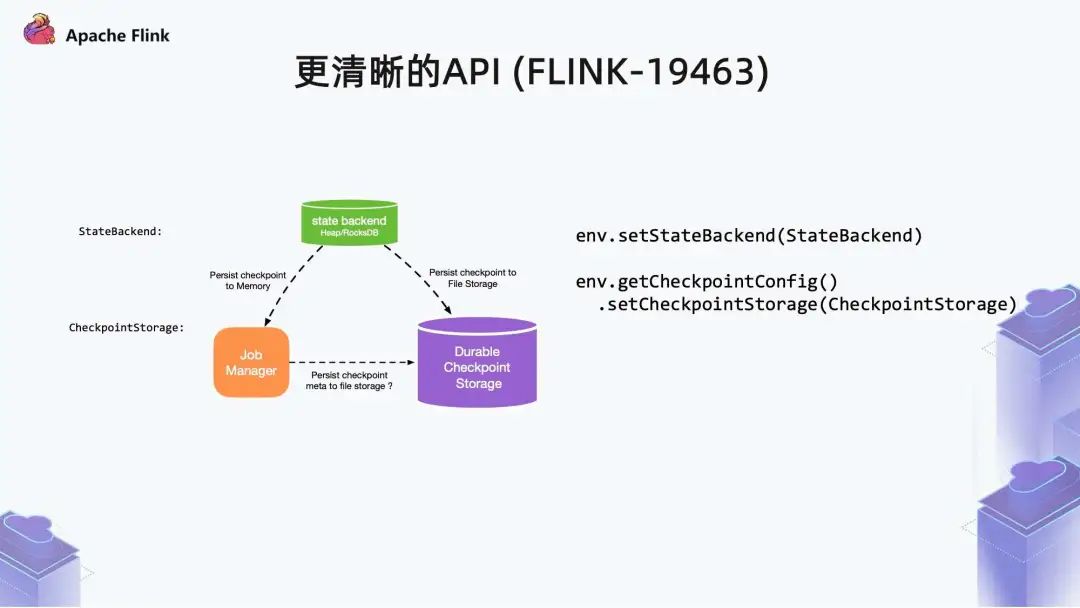
- 其中,State Backend 的概念变窄,只描述状态访问和存储;
- 另外一个概念是 Checkpoint storage,描述的是 Checkpoint 行为,如 Checkpoint 数据是发回给 JM 内存还是上传到远程。所以,相对应的配置项也被拆开 。
当前不仅需要指定 State Backend ,还需要指定 Checkpoint Storage。以下就是新老接口的对应关系:
当然,虽然旧接口目前仍然保存,但还是推荐大家使用新接口,向新方式迁移,从概念上也更清晰一些。4. RocksDB partitioned Index & filter
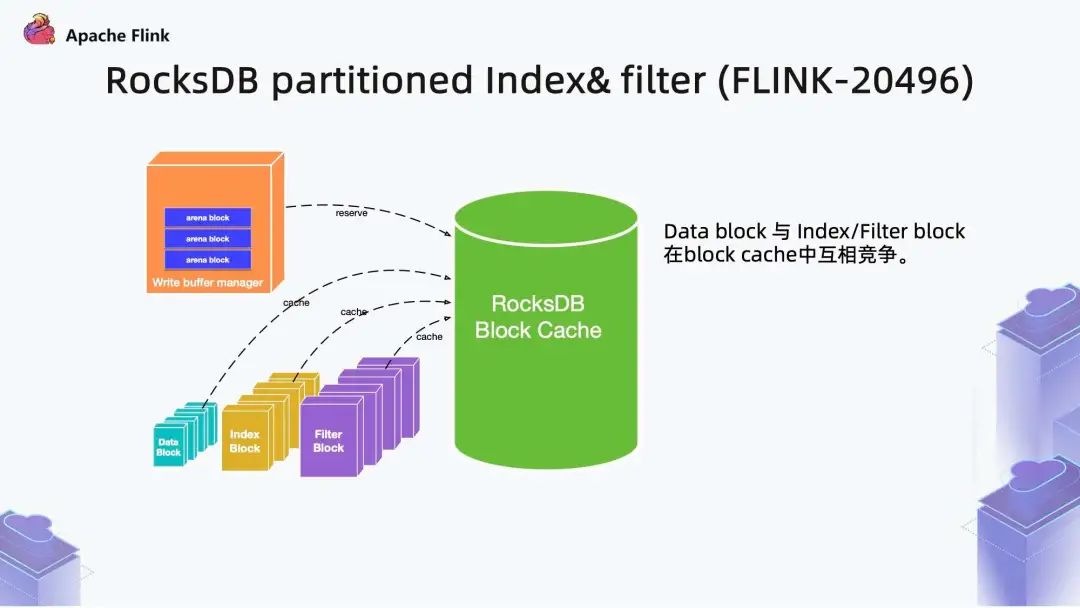
Flink1.13 中对 RocksDB 增加了分区索引功能。如上图所示,RocksDB Block Cache 中存储的数据包含三部分:
- Filter Block (对文件的 Bloom Filter)
可以通过方块大小明显看出块大小,Index 和 Filter 是明显大于 Data 的。以 256M SSD 文件为例,Index Block 大概是 0.5M,Filter Block 大概是 5M,Data Block ze 则默认是 4KB。当 Cache Block 是几百 MB 的时,如果文件数特别多,Index 和 Filter 不断的替出换入,性能会非常差,尤其是在默认开启了内存管控后。比较明显的现象是,IO 特别频繁,性能始终上不去。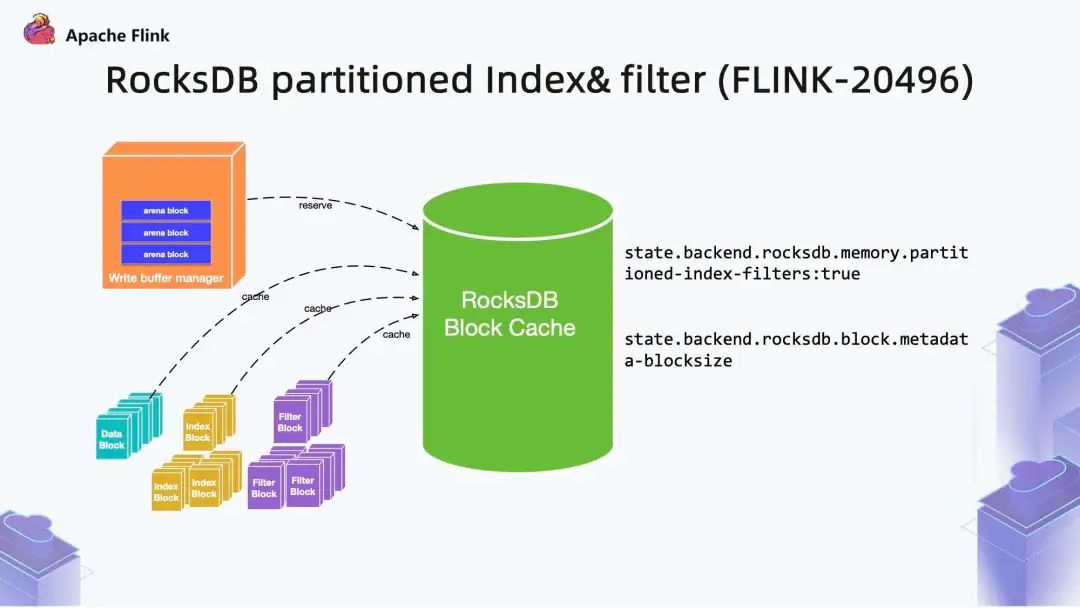
Flink1.13 中,复用了 RocksDB 的 partitioned Index & filter 功能,简单来说就是对 RocksDB 的 partitioned Index 做了多级索引。也就是将内存中的最上层常驻,下层根据需要再 load 回来,这样就大大降低了数据 Swap 竞争。线上测试中,相对于内存比较小的场景中,性能提升 10 倍左右。所以,如果在内存管控下 Rocksdb 性能不如预期的话,这也能成为一个性能优化点。- state.backend.rocksdb.memory.partitioned-index-filters:true (默认 false)
- state.backend.rocksdb.block.metadata-blocksize (多级索引内存配置)
5. 默认行为变化

Flink1.13 中,默认行为发生如上图所示变化。当然,性能提升的同时,对 HDFS 底层压力更大些,如果升级后 HDFS 不稳定,可考虑是否与此处相关。
二、RocksDB state-backend 内存管控优化
Flink 1.10 开始做 state-backend 内存优化,在之后的每个版本中都有相关改进。

对 RocksDB State Backend 做内存管控的最基本原因在于 Flink state 与 RocksDB 的 Column Family (独立内存) 一一对应。在 Flink 1.10 之前,如果声明两个 state,会各自享用自己的 Write Buffer 和 Cache 内存,Flink 并没有对一个 operator 中的 state 数量限制,理论上用户可以设置几千个、几万个 state,可能导致容器内存撑爆。另外,Flink 在 slot-sharing 机制下,一个 slot 内可以存在多个包含 keyed state 的 operator,也很难保证 state 个数不超。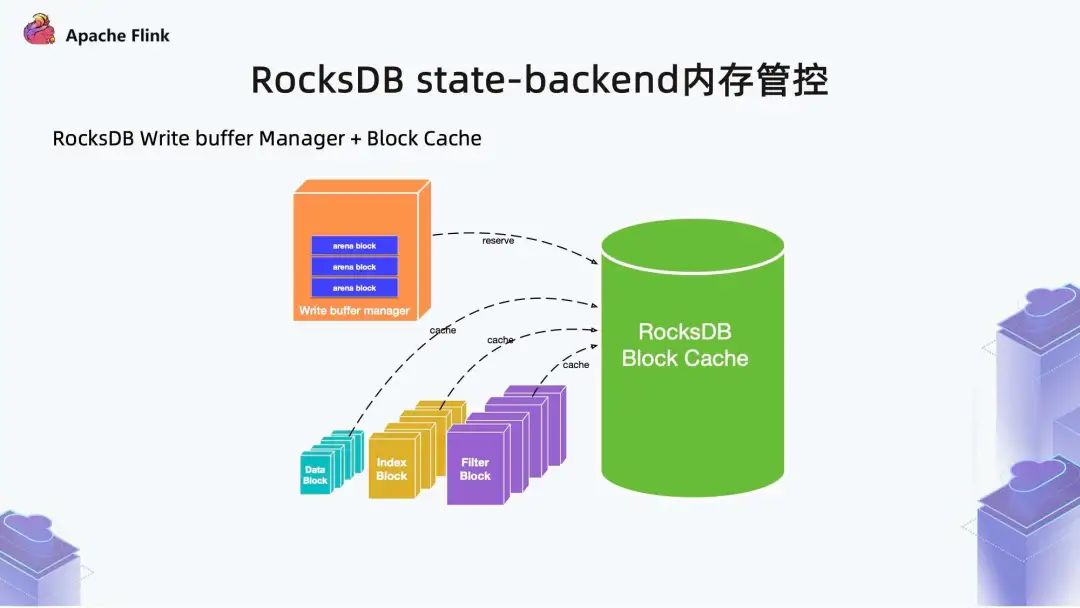
多个 RocksDB 会有多个 Write Buffer Manager 。如上图所示,以单个 Write Buffer Manager 为例,它将自己的内存 reserve 到 Block Cache 中,根据自己的内存管控逻辑来实现记账,Block Cache 内有 LRU Handle,超出预算时,会被踢出。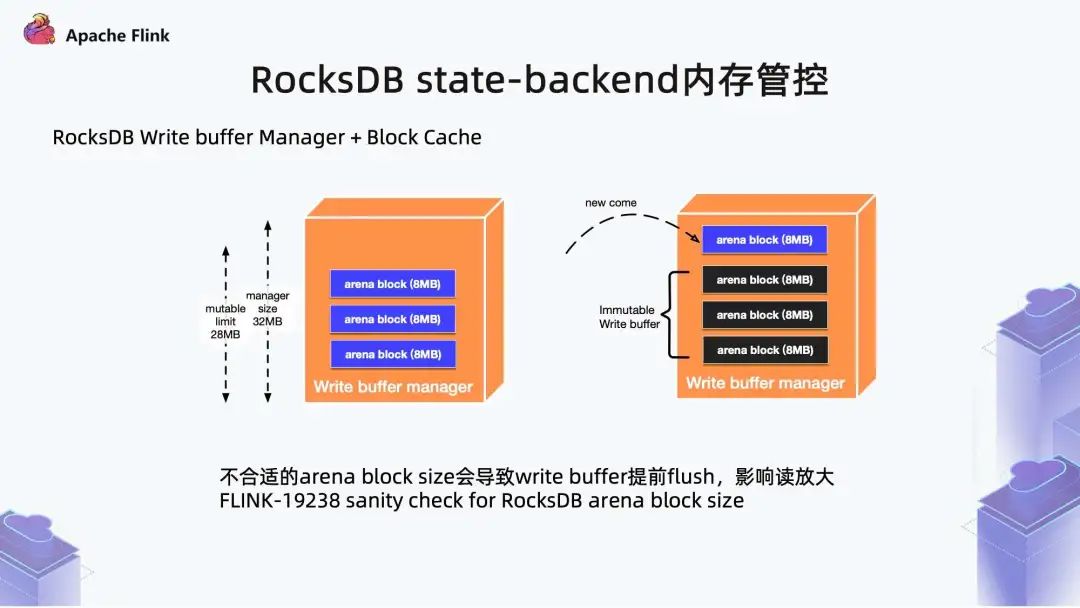
上图提到的 arena block ,是 Write Buffer 最小内存分配单元,默认是 Write buffer 默认配置的 1/8,内存默认为 8MB。但在极端情况下,磁盘上会出现小文件过多的现象,导致性能非常差。如当整体内存分配过小时,Write Buffer 所管控的内存数量也就会比较少,刚开始申请内存时,默认申请 8MB 内存,当已用内存达到总内存的 7/8 时,会被置为 Immutable (置为不可变),之后这部分数据被替出到磁盘上。如果单个 arena block 内存占比过大,可能会出现临界 arena block 只写了几 KB,但触发了 Write Buffer 的内存行为管控,将 arena block 置为了 Immutable,之后的数据就会被刷出去,产生小文件,导致性能非常差。对于 LSM DB 来说,提前 flush,对读放大性能产生很大影响,Write Buffer 无法缓存更多读请求。我们引入对 arena block 大小有强校验,当 arena block 大小不合适时,会打印 Warning 级别日志,认为当前需要对 arena block 大小作出相应调整。即需要降低 arena block 大小,从而解决数据提前被 flush 的问题,进而提升性能。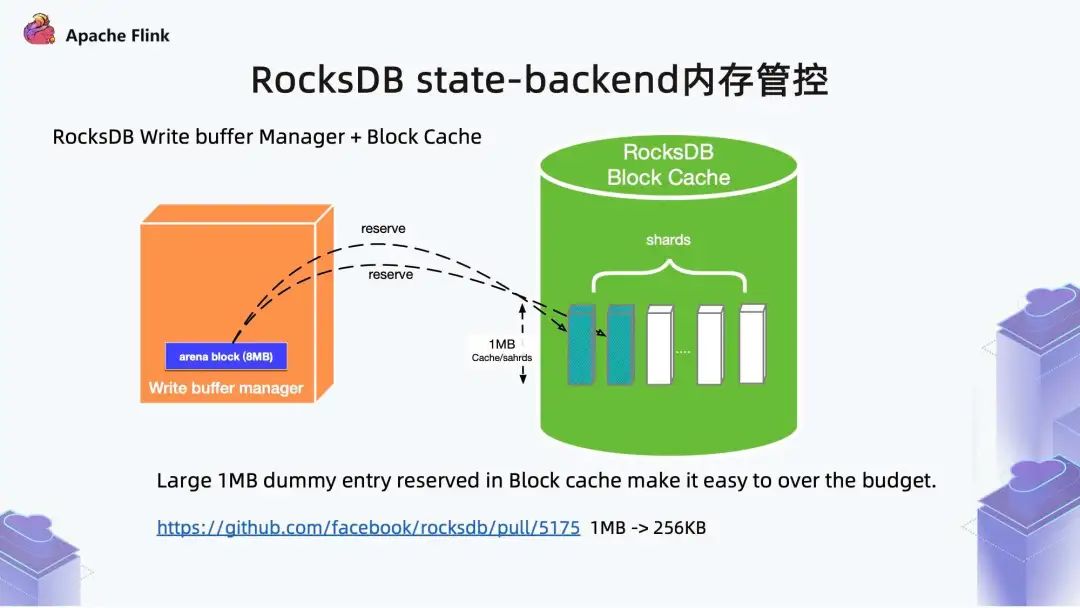
RocksDB Block Cache 为了提高并发性能,将 arena block 分成了若干个分片 (shards)。实质上是 Write Buffer Manager 在做 reserve 时,将 arena block 拆成了若干个 dummy entry,实际上只做了记账,会占据 block cache 的逻辑容量。目前 Flink 使用的 RocksDB 版本中,shards 默认是 1MB,可能会有 shards 的数据超过预算的风险。后来的 RocksDB 高版本中,将 1MB 调成了 256KB 来解决这个风险。由于 Flink 1.13 中没有对 RocksDB 版本升级,所以这个问题依然存在。此外,Flink 1.13 中,没有将 RocksDB Block Cache 内存管控设置成严格模式 (Strict Mode)。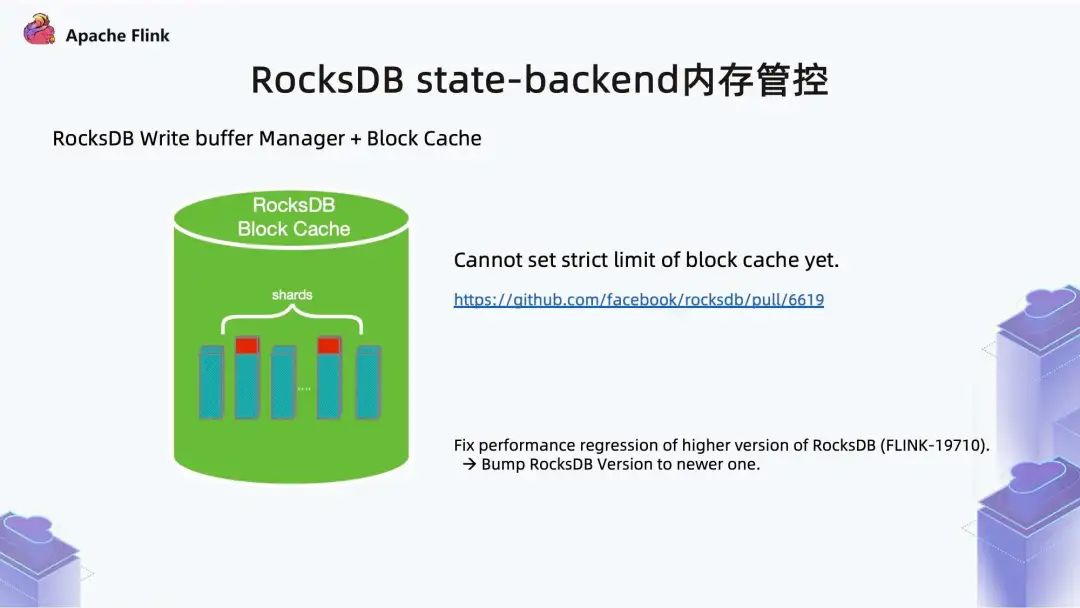
目前社区用的 RocksDB 的版本是 5.17.2,与 RocksDB 社区最新的 6.17+ 版本,相差大概一两千个 commit。社区在尝试升级 RocksDB 版本时,发现高版本有一些性能回退,即使尽力解决,也只是解决了其中一部分,在部分访问接口下,还是有大约不到 10% 的性能下降。所以,Flink 1.13 决定暂不升级 RocksDB 版本,社区预计会在 Flink 1.14 中做相应升级,引入 RocksDB 一些新的 future,借此弥补目前已知的 10% 性能回退的 Gap。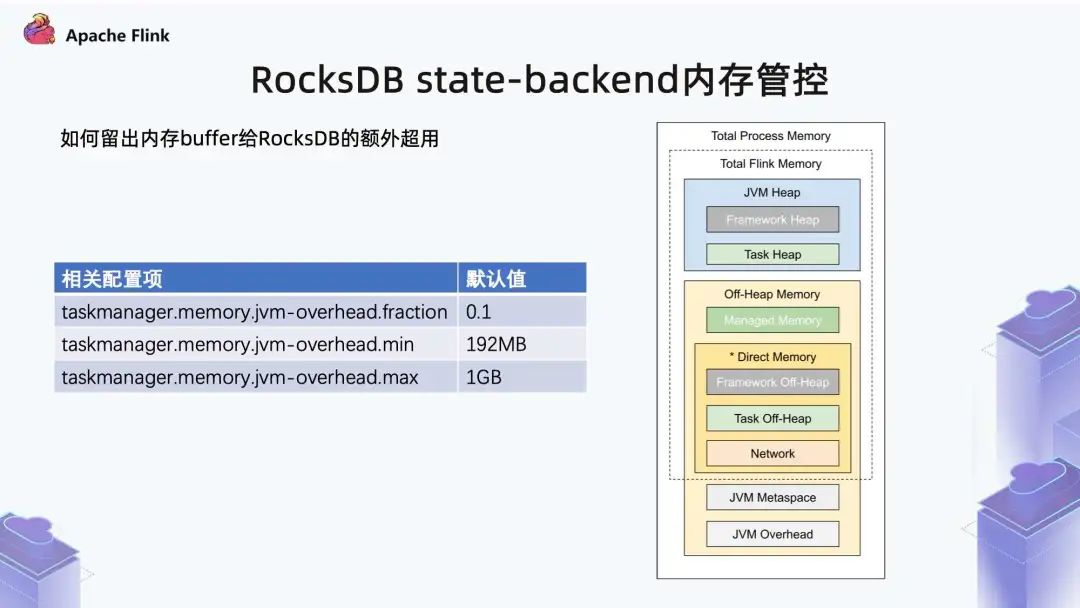
综上各种问题,RocksDB 内存管控不完善,加上 Writer Buffer 对 Data Block 不严格的管控,在理论上还是存在一定小几率内存超用的。但就目前来看,整体还是比较稳定,超用的部分不会太多。如果想手动多分一部分内存给 RocksDB 来防止超用,预防在云原生的环境因 OOM 被 K8S kill,可手动将 JVM OverHead 内存调大,如上图所示。之所以不调大 Task Off-Heap,是由于目前 Task Off-Heap 是和 Direct Memeory 混在一起的,即使调大整体,也并不一定会分给 RocksDB 来做 Buffer,所以我们推荐通过调整 JVM OverHead 来解决内存超用的问题。同理,如果 Flink 中用到其他相关库,遇到相似问题,也可以尝试将 JVM OverHead 调大来解决。如果想查明内存泄漏原因,也可以结合相应 jemalloc + jeprof 等分析工具排查解决。
三、 Flink state-backend 模块发展规划
在 Flink 的未来规划里,基于 Changelog 的更快速更通用的增量 Checkpoint 机制,正在开发中。而目前只有 RocksDB 支持增量 Checkpoint。
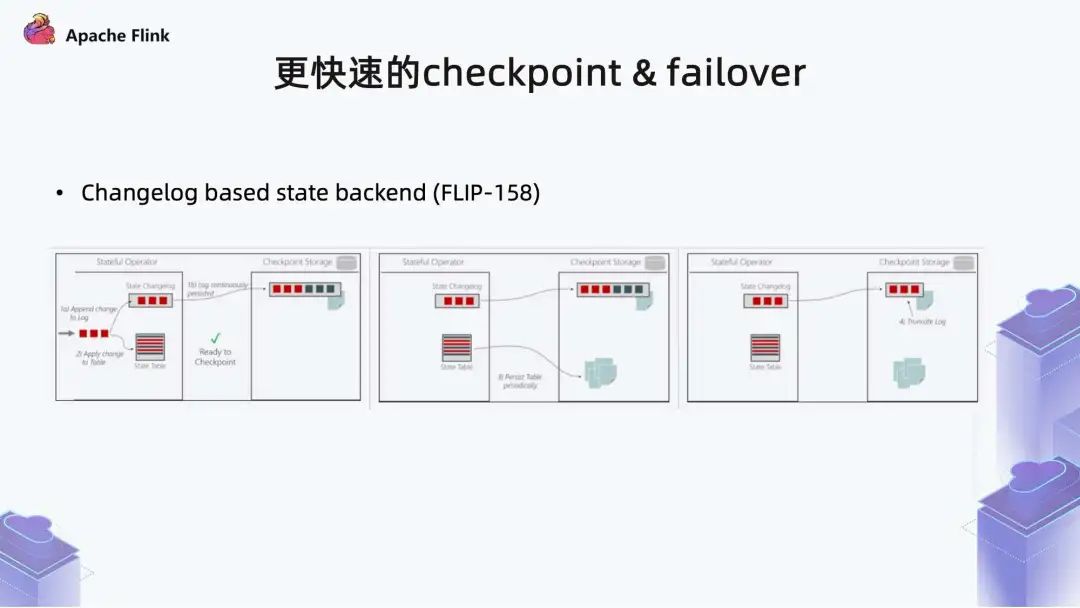
对于 Changelog,在 Apache Kafka 和 Apache Pulsar 中都有这个概念。Changelog 的引入,是 Flink 作为流式计算系统,对传统消息中间件的借鉴。即在数据上传同时,做一个 proxy,将数据定期写到外部的 log 里,每次做 Checkpoint 时不需要等数据上传,进而使 Checkpoint 的时间更加可控。Flink 1.13 已经实现了 proxy 代理层,实际的逻辑层还没有实现,在 Flink 1.14 中会做具体实现,包括相关 log 清理逻辑。希望在 Flink 1.14 中对状态和检查点性能有更好的提升,尤其是目前二阶段提交依赖于 Checkpoint commit,Changelog State Backend 的引入,预计在 Flink 1.14 可以尽快解决相关痛点。
更多 Flink 相关技术交流,可扫码加入社区钉钉大群~
▼ 关注「Flink 中文社区」,获取更多技术干货 ▼
 戳我,立即报名!
戳我,立即报名!
