
Python中堪称神仙的6个内置函数

人生苦短,快学Python!
大家好,我是小五。之前给大家分享过3个节省时间的Python技巧,当时就提出了,大家可以多使用Python的内置函数,既能提高自己的Python程序速度,同时还能保持代码简洁易懂。
今天,它们就来了,我们会一次性分享6个堪称神仙的内置函数。在很多计算机书籍中,它们也通常作为高阶函数来介绍。而我自己在日常工作中,经常使用它们来使代码更快,更易于理解。
Lambda 函数
Lambda函数用于创建匿名函数,即没有名称的函数。它只是一个表达式,函数体比def简单很多。当我们需要创建一个函数来执行单个操作并且可以在一行中编写时,就可以用到匿名函数了。
lambda [arg1 [,arg2,.....argn]]:expression
lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。例如:
lambda x: x+2
如果我们也想像def定义的函数随时调用,可以将lambda函数分配给这样的函数对象。
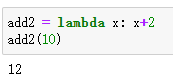
add2 = lambda x: x+2
add2(10)
输出结果:
利用Lambda函数,可以将代码简化很多,具体再举个例子。
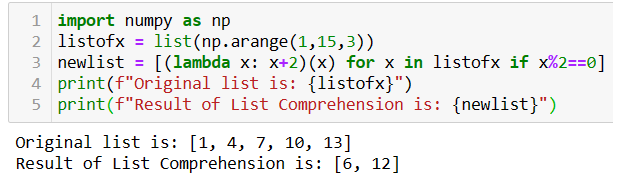
如上图所示,结果列表newlist是使用lambda函数用一行代码生成的。
Map 函数
map()函数会将一个函数映射到一个输入列表的所有元素上。
map(function,iterable)
比如我们先创建了一个函数来返回一个大写的输入单词,然后将此函数应有到列表colors中的所有元素。
def makeupper(word):
return word.upper()
colors=['red','yellow','green','black']
colors_uppercase=list(map(makeupper,colors))
colors_uppercase
输出结果:

此外,我们还可以使用匿名函数lambda来配合map函数,这样可以更加精简。
colors=['red','yellow','green','black']
colors_uppercase=list(map(lambda x: x.upper(),colors))
colors_uppercase
如果我们不用Map函数的话,就需要使用for循环。
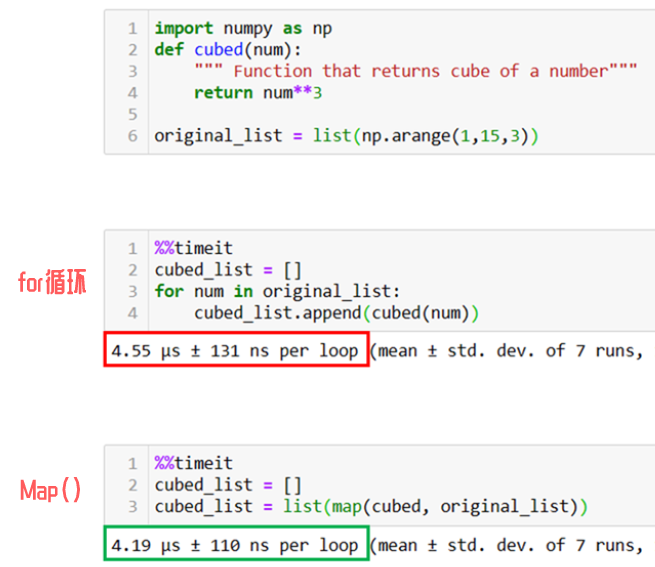
如上图所示,在实际使用中Map函数会比for循环依次列表元素的方法快1.5倍。
Reduce函数
当需要对一个列表进行一些计算并返回结果时,reduce()是个非常有用的函数。举个例子,当需要计算一个整数列表所有元素的乘积时,即可使用reduce函数实现。[1]
它与函数的最大的区别就是,reduce()里的映射函数(function)接收两个参数,而map接收一个参数。
reduce(function, iterable[, initializer])
接下来我们用实例来演示reduce()的代码执行过程。
from functools import reduce
def add(x, y) : # 两数相加
return x + y
numbers = [1,2,3,4,5]
sum1 = reduce(add, numbers) # 计算列表和
得到结果sum1 = 15,其代码执行过程如下方动图所示。
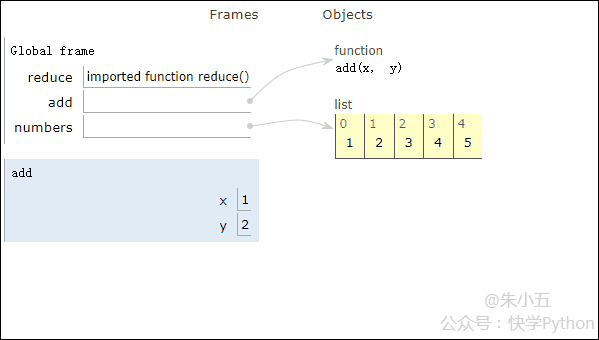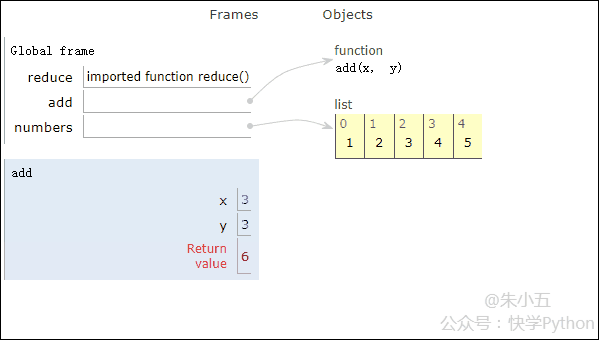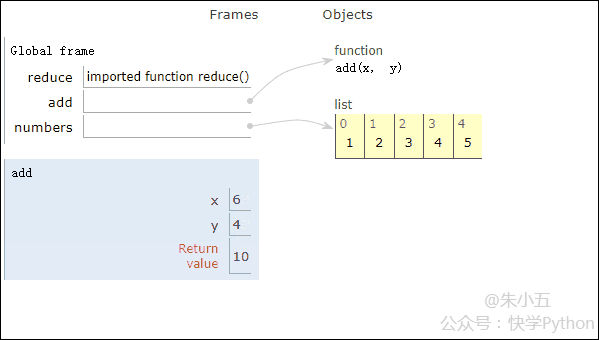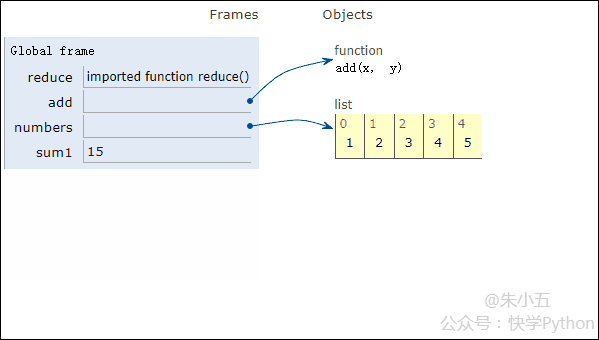
结合上图我们会看到,reduce将一个相加函数add()作用在一个列表[1,2,3,4,5]上,映射函数接收了两个参数,reduce()把结果继续和列表的下一个元素做累加计算。
此外,我们同样可以使用匿名函数lambda来配合reduce函数,这样可以更加精简。
from functools import reduce
numbers = [1,2,3,4,5]
sum2 = reduce(lambda x, y: x+y, numbers)
得到输出sum2= 15,与之前结果保持一致。
需要注意:Python3.x开始
reduce()已经被移到functools模块里[2],如果我们要使用,需要用from functools import reduce导入.
enumerate 函数
enumerate()函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中。它的语法如下所示:
enumerate(iterable, start=0)
它的两个参数,一个是序列、迭代器或其他支持迭代对象;另一个是下标起始位置,默认情况从0开始,也可以自定义计数器的起始编号。
colors = ['red', 'yellow', 'green', 'black']
result = enumerate(colors)
如果我们有一个存放colors的颜色列表,运行后就会得到一个enumerate(枚举) 对象。它可以直接在for循环中使用,也可以转换为列表,具体用法如下所示。
for count, element in result:
print(f"迭代编号:{count},对应元素:{element}")

Zip 函数
zip()函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表[3]。
我们还是用两个列表作为例子演示:
colors = ['red', 'yellow', 'green', 'black']
fruits = ['apple', 'pineapple', 'grapes', 'cherry']
for item in zip(colors,fruits):
print(item)
输出结果:

当我们使用zip()函数时,如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。
prices =[100,50,120]
for item in zip(colors,fruits,prices):
print(item)

Filter 函数
filter()函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表,其语法如下所示[4]。
filter(function, iterable)
比如举个例子,我们可以先创建一个函数来检查单词是否为大写,然后使用filter()函数过滤出列表中的所有奇数:
def is_odd(n):
return n % 2 == 1
old_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
new_list = filter(is_odd, old_list)
print(newlist)
输出结果:

今天分享的这6个内置函数,在使用 Python 进行数据分析或者其他复杂的自动化任务时非常方便。
如果喜欢本文,欢迎给右下角点赞👍
参考资料
书籍: 机械工业出版社-《Python编程基础》
[2]菜鸟教程: https://www.runoob.com/python/python-func-reduce.html
[3]菜鸟教程: https://www.runoob.com/python/python-func-zip.html
[4]towardsdatascience: https://towardsdatascience.com/

