
CPU 使用率过高和 jvm old 占用过高排查过程
报警
cpu使用率过高报警,接近100%
后续又来了jvm old过高报警
排查过程
首先打开监控平台看报警节点的cpu使用情况
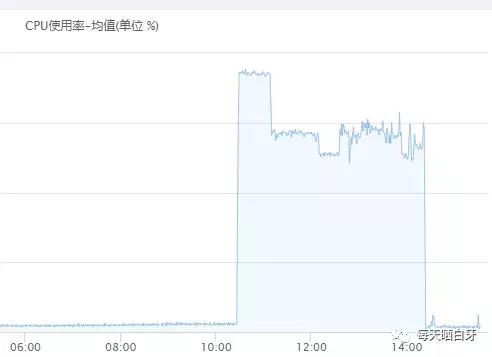
登录服务器找到占用 cpu过高线程堆栈信息
①通过 top 命令找到占用cpu最高的 pid[进程id]
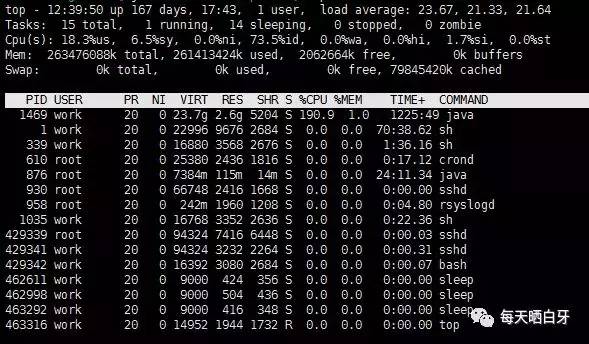
定位到pid是 1469
②通过 top -Hp pid 查看进程中占用cpu过高的 tid[线程id]
③通过 printf pid |grep tid 把线程id转化为十六进制
④通过 jstack pid | grep tid -A 30 定位线程堆栈信息
占用cpu过高的线程有两个,其中一个是打印异常日志的(会new 对象),还有gc线程
打印异常堆栈
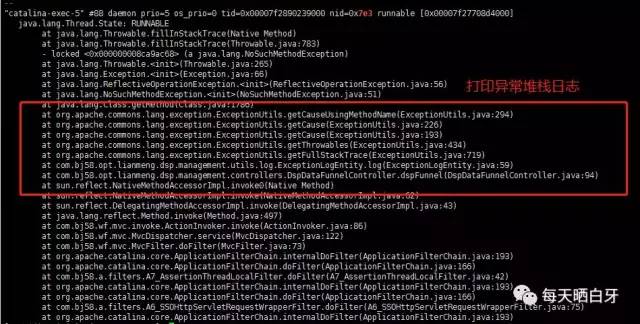
这个占用cpu根据堆栈信息就可以定位,看下代码,可以发现new 对象,且打印全栈信息
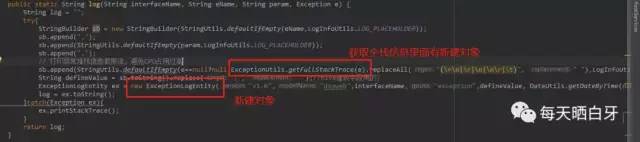
其中ExceptionUtils.getFullStackTrace(e) 属于commons.lang包
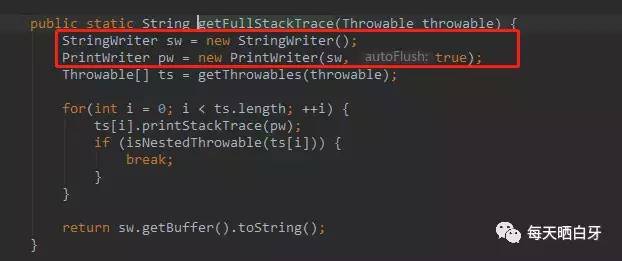
可以发现上面两个方法会创建很多对象且打印堆栈信息占用内存
gc线程
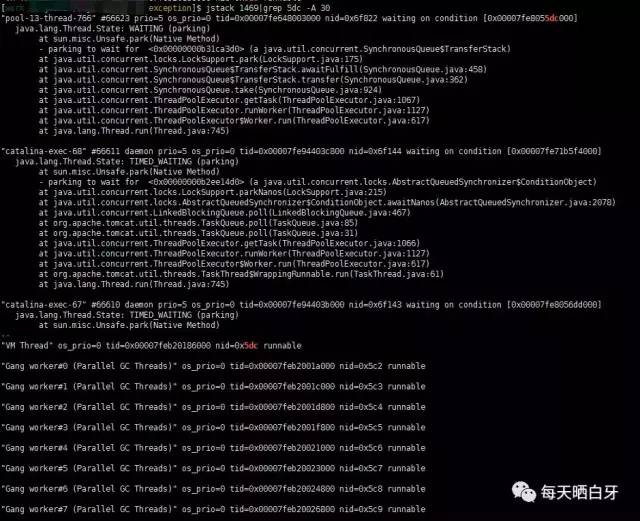
可以发现占用cpu过高的线程进行大量的gc
1. 通过 jstat -gcutil pid 时间间隔 查看 jc 信息
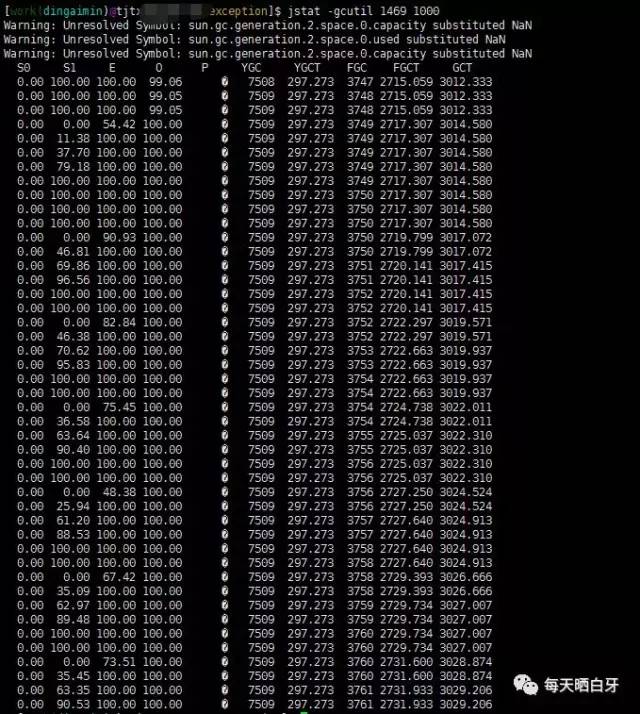
可以发现伊甸园区和老年代都已经满了,且进行了大量的FGC
指标介绍
S0:年轻代第一个幸存区(survivor)使用容量占用百分比
S1:年轻代第二个幸存区(survivor)使用容量占用百分比
E:年轻代伊甸园区(eden)使用容量占用百分比
O:老年代使用容量占用百分比
P:perm代使用容量占用百分比
YGC:从应用程序启动到当前采样时年轻代gc的次数
YGCT:从应用程序启动到当前采样时年轻代gc的时间
FGC:从应用程序启动到当前采样时老年代gc的次数
FGCT:从应用程序启动到当前采样时老年代gc的时间
GCT:从应用程序启动到当前采样时gc总耗时
2. 导出dump文件,使用jdk自带的jvisualvm.exe分析
使用 jmap -dump:format=b,file=name.dump pid 导出dump文件,一般dump文件会比较大【我的这个2.94G】,然后下载【可以用 sz name.dump】到本地用jvisualvm【jdk自带的,在bin目录下】分析
首先看下dump文件的概要
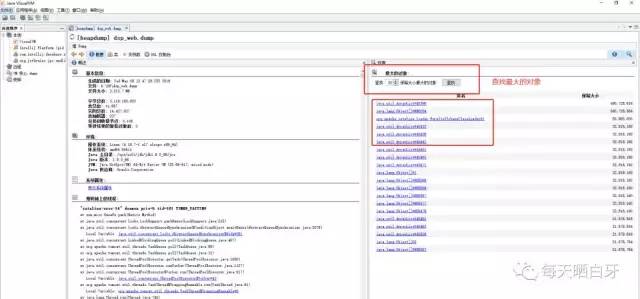
看看这些大对象都是什么
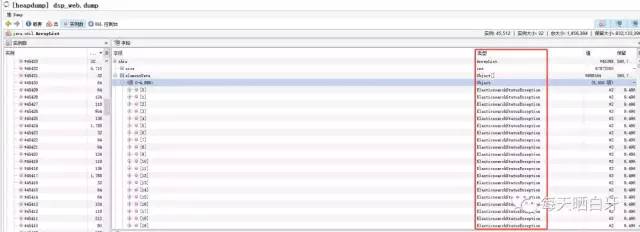
发现前面几个大对象都和 ElastaicSearchStatusException对象有关,然后这个管理平台用到es的地方只有一处,就是做数据漏斗,记录广告检索在哪些步骤过滤掉,方便产品和运营查看广告被过滤的原因,然后翻开代码
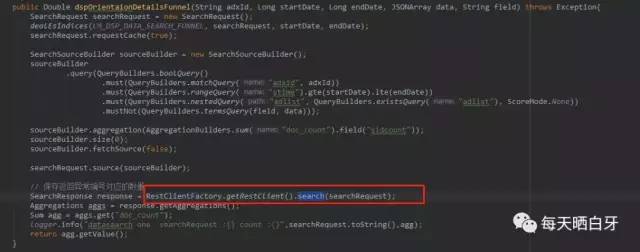
其中 RestClientFactory.getRestClient().search(searchRequest)的 search方法一步一步跟进,发现抛ElasticSearchStatusException的地方
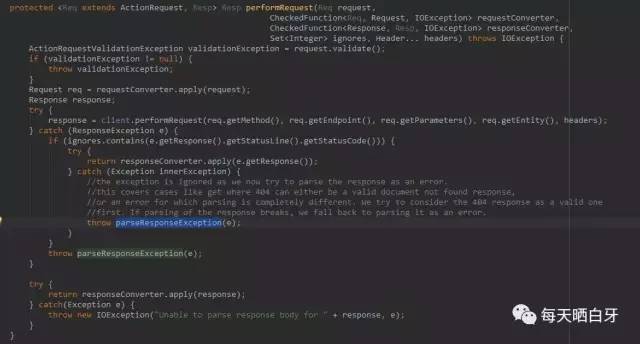
其中parseResponseException方法会抛出ElasticSearchStatusException异常,至于这两个地方具体是哪个步骤抛的,可以继续研究es代码判断或者 远程debug判定,我这里先不管了,反正我们能知道es出问题了
其实正是因为这里抛异常才会导致创建大量对象,因为异常在上面提到的打印异常日志的地方也会创建对象,老年代占用过高,导致大量fgc
但es这里为何会有异常?
我登录到es的管理平台查看es的索引,发现有的索引没有创建,索引的创建是有任务去创建并实时写入数据的,发现那个任务已经停了。
处理过程
找到相关的任务重新启动,并找任务停止的原因,修复,并把丢失的索引创建并修复数据
在异常日志打印那最好加入流控【用Guava.RateLimiter控制】
小结
cpu占用过高排查思路
top 查看占用cpu的进程 pid
top -Hp pid 查看进程中占用cpu过高的线程id tid
printf '%x/n' tid 转化为十六进制
jstack pid |grep tid的十六进制 -A 30 查看堆栈信息定位
jvm old区占用过高排查思路
top查看占用cpu高的进程
jstat -gcutil pid 时间间隔 查看gc状况
jmap -dump:format=b,file=name.dump pid 导出dump文件
用visualVM分析dump文件