
多交互注意力网络用于CTR预估中细粒度特征学习
| 作者:YEN
本文分享一篇发表在WSDM’21的点击率预估方面的文章:交互注意力网络用于CTR预估中细粒度特征学习[1]
论文核心内容:构建更细粒度的特征交互提升CTR预估效果

接下来将从以下角度分享本篇论文:问题背景、相关的解决方案、已有方案存在的不足、提出的模型框架、提出的模型细节、实验设置及分析、总结。
CTR背景
点击率预估在推荐系统和在线广告场景中扮演着重要的作用。典型的点击率预估场景包括:淘宝/京东商品点击率预估,腾讯广告点击率预估...
CTR预估任务的数据一般包含用户属性、物品属性、交互上下文等多个域(Field)。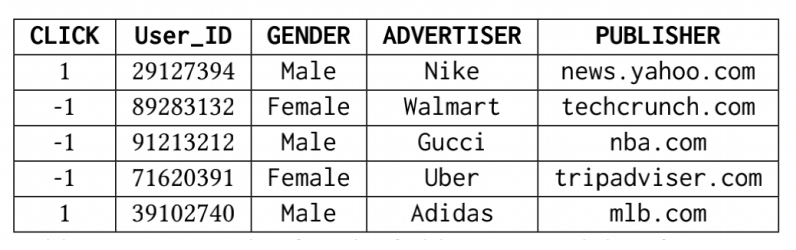
CTR预估模型可粗略的分为以下几类:
考虑特征交叉浅层模型:LR、FM、FFM、FwFM、FmFM... 考虑特征交叉深层模型:DeepFM、xDeepFM... 考虑历史行为的模型:DIN、DIEN (今天分享的论文属于本方向)
现存的考虑历史行为的方法
DNN 模型
在 2016 年,阿里妈妈团队开始尝试引入深度学习来解决 ctr 问 题,并考虑了用户的交互历史物品。第一代 Deep CTR 模型:
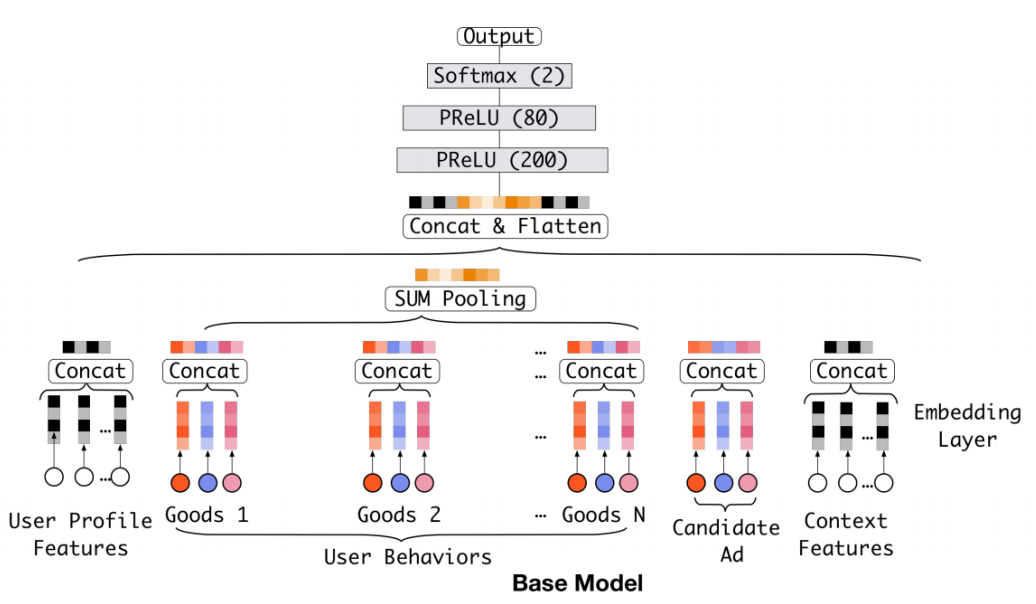
DNN模型对历史行为特征的应用仅仅是得到嵌入后直接相加。
DIN模型
然而,用户的历史行为数据,并不是每个都与当前的候选物品有关系,而是仅仅有一部分在起作用。比如一个爱好购物的人,购买过"羽绒服",也购买过"电脑",那么这次的预估是否会点击一个"裙子"时,"裙子"就更容易受到"羽绒服"这个购买历史的影响。所以阿里在 2017 年提出了Deep Interest Net (DIN)模型:
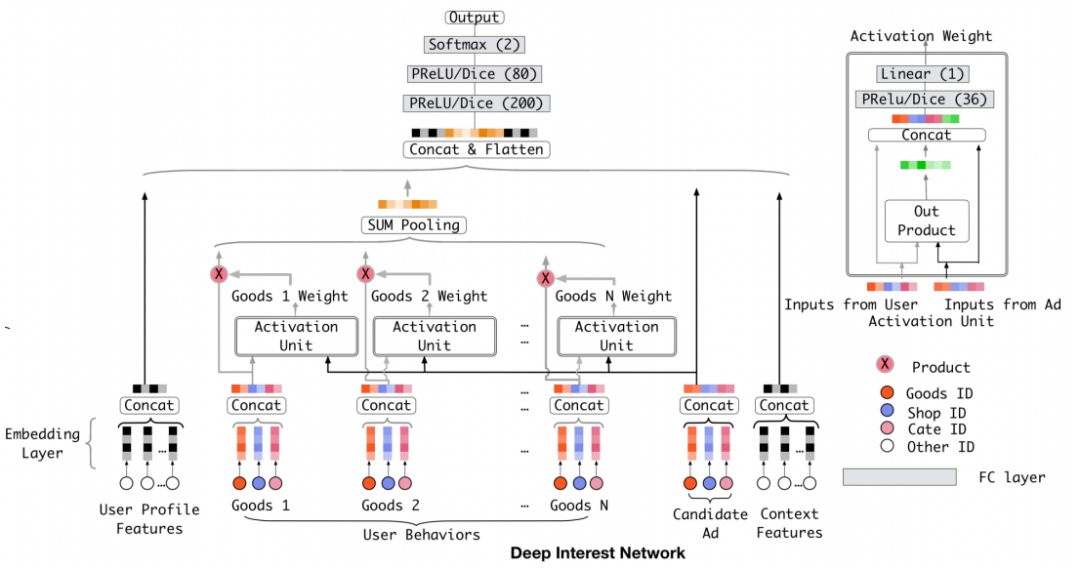
DIN通过对候选物品使用反向激活的方式,按照候选物品与历史点击商品的相关性的高低,来赋予历史行为不同的权重。
相关论文发表在:Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, et al. Deep interest network for click-through rate prediction. KDD, 2018.
DIEN
然而,DIN 模型忽略了兴趣随着时间之间演化这样一个重要的性质。所以 2018 年, 阿里进一步提出 DIEN,重点就是针对这样一个兴趣随时间演化的特点来进行建模以及模型的改造。
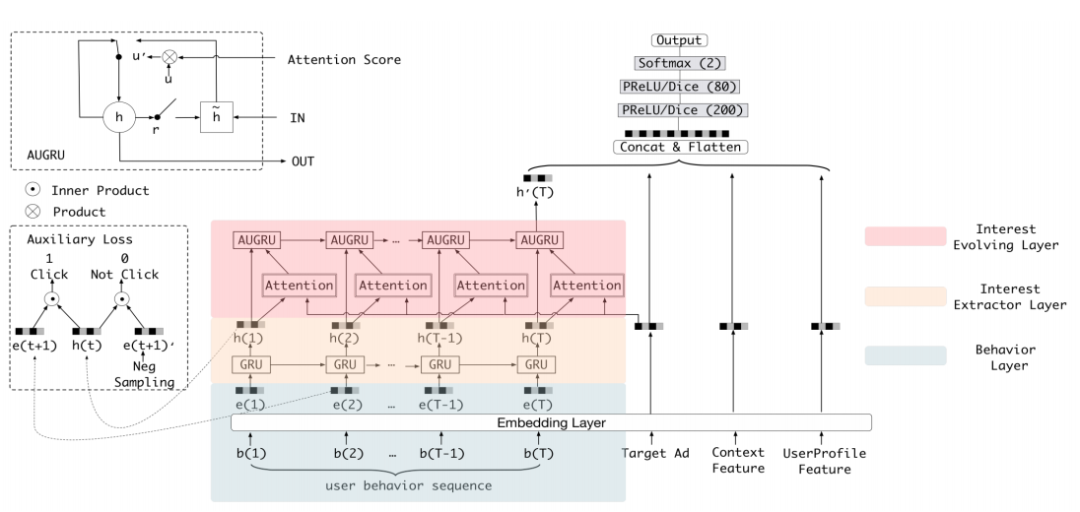
相关论文发表在:Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, et al. Deep interest evolution network for click-through rate prediction. AAAI, 2019.
现存方法的不足
尽管DIN、DIEN等方法取得了较大的成功,但他们依旧存在一些不足。如下图所示,即他们仅考虑了候选 item 与历史行为的关系,而忽略了候选 item 与用户属性、交互上下文信息的关系。
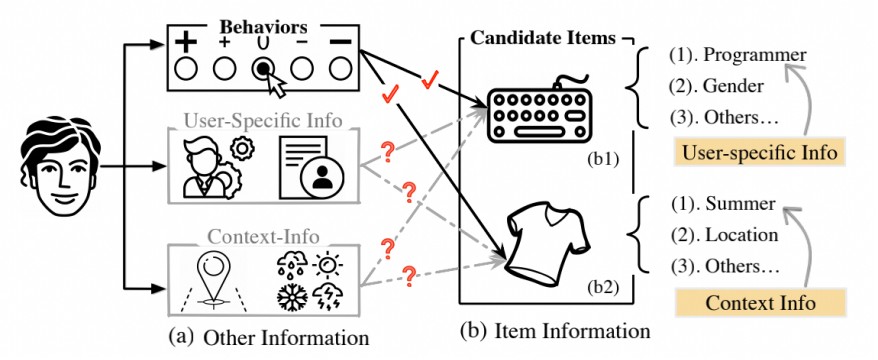
这可能导致以下问题:
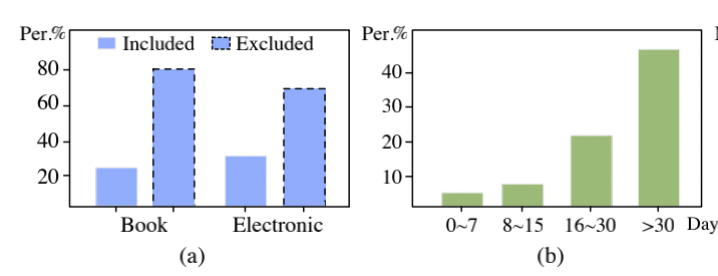
之前的方法考虑历史交互行为,然而用户可能会有与历史交互无关的需求(如下图a所示,在amazon数据集上仅有少量物品是出现在之前的历史行为中的)。传统的给用户行为加注意机制的 CTR 预测方法不适用; 很多物品的交互可能发生在很长时间之前,而近期没有活跃行为(如下图b所示,在amazon数据集上有超过50%的用户最近的活跃记录都在30天前)。因此很难通过近期的行为获得用户当前的喜好。 不同的场景中激活的历史行为应该是不同的。例如“T-shirt”这 个 item 应该激活的是“summer”这个上下文场景而不是“winter”。“mechanical keyboard”这个候选 item 更应该与用户属 性中的“programmer”这个特征相关。
提出的模型框架
这篇文章提出了 Multi-Interactive Attention Network (MIAN) 模型,它集成了多种细粒度交互信息。
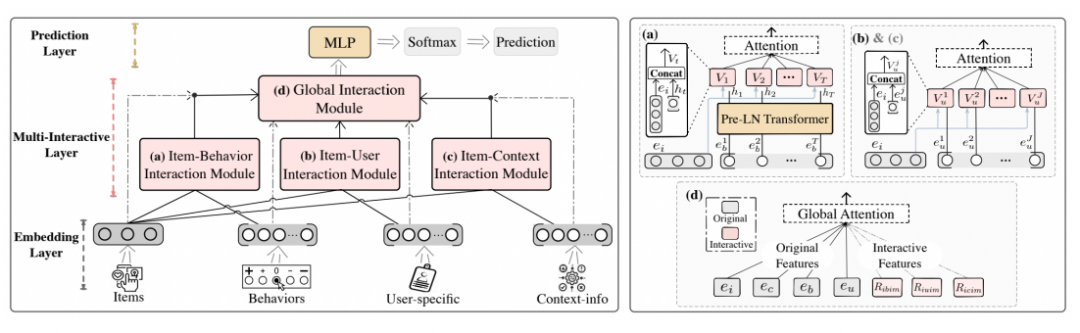
多交互网络包含三个局部交互模块(候选物品-行为交互模块;候选物品-用户属性交互模块;候选物品-上下文交互模块)和一 个全局交互模块。
模型细节
问题定义
CTR 预估的输入输入分为四个模块,候选物品、历史行为、上下文、用户属性。对每个类型的特征进行嵌入。
Item-Behaviors Interaction Module (IBIM)模块
此模块的目的是学习候选物品-历史行为之间的交互关系
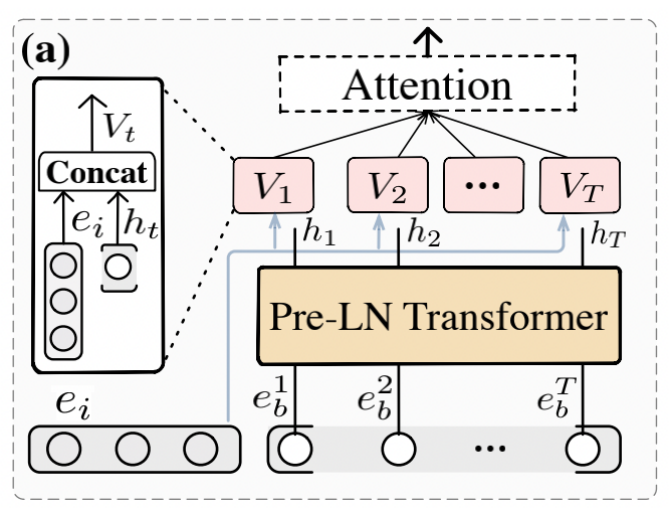
具体的,此模块包括以下五个计算步骤:
对输入数据进行Layer Normalization
使用Transfomer中的Multi-Head Self-Attention
得到的结果记为
Position-wise Feed-Forward Network (FFN)
目的:引入非线性变化,得到的结果记为
聚合行为状态与候选物品的embedding, 然后计算行为之间的重要性
加权融合历史行为
Item-User Interaction Module (IUIM)模块
此模块目的是计算候选物品与用户属性的交互
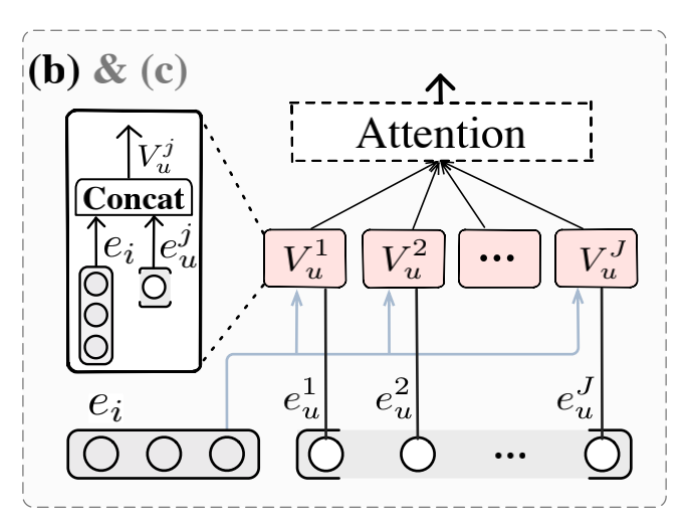
具体的,此模块包括以下三个计算步骤:
连接用户每个 field 的属性与候选item
计算attention
加权融合用户属性
Item-Context Interaction Module (ICIM)模块
此模块计算候选物品和上下文的交互
操作类似 IUIM 模块
Global Interaction Module (GIM)模块
此模块显式的捕获原始低阶特征和生成的高阶交互特征
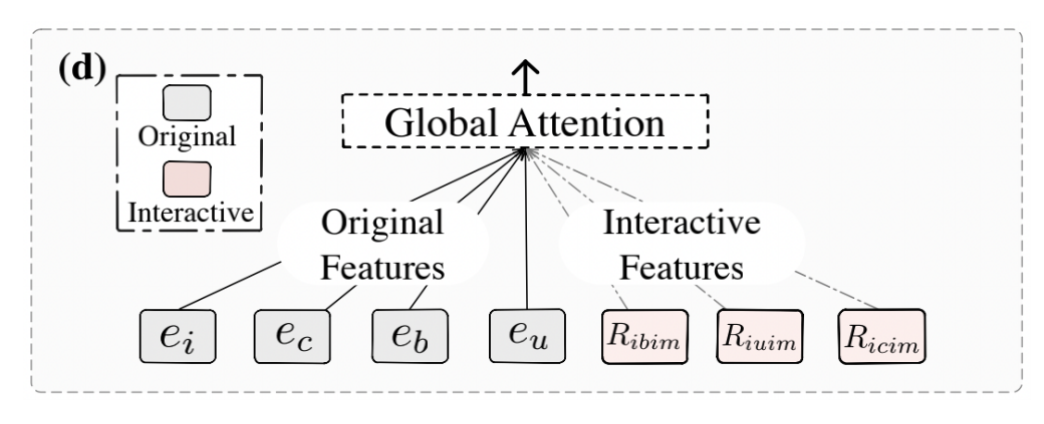
最终得到的表示为:
预测层
把上面的输入喂入MLP
然后通过softmax得到点击与不点击的概率:
模型训练
使用Cross-entropy Loss(损失函数)训练模型参数:
实验设计
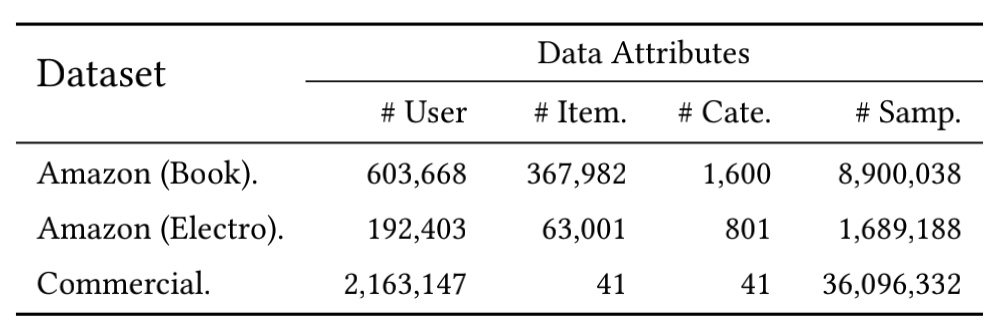
数据集:两个公开数据集一个私有数据集
实验结果
性能对比
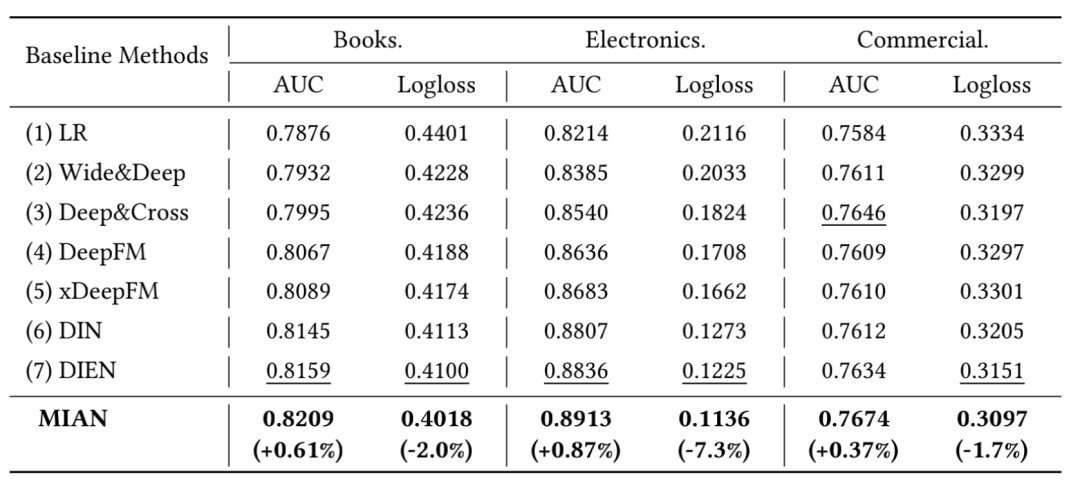
对于 Amazon 数据集,DIN、DIEN 等考虑序列关系的模型优于 DeepFM 等交互模型 对于商业数据集由于历史行为比较少,所以 DIN、DIEN 并未由于其他模型 MIAN 持续优于其他模型
消融实验
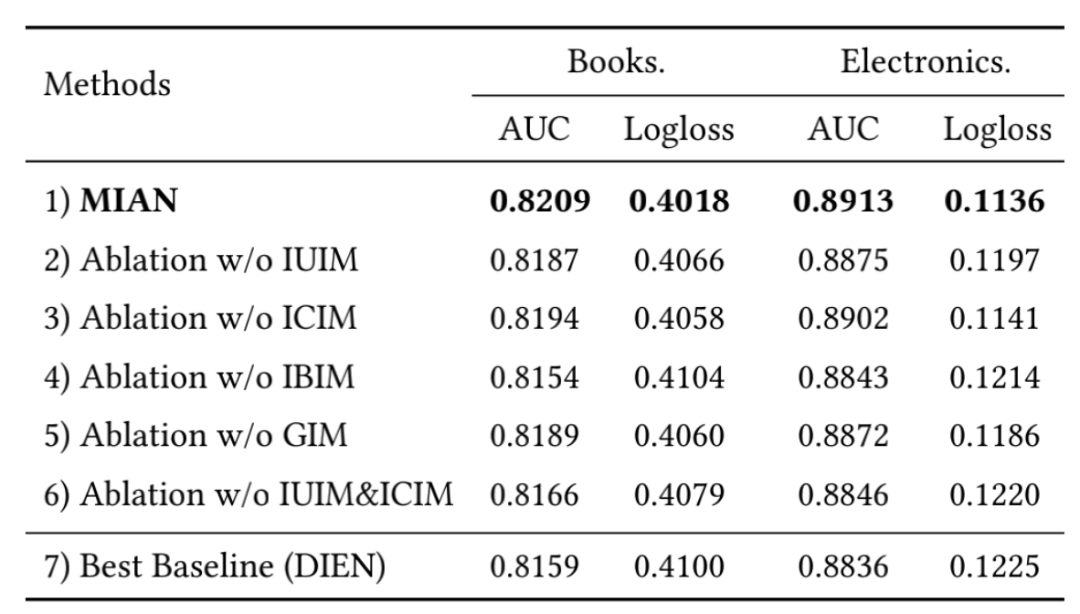
在所有环境中,移除 IBIM 都会伤害性能,表明 MIAN 可以有效的通过历史行为捕获用户偏好. 移除 IUIM、ICIM 也会伤害性能,但有趣的是它还是由于 DIEN,这表明 IBIM 模块与以往的顺序方法相比,能够充分有效地利用用户的历史行为特征。 此外,我们可以观察到,删除 GIM 确实在一定程度上损害了 MIAN 的性能。结果表明,CTR 的最终预测需要整个模型的高阶交互作用和多个模块的平衡。
特征重要性可视化
数据:随机从 Amazon 数据集中选择了 14 个例子来可视化权重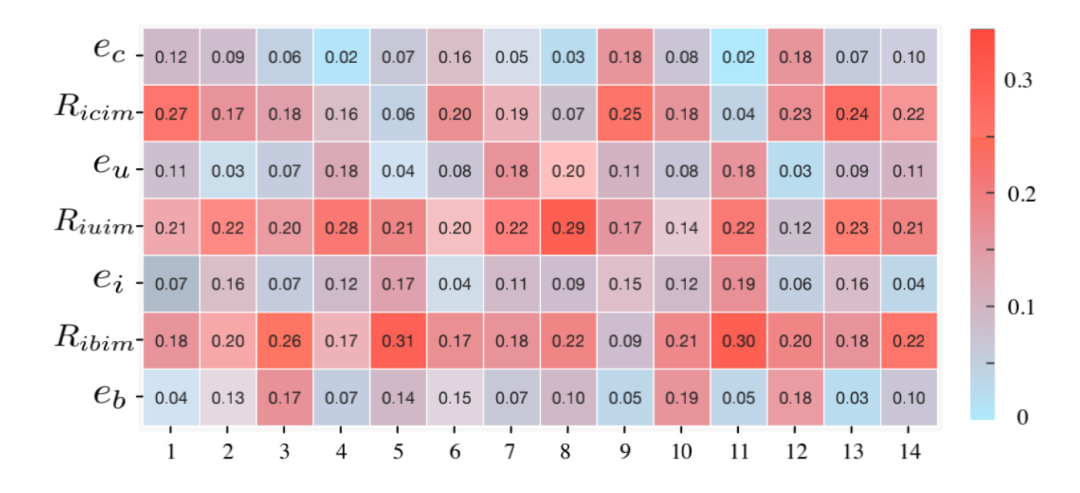
可以观察到", , "这几个特征的重要性高于原始特征表示,即""
总结
为了进一步提高CTR预测的性能,这篇提出了一种新的MIAN模型来模拟物品、用户顺序行为、用户特定信息和上下文信息之间的细粒度交互。
参考资料
Kai Zhang, Hao Qian, Qing Cui, Qi Liu, Longfei Li, Jun Zhou, Jianhui Ma, Enhong Chen.Multi-Interactive Attention Network for Fine-grained Feature Learning in CTR Prediction.WSDM, 2021.: https://dl.acm.org/doi/pdf/10.1145/3437963.3441761