
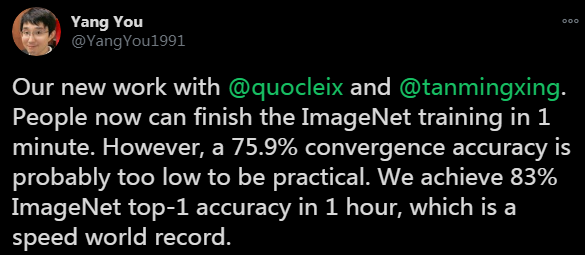
ImageNet训练再创纪录!谷歌提出1个小时训练EfficientNet,准确率高达83%!
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者 | 青暮
1
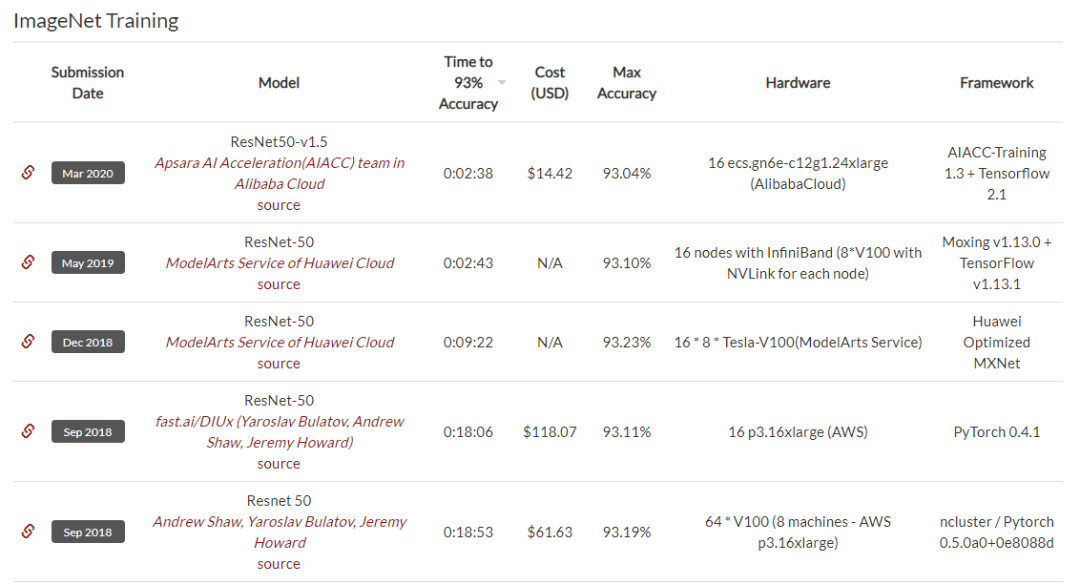
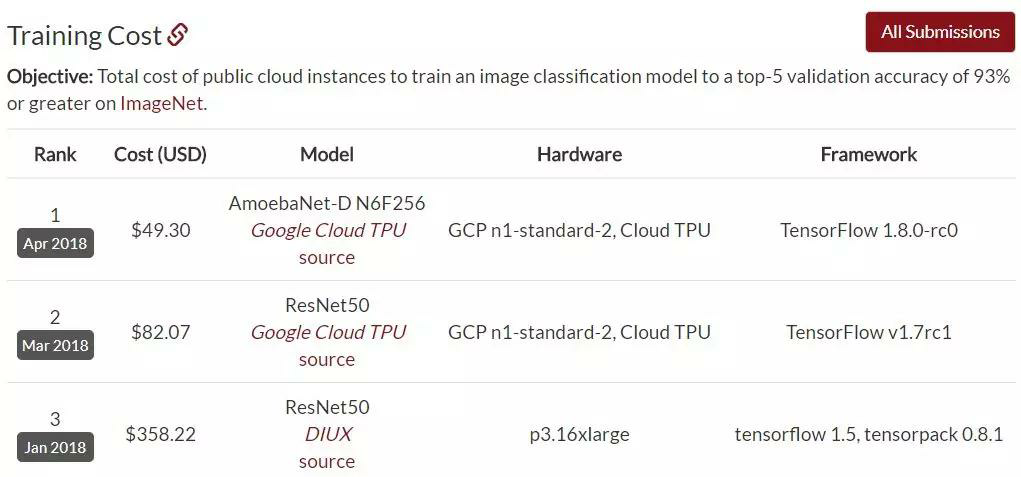
ResNet霸榜,偶有对手



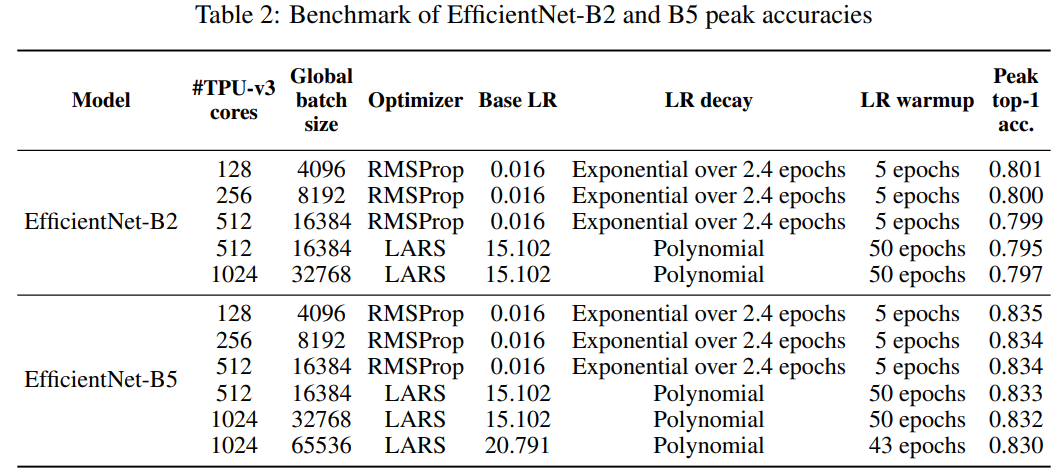
2
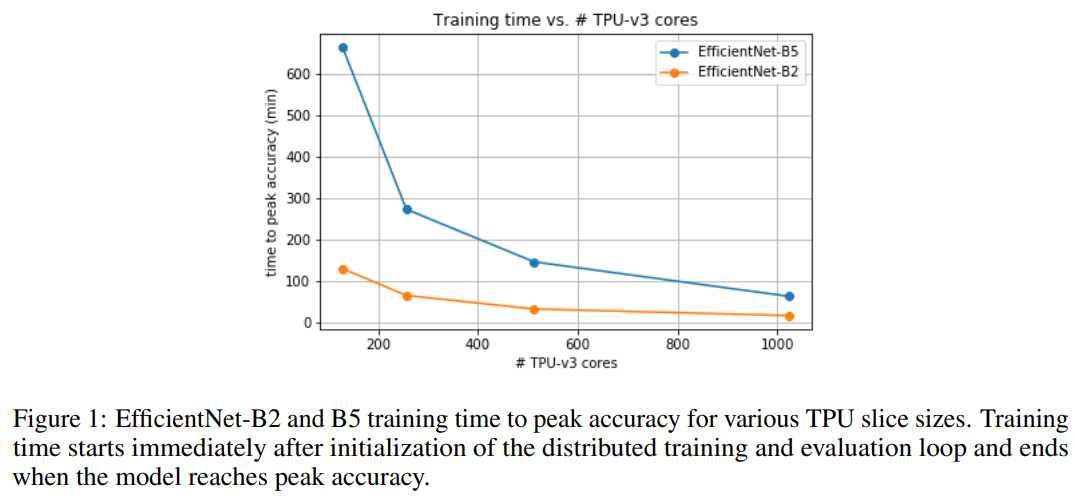
方法
论文PDF下载
链接: https://pan.baidu.com/s/1w_3nt6lx0rX4QyFzPdckug
提取码: qxwq
推荐下载
82页《现代C++教程》:高速上手C++ 11/14/17/20
链接: https://pan.baidu.com/s/11jMlqcTD55bdD-u1q5026Q
提取码: m5yu
下载1:速查表
在「AI算法与图像处理」公众号后台回复:速查表,即可下载21张 AI相关的查找表,包括 python基础,线性代数,scipy科学计算,numpy,kears,tensorflow等等
下载2 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
觉得不错就点亮在看吧

评论