
Python中进行特征重要性分析的9个常用方法
作者丨Roushanak Rahmat
来源丨Deephub Imba
特征重要性分析用于了解每个特征(变量或输入)对于做出预测的有用性或价值。目标是确定对模型输出影响最大的最重要的特征,它是机器学习中经常使用的一种方法。
为什么特征重要性分析很重要?
改进的模型性能
减少过度拟合
更快的训练和推理
增强的可解释性
特征重要性分析方法
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.inspection import permutation_importance
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=1)
rf = RandomForestClassifier(n_estimators=100, random_state=1)
rf.fit(X_train, y_train)
baseline = rf.score(X_test, y_test)
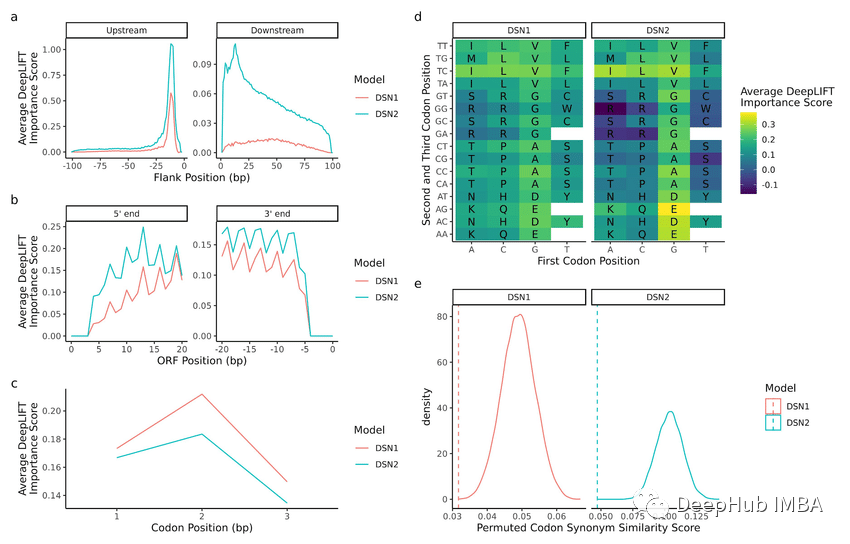
result = permutation_importance(rf, X_test, y_test, n_repeats=10, random_state=1, scoring='accuracy')
importances = result.importances_mean
# Visualize permutation importances
plt.bar(range(len(importances)), importances)
plt.xlabel('Feature Index')
plt.ylabel('Permutation Importance')
plt.show()
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
X, y = load_breast_cancer(return_X_y=True)
rf = RandomForestClassifier(n_estimators=100, random_state=1)
rf.fit(X, y)
importances = rf.feature_importances_
# Plot importances
plt.bar(range(X.shape[1]), importances)
plt.xlabel('Feature Index')
plt.ylabel('Feature Importance')
plt.show()

from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import numpy as np
# Load sample data
X, y = load_breast_cancer(return_X_y=True)
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# Train a random forest model
rf = RandomForestClassifier(n_estimators=100, random_state=1)
rf.fit(X_train, y_train)
# Get baseline accuracy on test data
base_acc = accuracy_score(y_test, rf.predict(X_test))
# Initialize empty list to store importances
importances = []
# Iterate over all columns and remove one at a time
for i in range(X_train.shape[1]):
X_temp = np.delete(X_train, i, axis=1)
rf.fit(X_temp, y_train)
acc = accuracy_score(y_test, rf.predict(np.delete(X_test, i, axis=1)))
importances.append(base_acc - acc)
# Plot importance scores
plt.bar(range(len(importances)), importances)
plt.show()

import pandas as pd
from sklearn.datasets import load_breast_cancer
X, y = load_breast_cancer(return_X_y=True)
df = pd.DataFrame(X, columns=range(30))
df['y'] = y
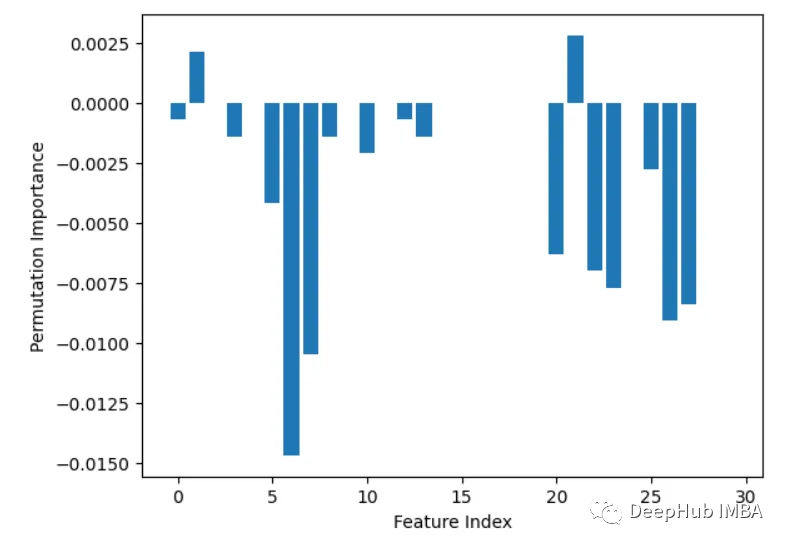
correlations = df.corrwith(df.y).abs()
correlations.sort_values(ascending=False, inplace=True)
correlations.plot.bar()
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import RFE
import pandas as pd
from sklearn.datasets import load_breast_cancer
import matplotlib.pyplot as plt
X, y = load_breast_cancer(return_X_y=True)
df = pd.DataFrame(X, columns=range(30))
df['y'] = y
rf = RandomForestClassifier()
rfe = RFE(rf, n_features_to_select=10)
rfe.fit(X, y)
print(rfe.ranking_)
import xgboost as xgb
import pandas as pd
from sklearn.datasets import load_breast_cancer
import matplotlib.pyplot as plt
X, y = load_breast_cancer(return_X_y=True)
df = pd.DataFrame(X, columns=range(30))
df['y'] = y
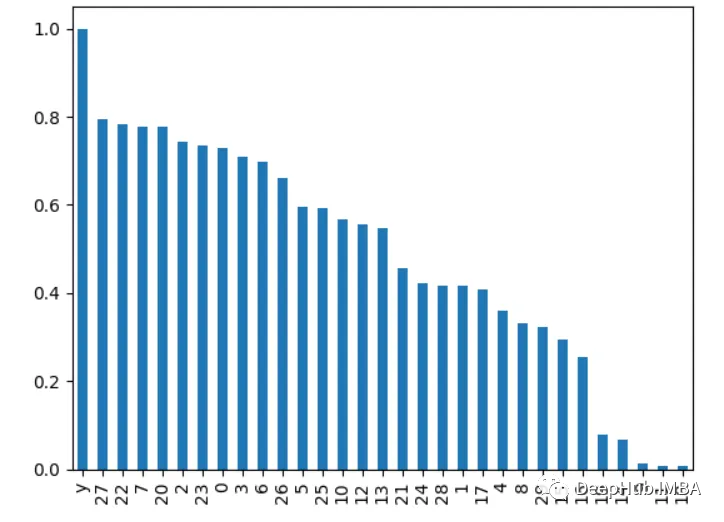
model = xgb.XGBClassifier()
model.fit(X, y)
importances = model.feature_importances_
importances = pd.Series(importances, index=range(X.shape[1]))
importances.plot.bar()
from sklearn.decomposition import PCA
import pandas as pd
from sklearn.datasets import load_breast_cancer
import matplotlib.pyplot as plt
X, y = load_breast_cancer(return_X_y=True)
df = pd.DataFrame(X, columns=range(30))
df['y'] = y
pca = PCA()
pca.fit(X)
plt.bar(range(pca.n_components_), pca.explained_variance_ratio_)
plt.xlabel('PCA components')
plt.ylabel('Explained Variance')

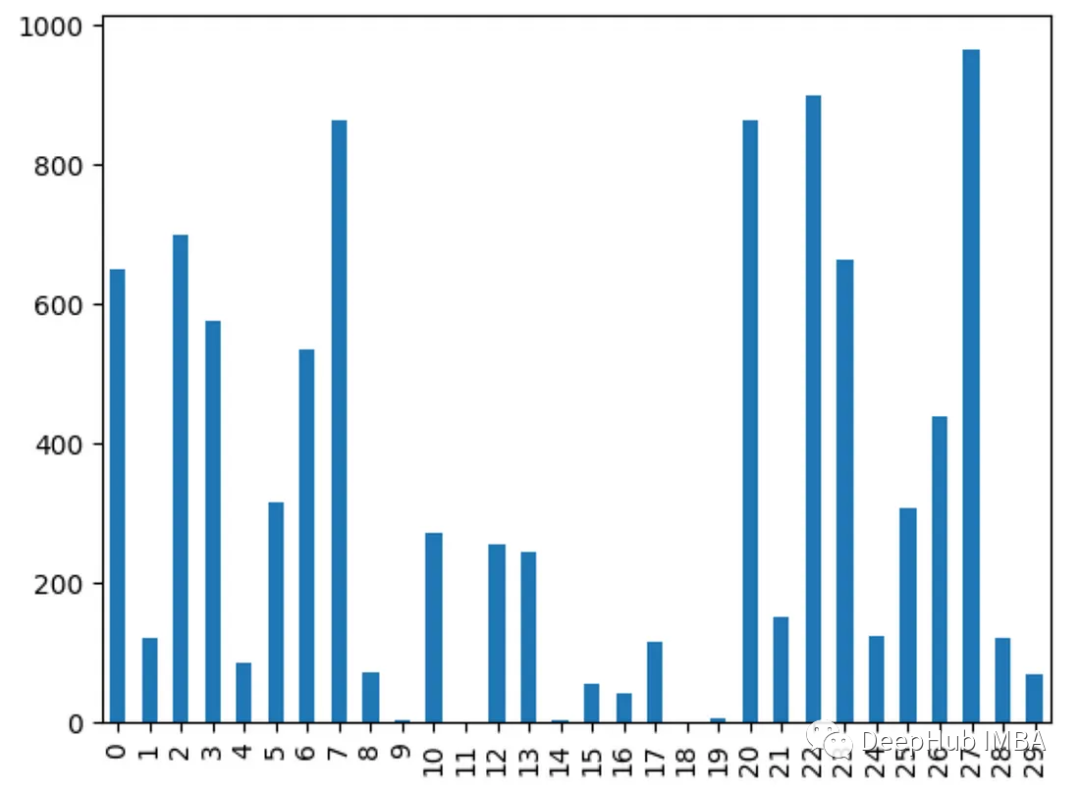
from sklearn.feature_selection import f_classif
import pandas as pd
from sklearn.datasets import load_breast_cancer
import matplotlib.pyplot as plt
X, y = load_breast_cancer(return_X_y=True)
df = pd.DataFrame(X, columns=range(30))
df['y'] = y
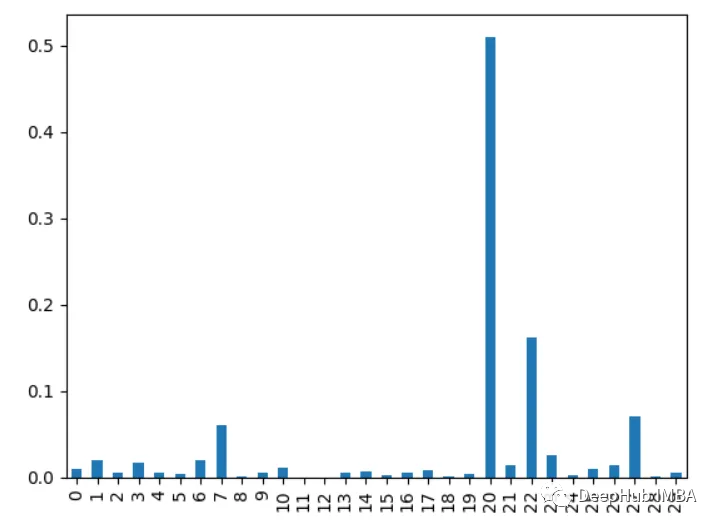
fval = f_classif(X, y)
fval = pd.Series(fval[0], index=range(X.shape[1]))
fval.plot.bar()
from sklearn.feature_selection import chi2
import pandas as pd
from sklearn.datasets import load_breast_cancer
import matplotlib.pyplot as plt
X, y = load_breast_cancer(return_X_y=True)
df = pd.DataFrame(X, columns=range(30))
df['y'] = y
chi_scores = chi2(X, y)
chi_scores = pd.Series(chi_scores[0], index=range(X.shape[1]))
chi_scores.plot.bar()
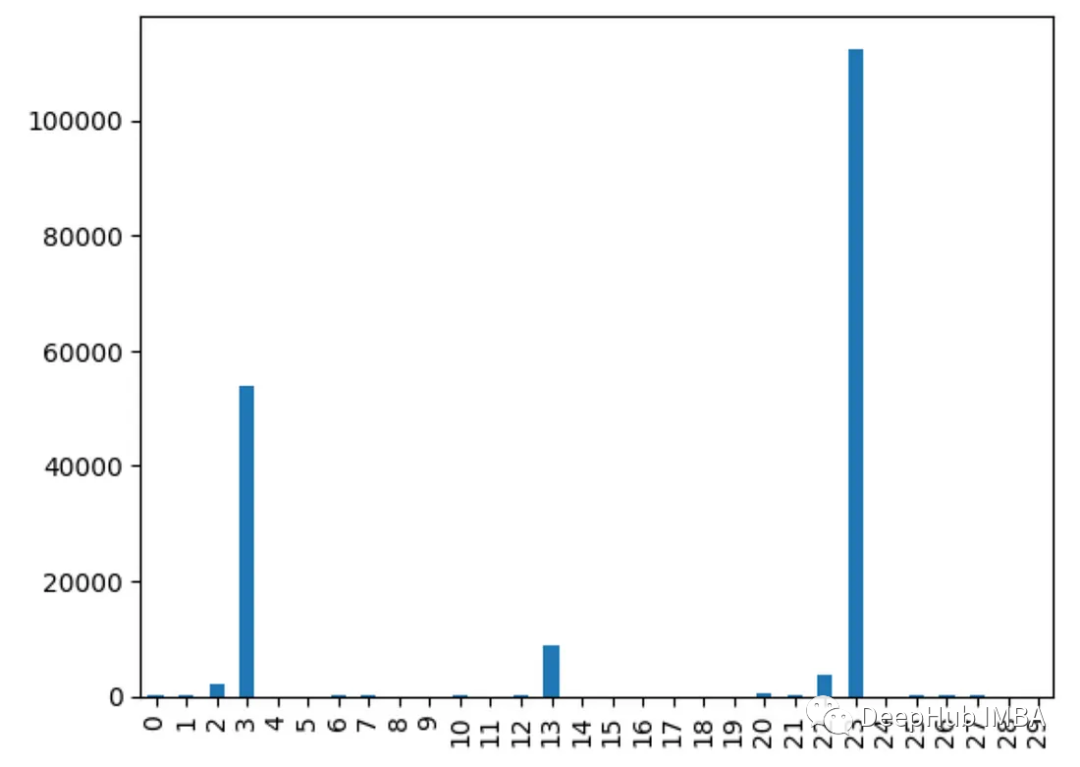
为什么不同的方法会检测到不同的特征?
选择特征重要性分析方法的一些最佳实践
尝试多种方法以获得更健壮的视图
聚合结果的集成方法
更多地关注相对顺序,而不是绝对值
-
差异并不一定意味着有问题,检查差异的原因会对数据和模型有更深入的了解